
面向对象第三单元JML系列总结
前言
本单元作业难度较前两个单元低了许多,加上五一假期停了一次作业,给了自己一个充足的缓冲时间,总体来看本单元算是过的比较轻松。JML规格非常严谨,但是可读性比较差,需要花费大量时间读JML,而且还要多次阅读,才能发现自己在一开始理解上的错误。本单元作业写代码花费的时间并不是很多,但是给我最大的感觉是非常“熬”。首先,自己没有算法基础,对于部分图论算法,是在自己迷迷糊糊的状态下比着网上的资料仿写的,自己在算法上并没有十足的正确性把握。其次,JML细节非常多,本次作业对性能有一定的要求,我花了很多时间写测评程序,发现写测评比实际作业还要难。最后,讨论区对JML的改动非常频繁,需要经常关注讨论区修改JML的消息。总的来说,这一单元接触了契约式编程,了解了JML,还是很有收获。
总结分析自己实现规格所采取的设计策略
本单元作业没有需要自己设计的宏观架构,主要在于每个方法要严格满足JML。本次作业中,我都是先通读完所有JML再进行动笔,对需要使用的数据结构与算法做到心中有数,接下来在实现的过程中才不会遇到过多的困难。从规格到实现的过程中,我的设计策略基本如下:
①代码实现一定要严格符合规格。分支一定要覆盖全,如果发现JML中分支的逻辑覆盖并不全,则还是要对分支条件进行判断,而要避免直接使用else,要考虑到JML书写者可能书写不规范的情形。实现的时候一定按照JML的描述实现,例如平均数与方差的计算中,尽量按照JML的描述进行,否则可能会出现java取整的误差导致错误。自己等价变形时要推理一遍是否会改变正确性,如果确定不会改变正确性再作等价变形。
②评估规格的复杂度,如果复杂度过大要考虑更换数据结构与算法。例如规格描述中大多使用数组与循环,部分方法在规格中的复杂度是O(n^2),这样的复杂度显然过高,需要进行适当的优化。
结合课程内容,整理基于JML规格来设计测试的方法和策略
JML是测试的抓手,可以让我们对每个方法有的放矢地进行测试。本单元我主要进行三个方面的测试:根据JML对方法进行覆盖性测试,针对自己程序独有的部分进行重点测试,对拍。
根据JML对方法进行覆盖性测试
这一部分测试主要通过单元测试进行。根据JML中各个正常与异常的分支书写相应的条件。比较麻烦的是,测试要使用自己的数据结构将社交网络进行一定的初始化,由于是手动构造的,往往比较简单,强度不够。有的方法内部会调用更加原子的方法,所以在单元测试时要注意顺序,先对原子方法进行测试,然后逐层的测试方法。
第二次作业中,我在平均数计算的时候遗漏了除0要特判的情况,通过单元测试找到了这个bug,避免了强测中悲剧的产生。
针对自己程序独有的部分重点测试
自己的程序中要服务于特定的数据结构与算法还会添加部分新的类与方法,此时没有JML可以使用了,当然如果是大佬也可以自己先写,我通过要实现的功能进行检查,如我实现了基于rank的路径压缩的并查集,所以我在新的类中通过全局JML再写自己添加的方法debug开关与print(),对程序执行到的各个地方进行输出,如输出当前各个节点的根节点编号,各个节点的rank值等。通过全局变量debug进行控制可以很好地控制调试输出,以防忘记删除导致强测出锅。网上学习到更好的方法是封装一个debug类,实现类似于print的接口,让调试程序也变得模块化。
对拍
对拍使用的数据也并不是随机生成的数据,我使用的数据综合了JML中的各个分支,并对可能出现错误的地方进行了预测并生成边界数据。以第三次作业的数据生成器为例,由我和几个朋友分工合作完成。其中一名同学负责对异常进行全覆盖,另一名同学负责对第三次作业中新添加的集中消息类型emoji、redEnvelope、notice的操作进行检查,我负责最短路径相关数据的构造。
我使用python生成数据,考虑了如下几种情况:在同一个连通分量的两个人之间addRelation,在不同的两个连通分量的两个人之间addRelation,先addRelation再sendIndirectMessage,addRelation与sendIndirectMessage交替进行,稀疏图与稠密图,重复查询与非重复查询等。
