数据库分库分表 redis序列生成器
1 什么是分库
当业务系统越来越大,查询新增的压力在单个数据库集群已经无法满足时,就会将当前的数据库进行业务拆分.如:CRM库,分割为CRM-USER,CRM-ORDER, CRM-GOOD,不同数据库对应不同业务模块,不同的数据库放在不同的硬件(服务器)上,这就是数据库分库
虽然数据库的压力减少了,但是执行业务操作的技术要求就提高了,举个例子,商城订单系统要获取用户信息和订单信息,这就要连表查询,但是待关联的表在不同的数据库上,这就涉及到了跨库查询
2 什么是分表
- 拓展:分表和拆表的区别
我的理解,分表是很长一张表,横切一刀,分成两张表,只是对数据量进行拆分,增删查改其实还是对单表进行操作;拆表是竖切一刀,把表的字段拆到别的表上,增删查改需要连表操作
当某个表的数据量较大,且修改查询的频次较高,则会将表进行拆分,按照mycat的介绍,mycat可以将数据库表按照一千万的量级进行划分,假设一张表有一亿条数据,那么就要被划分为十张表
分表的方式如下图,可以按照时间分表,也可以按照ID分表
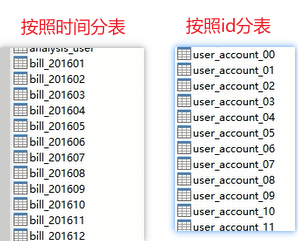
2.1 按照时间分表
比如银行流水,默认显示半年,这就是默认查询的表只记录半年的数据,更早的被拆到其他表中保存,如果用户需要查询更早的数据,需要让用户手动选定时间范围,再执行连表查询
通过这种方式,就能减轻数据库查询压力
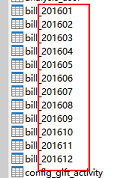
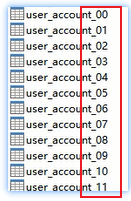
2.2 按照ID分表
假设有一张账户表,将表拆分为小表后,每张小表加一个后缀以区分
3 分表后实现数据的主键全局唯一
数据库表的数据要确保有一个主键,如果在单表上,使用自增主键即可

但现在表已经拆分,如果每张表都使用自增主键,就会在连表查询时出现主键重复的情况

所以在分表后,需要解决的就是不同表中数据的主键如何实现全局唯一
3.1 方式一 用一张数据库表记录
如果新增数据并不频繁,那么可以在数据库创建一张表,每次新增数据时,先在这张表增加一条记录,再从这张表返回主键值给新数据,这就实现了每条新数据的主键全局唯一
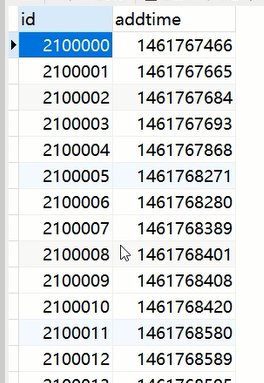
举例:
如下图,每次新增账户时,先到这张表新增一条数据,然后把新数据的id字段返回给新增账户,作为新增账户的主键值

