数据库中间件 mycat 介绍 实现mysql读写分离 mysql主从同步
1 引入
数据库作为一个项目最重要的部分,不允许出现任何差错,所以Mysql也要实现主从结构,读写分离,要实现这种结构,通常借助一个开源的数据库中间件Mycat
2 是什么
Mycat是阿里巴巴开源的数据库中间件,实现了 MySQL 协议的Server,其核心功能是分表分库,即将一个大表水平分割为 N 个小表,存储在后端 MySQL 服务器里或者其他数据库里。
- 对于软件工程师来说
Mycat 就是一个近似等于 MySQL 的数据库服务器,你可以用连接 MySQL 的方式去连接 Mycat(除了端口不同,默认的 Mycat 端口是 8066 而非 MySQL 的 3306,因此需要在连接字符串上增加端口信息),大多数情况下,可以用你熟悉的对象映射框架使用 Mycat,但建议对于分片表,尽量使用基础的 SQL 语句,因为这样能达到最佳性能,特别是几千万甚至几百亿条记录的情况下。
- 对于架构师来说
Mycat 是一个强大的数据库中间件,不仅仅可以用作读写分离、以及分表分库、容灾备份,而且可以用于多租户应用开发、云平台基础设施、让你的架构具备很强的适应性和灵活性,借助于即将发布的 Mycat 智能优化模块,系统的数据访问瓶颈和热点一目了然,根据这些统计分析数据,你可以自动或手工调整后端存储,将不同的表映射到不同存储引擎上,而整个应用的代码一行也不用改变。
简单来说,mycat就是一个代理,我们把它当数据库使用,但它实际不是数据库,而是一个java应用,它帮我们关联数据库以及执行sql语句并返回结果
