P4-单周期CPU(Verilog实现)
仅凭阅读本文,您并不能学会如何用verilog实现单周期CPU,但是您的收获可能有:知道怎么实现是麻烦的,知道麻烦的后果是什么,了解一种比较好的实现思路,了解课上测试的形式与内容。
注意,由于20级更换了评测平台,并且看起来测试数据变多了,所以测试点**不一定**有“分布特点”:前几个点是课上的新指令点,后面的都是纯课下指令的强测。如果有大佬课上很快地AK了,可以故意把新指令删了提交上去试一下。
PS:本人还没死透,虽然在P3献出了首挂,但仍可一搏,拖更的原因是,我第一遍写代码又写复杂了,虽然能过,但是为了课上方便修改,所以又重写了一遍(人不能没有从头再来的勇气)
这里会粗略介绍搭建过程,重点介绍P4与P3在实现上的区别、我踩过的坑、第一次写时代码的缺陷以及第二次编写时的优化点,希望能拿来警醒自己,也希望能给各位的设计提供一些可能的优化方案。
想学习单周期CPU理论的,请移步课本/课件,本人自知理论功底浅薄,且理论并非一篇文章就能讲明白的,所以此处分享内容更偏重实现。
引流:关于课上测试的题目风格,可以看这位学姐的博客:https://www.cnblogs.com/Happy-Huan/p/14092007.html
注意:弱测3个点,不CE基本就能过2个点,弱得一批。
搭建中的注意点:
实现基本功能的关键在于两表的填写,实现的复杂度取决于对P3电路的翻译方式。两表,即数据通路表以及指令-信号真值表。在P3中,我们已经至少写过一遍两表了,这里不再多说表的填写方式了。值得注意的是,与P3稍有不同,P3中我们可以尝试先写一条R型指令的所有信息,然后连接一下数据通路,然后再选I,J型的连接一下,造出来基本的框架,但P4推荐把表完全写完之后再去写代码,理由如下:代码描述电路不如直接连线那么直观,如果想要在原有的数据通路上做修改的话,需要自己“耳聪目明”+“命名合理”,才能在修改的时候能够知道该改哪条导线;如果列完表再去写代码的话,由于各个输入输出端口到底有哪些来源,需要怎样的控制信号,都已经完全确定了,故节省了在修改上所花费的时间,并且从实际效果来看,可以节省在mips.v(顶层)定义的导线条数(不推荐再尝试逐步修改实现所有指令的方法了,有时间不如看看流水线)
为了辅助写代码,看着P3的电路图是一个方法,但是,前面说过了,代码实现复杂度取决于翻译方式!再次掏出P3电路说事儿:
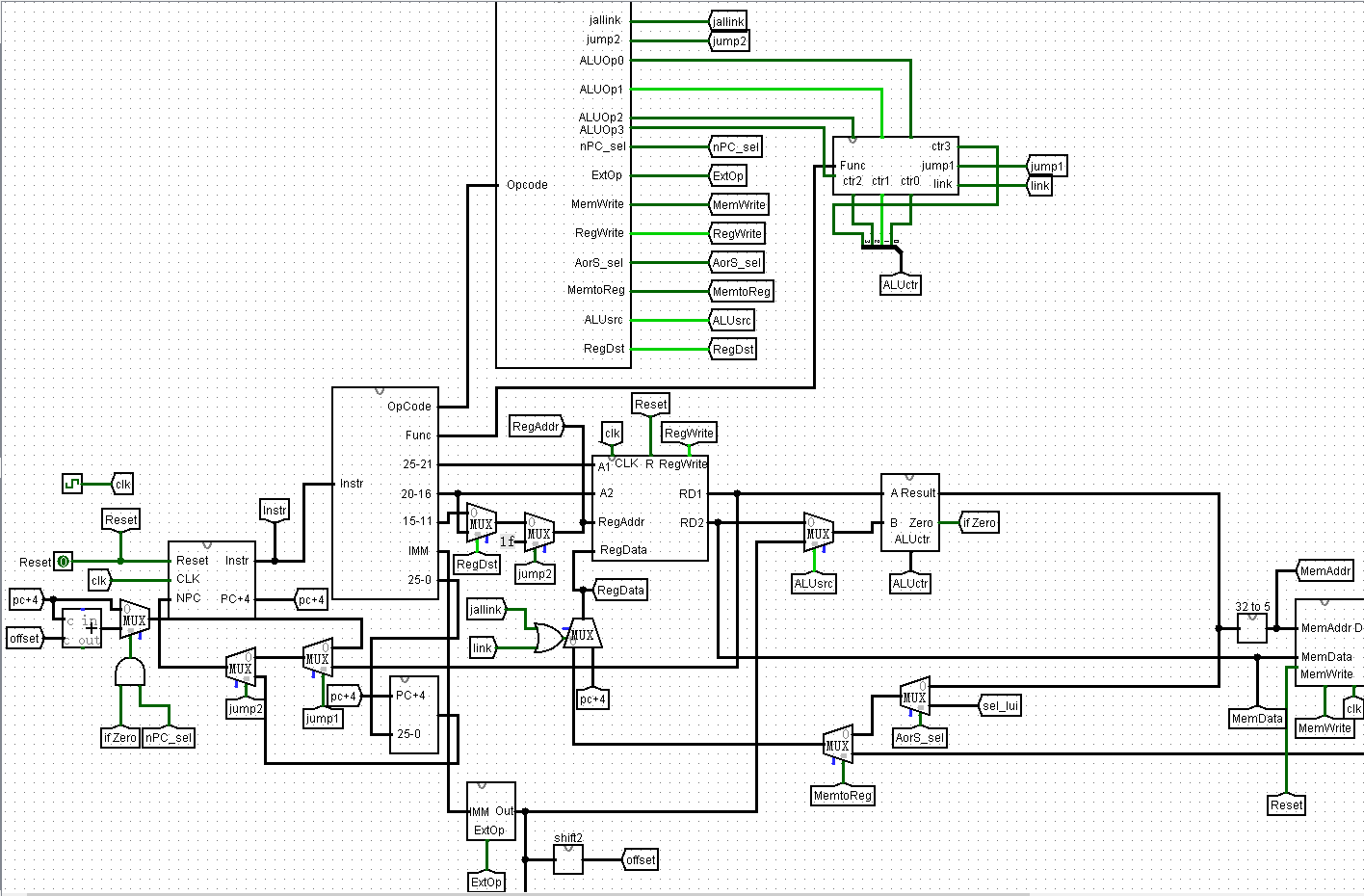
我前段时间自认为连得还不算复杂,课上的时候改动也不大,于是我就使用了铁憨憨式翻译法。
