java集合 List Set Map
1 说明
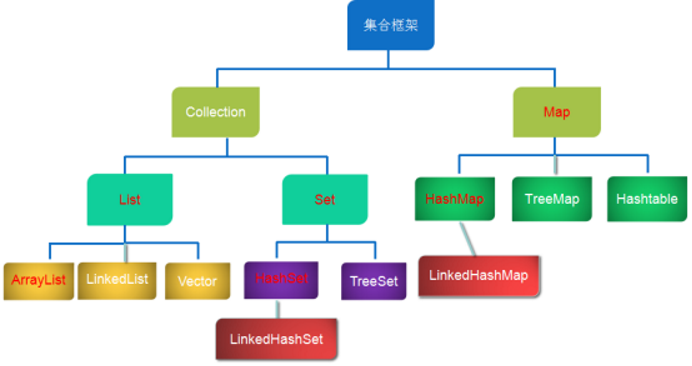
①、Collection:是list和set的根接口(即纯粹的抽象类,不能直接new对象),存储的是单值(区别于Map储存键值对)
②、Map:也是一个接口, 存储的是key-value键值对
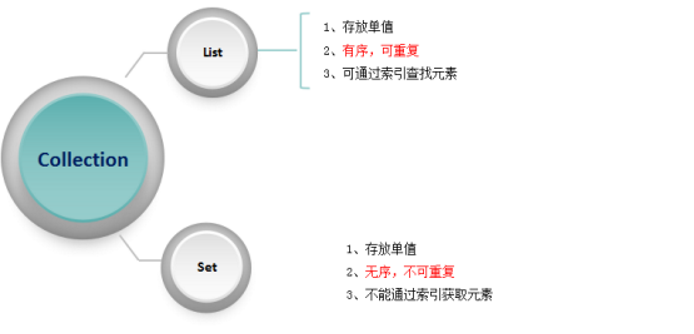
③、List:列表,也是一个接口, 存储的是单值,允许重复、有顺序,所以通过索引来取值 --> 底层类似于数组
④、Set:集 ,也是一个接口, 存储的是单值,不允许重复,没有顺序,不能通过索引来操作
2 List
2.1 综述
List作为接口 有三种实现类

| 常用实现类 | 新增/查询/删除 | 底层数据结构 |
|---|---|---|
| ArrayList |
查询最快 | 动态数组 |
| LinkedList |
新增/删除最快 查询慢 | 双向链表 |
| Vector |
三者都慢 | 动态数组 |
2.2 ArrayList
ArrayList 我们常说的动态数组,ArrayList的底层是数组 之所以是动态的,是因为底层会自动的根据元素个数进行容量变动,同时在不指定元素的数据类型时,可以储存多种类型的数据
ArrayList作为List的实现类 底层又是数组,所以具有索引,因此在快速访问和遍历元素方面性能优秀
2.3 ArrayList的扩容机制
前面提到了ArrayList的底层是数组,因此ArrayList的扩容机制就是依靠Arrays.copyOf()实现的 但是在具体的判断上要说明一下:
当ArrayList创建出来时,如果给了初始容量,那么就会有一个初始容量

如果没有设置 那么初始容量就默认为10
