编写复杂的sql语句要掌握的知识
1 基础sql
增
INSERT INTO 表名 VALUES(第一列对应数据, '第二列对应数据');

删
删除符合指定条件的所有数据
Delete from 表名 where条件

改
使用update关键字
修改表中某一列的所有值为指定值
Update 表名 set列名=新值;

修改符合指定条件的所有数据为指定值
Update 表名 set列名1=新值,列名2=新值 where 用作条件的列名=用作条件的值;

查
Select * from 表名 where 条件;
查询并按照给定顺序展示指定列:
将查询条件中的*改为 列名1,列名2,列名3 即可 如果选择了多列,那么列与列之间用逗号隔开,并且列名都可以通过空格“ ”或则“as”起别名

2 常用的查询的复杂字段
2.1 where子句的条件
https://blog.csdn.net/axl19530209/article/details/43950953
| 类别 | 运算符 | 说明 |
|---|---|---|
| 比较运算符 | =、>、<、>=、<=、<>、!= | 比较两个表达式 |
| 逻辑运算符 | AND、OR、NOT | 组合两个表达式的运算结果或取反 |
| 范围运算符 | BETWEEN、NOT BETWEEN | 搜索值是否在范围内 |
| 列表运算符 | IN、NOT IN | 查询值是否属于列表值之一 |
| 字符匹配符 | LIKE、NOT LIKE | 实现模糊查询,字符串是否匹配 |
| 判空运算符 | IS NULL、IS NOT NULL | 查询值是否为NULL |
- 字符串利用=判断是否相等 而且字符串可以用单引号或双引号引起来
利用!=和<>可以表示不等于
利用>=和<=可以表示大于等于和小于等于
- 日期可以直接进行比较,2021-5-1小于2021-6-1

-
between and 表述的是闭区间
-
利用 and or时 不能直接在两侧接值 都得有属性=值 构成完整语句
-
and优先级比or大,在混用操作符时想执行and,后面执行or
select * from 表名 where 条件1 and 条件2 OR 条件3 and 条件4;
上述sql语句会查找同时满足条件1和条件2的数据以及同时满足条件3和条件4的语句,等价于
select * from 表名 where 条件A OR 条件B;
-
or表示对两个结果集取合集,会去重,当条件里有or时,经常会改写成union
-
只有查询出来的数据 不确定具体数量 才用in
明确知道查询的数据时 不要用in 而是用or 这样能提升数据库性能 因为in可以理解为多重循环 所以很占资源

- 使用where A in B时,如果B是一张n行m列的表,那么A可以由m个属性构成的单行矩阵来对应
例如这个实例:
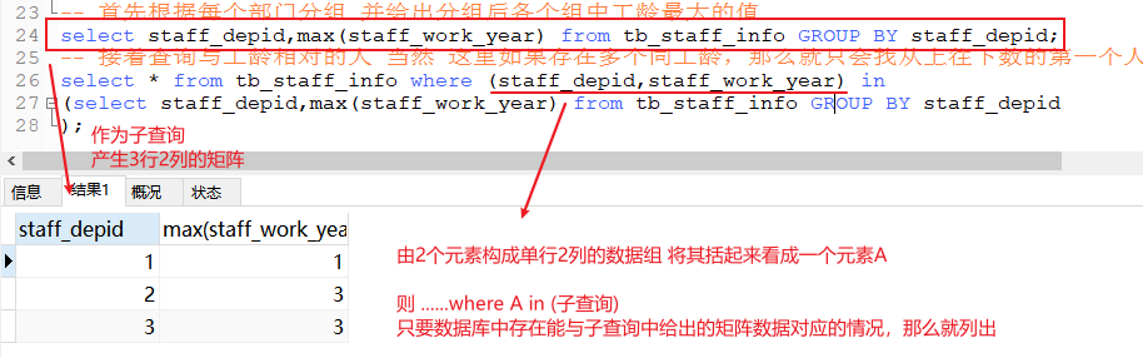
- 如果字段是char和varchar型,用等号判断会比较好;如果是int型,用ISNULL判断比较好
2.2 去重复distinct 列名
使用distinct 将指定的列中不相同的数据展示出来
如下图,对员工信息表使用,每个员工都有自己对应的部门编号,最后去重复后就能获得一个单列多行矩阵,展示数据库中该列不重复的数据

distinct还能在聚合函数中使用
select count(字段A)/count(distinct 字段A) from 表名
2.3 模糊查询 like
使用关键字 like
配合表示存在0个或多个其他数据的字符 %
配合表示占位符的下划线 _ 一个下划线对应一个任意字符
表示字符串可以用单引号 也可以用双引号
Select * from 表名where 列名 like 条件;


2.4 排序order by 列名 asc/desc
2.4.1 简单 根据单列排序
Select * from 表where 条件 order by 列名 desc/asc
这里desc表示降序 asc表示升序 不指定时默认为asc
如果不指定条件 即没有where 条件 即不筛选数据 那么就是对全表的数据进行排序

筛选数据后,在筛选的结果上进行排序:

2.4.2 复杂 根据多列排序
如果要求整个表先按照列1升序,再按照列2降序,那么可以用order by 列1 排序方式,列2 排序方式......
多列之间逗号隔开,每列后接排序方式,列与列之间存在先后顺序
select * from 表名 order by 列1 asc,列2 desc;
实例:
按照gpa、年龄降序排序输出
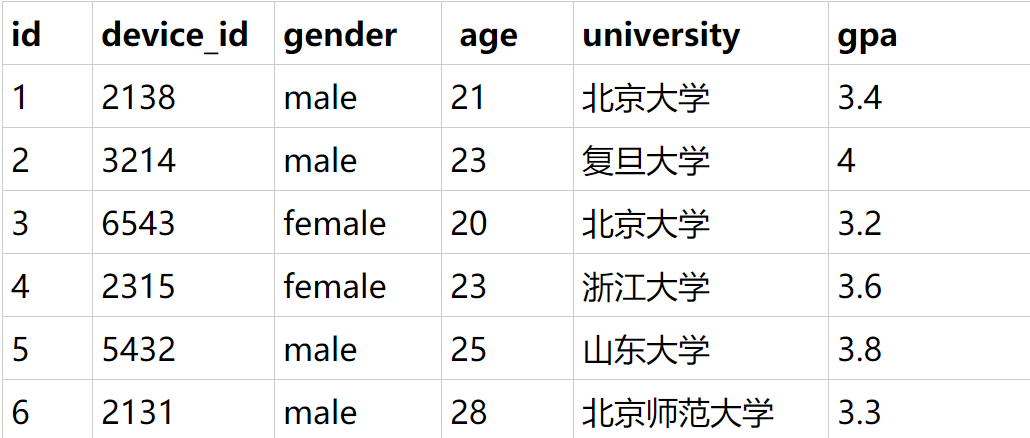
结果,可以看出整表先按照gpa降序,而age是乱序,这是因为order by 先保证gpa降序,当数据的gpa相同时,再根据age降序排列
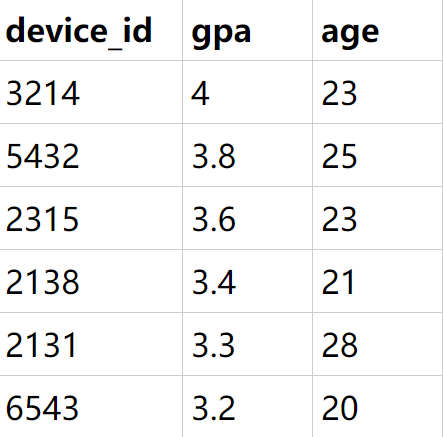
2.5 聚合函数 用来对列进行计算
2.5.1 基本使用

