高并发 低并发
1 高并发
1.1 高并发的概念
https://www.cnblogs.com/myseries/p/12543523.html
https://blog.csdn.net/weixin_34402408/article/details/92466550
1.1.1 高并发场景
面试时常说的“具备高并发技术”,就是要求面试者具备解决高并发场景的技术。
高并发场景下,服务端要能快速响应前端的大量请求,比如商城秒杀或者大流量的SaaS平台。
无论是分布式还是单机模式,都会存在高并发场景,但是为了能更好的解决高并发场景,通常都不会让项目再保持单机模式,而是升级为分布式模式
1.1.2 高并发技术
高并发场景下涉及到的技术非常多,硬件、网络、系统架构、开发语言的选取、数据结构的运用、算法优化、数据库优化等等
因此高并发≠多线程,多线程只是高并发场景的解决方法之一,高并发技术指的是一整套技术而不是单个技术。
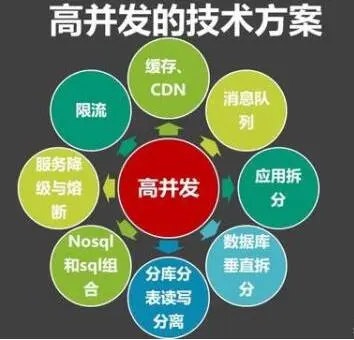
1.1.3 面试要聊的高并发
高并发场景下要解决:
-
数据表普遍被分库分表,否则单机放不下,或者查询性能不足
-
解决分布式事务
-
因为机器都可能坏,为了保证少数机器坏掉不会影响处理的性能,必须引入HA机制
-
因为系统都有极限,超过极限响应能力就会急剧下降。因此必须引入限流的方案来保护系统
-
这么复杂的系统会涉及到N个service,N个存储,N个队列…… 这些资源的管理又成为了新的问题,这又需要对集群和服务做管理
-
这么多服务,肯定要解决分布式的Tracing和报警问题
-
……
当面试的时候提起【高并发】,大概率是希望面试者聊聊上面这些主题。但请特别特别留意,不同领域的【高并发】实际的意思(怎么算“高”,如何达成,哪些问题是关键问题)会非常不同。电商的高并发,抖音的高并发,12306卖火车票的高并发,基金交易系统的高并发,海量数据处理的高并发,这些问题其实都很不同。所以我很建议每次都讨论具体的问题,而非泛泛谈论【高并发】这个名词。
1.1.4 高并发的实质
高并发要求的是“短时间内以最低的成本解决大量的请求”,并不在意技术手段。
如果现在一个Nginx运行在单核CPU的服务器上,所有线程都只能并发执行,无法并行,通过使用多线程只能提升CPU使用率而不能实现线程并行操作,但是还可以通过CDN缓存加速、消息中间件、优化sql慢查询等技术手段,令它每秒能处理10万个请求,超过峰值需要的8万个请求,此时Nginx也就满足了高并发场景的需求,这也算解决了高并发。
1.2 高并发场景的指标
高并发场景是一个相对于业务场景提出的概念,需要通过以下指标综合判断系统遇到的并发情况是否属于高并发。
关键指标:
-响应时间(Response Time)
-吞吐量(Throughput)
-每秒查询率QPS(Query Per Second)
-每秒事务处理量TPS(Transaction Per Second)
-同时在线用户数量(并发用户数)
-访问量(PV)
举个例子:
木头同学去一家创业公司面试。这个公司做的产品还没有上线,面试官小熊之前就职过公司的产品都没有什么量。
小熊:“有高并发经验吗?”
木头:“我们服务单机QPS2000+,线上有4台机器负载均衡。”
这时候小熊心里的表情大概是:
哇塞,遇到懂高并发的大佬了!

但是如果小熊就职的公司是美团之类的。那这这时候小熊心里的表情大概是:
什么玩意儿,这也能叫高并发?

