决策树与集成
Decision Tree
Greedy, Top-down, Recurrent
Classification Tree
misclassification loss is not suitable for decision tree loss, because
can not always be guaranteed > 0.
we usually use Cross-Entropy Loss.
the \(L_{misclass}\) is not strictly concave uniformly.
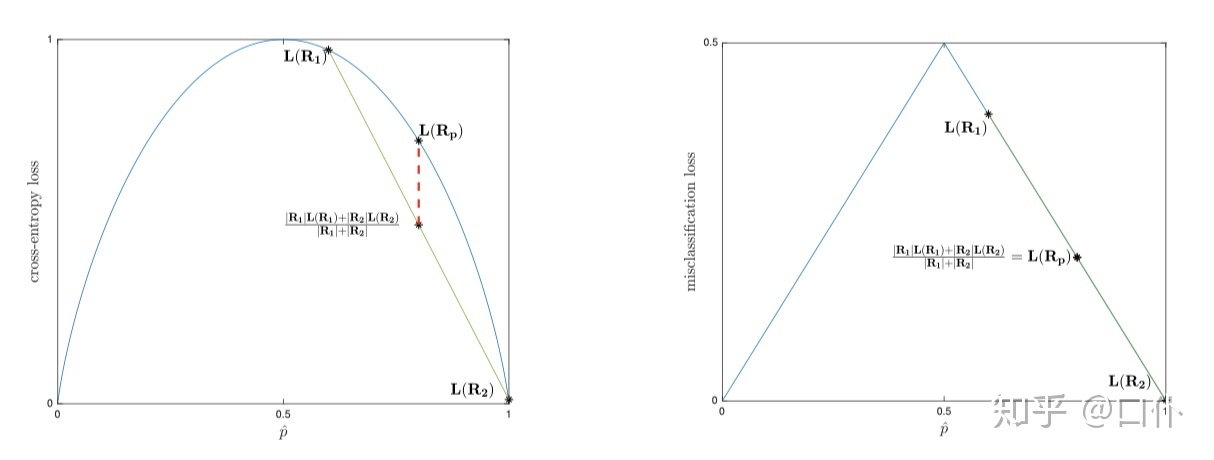
( from https://zhuanlan.zhihu.com/p/146964344 )
Regression Tree
Output the average value of region R.
We use Square Loss
Regularization
- 「最小化叶子规模」:当区域的基数低于某个阈值时,停止分割该区域
- 「最小化深度」:如果某个区域进行的分割次数超过了某个阈值,则停止分割
- 「最小化节点数量」:当一个树拥有了超过某个阈值的叶子节点,则停止生长
Prune after building the tree.
( from https://zhuanlan.zhihu.com/p/146964344 )
Pros and cons
cons: High variance, not support additive model very well
Assemble Method
so if we want to reduce the Var, we can increase the number of models or cut down \(\rho\)
Bagging
bagging is Bootstrap Aggregation. Decrease Var
-
bootstrap
P is total population, S is the training set
suppose that S=P, sample Z from S to guide a sub model.
bootstrap samples \(Z_1,Z_2,...,Z_M\) train \(G_m\) on \(Z_m\)
reduce \(\frac{1-\rho}{M}\) bias is larger
-
aggregation
\[G(x)=\frac{\sum_{m=1}^M G_m(x)}{M} \] -
Random Forest
at each split, consider only a fraction of your total features
decrease the correlation(\(\rho\)) between models
Boosting
Decrease Bias
the assemble is additive(not average).
the misclassified cased will be weighted more in the next tree's training process.
Adaboost:
\(\alpha_m\) for \(G_m\) is \(\log (\frac{1-err_m}{err_m})\)
Takeaway