实例1:直接对整个表计算 这里*表示整个表 实际上只要一行中某一格不为null 那么就会被计入
在计算函数后可以接字符串用来修改展示格式
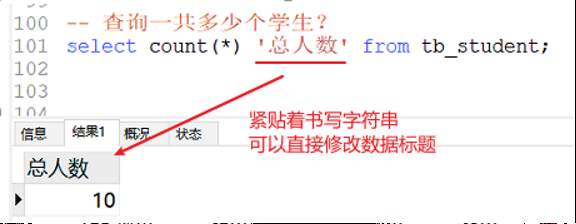
实例2:对指定列计算 这里height就是指定的列

2.5.2 分组使用
如果一个查询使用了分组 group by,那么聚合函数会在分组之后,对每个组的指定列分别进行计算
2.6 分组 group by 列名
2.6.1 简单 根据单例分组
select * from 表名 group by 列名;
会根据指定的列名出现的不同的值进行分组
实测SQL会先执行筛选(where) 再执行分组( group by) 并且写代码时要先写筛选再写分组 否则会报错

实例1:根据指定的列的值对全表数据进行分组 然后列出每个组的第一条数据
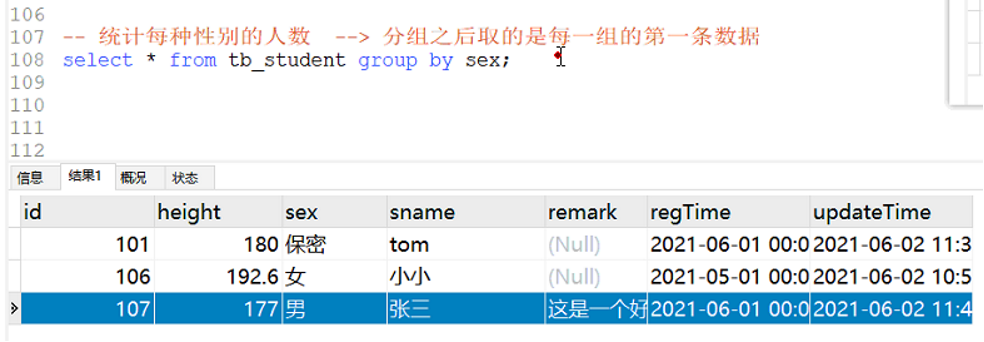
但是仅仅是分组然后给出第一条没有意义,我需要的是分组后根据需求给出数据
所以需要进一步结合聚合函数设置输出格式:
根据指定的列(sex)对整个表进行分组 然后输出n行2列的矩阵
一列为分组后的sex值
另一列为对应sex值的行数数量
Select sex,count(sex) from 表名 group by sex;

结果:

2.6.2 复杂 根据多个列分组
https://blog.csdn.net/weixin_38750084/article/details/82780519
select * from 表名 group by 列名1,列名2
这样可以根据多个字段进行分组,这些列名存在顺序关系,假如一整张表按照列名1分为A\B两组,然后再对A\B两组分别按照列名2进行细分,得到A-1、A-2、A-3等组,以及B-1、B-2等组。
实例:
假设现在整表查询如图
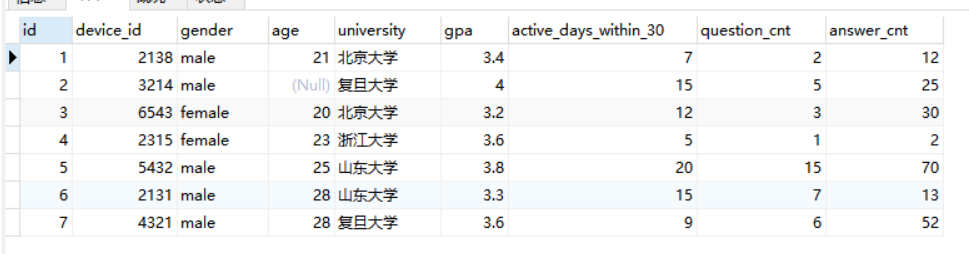
使用group by university,gender
mysql首先会将整个表按照university分组,同组的数据调整顺序放到一块,如果此时没有gender,则直接展示每组第一条数据。

由于这里还有gender,因此mysql在根据university分组并调整顺序后,在此基础上进一步对每组按照gender分组。

2.7 连表查询
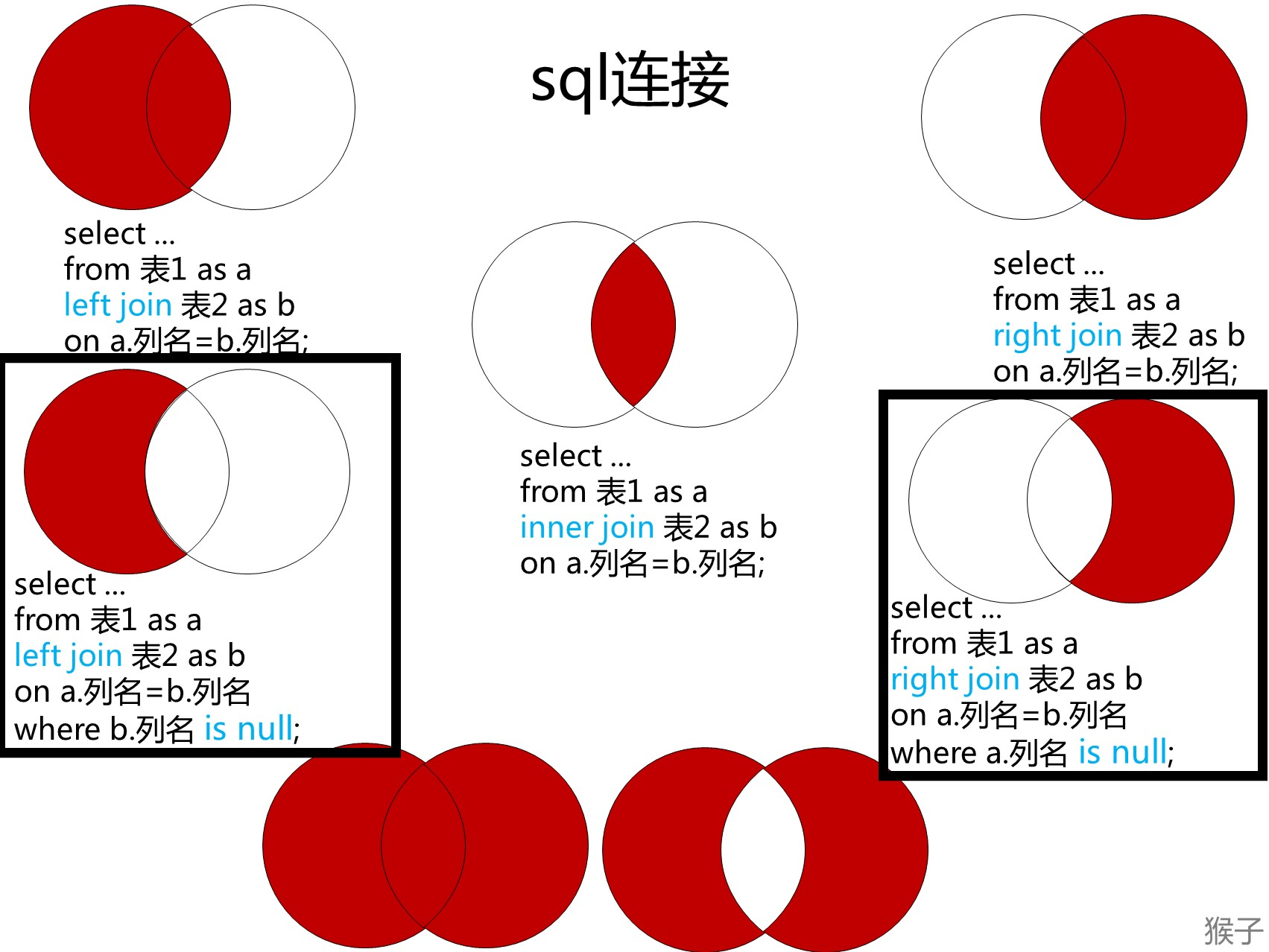
2.7.1 子查询
具备主外键是连表查询的基础,但是通常不允许使用主外键,只允许从业务逻辑进行连表,所以常用的是子查询而不是内、外连接
一个查询当做另一个查询的条件、列、表 那么这个查询叫子查询
把一个查询当做另一个查询的条件,即写在where之后
把一个查询当做临时列来用,即写在select和from之间
把一个查询当做另一个查询的临时表,即写在from和where之间
写法:一般都将子查询放在()里
2.7.2 内连接
2.7.2.1 简单的两表
两种写法
select * from 表1 inner join 表2 on 表1=表2的关联条件(主外键那列)
select * from 表1,表2 where 表1=表2的关联条件(即主外键)
2.7.2.2 复杂的多表
举例,三表联查,使用内连接
SELECT
*
FROM 表1 a,
表2 b,
表3 c
WHERE
a.列1 = b.列1
and
a.列2 = c.列1
2.7.3 外连接
2.7.3.1 简单的两表
分左右连接
左连接:将以左边的表作为主表,右边的表没有的数据会自动设置为null
select * from 表1 left join 表2 on 表1=表2的关联条件
在这里表1是左表 即主表
右连接:将以右边的表作为主表,左表没有的数据将自动填充null
select * from 表1right join 表2 on 表1=表2的条件(即主外键对应的列)
在这里表2是右表 即主表
2.7.3.2 复杂的多表
举例,三表联查,使用左连接
SELECT
*
FROM 表1 AS a
LEFT JOIN 表2 AS b
ON a.列1=b.列1
LEFT JOIN 表3 AS c
ON a.列2=c.列1;
2.7.4 养成指定属性所属表的习惯
不依靠主外键约束的两表连接,要养成对属性都指定原归属表的习惯