为提高测试数据的质量,我在python中将不同的连通分量用list维护起来,可以有针对性的区分添加关系的不同情况,在数据产生的过程中,逐步控制连通分量的数目使其不断减少,增加每个连通分量的稠密程度。
本次我构造的数据有一定的强度,成功帮助一名同学找到了最短路径计算中的一个bug,让另一名同学因为没有对迪杰斯特拉进行优化超时。
总结分析容器选择和使用的经验
容器是java中重要的数据结构,相较于数组,容器提供了非常简洁明确的使用接口,只要保证按照正确的方法使用容器,可以更加轻松的实现自己想要的功能,并且大大减轻了自己维护的成本。本单元主要使用了HashMap、ArrayList、HashSet容器,这里HashMap、ArrayList、HashSet、LinkedList进行梳理。
HashMap
HashMap类型主要适用于拥有映射关系的数据,利于Person的id与Person对象的映射等,方便根据其中一个值快速到找到另一个值,时间复杂度接近O(1)。如果要实现双向互查,则需要维护两个HashMap。要注意的是如果用作HashMap键值的是java中定义好的类,则直接使用即可,如Integer等,但是如果使用自定义的类,则需要重写equals方法与hashCode方法,要满足eqauls结果为true的对象要有相同的哈希码。HashMap中许多操作都是基于这两个方法的,如containsKey、get等。
HashSet
HashSet与HashMap非常类似,可以认为是一种一维的HashMap。HashSet用来存放不能重复的元素,而且查询的时间复杂度接近O(1)。通常适用于存储互异的元素并且后面有“查询元素是否在集合的操作”。如本单元作业中,在使用迪杰斯特拉算法求最短路径时,要记录已经访问过的Person的id,此时使用HashSet存储调用contains()方法可以实现。
ArrayList
ArrayList是历次作业中最常使用的容器,ArrayList可以当成可变长数组来使用,其随机访存效率高。如果数据的长度需要动态的变化,而且需要遍历操作,使用ArrayList是不错的选择,非常简单。
LinkedList
LinkedList和ArrayList都实现了List接口,所以两者的功能十分相似。两者的内部实现机制有所不同。ArrayList是动态数组的数据结构,LinkedList是链表的数据结构。ArrayList的随机访存效率高,而LinkedList的数据插入删除效率高,所以程序中插入删除操作比较多时,可以选择LinkedList;访存操作比较多时,可以选择ArrayList。
针对本单元容易出现的性能问题,总结分析原因
本次单元可能出现的性能问题可能有如下几点:
第一次作业
NetWork中isCircle使用dfs,queryBlockSum方法直接根据JML写双重循环会导致复杂度过高,而且注意到queryBlockSum根据规格调用了isCircle方法,会如果isCircle方法复杂度过高,也会增大queryBlockSum的方法复杂度。
第二次作业
Group类中getValueSum、getAgeMean与getAgeVar按照规格写分别是O(n^2)、O(n)、O(n)复杂度,可能会超时。
第三次作业
NetWork中sendIndirectMessage中查询最短路径如果使用朴素迪杰斯特拉算法可能会超时,deleteColdEmoji中如果没有选取更加高效的数据结构,要遍历emojiList与messages两个数组,可能会超时。
本单元我的程序没有因为性能较差被卡,主要原因有如下:
①考虑到方法内部仍然可能会调用别的方法,所以在评估方法复杂度时,我没有忽视这一点,对于复杂度较高但是还在其他方法中被频繁调用的方法,我对其性能进行了重点的优化。