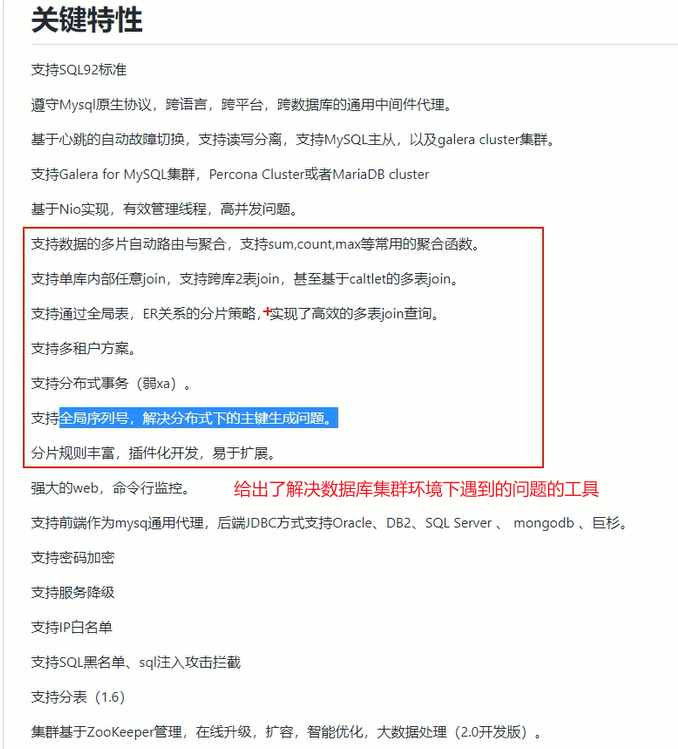
查看GitHub的官方readme,可以看到Mycat的功能介绍,其中的部分内容给出了解决数据库集群环境下遇到的问题的工具
说明:
1. 一般不会用Mycat的“基于心跳的自动故障切换”,因为数据库是一个很严谨的东西,假如在数据写入数据库时master数据库挂了,Mycat又自动切换数据库,就会导致数据丢失——master真挂了,要靠别的方式去解决(类似redis的aof机制),避免数据丢失,这是一个中间件无法解决的
2. 一般不会用Mycat的“分布式事务”
3. 一般也不会用Mycat的“全局序列号”,都用自己的独立的额外的解决方案
3 应用场景
-
单纯的读写分离,此时配置最为简单,支持读写分离,主从切换;
-
分表分库,对于超过 1000 万的表进行分片,最大支持 1000 亿的单表分片;
-
多租户应用,每个应用一个库,但应用程序只连接 Mycat,从而不改造程序本身,实现多租户化;
-
报表系统,借助于 Mycat 的分表能力,处理大规模报表的统计;
-
替代 Hbase,分析大数据;
-
作为海量数据实时查询的一种简单有效方案
4 安装
从GitHub下载安装包,放到Linux系统下的opt文件夹下,解压Mycat安装包,可以得到一个文件夹
tar zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