如上代码,两表依靠业务逻辑,使用where进行的软连接,同时两表存在同名列——id, 虽然从上面的图可以看出能正常的拼合,且同名的列被自动重命名(靠右的id列变为id1),但是涉及到分组、聚合时,如果使用了同名的列,就必须进一步指明列的原归属表,否则就会报错

2.7.5 自连接
其实就是将表自己与自己连接,然后使用别名来区分两个“自己”,最后按照两表连接进行之后的数据操作,注意此时对列的操作都要用别名进行指定,因为自己和自己拼合,不但属于内连接(等值连接),列还全都同名。
自连接目前用的最多的就是子类拥有父类的id,需要查询出父类id对应的父类名字
图中的表就它本身,自己的id和自己的父类id关联,用了自连接和子查询

2.8 分页limit
mySQL独有的语句 ,给最终的查询结果进行分页展示
两种写法
limit N:从第一条开始查,查N条 此时N代表显示结果最多N条
limit N,M:从第N条开始查,查M条 此时N代表的是索引 N=0代表第一条 M代表的是显示结果最多M条
2.9 集合运算 Union
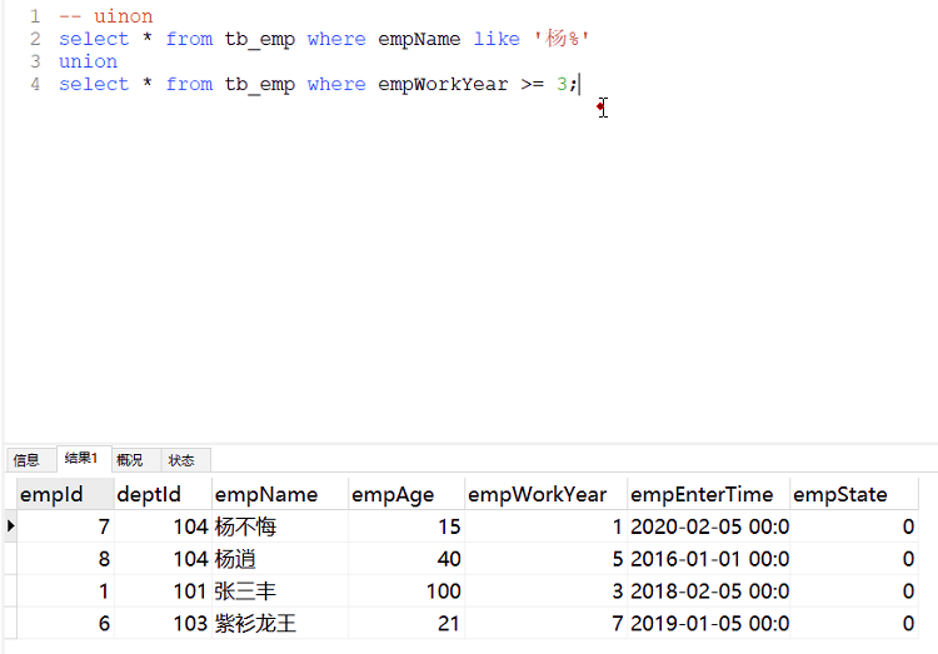
2.9.1 union
Union 放在两个select语句中间起到连接作用,Union 在两个select存在一样的数据时,只取一个,也就是自带去重
语法:
Select * from 表1 ;结果1
Union
Select * from 表2 ; 结果2
要求结果1和结果2得到的查询列数要一致
实例
2.9.2 union all
Union all ,会将两select的数据全部取到,组成一个表,但是不去重
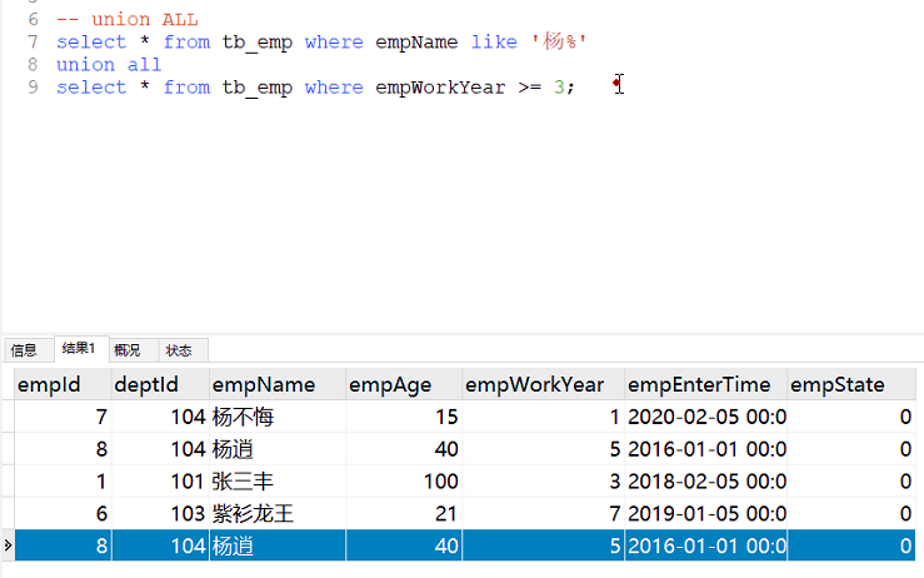
2.10 条件 having
https://www.runoob.com/sql/sql-having.html
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组(group by)后的各组数据。
where 和having都是筛选条件,但是有区别的:
1.where在group by前, having在group by 之后
2.聚合函数(avg、sum、max、min、count),不能作为条件放在where之后,但可以放在having之后
2.11 判空 列名 is null
如果要筛选某列为空的数据
select * from 表名 where 列名is null;
反之,要获取某列不为空
select * from 表名 where 列名is null null;
2.12 范围内取值 列名 in ("字段1","字段2"......)
如果需要查询某个字段等于A或者等于B或者等于C,那么就要用in
select * from 表名 where 字段 IN ("A","B","C");
反之,要求某个字段不等于A和B和C,那么就可以用not in
select * from 表名 where 字段 not IN ("A","B","C");
2.13 sql的精度
sql在对整数做除法运算时,会自动将结果转为浮点数,并且默认最多保留4位小数
select 1/1 as a; //1
select 1/2 as a; //0.5
select 1/3 as a; //0.3333
select 1/4 as a; //0.25
但是如果使用了聚合函数count,那么就会直接保留4位小数
没有表的基础上 直接在查询里做运算 此时count(1)=1
select count(1)/count(1) as b; //1.0000
select count(1)/1 as b; //1.0000
select count(1)/2 as b; //0.5000
select count(1)/3 as b; //0.3333
select count(1)/4 as b; //0.2500
特别的,使用聚合函数后,可以乘以浮点数提升精度,这是整数做除法运算时无法做到的
select count(1)/4*1.0 as b; //0.25000
select count(1)/4*1.00 as b; //0.250000
2.14 改变精度的三种方式
https://blog.csdn.net/weixin_43792309/article/details/107511016
2.14.1 乘一个浮点数
如果使用了多个聚合函数并且使用了除法,比如下面的sql,此时结果只会保留4位小数
select count(字段A)/count(distinct 字段A) from 表名
可以将其中一个数通过乘一个浮点数提升精度
select count(字段A)*1.0/count(distinct 字段A) from 表名
特别的,乘以1.0和乘以1.00是不一样的,后者会导致小数更多一位,也就是更精确
2.14.2 cast(数据 as 新的数据类型) 配合decimal(p,d)
http://www.360doc.com/content/17/0328/15/40081561_640836375.shtml
https://www.cnblogs.com/owenma/p/7097602.html
使用cast()函数可以改变数据类型
select cast(count(字段A) as double)/count(distinct 字段A) from 表名
如果使用cast(),一般会配合数据类型decimal(p,d)
select cast(count(字段A) as decimal(10,4))/count(distinct 字段A) from 表名
P是表示有效数字数的精度。 P范围为1〜65。
D是表示小数点后的位数。 D的范围是0~30。MySQL要求D小于或等于(<=)P。
举个例子,decimal(10,4)代表一个数整数部分位数+小数部分位数<=10,并且小数部分位数指定为4位
2.14.3 round(数据,要保留几位小数)
https://www.w3school.com.cn/sql/sql_func_round.asp
还是同样的例子,可以将计算结果保留指定位数的小数
select round((count(字段A)/count(distinct 字段A)),4) from 表名
又或者只是对显示结果进行小数点设置
select round(字段B,4) from 表名
2.15 if条件函数
https://blog.csdn.net/weixin_41758552/article/details/105437649
if条件函数会对给定的表每一行数据进行判断,符合条件则执行操作1,否则执行操作2
select if(条件,操作1,操作2) as 自定义列名 from 表名
实例
现在有一张表如图,有7条数据
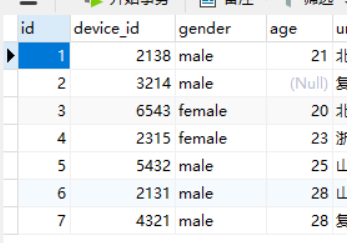
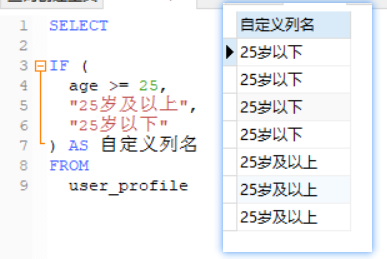