铁憨憨式翻译法(错误!):兄弟们,看到这个电路里的导线了吗?他们有五六十根,我们只要把所有模块搭建好,把所有导线都取上名字,然后对应连起来,就好了,这导致的车祸现场是这样的:

上图为部分mips.v文件中的导线定义,所有导线定义有接近两屏,可以自行想象。
虽然我使用了“前一元件 to 后一元件”的命名方法,但是,我第一次是边造表边连接的,所以很多导线在加指令的时候需要改名字,这样改着改着,导线定义就弄了六十多行,连完之后出了bug怀疑人生,这可怎么改?事实上还是可以改的,合理的添加断点,查看中间变量以及逐条测试指令可以解决这一问题,最终还是奇迹般的过了,然而我估计自己并不敢上课对这样一坨“庞然大物”动手动脚。这个设计无疑是失败的。首先,我这个电路图就不好,比如这里:
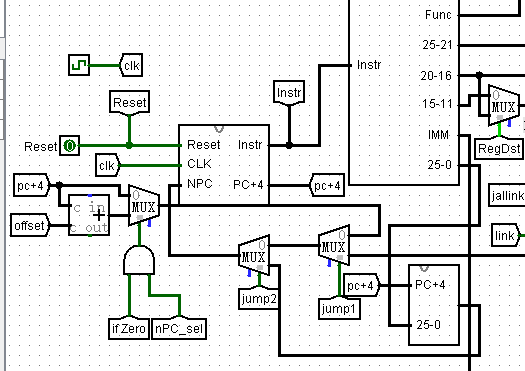
NPC有多少种可能性呢?目前支持的指令中,无非是pc+4, pc+4+(offset<<2), {pc+4[31:28],25-0,00}, $寄存器。这四个东西我居然用了3个选择器实现选择(这样的原因是从功利的角度来看,真正连接电路的时候特别好改,易于过课上),这会增加很多导线的定义,也是一种资源的浪费。很显然的一种改进方式是用4选一多路选择器,控制信号改为两位的,这样节省了导线,也减少了控制信号个数。
其次,我采用了边列表边写代码的方式,前面已经说了,这样会有很多改动,对于不直观且导线特别多的代码来说,修改是灾难性的,有时虽有注释,但搞不清导线的真正意义,有时会重定义,对于多路选择器,如果命名不好的话,也不知道该实例化哪一个。
找到失败原因之后,第二次中我采用了如下的翻译方法:
合并2选1多路选择器,并将多路选择器封装到主干模块内部的翻译法(仍不够优):先放一小段代码以举例子:


`timescale 1ns / 1ps module ALU( input [31:0] A, input [31:0] B_from_grf, input [31:0] B_from_ext, input [1:0] ALUsrc, //为了扩展方便,所以改成了两位 input [3:0] ALUOp, output reg [31:0] result, output reg zero ); //0000:加法, 0001:减法, 0010:或运算, 0011:比较运算 wire [31:0] B; wire [31:0] maybe_b[3:0]; //为了简化,把所有选择的数据存到数组中,方便直接通过选择信号直接选出来 assign maybe_b[0]=B_from_grf; assign