容量设置发生在第一次添加数据前 接着就是根据代码不断向其中添加数据
当第10次添加数据时,整个ArrayList就被填满了
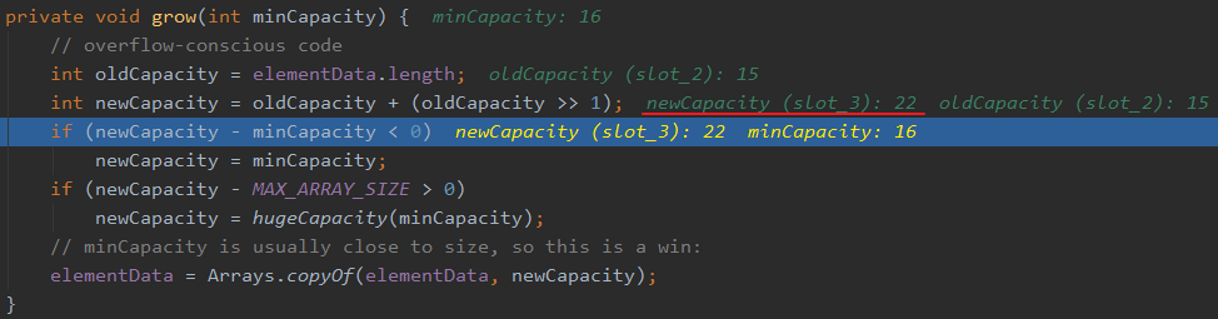
此时如果继续添加 那么在第11次添加数据前,系统就会自动对ArrayList进行扩容:

从代码可以看出新的容量是原有容量的1.5倍 因为 变量>>1 代表着数据除以2
在上次扩容后,新容量为15,那么在第16次添加数据时底层又会在原15的容量上扩容1.5倍 然后向下取整
以后的趋势是越扩容越大(底数越来越大 扩容1.5倍不变)
2.4 LinkedList
LinkedList 的底层实现是双向链表,这就使得LinkedList有了链表结构的一些特性
链表中元素的数量不受任何限制,可以随意地添加和删除,在添加和删除时只会影响相接的两个元素
因此与ArrayList相比,如果需要频繁地添加和删除元素,LinkedList的性能更加优越,而由于LinkedList又作为AbstractSequentialList类的子类,并实现了List接口,因此又能使用“索引”
但这不是真正的索引,所以链表查询数据会比较慢
特点:“查询效率低,增删效率高,线程不安全”
2.5 LinkedList有索引 为什么查找还会慢
这是因为该索引非彼索引
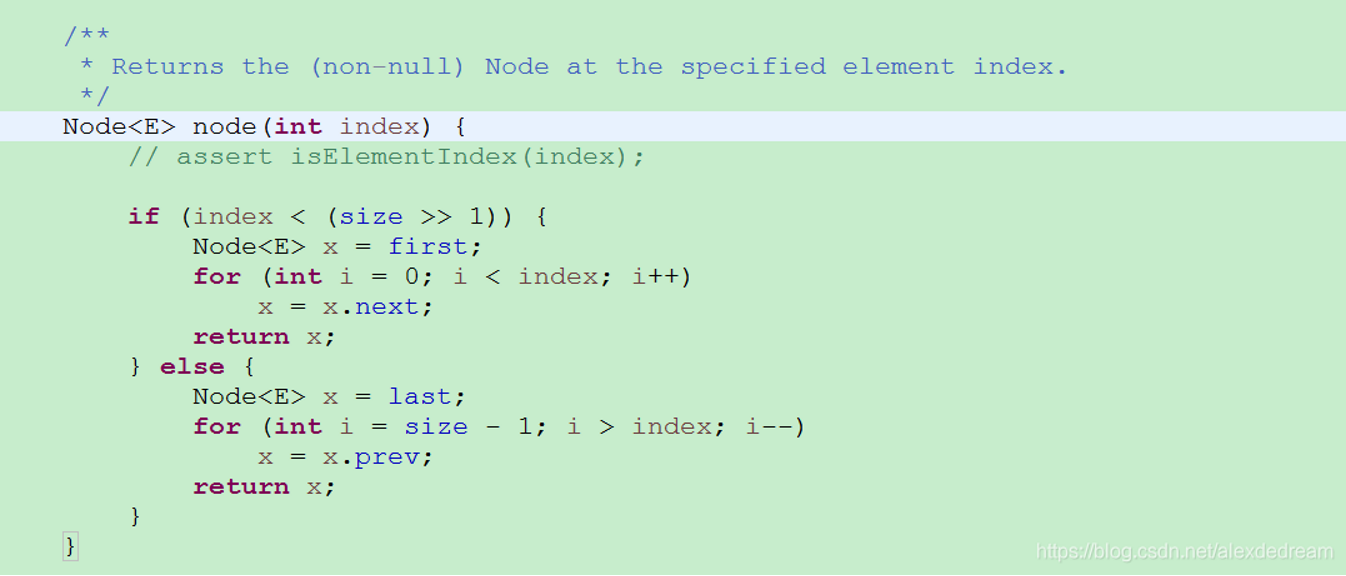
查看源码可以知道 LinkedList根据索引进行的操作都是,每一次for循环增加一次索引变量,然后返回item,不断循环下找到数据
而非真的根据索引直接找到对应元素。
假如集合size=100,要取index=40的元素,根据源码,100>>1=50,40<50,需要从前往后循环,循环40遍取出node.item.