现在使用if函数,可以做到对每条数据都执行if判断,再根据结果执行不同的操作
SELECT IF (age >= 25,"25岁及以上","25岁以下") AS 自定义列名FROM user_profile
7条数据被逐一判断,如果age>=25,就输出“25岁及以上”,反之输出“25岁以下”,而这些输出的信息会被放在单独的一列,列名自定义,如果不指定列名,那么就会把一整个if函数作为列名
2.16 case函数
https://blog.csdn.net/cpc784221489/article/details/90300424
2.16.1 简单case函数
有点像java的switch-case,按从上到下的书写顺序将col_name的值与每个WHEN子句的value进行比较,如果相等则返回对应的result,如果都不想等则返回ELSE子句的result,如果没有ELSE子句则返回null
形式
CASE <col_name>
WHEN <value1> THEN <result1>
WHEN <value2> THEN <result2>
...
ELSE <result>
END
例如
select day
when 1 then "星期一"
when 2 then "星期二"
when 3 then "星期三"
when 4 then "星期四"
when 5 then "星期五"
when 6 then "星期六"
else "星期天"
end
2.16.2 case搜索函数
对给定表的每一个数据都进行判断,例如满足条件1,就返回结果1,一旦满足条件,就不再进行后续判断,如果都不满足则返回ELSE子句的结果,如果没有ELSE子句则返回null
形式
CASE
WHEN <条件1> THEN <结果1>
WHEN <条件2> THEN <结果2>
...
ELSE <结果>
END
例如
case
when score<60 then"不及格"
when score <=70 then "及格"
when score<=80 then "中等"
when score<=90 then "优良"
else "优秀"
end
2.17 日期函数
https://www.cnblogs.com/feiquan/p/8645885.html
日期函数很多,常用的是day() month() year()这三个函数,可以对data类型的字段分别取出日、月、年,再配合where进行判断
2.18 文本函数 字符串截取substring_index
https://zhuanlan.zhihu.com/p/109778760
substring_index(str,delim,count)
str:要处理的字符串
delim:分隔符
count:计数
示例:
如 str=www.wiki.com
则 substring_index(str,'.',1) 处理的结果是:www
substring_index(str,'.',2) 得到的结果是:www.wiki
也就是说,如果count是正数 ,那么就是从左往右数 ,第N个分隔符的左边 的全部内容,
相反,如果是负数 ,那么就是从右边开始数 ,第N个分隔符右边 的所有内容。
如:
substring_index(str,'.',-2) 得到的结果为:http://wikibt.com
如果要中间的的 wiki 怎么办?
很简单的,需要从两个方向截取,也就是分两步:
先截取从右数第二个分隔符的右边的全部内容,再截取从左数的第一个分隔符的左边的全部内容:
substring_index(substring_index(str,'.',-2),'.',1);
2.19 窗口函数
https://zhuanlan.zhihu.com/p/92654574
2.19.1 应用场景说明
以往做排名,都是给定人员A\B\C,然后进行排序,但是如果给定的是A\B\C部门,然后要求出各个部门前N名人员,那么除了各个部门分别处理数据,最后再用union合并数据外,还可以考虑使用mysql的高级函数功能——窗口函数
2.19.2 基本语法说明
窗口函数的基本语法如下:
<窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名> asc/desc)
asc/desc不指定时默认为asc升序
<窗口函数>的位置,可以放以下两种函数:
1) 专用窗口函数,包括后面要讲到的rank, dense_rank, row_number等专用窗口函数。
2) 聚合函数,如sum,avg, count, max, min等
因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中 。
2.19.3 窗口函数和group by的区别
窗口函数具备了我们之前学过的group by子句分组的功能和order by子句排序的功能。那么,为什么还要用窗口函数呢?
这是因为,group by分组汇总后改变了表的行数,一行只有一个类别。而partiition by和rank函数不会减少原表中的行数 。例如下面统计每个班级的人数。
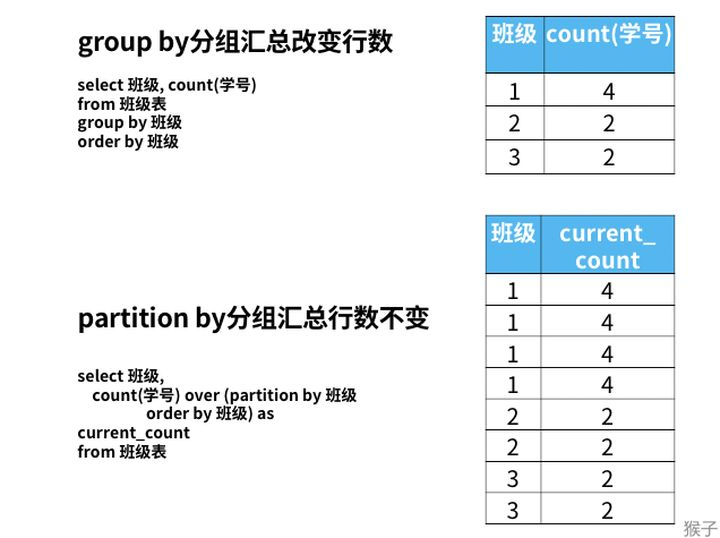
2.19.4 专业窗口函数的区别
有三种专业窗口函数:rank(), dense_rank(), row_number()
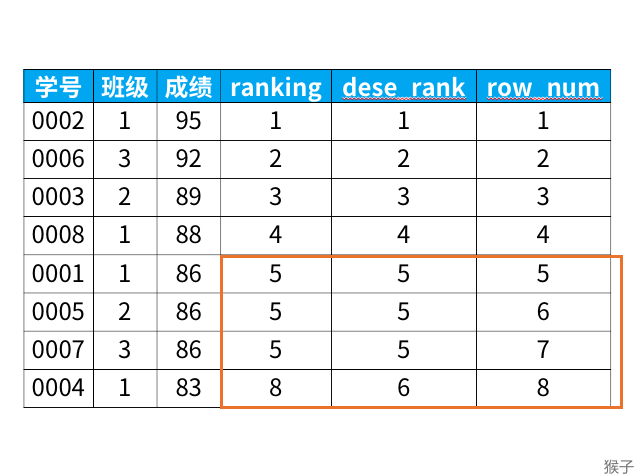
对一张表,执行查询如下
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num
from 班级表
//在上述的这三个专用窗口函数中,函数后面的括号不需要任何参数,保持()空着就可以。
结果如图
对比:
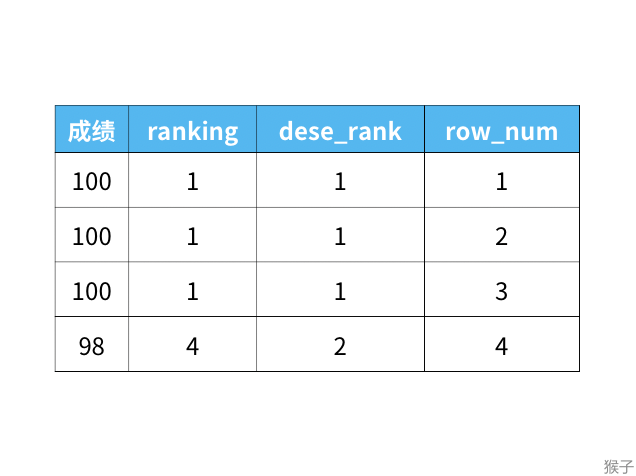
- rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1 ,4。
- dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1 ,2。
- row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3 ,4。
更简单的一图流
2.19.5 聚合函数作为窗口函数
聚和窗口函数和上面提到的专用窗口函数用法完全相同,只需要把聚合函数写在窗口函数的位置即可,但是函数后面括号里面不能为空,需要指定聚合的列名。
聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值、最小值等)。同时可以看出每一行数据,对整体统计数据的影响。
如果想要知道所有人成绩的总和、平均等聚合结果,看最后一行即可。
具体使用方式见上方的帖子。
3 sql语句执行顺序
聚合函数执行顺序在group by之后
case()函数执行顺序在group by之前