将文件夹移动到usr/local下,由于mycat是一个java程序,所以直接启动就行,相关配置在各种配置文件中
mv mycat /usr/local/
5 server.xml中的配置
在启动mycat前,需要修改server配置文件中的设定
cd /usr/local/mycat
vim server.xml
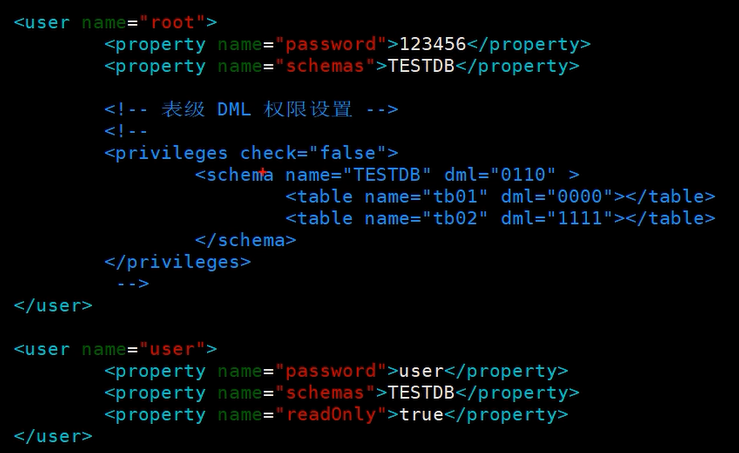
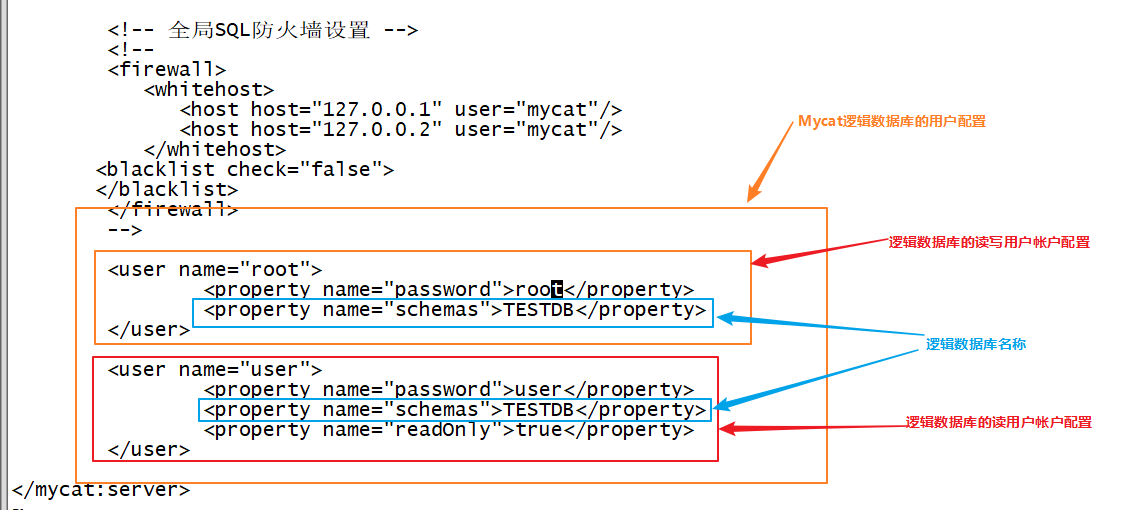
在server.xml里可以配置多个user标签,对应多个连接mysql的账号,每个账号通过
接着配置该账户对应的逻辑库“TESTDB”,每个逻辑库都可以基于privileges标签对库和表的权限进行设置,这种权限管理功能默认关闭,dml分为4个值,顺序为“增改查删”,0代表没有权限,1代表有权限,所以这里的0110表示只有改和查的权限
通过设置readOnly,可以令账号只具备查看权限
6 schema.xml中的配置
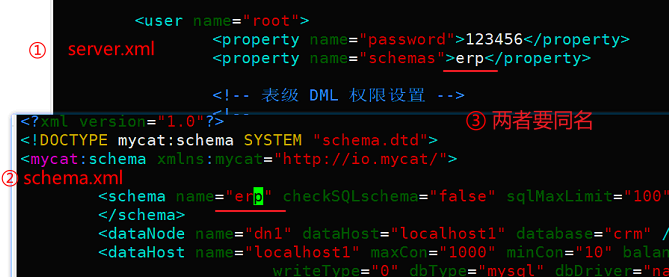
6.1 最终配置如图
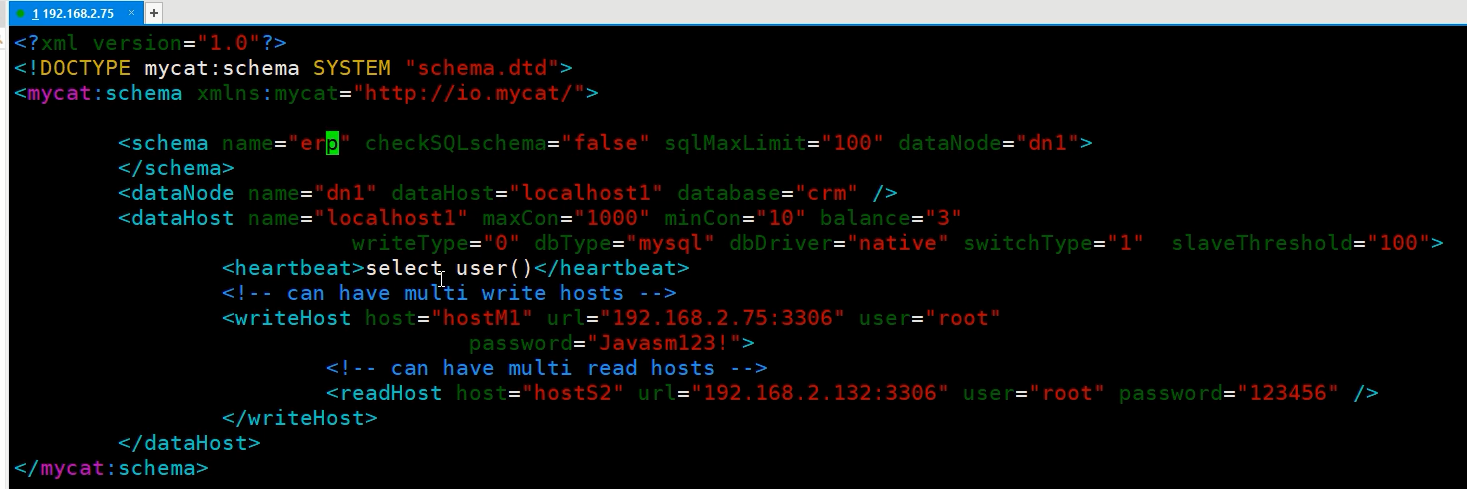
在schema.xml中可以配置逻辑库,包括创建逻辑库(用于在server.xml中使用)、将逻辑库映射到mysql数据库,简洁版配置最终代码如图
整个配置从上往下写,但理解上要从下往上看
6.2 dataHost标签
声明dataHost标签,这个标签里配置连接参数和心跳检测