如果正好取中间那位或者排后面的,则从后往前循环,直到找到该元素,所以LinkedList查找数据很慢,核心原因是用了循环去寻找数据。
3 set
3.1 综述
Set即集,作为Collection的子接口,与List相对,特点是元素不重复、无序、无索引
Set底层实现靠的是Map,实际存储了Key,所以无顺序且不可重复

3.2 hashset
作为Set接口的实现类,HashSet也要求元素不可重复,同时元素之间是无序的,输入的顺序和输出的顺序并没有关系,同时HashSet允许空对象的存在,但是只允许存在一个
HashSet的底层实现靠的是HashMap
3.3 LinkedHashSet
作为HashSet的子类,方法与父类几乎一模一样,不同的是元素是有序的,元素的插入顺序与遍历顺序一致
与HashSet一般,底层都是由HashMap实现
3.4 TreeSet
作为Set的一个实现类,与HashSet不同之处在于TreeSet采用的是红黑树数据结构,因此会默认对存入其中的元素进行排序
TreeSet的这种默认排序的特性就要求TreeSet的元素必须实现Comparable接口即重写了CompareTo()方法
如果是基本数据类型中数值类型的封装类(包裹类型) ,那么不用担心,这个接口都是实现了的
如果是自己定义的类,例如User、Person等等,那么就需要重写CompareTo()方法,也就是指定一个成员变量作为排序的依据,否则TreeSet就不允许该数据存入
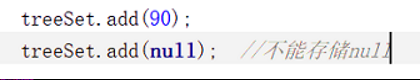
4 map
4.1 综述
Map存储的都是一一对应的键值对,Key不能重复,Value可以重复,每个Key最多映射一个值Value。
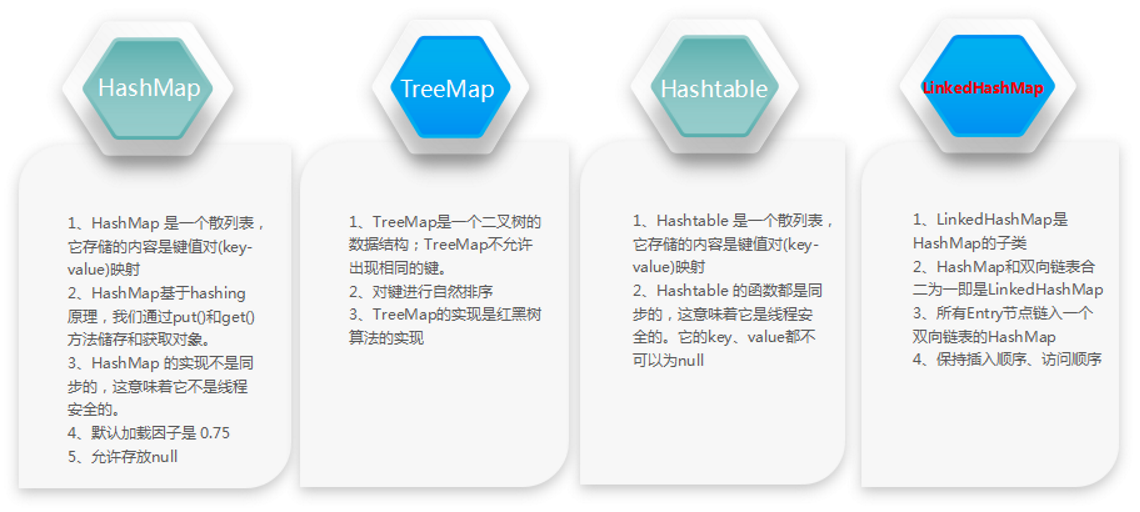
Map作为接口不能直接穿件对象,它下面有四种实现类
Map的实现类的比较
| 实现类 | 底层数据结构 | 线程是否安全 | K与V是否可以为null |
|---|---|---|---|
| HashMap<K,V>(推荐) | hash表 | 否 | K和V 都可以为null |
| LinkedHashMap<K,V> | 链表+hash表 | 否 | K和V 都可以为null |
| TreeMap<K,V> | 红黑树 | 否 | K不可以为null , V可以 |
| CouncurrentHashMap<K,V>(推荐) | 1.7 锁分段 1.8 CAS | 是 | K和V都不可以为null |
| HashTable<K,V> | hash表 | 是(同步) | K和V都不可以为null |
4.2 HashMap
HashMap是Map下的一个实现类,并且允许出现null键和null值,与Map一样,key不能重复,value可以重复
key和value可以是任意类型,但一般情况建议key:String value:Object
如图创建了一个HashMap 其中K为字符串类型 V为对象类型 初始容量为20
在没有指定容量时,HashMap的默认容量为16,默认负载因子为0.75 也就是说当数据超过16*0.75=12个时,HashMap就会自动进行扩容,新的容量为旧的容量的2倍

4.3 LinkedHashMap
LinkedHashMap是HashMap的子类,两者的功能方法几乎一致。
LinkedHashMap元素可以记录key录入的顺序,令key的录入顺序与遍历顺序一致。
4.4 TreeHashMap
TreeMap的key值有序,按照自然顺序对key进行排列,因此要求key的类型一定得实现Comparable接口 重写了compareTo()方法
TreeMap的方法与另外两个实现类相同
4.5 ConcurrentHashMap
https://www.cnblogs.com/jxxblogs/p/12517197.html