4 DDL等名词说明(SQL组成)
名词解释
- DDL(Data Definition Language): 数据定义语言
- 用来定义数据库对象:数据库,表,列等。 关键字:create,drop, alter等。
- DML(Data Manipulation Language): 数据操作语言
- 用来对数据库中的表进行增删改操作。 关键字:insert,delete,update等。
- DQL(Data Query Language): 数据查询语言
- 用来查询数据库中表的记录(数据)。 关键字:select, where等
- DCL(Data Control Language): 数据控制语言
- 用来定义数据库的访问控制权限和安全级别,及创建用户。关键字: grant, revoke等
SQL主要分成四部分 :
(1)数据定义。(SQL DDL)用于定义SQL模式、基本表、视图和索引的创建和撤消操作。
(2)数据操纵。(SQL DML)数据操纵分成数据查询和数据更新两类。数据更新又分成插入、删除、和修改三种操作。
(3)数据控制。(DCL)包括对基本表和视图的授权,完整性规则的描述,事务控制等内容。
(4)嵌入式SQL的使用规定。(TCL)涉及到SQL语句嵌入在宿主语言程序中使用的规则。
5 题目
第二高的薪水
题目描述

答案
select ifNull((select distinct Salary from Employee order by salary desc limit 1,1 ),null) as SecondHighestSalary;
说明
1. select ifNull((查询),查不到就要返回什么信息) as 自定义表名通常是题目名
2. select ditinct 去重依据字段 from 表 加了ditinct字段能去重
3. order by 排序依据的字段 asc/desc
4. limit 1,1 查询第二高的数据,同理,查询第三高就用limit 2,2
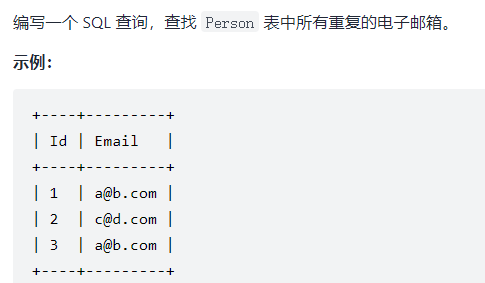
查找重复的数据
题目描述:
答案:
解法1:having +聚合函数 > select Email from Person group by Email having count(Email) > 1;
解法2:自链接 > select DISTINCT p1.Email from Person p1, Person p2 where p1.Email = p2.Email and p1.Id != p2.Id;
解法3:子表查询 > select Email from (select count(1) as t, Email from Person group by Email) r where r.t > 1;
说明:
三种解法
1. having+聚合函数 ,在全表查询的基础上使用having进行过滤,相比where可以使用聚合函数count 再配合比较符号>1即可查询重复数据
2. 自连接,使用where将需要查询重复数据的字段连接,同时要求主键不相同,就能得到一张记录多条相同数据但主键id不同的表,最后使用去重DISTINCT
3. 子查询,首先将表按照Email分组,然后使用聚合函数count统计指定列1记录不为null的条数,并给这个字段一个别名t,这样就可以知道每一个邮箱有多少条,再然后把这个表作为子查询,给别名r,再从这个r表使用where判断t字段>1的email。
实话说有点绕,其实核心就是聚合函数+where,由于where不能用聚合函数,只能先在子查询中用聚合函数再用where判断,还是解法一简便
查找不在表中的数据
题目描述
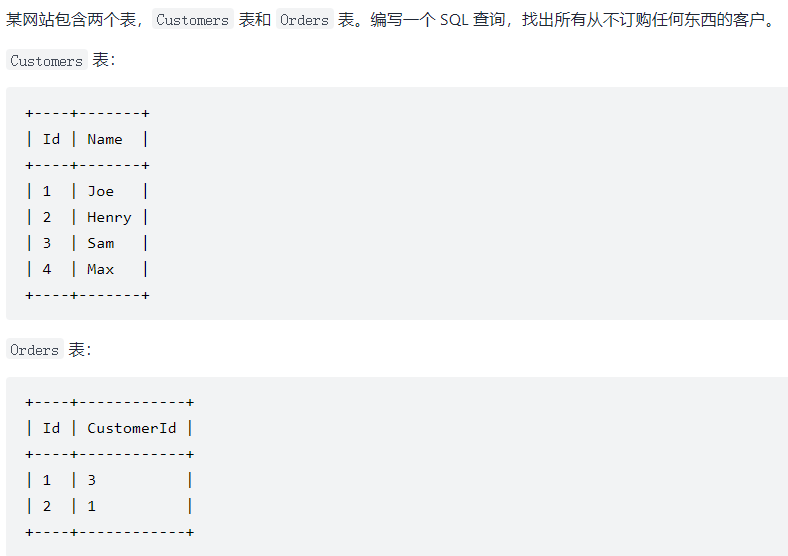
答案
select a.Name as Customers from Customers as a left join Orders as b on a.Id=b.CustomerId where b.CustomerId is null;
说明
其实就是多表联查,上面总结了都有哪些连表方式2.7 连表查询,题目的意思就是在查找在顾客表但是不在订单表的数据
遇到要查找“不在表里的数据 ,也就是在表A里的数据,但是不在表B里的数据。”可以使用下图黑框里的sql语句。
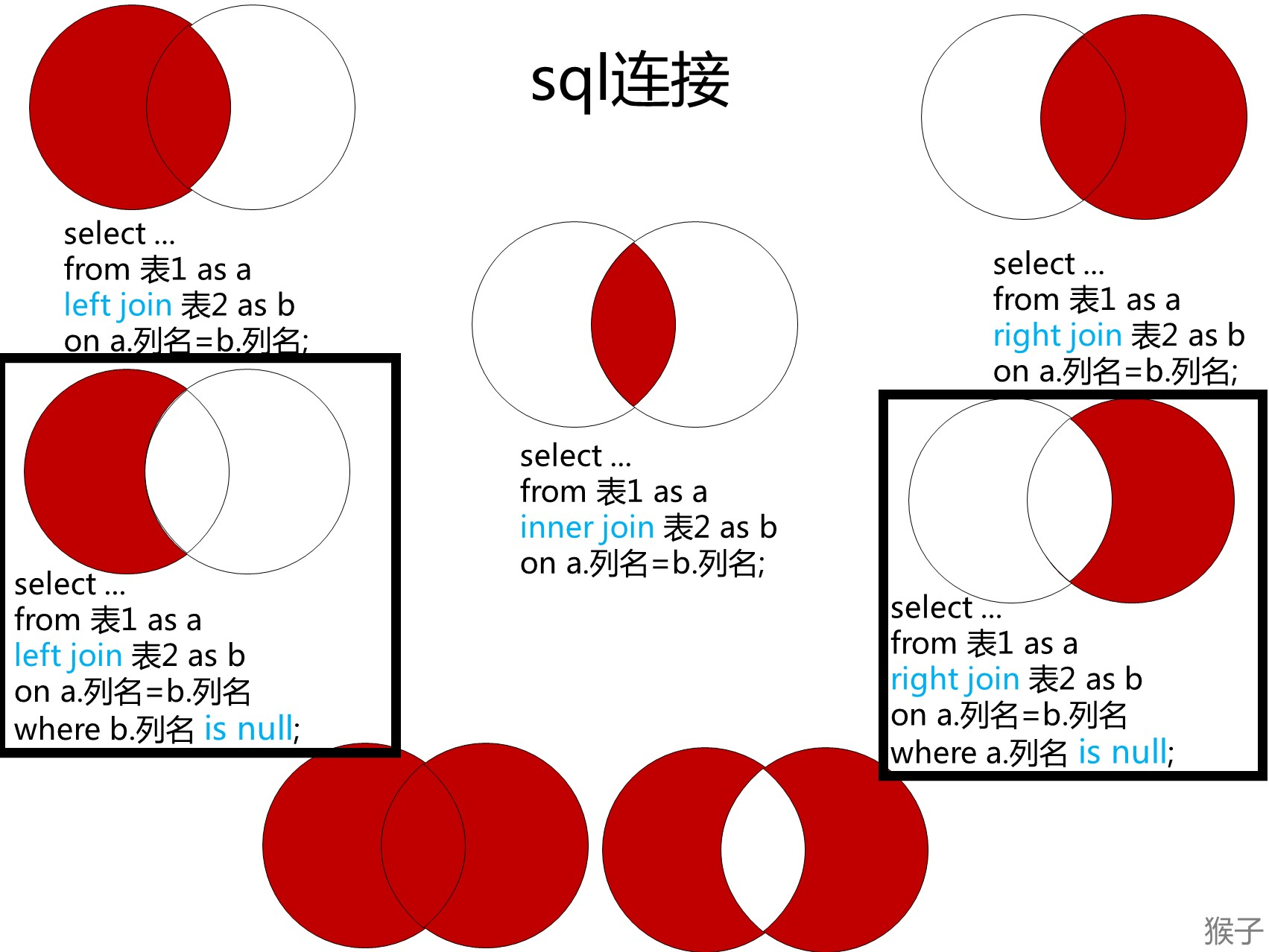
having的一些概念

