redi集群主从结构 以及 哨兵模式
1 redis集群的结构——主从结构
1.1 什么是主从结构
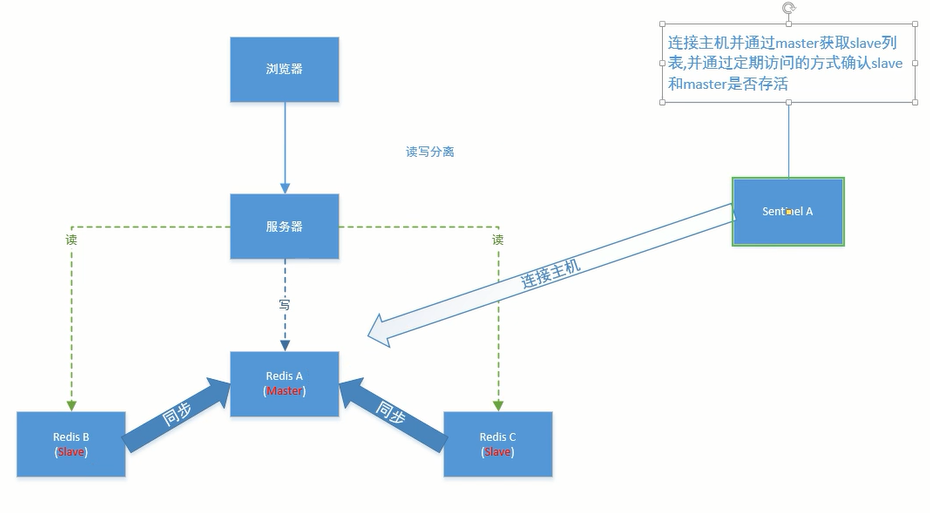
如图是常见的服务器架构,一个Nginx连接多个tomcat,每个tomcat共享一个redis

但是如果业务访问量巨大,一个redis又要写数据又要读数据,无法支撑业务,那么就要组建redis集群
假如现在组建的redis集群有三台redis,每台redis同时具备读写职责。
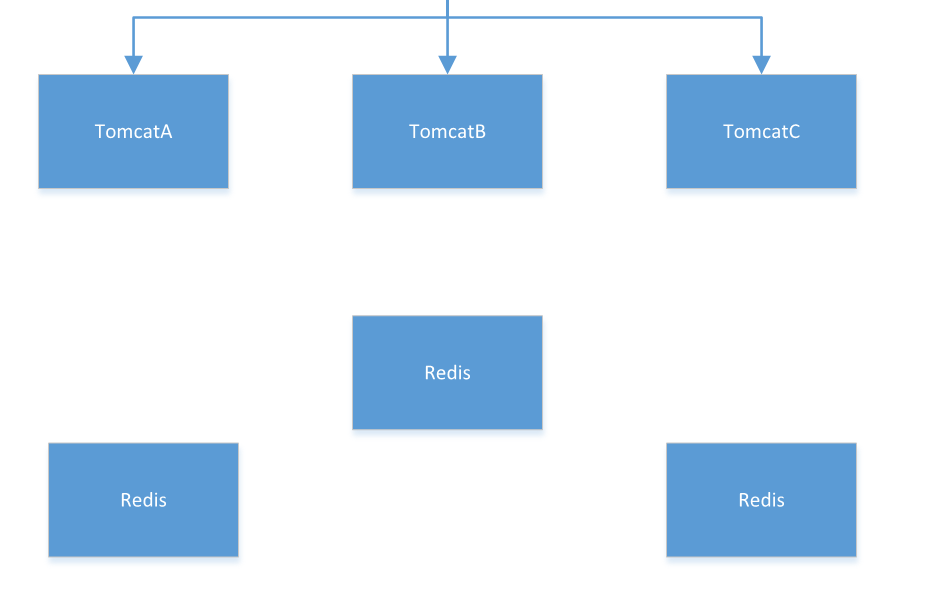
如果每台tomcat单独对应一台redis,一旦其中一台redis宕机,那么对应这台redis的tomcat就没办法查询数据了
如果每次查询都把数据保存在三台redis上,让三台redis分摊查询压力,那么每次写入redis都要写三次,一旦其中一台的写入操作出了问题,就会导致几台redis之间数据不一致,那么数据就不可靠了。
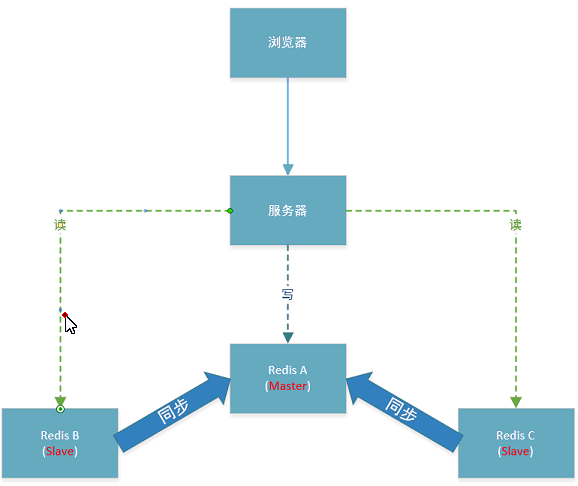
所以现在只让一台redis专门负责写,称为master,其他redis专门负责读,称为slave,为了保证数据一致,再让所有slave以master的数据为准,进行数据同步,整个结构如下图,这种结构叫主从结构,这就实现了redis的读写分离。
1.2 主从结构的特点
-
一个master可以有多个slave
-
除了多个slave连到相同的master外,slave也可以连接其他slave形成图状结构
-
主从结构可以用来提高系统的可伸缩性,我们可以用多个slave 专门用于client的读请求,比如sort操作可以使用slave来处理,也可以用来做简单的数据冗余
-
可以在master禁用数据持久化,只需要注释掉master 配置文件中的所有save配置,然后只在slave上配置数据持久化,这能保证master写入的性能最大化。
-
可以用于读写分离和容灾恢复。
-
假如master宕机了,那就会发生“可看不可写”的情况。