1.3 QPS
1.3.1 概念
那么多高并发的关键指标,但是日常中基本都以QPS来看待一个项目对并发场景的应对能力。
QPS就是衡量吞吐量(Throughput)的一个常用指标,就是说服务器在一秒的时间内处理了多少个请求 —— 我们通常是指 HTTP 请求,显然数字越大代表服务器的负荷越高、处理能力越强,也就越能应对高并发场景。
1.3.2 计算公式
对于整个项目
估算QPS= 整个项目的后端服务器能响应的并发数总和/程序平均响应时间
精确QPS,使用压测工具去测
对于单个服务器
估算QPS=这个服务器能响应的并发数/程序平均响应时间
精确QPS,使用压测工具去测
1.3.3 计算QPS举例
假设现在有一个项目,处理一个业务请求平均响应时间为100ms(0.1秒),同时,整个服务端有20台Apache的Web服务器,配置MaxClients为500个(表示Apache的最大连接数目)
$$
20*500/0.1 = 100000 (10万QPS)
$$
因此整个项目的服务端,最大能承载10万QPS,也就是每秒能响应10万个请求。
不过对于大多数中小企业来说,没那么大体量的业务需求,因此没必要花那么多钱去租20台web服务器,公式中的分母——“整个项目的后端服务器能响应的并发数总和”一般是通过二八定律计算出来然后再上浮一点。
1.3.4 二八定律
二八定律:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间。
计算公式:( 每天总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS) 。
除了上述计算,也可以通过运维监测,得到更为精确的QPS
总之只要整个项目能响应的并发数比峰值时间的需求要高一点就行了。
假设整个项目每天有300W的访问量,通过二八定律计算,( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS),因此整个项目在峰值时间QPS会达到139
然后使用一些压测工具比如locust、Apache ab, Apache JMeter (互联网公司用的较多),LoadRunner 等,测出一台服务器的QPS是多少,然后就可以通过139/测出来的单台服务器QPS,再向上取整得到整个项目应该部署多少台服务器才能保证峰值到来时项目不宕机。
1 .3.5 优化最大QPS
https://blog.csdn.net/qq_26222859/article/details/54411693
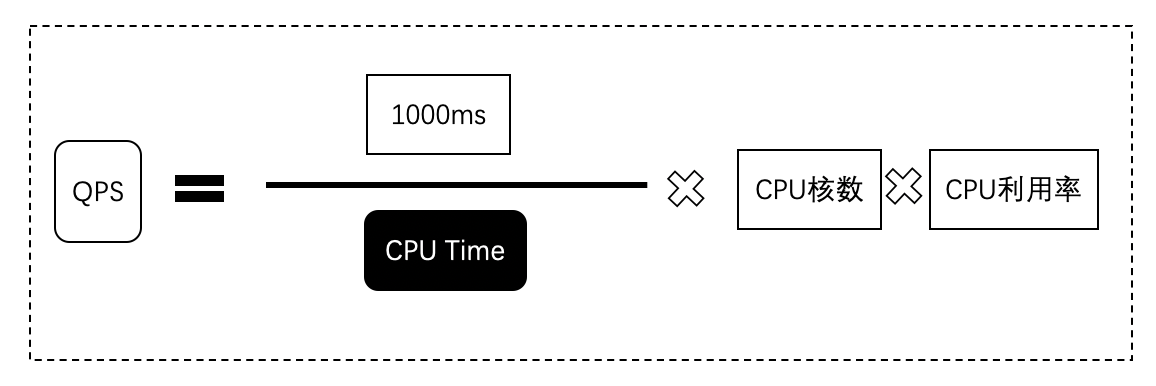
无论是整个项目还是单个服务器的QPS,计算中的分子是固定的——根据配置的MaxClients确定。
但是一开始是怎么确定这个值的,经验?那么如何提升QPS?真的是提升MaxClients就行了嘛?
上面的文章就给出了单台服务器计算最大QPS的公式,并给出了验证,所以要提升QPS,就可以从cpu time和cpu利用率入手。
得到单机最大QPS后,反过来设置单台服务器的MaxClients,以实现对整个项目的最大QPS的优化。
1.3.6 简单估算最大QPS
https://zhuanlan.zhihu.com/p/24379913
根据文章说的指标,使用别人写好的静态页面填写指标,就可以估算出最大QPS
1.4 并发用户数
并发用户数是指系统可以同时承载的正常使用系统功能的用户的数量。与吞吐量(Throughput)相比,并发用户数是一个更直观但也更笼统的性能指标。
实际上,并发用户数是一个非常不准确的指标,因为用户不同的使用模式会导致不同用户在单位时间发出不同数量的请求。