6.2.1 配置连接参数
6.2.1.1 balance属性(实现读写分离)
dataHost标签中有一个balance属性,用于设置负载均衡模式,通常设为3,也就是开启读写分离
balance=0:不开启读写分离,所有读操作都发生在当前的writeHost上
balance=1:所有读操作都随机发送到当前的writeHost对应的readHost和备用的writeHost
balance=2:所有的读操作都随机发送到所有的writeHost,readHost上
balance=3:所有的读操作都只发送到writeHost的readHost上

6.2.1.2 writeType属性
这个属性默认值为0,通常使用时不需要配置
负载均衡类型,目前的取值有3种:
writeType="0", 所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .
writeType="1",所有写操作都随机的发送到配置的writeHost。
writeType="2",没实现。

6.2.1.3 switchType属性
这个属性默认值为1,通常也不需要修改
switchtype属性如下(控制自动切换的 )
-1不自动切换
1默认值自动切换
2基于mysql主从状态决定是否切换
6.2.1.4 dbType属性
就是设置逻辑库关联的数据库类型,通常就是mysql
6.2.1.5 dbDriver属性
默认为native,即本地的,通常也不需要修改

6.2.2 配置心跳检测(heartbeat标签)
- 拓展:mycat心跳检测的原理
在mysql中输入下面的sql语句,就能获得一条数据

所以mycat要做的就是对各个关联的数据库随便发送一个查询,只要能收到回复,就证明数据库存活
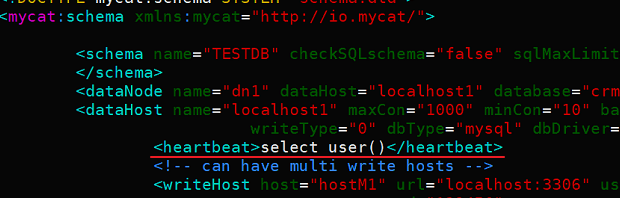
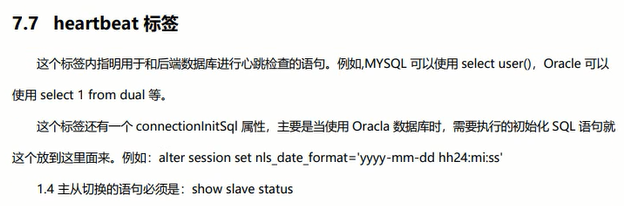
这个标签用于设置mycat执行心跳检测时发送的查询语句

6.2.3 writeHost标签
用于配置mycat连接的用于写入操作的mysql
6.2.4 readHost标签
用于配置mycat连接的用于读取操作的mysql,为了简化,只配置了一个readHost标签
6.3 dataNode标签
接着声明dataNode标签,这个标签关联mysql数据库以及dataHost
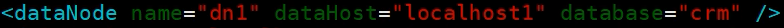
6.4 schema标签
最后声明schema标签,一个schema标签对应一个逻辑库,通过配置多个schema标签,实现创建和配置逻辑库
6.4.1 逻辑库关联server.xml的账户
创建的逻辑库的名字要与server.xml中配置账户时给的逻辑库名字相同,这才能将逻辑库关联到server.xml的账户
6.4.2 设置逻辑库查询mysql数据库时数据数量限制
- 拓展:mysql查询数据时多用limit
如果要直接查看mysql,建议直接双击打开表,因为这等于执行
select * from 表名 limit 1000
或者执行下面的代码(但也不建议用,只是+limit相对count+limit)
select * from 表名 limit 100
千万不要使用下面的命令
select * from 表名 //如果数据由1亿,就真的会去查1亿
select count from 表名 limit 100 //不要用count 这会扫描整个表 直接用*就行了
mycat查询mysql的数据时,可以设置每次返回的数量,等效于sql语句中设置limit,避免一次查太多数据导致mysql数据库崩溃