解答一
A F:having子句即可包含聚合函数作用的字段也可包括普通的标量字段,实施上所有的where子句都可以用having代替
B、C、E:where子句是过滤行;having子句是过滤分组。where在数据分组之前使用,having在数据分组之后使用,可以同时使用。
D:group by 子句是限定分组条件的,having是过滤分组的
解答二
- where子句 = 指定行所对应的条件
- having子句 = 指定组所对应的条件
- D中是Group by才用来分组的,group by的作用是限定分组条件,而having则是对group by中分出来的组进行条件筛选。
- 所以用having就一定要和group by连用,且是先group by XXX 再having XXX,用group by不一有having(它只是一个筛选条件用的)
- having 是对 group by后的数据进行筛选过滤,必须要有group by才能用having
- having只用来在group by之后,having不可单独用,必须和group by用
转存数据
题目描述
某打车公司要将驾驶里程(drivedistanced)超过5000里的司机信息转存到一张称为seniordrivers 的表中,他们的详细情况被记录在表drivers 中,正确的sql语句为()
答案
select * into seniordrivers from drivers where drivedistanced >=5000
说明
INSERT INTO 语句用于向表格中插入新的行 。
INSERT INTO table_name VALUES (值1, 值2,....)
指定所要插入数据的列:
INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....)
SELECT INTO 语句从一个表中选取数据,然后把数据插入另一个表中 。常用于创建表的备份复件或者用于对记录进行存档。
把所有的列插入新表
SELECT *
INTO new_table_name [IN externaldatabase]
FROM old_tablename
只把希望的列插入新表
SELECT column_name(s)
INTO new_table_name [IN externaldatabase]
FROM old_tablename
查询语句的统计函数辨析
题目描述
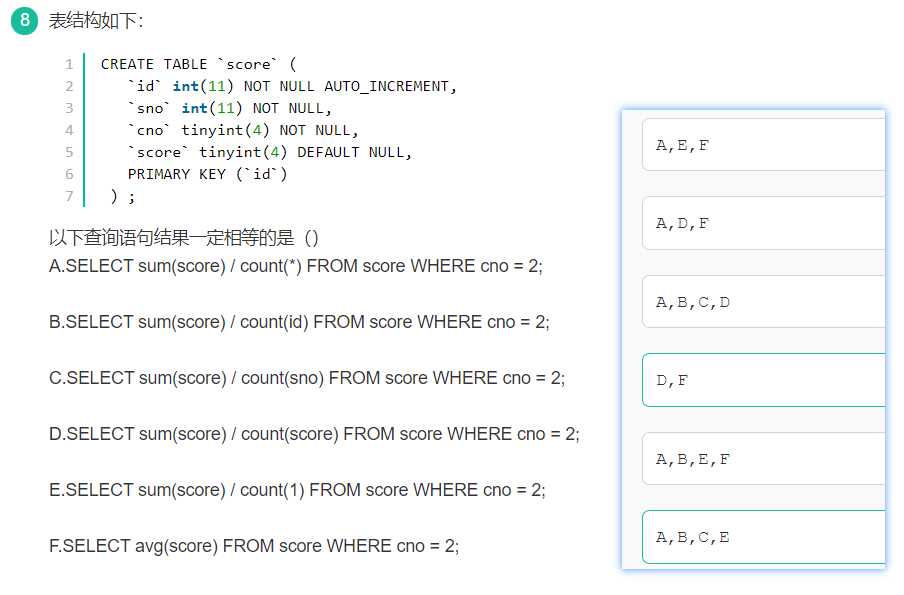
答案
A\B\C\E是一组,结果一样
D\F是一组,结果一样
由于这是一个选择题,给出的答案中只有D,F选项符合题意,所以答案是D\F
说明
1. 所有统计函数函数都是在where筛选之后,针对筛选好的表进行的
2. sum(指定字段)会获得筛选后整个表的score字段的和
3. count(*)会获得筛选后整个表的行数
4. count(1)可以理解为count(数字),也是获得整个表的行数
5. count(指定字段)会获得整个表中这个字段不为null的行数
6. avg(score)等价于sum(score)/count(score)
7. 每条sql语句意思如下:
A :分数之和/所有学生,分数之和不包括分数为null的记录,但会把分数为null的学生也算入分母,徒增分母的值
B :与A一样,因为id主键非空,count(id)所得分母基数是所有学生。
C : 与B一样,sno也是非空属性。
D :由于score字段的值可能是空,空值在统计时忽略,所以count(score)和sum(score)统计的只是score不为空的学生,计算得到的平均分也只是有成绩的学生的平均分,无法计算所有学生的平均分。
E: 与A一样,因为count(1)与count(*)一样。
F:和D一样,avg(score)等价于sum(score)/count(score)
总的来说A,B,C,E返回sum(score)除以行数;D,F返回sum(score)除以score不为null的行数
8. 对于count,有三种情况,对应四种表现形式
此处设定count(a),其中a为变量,可以为各种值,下面根据a的不同值,得出不同的count(a)的结果
1)当a = null时,count(a)的值为0;count()
2)当a != null 且不是表的列名的时候,count(a)为该表的行数;count(*)或者count(数字)
3)当a是表的列名时,count(a)为该表中a列的值不等于null的行的总数,它和2)中的差值就是该表中a列值为null的行数count(指定列)
9. count()和count(1)可以看成count()与count(不为列名的数字),从结果上看是一样的,不同的是两者的性能
10. 性能方面:count(数字)和count(*)均>count(具体字段)
因为在sql的引擎中,分完组之后,count(*)与count(数字)其实结果就已经出来了,但是如果写了count(具体字段),引擎还会在遍历一遍分完组的数据,统计具体字段不为空(null)的条数,然后返回出来。