②查阅了许多算法方面的资料,自学补充了许多算法知识,例如并查集、堆优化的迪杰斯特拉等,对于能优化的方法做到尽可能的优化。
③充分利用了缓存的思想,通过空间换取时间,如对已经计算出的最短路径长度进行缓存。
我主要采取了如下具体措施来提高我的程序性能:
第一次作业
第一次作业难点就在于连通性问题,我实现了并查集类UnionSet,并且实现了基于rank的路径压缩,使路径尽可能平衡且比较短。
第二次作业
第二次作业主要通过缓存解决需要遍历的问题,所以我在MyGroup类中维护了valueSum、ageSum、ageSumPower,分别缓存当前状态下group的value和、年龄和、年龄的平方和。并在类的更新操作下对缓存量进行更新。其中关于方差的计算需要对数学公式进行等价变形才能够使用年龄和缓存实现O(1)的复杂度。缓存的维护提高了编程的难度,因为很多操作都会对缓存量造成影响,有时可能类外部的某个操作都会对缓存量造成影响,维护难度增大,并且类与类之间的耦合度增大,不太符合面向对象的思想,但是这里考虑到对性能提高的巨大作用,也是进行了一个trade off。在缓存group的valueSum时,除了group类内部addPerson与delPerson会影响缓存,Network类中addRelation也要对valueSum进行更新,此时要遍历所有的组,可以看到缓存减少了一种时间开销,但是也可能会带来新的时间开销,所以要具体问题具体分析,在本次作业中,由于group的数量不会超过10,所以权衡之后缓存仍然能够起到正面的作用。
第三次作业
第三次作业针对最短路径,我采取了堆优化的迪杰斯特拉算法,使用了PriorityQueue,新建了一个Pair类实现了Comparable<Pair>接口,重写了CompareTo方法,得到了一个小根堆。
另外,我采取了按PersonId缓存的方法,因为最短路径上任意两点之间也是最短路径,这样珍贵的信息如果不缓存着实有些可惜。于是我将计算src到dst最短路径的过程得到的其他的最短路径(src到沿途各点的最短路径)保存下来,以供后面的查询。我使用了HashMap<Integer src,HashMap<Integer dst,Integer minPathLength>>来进行缓存,表示以src到各个dst的最短距离。
addRelation时需要更新最短路径缓存,但是不必全部清除。如果addRelation(id1,id2)中的id1与id2在同一个连通分量i中,只需要把连通分量i中的最短路径缓存清楚,其余的不需要清楚。这一点很容易证明其正确性。同理,缓存减少了后期可能的求解最短路径的时间开销,但是addRelation中需要有选择地清除缓存,这也会带来额外的开销。起初我按照(id1,id2):minPathLength的结构进行缓存,表示id1 id2之间的最短距离,这样在更新缓存时遍历的数据规模较大,很难体现缓存的优势。由于迪杰斯特拉是单源最短路径算法,得到的最短路径有源头id相同的数据特征,于是我再缓存时也利用了这一点,采取按照src来缓存一个最短路径簇,降低了更新缓存时遍历的规模,很好地发挥出了缓存的优势。
deleteColdEmoji中我在MyNetwork中建立了一个新的数据对象,HashMap<Integer,HashSet<Integer>> emojiId2Ids,用来存储emojiId到多个(message)id的映射,如此确定了要删除的emojiId之后,可以直接找到对应的(message)id进行删除,但是emojiId2Ids需要addMessage、sendMessage、sendIndirectMessage中维护,维护操作比较繁琐但是并不会增加较高的复杂度,发挥出了缓存的优势。
梳理自己的作业架构设计,特别是图模型构建与维护策略