6.4.3 设置逻辑库关联的dataNode
每个schema标签关联一个dataNode标签,实现逻辑库的配置

7 启动mycat
- 拓展:报错 can`t get connection for sql
如果报错,如图表示心跳检测功能希望发送select user()到mysql,但没能成功,可能原因是给mycat配置的账户权限不足,如果mysql确实修改了账户权限,那么尝试刷新一下mysql的缓存或者重启mysql,令账户权限的修改生效

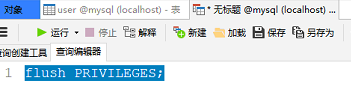
- 拓展:mysql的缓存
mysql也有自己的内存级的缓存,在启动时就把配置存到了内存中,所以如果手动修改了user表中账号的权限,要么手动重启mysql,要么执行下面的刷新语句,否则更新后的权限无法载入缓存
GitHub上的官方文档给出了运行指令,可以看出mycat是一个独立的进程

根据官方文档,使用命令启动mycat

8 mycat连接测试
启动mycat后,先进行连接测试
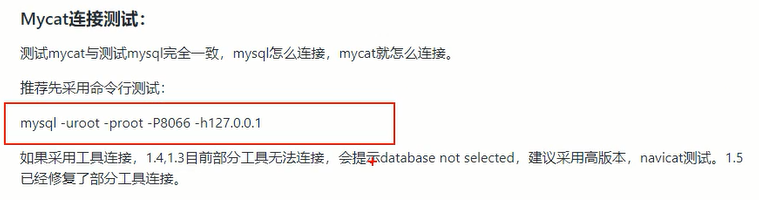
官方推荐采用命令行测试,类似mysql的连接方式
//mysql连接方式如下
mysql -u root -p
//mycat连接方式如下
mysql -uroot -proot -P8066 -h127.0.0.1
9 演示mycat的读写分离
上面配置并开启了mycat后,在win下,可以通过navicat查看mysql的主库和从库,主库配置在虚拟机中,从库配置在本地
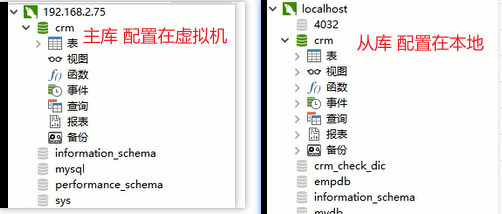
通过navicat连接mycat,可以看到mycat连接的表,这些表就是mycat通过mysql负责读取操作的库获得的表
点击这些表,修改表中的数据,数据不会显示出来,反倒显示在了主库,这说明通过修改这张表,实现了数据写入mysql负责写入操作的库,而修改结果不显示在这张表上,说明修改结果并没有同步到mysql负责读取操作的库中,也是就是说没有实现主从同步
但至少已经看得出,mycat实现了mysql的读写分离
10 设置主从同步
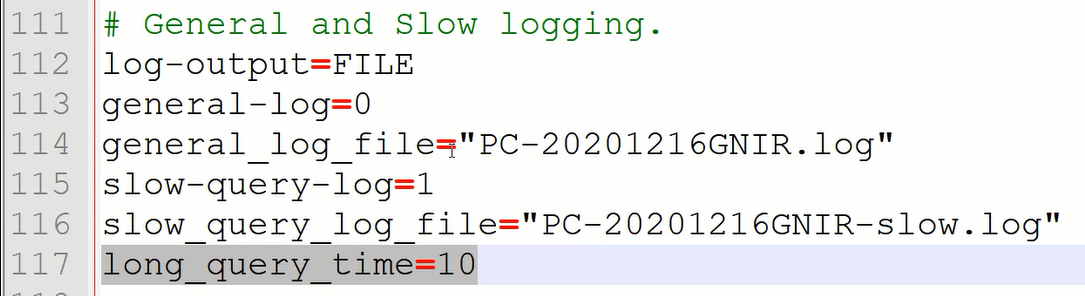
- 拓展:mysql配置文件之long query time
在mysql的配置文件中(my.ini),有一个配置叫“long query time” 默认为10,表示超过10秒的查询为慢查询,会被记录到log中,方便开发人员查阅以便优化sql或者表
- 拓展:mysql配置文件之max_connection
在win或mac系统的my.ini中,可以修改mysql的一些设置
其中max_connection=151代表最大并发数,可以把mysql看成插排,可同时接收151个插头,所以这151并不少,实际开发每个请求能用个1秒就了不得了,用完就走了,所以基本用不上修改