以网站系统为例,假设用户只有注册后才能使用,但注册用户并不是每时每刻都在使用该网站,因此具体一个时刻只有部分注册用户同时在线,在线用户就在浏览网站时会花很多时间阅读网站上的信息,因而具体一个时刻只有部分在线用户同时向系统发出请求。
这样,对于网站系统我们会有三个关于用户数的统计数字:注册用户数、在线用户数和同时发请求用户数。由于注册用户可能长时间不登陆网站,使用注册用户数作为性能指标会造成很大的误差。而在线用户数和同事发请求用户数都可以作为性能指标。
相比而言,以在线用户作为性能指标更直观些,而以同时发请求用户数作为性能指标更准确些。
1.5 如何解决高并发
1.5.1 解决思路
为了解决高并发场景,需要使用许多技术,比如:
对于服务器负荷,就是从QPS下手,要提升整个项目的最大QPS,减小峰值QPS。
对于线程安全,就是从CAS、锁、内存模型下手。
1.5.2 常用的高并发处理方案
可以从以下五点进行处理
- 缓存处理(Redis等)
大部分的高并发场景,都是读多写少,通过使用redis,缩小程序响应时间,这样就能提升项目QPS,需要考虑的是如何把项目中读多写少的场景反到缓存中
- 硬件升级(调整服务器CPU,带宽,处理器)
通过添加设备,直接把整个项目承载能力提升,等于提升了项目QPS的分子
- 负载均衡(Nginx,Spring Cloud的注册中心等)
通过均衡各个服务器的负荷,让各个服务器不至于宕机,提升整个服务集群的稳定性
- 性能优调(Mysql)
通过优化慢查询sql语句,减少程序请求的响应时间,等于令项目QPS的分母减小,整个项目QPS就增大了
- 代码处理(设置策略,IP账号限制,验证码处理)
这一步主要是为了限制峰值QPS,通过IP账号限制,单IP一定时间内只能发送一次请求,还有要求输入验证码来增加请求之间的间隔时间,将峰值QPS的分母增大,这样整个峰值QPS就缩小了。
其他手段
-
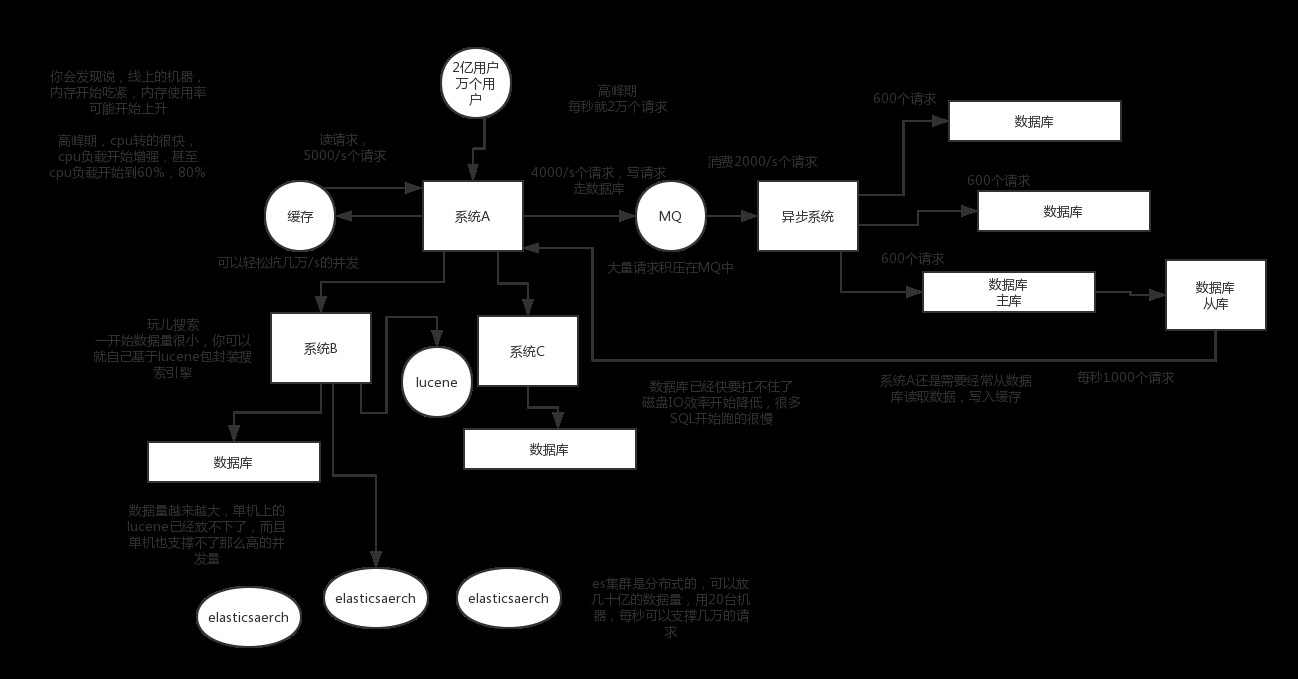
MQ(消息队列),必须得用MQ。可能你还是会出现高并发写的场景,比如说一个业务操作里要频繁搞数据库几十次,增删改增删改,疯了。那高并发绝对搞挂你的系统,人家是缓存你要是用redis来承载写那肯定不行,数据随时就被LRU(淘汰掉最不经常使用的)了,数据格式还无比简单,没有事务支持。所以该用mysql还得用mysql啊。那你咋办?用MQ吧,大量的写请求灌入MQ里,排队慢慢玩儿,后边系统消费后慢慢写,控制在mysql承载范围之内。所以你得考虑考虑你的项目里,那些承载复杂写业务逻辑的场景里,如何用MQ来异步写,提升并发性。MQ单机抗几万并发也是ok的
-
分库分表,可能到了最后数据库层面还是免不了抗高并发的要求,好吧,那么就将一个数据库拆分为多个库,多个库来抗更高的并发;然后将一个表拆分为多个表,每个表的数据量保持少一点,提高sql跑的性能
-
读写分离,这个就是说大部分时候数据库可能也是读多写少,没必要所有请求都集中在一个库上吧,可以搞个主从架构,主库写入,从库读取,搞一个读写分离。读流量太多的时候,还可以加更多的从库
总结
上面的操作,基本就是高并发系统肯定要干的一些事儿。你需要考虑,哪些需要分库分表,哪些不需要分库分表,单库单表跟分库分表如何join,哪些数据要放到缓存里去,放哪些数据可以抗掉高并发的请求,你需要完成对一个复杂业务系统的分析,然后逐步加入高并发的系统架构的改造,这个过程是复杂的,一旦做过一次,一旦做好了,你在这个市场上就会非常的吃香。
1.5.3常见高并发场景以及解决方案
1.5.3.1 syn洪水攻击
什么是洪水攻击?