3.2 方式二 redis序列生成器
如果新增数据频次很高,比如记录的是订单id,而订单的量很大,方式一就不合适了,会导致数据库压力增大
此时就可以通过使用中间件生成这个主键,比如redis,生成值、取值的代码如下
3.2.1 实现代码
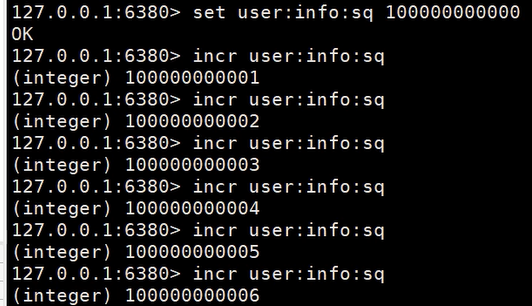
redis实现序列生成器是最简单的方式
//预先定义一个序列号
set user:info:sq 1000000000
//每次新增数据时用incr命令增加序列号并返回 这样每次取到的都是上一个序列号+1
incr user:info:sq
3.2.2 实现原理
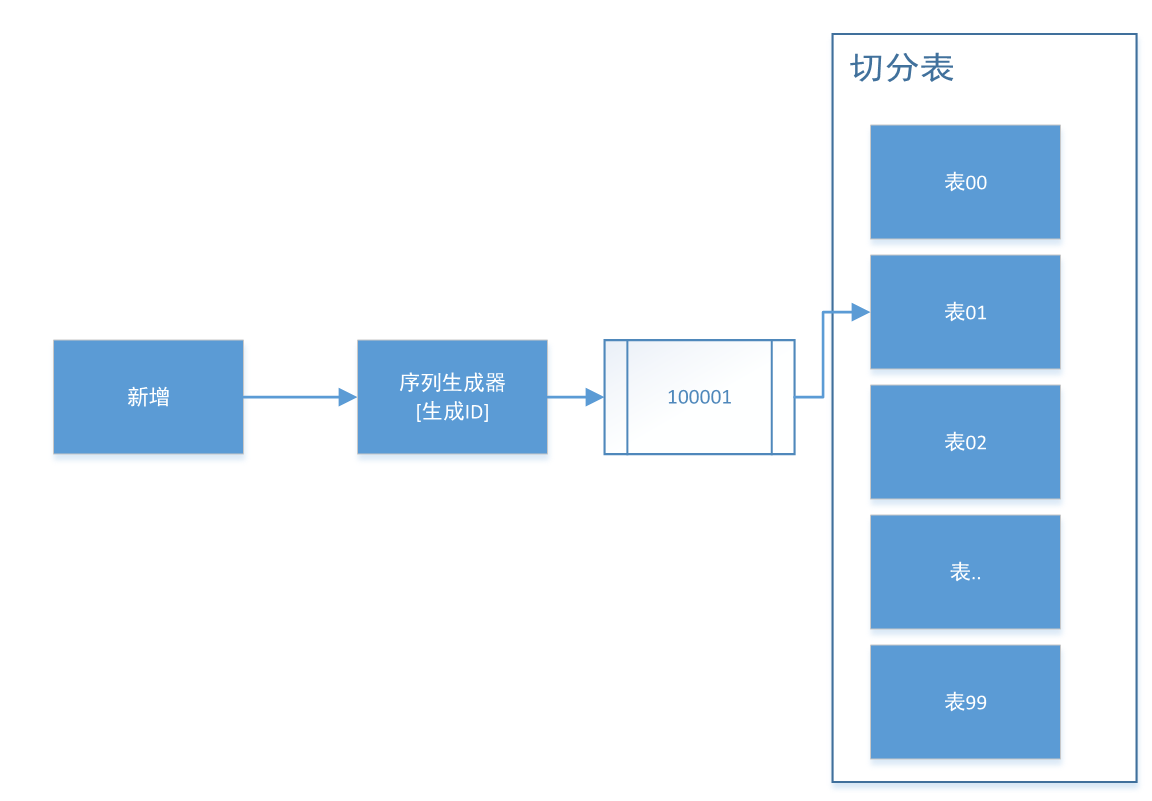
每次新增数据时,由序列生成器生成ID并赋给新增数据,再把数据存到切分好的表中
举例:
当ID为100001时,数据拿到ID后被存到了表01中;下一个新增数据拿到的ID为10002,此时数据会被存到表02中,以此类推
3.3 方式三 分布式序列生成器
如果数据吞吐量特别高,那么redis序列生成器就不管用了,例如微信,微信会给每一条消息都生成一个序列号,这种场景下就会产生很大的数据吞吐量
在数据吞吐量特别大的情况下,redis序列生成器就会达到瓶颈,这个时候就需要使用分布式序列生成器,序列生成器的底层原理是雪花算法,有兴趣可以去看看,如果想自己测试,至少要启动10台redis才能模拟这个算法。