虽然已经配置了读写分离,但是还没有配置主从同步,所以数据写到主库后,并没有自动同步到从库
10.1 设置mysql主库的配置文件
mysql的主库配置在虚拟机上,因此需要在虚拟机中打开主库的配置文件,Linux系统中,环境配置文件放置在etc目录下
在Linux下的mysql配置文件默认属性很少,但只是默认没配置进去,并不代表没有这个属性,可以根据win下的mysql配置文件往上加
vim /etc/my.cnf
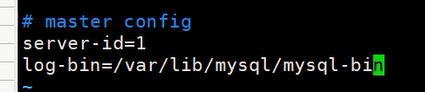
首先添加服务id配置,要保证唯一
server-id=1
然后开启二进制日志文件
log-bin=/var/lib/mysql/mysql-bin
最终配置如图
重启mysql
service mysqld restart
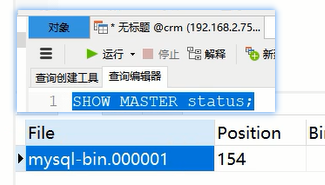
在navicat连接的主库下,执行sql语句,这能生成一个叫mysql-bin.000001的文件和position值,这两个数据用于配置从库
show master status;
10.2 设置mysql从库的配置文件
由于mysql的从库配置在本机,所以在win系统下搜索my.ini即可找到配置文件

首先添加服务id配置,要保证唯一
server-id=2
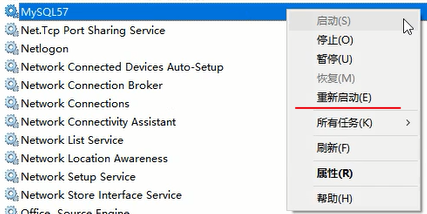
然后重启数据库,通过win+R启动“运行”弹窗,输入下面的命令,进入计算机管理窗口,执行重启操作
services.msc
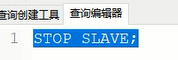
接着在navicat中,在从库下新建一个查询,输入停止从库的命令
接着执行下面的查询代码,将从库的master变更为执行master
change master to master_host='主库IP',
master_port=3306, master_user='主库用户名',
master_password='主库密码',
master_log_file='主库刚刚查到的File值',
master_log_pos= Position值;
最后执行下面的查询代码,重启从库
START SLAVE
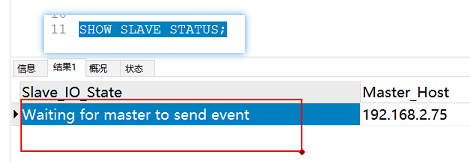
现在可以查看从库的状态,可以看到从库显示正在等待主库发送指令,现在我们再给主库修改数据,从库就能实时同步数据
10.3 演示主从同步
- 拓展:mysql从库同步主库的原理
从库同步主库的原理是主库发生变化时,主库发送指令告知从库,从库通过读取主库保存增量指令的日志文件实现数据同步,而主库保存增量指令的日志文件就是之前获得的file

