


李宏毅机器学习课程——Seq2Seq/Attention学习笔记
这一部分比较有难度,希望结合作业hw8代码,认真整理一下Seq2Seq与Attention机制的内容。本文主要是我对于这部分知识的理解和再加工,如有理解不当之处欢迎大家指出。文中的图文均来自于李老师的PPT。
多层LSTM
以下是LSTM的原理\(^{[3]}\)。
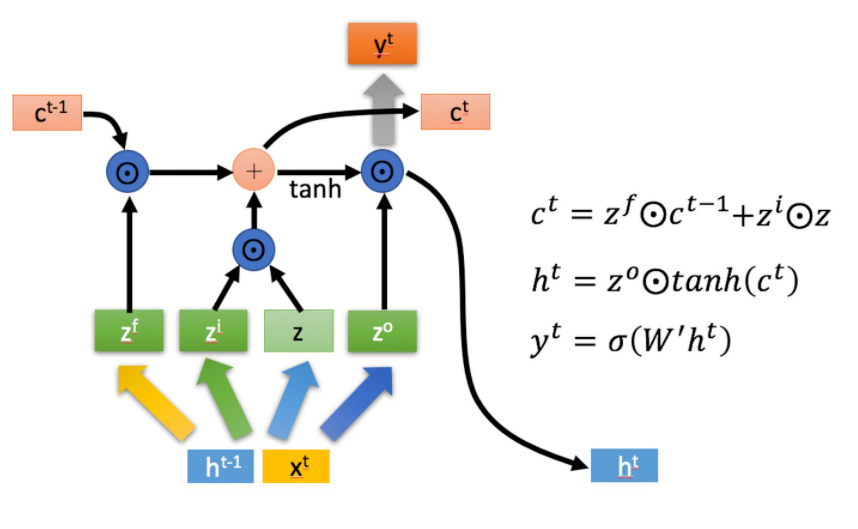
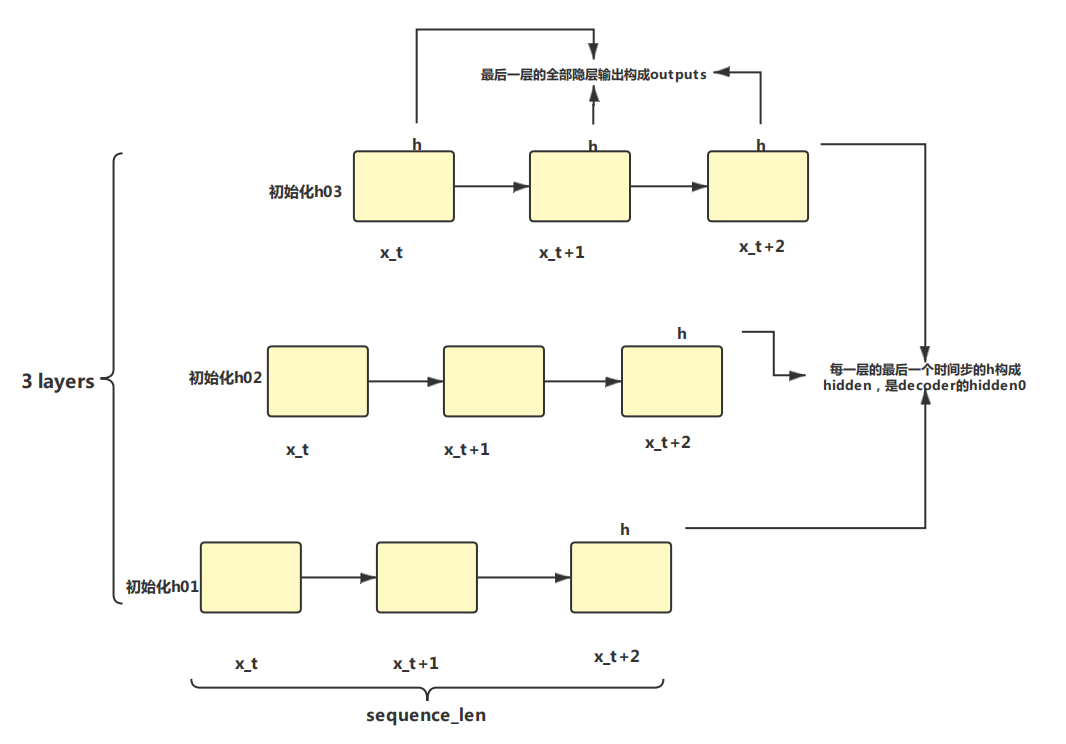
一直以来对多层LSTM存在误解,把time_steps与n_layers搞混,其实两者是不同的\(^{[1]}\)。两者是正交的。时间序列是在每一个层内存在的,层与层之间是并行的。
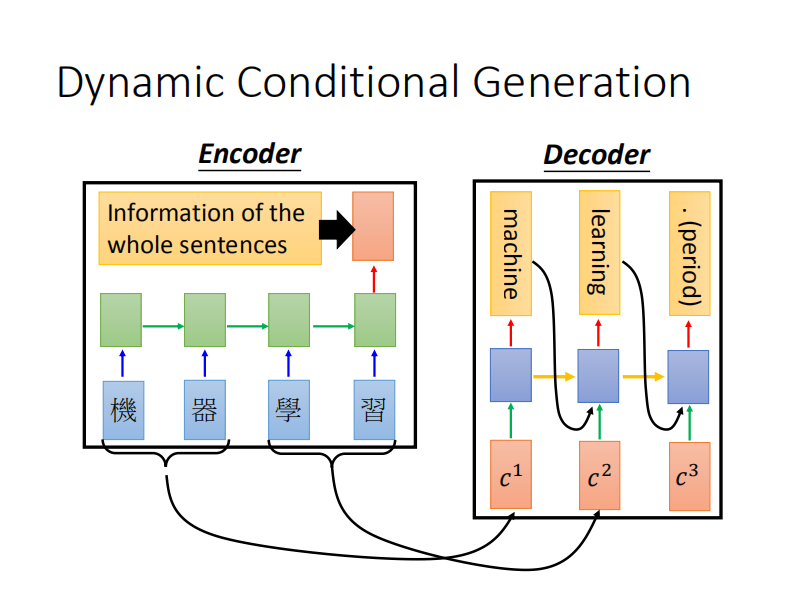
Seq2Seq
Seq2Seq表示模型输入一个序列,输出一个新序列。主要由Encoder于Decoder组成。
Encoder是一个多层的RNN结构,将输入序列投入Encoder中,最终产生一个向量,可以理解为将整个序列进行了学习得到了一个包含上下文信息的向量。
Decoder是RNN结构,从<START>开始逐个成分地生成序列。每个时间步t,Decoder接收Encoder产生的上下文向量与Decoder在(t-1)时刻的输出,产生t时刻的输出。通俗理解,Decoder需要知道整句话在说什么,并且自己刚刚说到哪里了,才能知道现在自己要说什么。
由于Encoder产生的中间向量——上下文向量在原始的Seq2Seq中是固定的,一个固定维度的向量很难一次性将整个输入序列的信息全部学到,为此引入了Attention机制来解决这个问题。
下图展示了一下student forcing下的Decoder\(^{[2]}\)。

Attention
引入了Attention机制后,Encoder不会只产生一个中间向量,而是会根据Decoder的在每一时间步t的输出再产生一个中间向量,同样这也是一个上下文向量,但是他更加注意了Decoder正在翻译的部分的上下文的信息,这样这个中间的上下文向量对于Decoder来说包含了更多的有效信息。通俗理解,Decoder翻译到哪里,Encoder就会给出那个地方附近的上下文。
beam-search
在Seq2Seq的student forcing时,如何选择生成的下一个元素是非常重要的策略问题,其中一种重要的方法是beam-search,在Seq2Seq模型进行test时几乎都要使用这个方法,所以在这里也顺便整理一下。
如果每一步都选择生成概率最大的元素作为输出,往往会陷入局部最优,难以保证全局最优,如果要确保全局最优,使用穷举的方法,会导致搜索空间指数级爆炸,难以实现。所以两者折中就产生了beam-search。
在beam-search中,要先指定超参数k,表示beam-search的宽度,在每一个时间步t,Decoder会选择当前累计的生成概率最高的前k个,用于下一个时间步的探索,最终在得到的全序列生成概率最高的k个中选择最高的那个进行输出。
\(P(t) = P(w_1)P(w_2|w_1)P(w_3|w_1,w_2)...P(w_{t}|w_{1},w_{2},...,w_{t-1})\)
如果输出是不定长的,会用平均每个元素的生成概率\(p(t)\)代替上述\(P(t)\)。
\(p(t)=\sqrt[t]{P(t)}\)
Coding
如果不需要了解细节,这一部分可以跳过。
以上对Seq2Seq和Attention的机制进行了一个宏观的概述,不同的实现中会遇到不同的细节,这里以李宏毅老师的机器学习中的版本为例,对细节进行一下梳理,以便coding的顺利进行n。
在李老师的PPT中可以找到上图的每一步的详细步骤,这里不再赘述。下面结合核心代码对过程进行详细的解读,一下是未使用attention与beam-search的原始版本:
class Encoder(nn.Module):
def __init__(self, en_vocab_size, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.embedding = nn.Embedding(en_vocab_size, emb_dim)
self.hid_dim = hid_dim
self.n_layers = n_layers
# 使用双向GRU作为Encoder的模型
self.rnn = nn.GRU(emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=True, bidirectional=True)
self.dropout = nn.Dropout(dropout)
def forward(self, input):
'''
@param: input (batch_size, sequence_len, vocab_size)
@return: outputs (batch_size, sequence_len, hid_dim * directions)
@return: hidden (num_layers * directions, batch_size, hid_dim)
outputs是最后一层RNN的全部输出(sequence_len),可以交给attention处理。双向的RNN需要把最优的outputs在hid_dim维度上进行拼接。
hidden是每一层(num_layers)最后时间步的隐藏状态,传递到Decoder进行译码。
作为decoder每一层的初始的h0,所以要求Encoder与decoder的layers相同,与seq_len无关
'''
embedding = self.embedding(input)
outputs, hidden = self.rnn(self.dropout(embedding))
# hidden才是最终投喂给decoder作为初始隐层 即一次性将上下文信息告诉decoder
# outputs用来计算上下文attention的
return outputs, hidden
Decoder 是另一个 RNN,在最简单的 seq2seq decoder 中,仅使用 Encoder 每一层最后的隐藏状态来进行译码,而这最后的隐藏状态有时被称为 “content vector”,因为可以想象它对整个前文序列进行编码, 此 “content vector” 用作 Decoder 的初始隐藏状态, 而 Encoder 的输出通常用于 Attention Mechanism。
如下的维度细节需要考虑明白。
Encoder中,在多层rnn中,outputs是最后一层所有时间步(seq_len)的“隐层”输出,hidden是所有层最后一个时间步的“隐层”输出。两者在维度上都有一个hid_dim信息。directions信息体现在不同的维度位置上。
Decoder的输出和隐层并不是RNN的输出与隐层,RNN中(c,h)h隐层也是rnn的输出,c使用用来传递的,Decoder的输出还需要对RNN的隐层进行进一步的加工(如加一个线性层等)得到符合我们要求的输出。
class Decoder(nn.Module):
def __init__(self, cn_vocab_size, emb_dim, hid_dim, n_layers, dropout, isatt=False):
'''
@param isatt: 是否使用注意力机制
'''
super().__init__()
self.cn_vocab_size = cn_vocab_size
self.hid_dim = hid_dim * 2