攻击者恶意访问让你的服务器资源耗尽,无法提供正常的服务,间接地拒绝。
怎么应对或处理洪水攻击?
情景一:黑客恶意攻击频繁使用假IP进行访问;
方法一:运用sysctl命令进行配置,针对SYN洪水攻击的防御措施.
方法二:利用安全狗,360安全卫士等杀毒软件,(软件有针对处理洪水攻击的策略)
情景二:用户频繁登录
方法一:代码优化处理,限制统一IP或统一账号,每秒访问次数,添加验证码策略,访问更新验证码加长用户操作时间。
1.5.3.2 硬件配置过低
情景一:CPU长期达到90%以上(升级CPU处理器)
情景二:CPU长期在40%左右带宽达到100%使用率。(升级带宽)
情景三:CPU与带宽正常物理内存处于占满状态。(升级物理内存)
1.5.3.3 SQL语句查询频繁,重复查询或SQL语句问题,导致接口处理时间过慢。
情景一:针对大量数据,sql语句过于简单,查询条件过少;
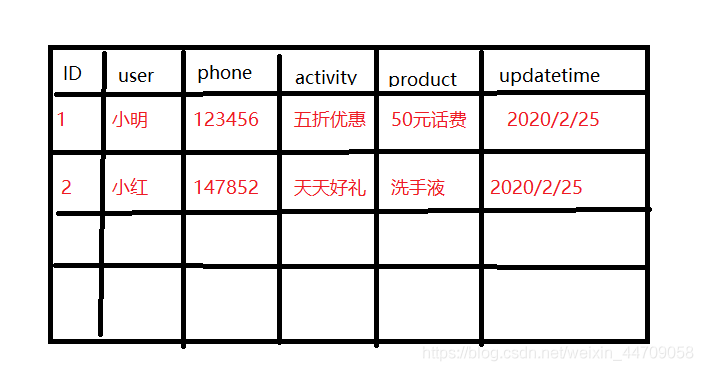
举个例子:一个数据库中有表为activityTable 我想查询用户在什么时间领取到什么产品;查询语句如下
SELECT * FROM activityTable where user = "小红";
// 处理少量数据时可能没什么问题,但是处理大量数据时他就会发生查询处理时间过长等问题
// 正确处理sql应该为加索引等优化
create index index_name on activityTable(phone) ;
select user from activityTable where phone = 123456;
数据库表如图,其中序号ID 用户名User , 活动 activity,手机号 phone,产品 product ,领取时间 updatetime。
情景二:查询sql过多,导致接口处理时间过长,用户操作界面处于等待;
方法一:利用缓存处理(Redis,Memcached等)将查询数据缓存到Redis数据库中,(Nosql数据库处理时间小于Mysql处理时间)
方法二:加大服务器硬件,调整CPU,带宽,处理器等(不推荐,有钱除外。)
1.5.3.4 用户量过大,CPU,处理器,带宽正常,但是仍旧过卡
情景一:Apache的Web服务器只有运行一个时
方法一:性能优调(Mysql,Nginx,Tomcat)负载均衡处理
mysql的myini文件优化
mysql的my.cof文件优
Tomcat性能优化
Nginx的nginx.conf文件配置
2 低并发
所谓低并发就是流量比较低的并发场景,此时一般不需要去考虑服务器的负载,但是如果用了多线程技术,那么依然要考虑线程安全——对同一条数据的修改引发的线程安全,也就是考虑如何使用锁。
具体考虑乐观锁、悲观锁、互斥锁、自旋锁,除了JUC,还有mysql的表锁、行锁。
按照美团的这篇文章来看就行了,更深的就说不知道