以第三次作业为例,如下是类图,由于本次作业的框架已经由课程组提供,异常类设置好静态计数变量并且注意好异常输出的格式即可。自己实现的类继承/实现课程组的类或接口,MyEmojiMessage MyNoticeMessage MyRedEnvelopeMessage继承MyMessage,实现代码的复用。
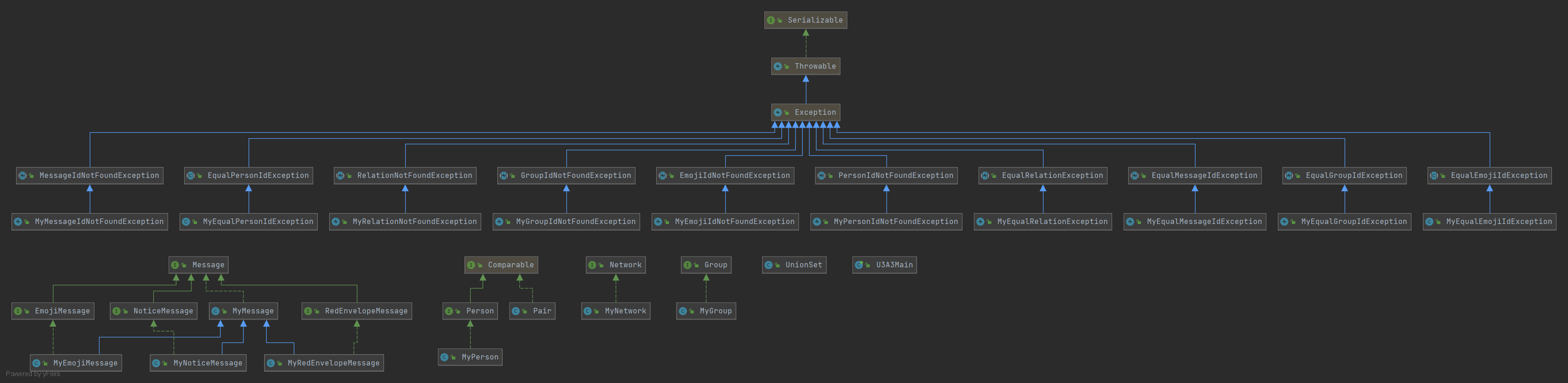
从类图中可以看出,本次作业有Network Group Message Person四个板块。这四个我认为称之为板块较之于层次更加合适,因为除了Network是总体的管理类,其余的三个分别储存着相对独立的数据,完成相对独立的功能。
从抽象角度看,图是<V,E>的集合,在本次作业中,Person和Value基本上对应于点集与边集。
我的作业中,图模型的构建,主要完成的是将图的数据分到不同的模块,每个模块维护好自身的部分,然后考虑模块与模块之间的相互作用。模块内部的管理,要对常用的数据进行缓存,根据数据管理的需要添加合适的方法,并向外提供更新与查询的接口。
模块的拆分一部分源于图这个数据结构本身,另一部分来源于客户的需求。前者主要实现功能的内聚,后者主要实现特定数据的内聚。例如研究图的连通性问题,就会存在连通分量问题,于是我专门抽象出并查集类UnionSet对图的连通性问题进行维护,在这个类中,对连通分量的数目,各个节点的祖先节点等数据进行了缓存与维护。其余的如Group类则是属于客户需求造成的类,并不与图的本质属性相关联,它将图中的特定节点割裂出来,单独维护部分性质,如valueSum,ageSum等,这些需要我们缓存下来。
几种不同的Message代表着图中节点与节点之间的相互作用的媒介,所以需要节点Person与NetWork类进行管理,Message的传递是一种对节点属性的修改,NetWork类需要发送消息时,需要对Person的属性进行修改,所以在Person中需要提供对外的修改属性的接口。
由于对数据和功能进行了拆分,Network类只需要存储宏观的属性与(UnionSet)Persons Message[] Group[]等,具体的操作则是Network中找到特定的模块,操作这个模块提供的更新或查询接口实现。实现了功能与数据的拆解。
最短路径这一部分也属于图这个数据结构与生俱来的一种功能模块,更好的做法应当是再专门抽象一个类ShortestPath,由这个类向外提供查询最短距离的接口,并且管理最短路径的缓存数据同时向外提供一个更新操作的接口,根据外界传递进来的信号进行缓存的更新。本次作业的不足之处是将这个最短路径模块作为一个方法写入到Network中,使得Network类不够简洁。
感想
JML是非常强大的工具,通过规格实现了设计与实现的分离,规约连接了需求与实现,书写JML只需要对前置条件、后置条件、副作用以及不变式进行约束,在顶层将实现的功能用数理逻辑进行精确的描述。有了JML规格,实现层面只需要满足规格约束即可。实现时也可以按照单元来进行实现,而不需要关注全局,这一点较之于前两次作业感受明显。前两次作业书写每个方法时都要适时考虑是不是满足整体的架构,是不是能够很好地与其他类与方法交互,极大地增加了开发的难度。而这一次作业时,大部分方法书写时只需要关注一个局部即可,JML将谋篇布局与具体实现分离开来。
JML的可读性是在太差,本单元的作业起初都是硬着头皮读完JML的,通常我还会使用自然语言对JML进行翻译,以减轻第二天阅读JML的难度。这样确实减轻了后面的劳动量,但是也会有一个问题,一旦前面的理解出现偏差,后面很难进行纠正,所以还是要培养自己阅读JML的能力。
JML可以很严谨,但是要想写出严谨的JML是非常困难的事情,每次作业讨论区都会有大量的JML更新,需要时不时进行修补,非常“熬”。JML有较为成熟的工具链,比较遗憾本次作业没有练习使用JML相关工具链,以后还可以对这一部分进行更加深入的学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号