self.n_layers = n_layers
self.embedding = nn.Embedding(cn_vocab_size, config.emb_dim)
self.isatt = isatt
self.attention = Attention(hid_dim)
# 注意力机制下input拼接了上一个单词与注意力部分
self.input_dim = emb_dim + hid_dim * 2 if isatt else emb_dim
self.rnn = nn.GRU(self.input_dim, self.hid_dim, self.n_layers, dropout = dropout, batch_first=True)
# hid_dim --> cn_vocab_size
self.embedding2vocab1 = nn.Linear(self.hid_dim, self.hid_dim * 2)
self.embedding2vocab2 = nn.Linear(self.hid_dim * 2, self.hid_dim * 4)
self.embedding2vocab3 = nn.Linear(self.hid_dim * 4, self.cn_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs):
'''
batch_first == True
@param input(batch_size, vocab_size)
@param hidden(batch_size, n_layers * 1(directions), hid_dim)
t-1时刻decoder的隐层
'''
# Decoder是单向 directions为1 input要添加一个维度
input = input.unsqueeze(1) # input(batch_size,1,vocab_size)
embedded = self.dropout(self.embedding(input)) # embedded(batch_size,1,embed_dim)
if self.isatt:
attn = self.attention(encoder_outputs, hidden)
# 需要将attention部分与单词的embed进行拼接作为带有注意力的input
embedded = torch.cat((embedded,attn),dim=2) #embedded(batch_size,1,embed_dim + hid_dim*2)
output, hidden = self.rnn(embedded, hidden) # output(batch_size,1,hid_dim)
# hidden(num_layers*1,batch_size,hid_dim)
output = self.embedding2vocab1(output.squeeze(1))
output = self.embedding2vocab2(output)
prediction = self.embedding2vocab3(output) # 转为在不同的词的概率分布 prediction(batch_size,cn_vocab_size)
return prediction, hidden
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
# 直接将Encoder的隐层喂给decoder的隐层
# encoder的所有层的最后step成为decoder的第一个step
assert encoder.n_layers == decoder.n_layers, "Encoder and decoder must have equal number of layers!"