11. count(数字)和count(*)分情况:
如果在开发中确实需要用到count()聚合,那么优先考虑count(*),因为mysql数据库本身对于count()做了特别的优化处理。
- 有主键或联合主键的情况下,count(*)略比count(1)快一些。
- 没有主键的情况下count(1)比count()快一些。
- 如果表只有一个字段,则count(*)是最快的。
12. 使用count()聚合函数后,最好不要跟where age = 1;这样的条件,会导致不走索引,降低查询效率,除非该字段已经建立了索引。
13. 使用count()聚合函数后,若有where条件,且where条件的字段未建立索引,则查询不会走索引,直接扫描了全表。
14. count(字段),字段是非主键字段,这样的使用方式最好不要出现,因为它不会走索引。
分组排序
题目
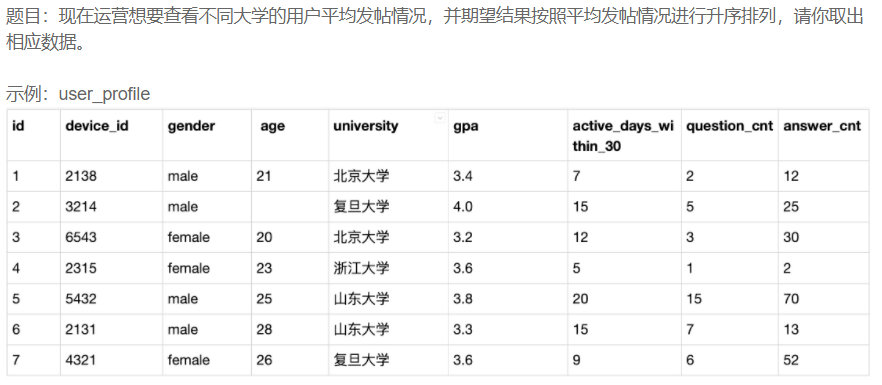
答案
select university,AVG(question_cnt) from user_profile GROUP by university ORDER BY AVG(question_cnt) asc;
说明
1. 根据sql语句执行顺序,整个表首先被group by根据指定列分成多个组
2. 然后每个组都会被avg()计算出属于这个组的数据,也就是说avg()直接面向组执行多次,而不是面向整张表只执行一次
3. 之前的理解是order by会根据指定数据对整个表的数据进行排序,在这里order by会对每个组依据指定的数据进行排序,其实也可以理解成group by+avg()之后,整个表只显示每组第一条数据,然后还有一列隐藏列记录每组的avg值,然后order by对这张表的数据根据这个隐藏列进行排序
4. order by排好序后,整张表再显示university字段和隐藏列的数据,也可以理解为显示university,然后再对各个组进行一次avg计算,再显示出来
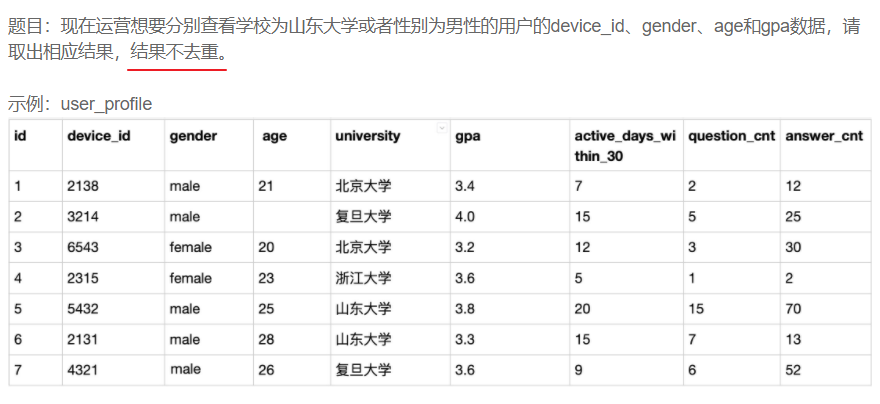
结果合并不去重
题目
答案
SELECT device_id,gender,age,gpa FROM user_profile WHERE university="山东大学"
union ALL
SELECT device_id,gender,age,gpa FROM user_profile WHERE gender="male"
说明
1. 限定条件:学校为山东大学或者性别为男性的用户:university='山东大学', gender='male';
2. 分别查看&结果不去重:所以直接使用两个条件的or是不行的,直接用union也不行,要用union all,分别去查满足条件1的和满足条件2的,然后合在一起不去重
3. or是取两个结果集的合集,union也是取两个结果集的合集,这两者都会导致去重,如果不希望去重,就要用union all
计算符合条件的统计结果
题目
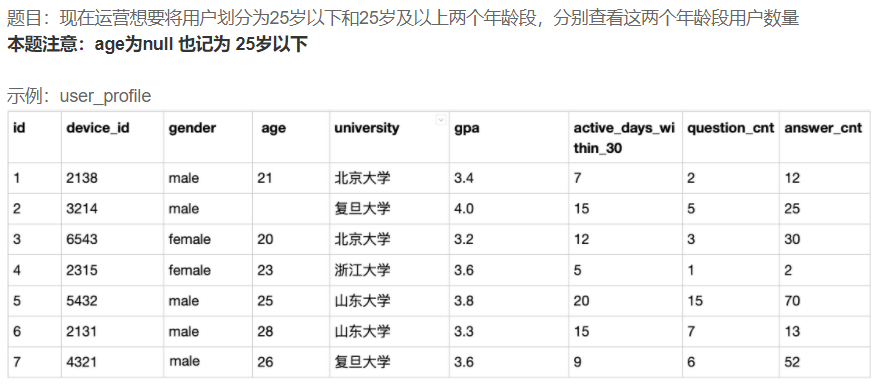
答案
//解法1 if函数
select age_cut, count(*)
from (
select
if(age>=25, "25岁及以上", "25岁以下") as age_cut
from user_profile
) as up
group by age_cut
//解法2 union
SELECT '25岁以下' age_cut,COUNT(device_id) Number
FROM user_profile
WHERE age < 25 OR age IS NULL
UNION
SELECT '25岁以及上' age_cut,COUNT(device_id) Number
FROM user_profile
WHERE age >= 25
//解法3 case函数
SELECT
CASE
WHEN age < 25 OR age IS NULL THEN '25岁以下'
WHEN age >= 25 THEN '25岁及以上'
END as age_cut,COUNT(*) as number
FROM user_profile
GROUP BY age_cut
解法一说明
1. 先看子查询,用if函数,对整个表的数据逐一判断,获得一个自定义表
子查询结果如图
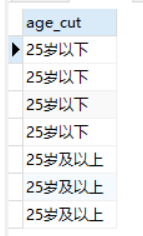
2. 然后就是对子查询获得的表分组,并使用聚合函数count
解法二说明
1. 解法二就是分别查询满足条件的数据,然后用union拼接
解法三说明
1. 使用了case搜索函数,就像用if函数一样,会得到一列自定义列结果
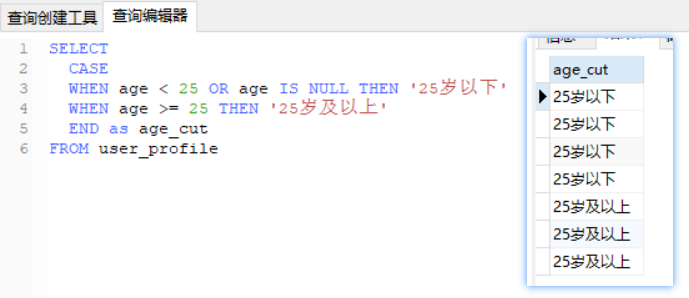
2. case/if这种函数执行顺序在group by之前
统计人数,需要的信息放在文本内
题目