现在依然通过mycat打开mysql的表,直接修改表中的数据,按下提交的“√”后,表上的数据并没有修改,但是刷新一下表,发现数据修改了
这一系列变化,首先说明mycat实现了mysql读写分离,然后说明了mysql实现了主从同步——之所以要刷新一下,是因为主从同步存在一定的延迟
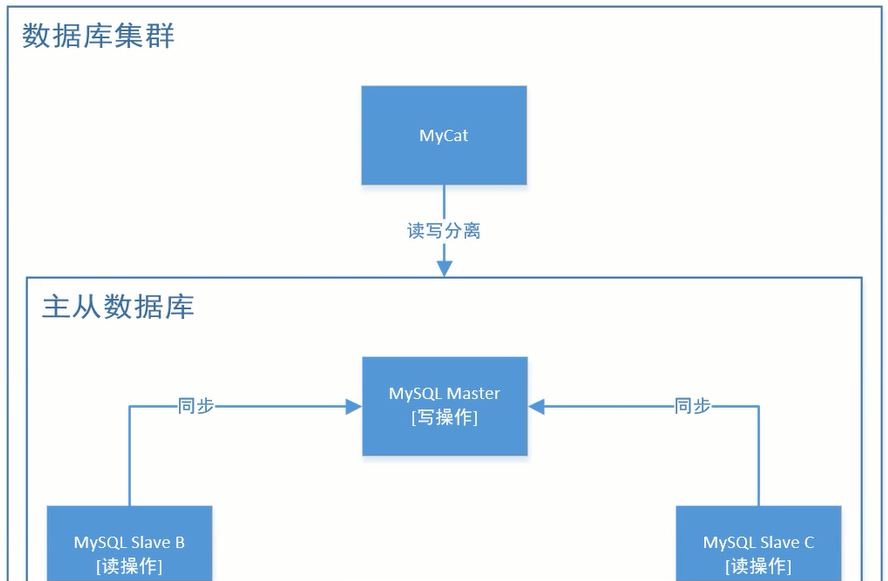
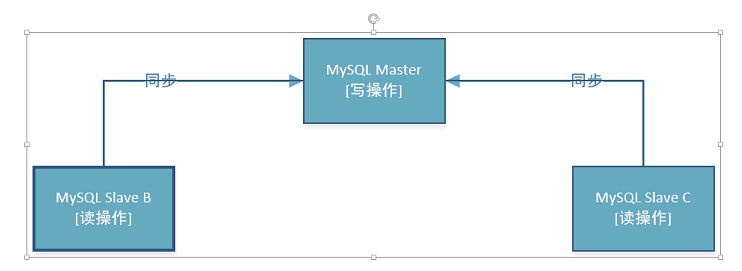
mycat实现读写分离以及mysql实现主从同步的流程如图,其中提到了弱一致性,指的是可以允许等待一段时间后,才达成一致性;相对的,强一致性则是要求一旦发生数据修改,立马同步
另一个概念是最终一致性,就需要等待很久才达成一致性,常见场景是前端发来许多订单请求,为了避免请求过多导致服务器阻塞,我们会把这些请求放在redsi中,为了避免redis崩溃导致数据丢失,所以每隔半小时把数据从redis保存到mysql中,放到mysql的过程就是达到最终一致性,在系统庞大的情况下, 我们都会追求最终一致性。
而强一致性的场景比如取款,一旦取出就要立刻达成一致,避免超额,实现手段是使用锁
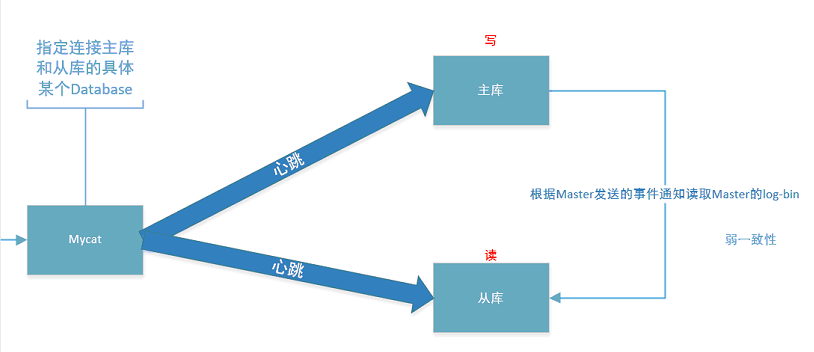
现在,整个数据库集群的结构如下