def forward(self, input, target, teacher_forcing_ratio):
'''
@param input (batch_size, input_len, vocab_size)
@param target (batch_size, target_len, vocab_size)
@param teacher_forcing_ratio 使用teacher forcing的几率
'''
batch_size = target.shape[0]
target_len = target.shape[1]
vocab_size = self.decoder.cn_vocab_size
outputs = torch.zeros(batch_size, target_len, vocab_size).to(self.device)
encoder_outputs, hidden = self.encoder(input)
# (num_layers * directions, batch_size, hid_dim)-->(num_layers, directions, batch_size, hid_dim)
hidden = hidden.view(self.encoder.n_layers, 2, batch_size, -1)
# 将directions拼接到最后一个维度
hidden = torch.cat((hidden[:, -2, :, :], hidden[:, -1, :, :]), dim=2)
input = target[:, 0]
preds = []
for t in range(1, target_len):
# target_len范围内
output, hidden = self.decoder(input, hidden, encoder_outputs)
outputs[:, t] = output
teacher_force = random.random() <= teacher_forcing_ratio
top1 = output.argmax(1)
input = target[:, t] if teacher_force and t < target_len else top1
preds.append(top1.unsqueeze(1))
preds = torch.cat(preds, 1)
return outputs, preds
def inference(self, input, target):
batch_size = input.shape[0]
input_len = input.shape[1]
vocab_size = self.decoder.cn_vocab_size
outputs = torch.zeros(batch_size, input_len, vocab_size).to(self.device)
encoder_outputs, hidden = self.encoder(input)
hidden = hidden.view(self.encoder.n_layers, 2, batch_size, -1)
hidden = torch.cat((hidden[:, -2, :, :], hidden[:, -1, :, :]), dim=2)
input = target[:, 0]
preds = []
# input_len范围内
for t in range(1, input_len):
output, hidden = self.decoder(input, hidden, encoder_outputs)
outputs[:, t] = output
top1 = output.argmax(1)
input = top1
preds.append(top1.unsqueeze(1))
preds = torch.cat(preds, 1)
return outputs, preds
Attention实现
如下来自于作业8的指导书:
- 当输入过长,或是单独靠 “content vector” 无法取得整个输入的意思时,用 Attention Mechanism 来提供 Decoder 更多的信息
- 主要是根据现在 Decoder hidden state ,去计算在 Encoder outputs 中,那些与其有较高的关系,根据关系的数值来决定该传给 Decoder 那些附加信息
- 常见 Attention 的实现是用 Neural Network / Dot Product 来算 Decoder hidden state 和 Encoder outputs 之间的关系,再对所有算出来的数值做 softmax ,最后根据过完 softmax 的值对 Encoder outputs 做 weight sum。
加权求和体现出了注意力在原序列上的差异性分布。
class Attention(nn.Module):
def __init__(self, hid_dim):
super(Attention, self).__init__()
self.hid_dim = hid_dim
def forward(self, encoder_outputs, decoder_hidden):
# encoder_outputs = [batch_size, sequence_len, hid_dim * directions]
# decoder_hidden = [num_layers, batch_size, hid_dim]
# 一般来说取 Encoder 最后一层的 hidden state 来做 attention
# ...
return attention
再捋一下注意力,很棒的思路,就是有点绕...
attention 原理实现过程\(^{[4]}\):
a. 初始化decoder的隐藏状态 z0
b. 计算attention权重:隐藏状态和和encoder的outputs计算(余弦,DNN,矩阵)出的结果进行sofamax之后得到attention weight
c. 得到context vector:attention weight 和 encoder outputs 计算得到
d. attention的最终结果:前一次的输出和context vector 进行concat,经过形状变换和tanh的处理后作为当前时间步的输入
e. decoder当前时间步会把attention的最终结果作为输入,还会把前一次的输出zi作为隐藏状态输入
参考文献
[1] https://blog.csdn.net/weixin_41041772/article/details/88032093
[2] http://karpathy.github.io/2015/05/21/rnn-effectiveness/
[3] https://zhuanlan.zhihu.com/p/32085405
[4] https://blog.csdn.net/weixin_44799217/article/details/115840569