maybe_b[1]=B_from_ext; assign B=maybe_b[ALUsrc]; always @ (*) begin case(ALUOp) 4'b0000:begin result<=A+B; zero<=0; end 4'b0001:begin result<=A-B; zero<=0; end 4'b0010:begin result<=A|B; zero<=0; end 4'b0011:begin if(A-B==0)begin zero<=1; end else begin zero<=0; end end endcase end endmodule
不像传统的ALU,我把ALU不同的B输入来源都作为单独的输入,并把ALUsrc信号也作为输入。在ALU中,开辟了一块可以存储这几种ALU的B端口的可能输入情况的空间,用ALUsrc选择,然后选出作为B的操作数,这样相当于把多路选择器封装到ALU里面了,用模块内的assign实现减少顶层导线的目的,也不用费尽心思去想怎么定义MUX才能知道这个MUX是干啥的。事实上,如果我们的MUX是以选择哪些地方的东西为标准命名的(比如这里的MUX名字命名为ALUB_select),而不是以它的每个输入是多少位,输出多少位,多少输入为标准命名的话(比如这里是32位输入,32位输出,命名为mux32_to_32,这样),放在顶层更好(因为保证了ALU功能的单一性:计算,没有杂糅选择功能,加指令的时候也只需要改动mux,不需要改alu的输入口个数)。
上述方法依然不够优,因为它把ALU弄成了一个四不像的东西。事实上,在做完P5之后,会发现一个更好的实现方法是:将小的模块与模块再次封装。比如ALU及其两个输入时用于选择的n选1MUX,我们可以将这三个东西再打包一次,弄一个新的模块(比如叫它为E模块),这样既避免了ALU内嵌mux而耦合严重,也因引入了E模块而简化了顶层mips.v的布线。类似地各位也可以将GRF以及它的输入端的几个MUX封装成新模块。
易错点:
1.非阻塞赋值与display的内容不相符
评测机是通过看我们display的东西和它需要的一样不一样来评判我们是否正确的。如果采用非阻塞赋值,紧接着来一句display的话,由于非阻塞赋值是在过程块结束时才统一赋值的,所以输出的东西是未修改的。
2.位宽
对于0x00003000,它的位宽是32位,所以二进制写法是32'b00000000000000000011000000000000,省事写16进制的话,是32'h00003000,这里的32指的是位宽,而不是这个数在某种进制下有几位!