https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw
有了HashMap 还产生了HashTable 是因为后者能实现线程同步 保证线程安全,但是后者基本不用 因为效率很低,取而代之的是ConcurrentHashMap,作为线程安全的HashMap ,它的使用频率也是很高,这个新的类型提出了一个“段”的概念,通过分段来保证线程安全与效率并举。
在多线程环境下,使用HashMap进行put操作时存在丢失数据的情况,为了避免这种bug的隐患,强烈建议使用ConcurrentHashMap代替HashMap。
总之 以后在多线程要使用Map时 推荐用ConcurrentHashMap
ConcurrentHashMap相对于HashMap效率提升了N倍(HashMap的容量倍数),至少16倍(HashMap初始容量16)
5 总结
【1】集合根类:
①、Collection和Map --> Object
②、Collection:存储的是单值! --> List和Set
③、Map:存储键值映射!
【2】List:列表。 --> 存储的是单值! 有顺序,允许重复!
①、ArrayList:
1.1:实质是一个动态数组!--> 容量会随着数组的数据增多或减少来自动设定大小!--> 查询速度会比较快。 删除:找到该索引然后将索引后的所有数据依次往前覆盖!
1.2:常用方法:add、 remove 、get(索引)、set、for循环、迭代器
1.3:ArrayList底层如何实现自动扩容?
1.3.1:创建了一个空的集合!
1.3.2:第一次添加数据的时候:会给集合分配一个默认的容量。 10
1.3.3:从第一次添加到第十次,当添加到十一的次时候:当数组的存满的时候,会进行扩容操作。 --> 按照1.5倍来进行扩容操作!
②、LinkedList:
2.1:实质是链表数据! --> Node fisrt ; Node last; --> Node{prev item next}
2.2:常用方法:围绕first和last --> addFirst removeFirst getFirst
2.3:优点:删除、添加都会很快! --> 删除操作影响前后!
③、Vector:-->保证线程安全! 如果在多线程中,要求每个线程之间单独互相不影响的时候!
【3】Set:集。 --> 底层实际是Map。实际中存储了Key。 无顺序,不可以重复!
①、HashSet。
②、LinkedHashSet:存储是按照插入的顺序!--> 根据key来排序!
③、TreeSet:存储是自然顺序!--> 存储的对象必须实现一个接口:Compable --> 重写compareTo
【4】Map:
①、HashMap:
1.1:存储键值一一对应!键是不可以重复的,是唯一的!而值是可以重复的!
1.2:常用方法:put(k,v) remove(k) get(k) repalce(k)
1.3:HashMap底层:
1.3.1:是Node数组+单向链表!
1.3.2:创建一个空的集合。 当第一次添加数据的时候,给node数组设定一个初始容量!
1.3.3:通过hash值和数组长度来计算出对应的索引,然后索引来存储!
1.3.4:当node数组存储到负载因子(默认是0.75,长度为12)对应的容量,进行扩容操作! --> 是按2倍的容量来进行扩容操作!
②、LinkedHashMap:根据插入的顺序!
③、TreeMap:根据key来按照自然顺序排序!
④、HashTable:保证线程安全!效率会非常低!
⑤、ConcurrentHashMap:保证线程安全!加了一个段!-->效率提高了N倍,最少是16倍!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号