答案
select
substring_index(profile, ',', -1) as gender,
count(device_id) as number
from user_submit
group by gender
说明
1. 题目需要根据性别统计人数,但是目前表上没有性别字段,只有一个profile,但是可以看到这个字段很规律,所以可以通过substring_index函数,对每一行数据的这个字段进行处理,得到性别数据,放在自定义字段gender中,然后再用这个gender字段分组,最后使用count函数进行统计
专业窗口函数使用
题目
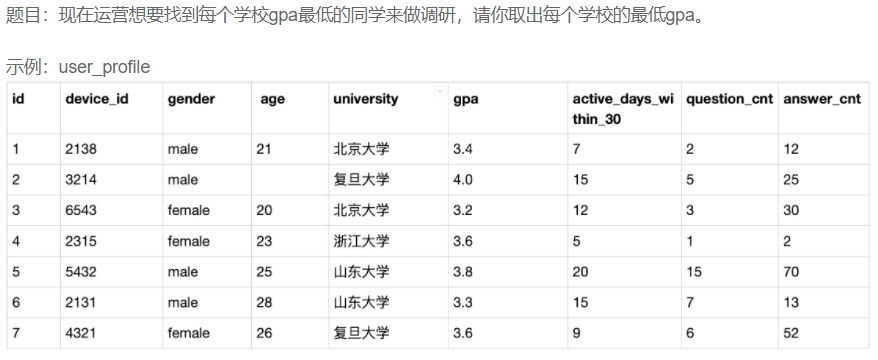
答案
//解法一 窗口函数
select device_id, university, gpa
from (
select *,
row_number() over (partition by university order by gpa) as rn
from user_profile
) as univ_min
where univ_min.rn=1
//解法二 将表a的device_id,university,gpa和表b的university,min(gpa)连接起来找
SELECT a.device_id,a.university,a.gpa FROM user_profile a
JOIN (SELECT university,min(gpa) gpa FROM user_profile GROUP BY university) b
on a.university=b.university and a.gpa=b.gpa
ORDER BY university;
说明
1. 这是典型的多组中求每组前N或者后N名,需要使用分组和排序,可以考虑连表实现,也可以考虑使用窗口函数
2. 使用窗口函数时,首先在user_profile表使用row_number() over(partition by 分组依据 order by 排序依据)得到分组并排序好的表univ_min 此时各个数据都会在列rn中记录自己在本组的序号
3. 然后查询表univ_min中rn=1的数据,即可得到题目需求的每组中最值人员