3.jr跳转
jr不只是可以跳31号寄存器存的地址,任何寄存器存储的地址它都可以跳!这是室友P4课上遭遇的车祸现场,课下弱测并没有测试出来!请务必检查jr是否写对了!
4.还是display
需要输出32位宽的内存地址,不是【11:2】(10位)地址,请大家看好自己的输出!和教程中提供的输出比对一下,应该就会发现。
5.Reset常见误区
首先是同步复位,这个老生常谈了,可以参考我以前的博客。之后就是reset的地方够不够,对不对,我们需要reset的地方是程序计数器PC,寄存器堆GRF,数据存储器DM,除此之外,如果发现自己在其他地方也使用了reset,就得好好斟酌一下,这里到底需不需要reset?比如,我发现自己在IM中加了一个reset,本地测试过了,提交没输出,为何?经过了一天的思考和从各方获取经验,我隐约意识到可能是复位出了问题,IM里面为什么需要reset?是防止PC值没有变成0x00003000吗?我最开始的确是这么想的,所以在里面加了reset,但是,后来我发现,我reset的并不是输入进来的PC,而是,指令存储空间!!也就是说,考虑到评测机最开始上来就reset一下,我读入的code直接没了,当然之后没有输出。为何本地没有测出来问题?因为我没有检查reset,只是保持reset=0跑的程序。这个点卡了我一天多,也卡了评论区不少同学好长时间。还有类似的问题如输出比正常的慢一周期的,也请看看reset。这样,关于reset的坑差不多就介绍完了。
关于debug:
Verilog教程部分的视频建议重新看一遍,学一学如何加断点,如何加入中间变量作为信号,这些对于我们追溯bug的来源很有帮助,比如我就用这个方法逐步追溯一个跳转bug,先在alu里面加断点,填加中间变量看zero是多少,发现不符合预期,并发现ALU的参与计算的AB不是自己想要的,然后我又加断点到GRF,成功发现自己把一条线连错了导致传入ALU的值不对。这里只是举了一个简单的例子,其他bug可以用这个方法类似解决。
另外,合理地设计测试程序也是很重要的,首先就是别好几条指令一起测,一次我们就测一条指令,比如先充分测ori,然后有了ori之后,测加减法,有了加减法之后测跳转以及其他的指令,最后可以再写一个综合测试程序把所有的都测一遍。不要一起测!!不瞒您说,我连加法都写错了,开始用综合测试程序测的,测到的我的beq没执行,然后我就一直看beq,好长时间之后才发现是我加法有问题,导致了值不符合分支条件。希望大家能引以为鉴。
更新:刚才看讨论区的时候,看到了所谓的implement debug法,这个办法我也曾经误触发过,挺有用的,可以查到很多因为笔误写出的bug。具体操作是:双击Synthesize-XST(就在语法检测旁边,所以我当时点错误触发过这个技能),或者在最上方点击绿色头朝右的三角形,然后等着,看下面的warning和error,复制到IDE或者记事本上一条一条看,对着改基本上就能解决很多问题。
关于命名:
记住一件事:采用from_to(从某模块的某接口到另一模块的某接口)式命名看起来虽然很严谨很nb,但是CPU中并非某个接口只连接另外的一个接口,所以这样命名是一场灾难!就会像我一样在P5中耗费巨大的精力重写代码规范命名!
本文就分享到这里吧,祝大家好运连连,AK P4