1.3 主从复制(主从同步)
master和slave之间的数据同步叫主从复制,主从复制不会阻塞master,但可能会阻塞slave。
当一个或多个slave与master进行初次同步数据时,master可以继续处理client(服务器)发来的请求(写入操作);相反slave在初次同步数据时则会阻塞不能处理client的请求(查询操作)
可以这样理解:初次同步数据属于全量更新,此时有大量的数据从master传到slave,为了避免查询到的数据错误,自然不允许响应查询请求,后续同步数据属于增量更新,数据量很少,所以允许随时查询
解决阻塞的操作:先逐个启动slave,等所有slave同步完成,再启动master
1.4 常见主从结构
在计算机领域,架构的节点数量都是3以上的奇数,所以下面的结构,至少要有3个redis
-
一主二仆 A(B、C) 一个Master两个Slave
-
薪火相传(去中心化)A - B - C ,B既是主节点(C的主节点),又是从节点(A的从节点)
-
反客为主(master节点down掉后,手动操作升级slave节点为master节点) & 哨兵模式(master节点down掉后,自动升级slave节点为master节点)
1.5 Linux下搭建主从结构redis集群
只需要知道所有数据库都有这种主从结构就行,项目中如何用后面再说
在linux系统中,如果直接运行三次redis-server,可以产生三个redis,但这三个redis都会默认被设置为master
所以要复制出多个conf,然后把其中两个redis.conf中的slaver功能打开,并指定master为第三个conf文件,然后写入访问master的密码,其他设置保持默认,此时分别指定这三个配置文件启动redis,就能搭建起主从结构redis集群
1.5.1 复制三个conf文件

1.5.2 修改主库的conf文件
包括:
-
修改端口
-
设置访问密码
-
删掉所有save设置(可选)
-
预设好要关联的主库密码(masterauth),避免挂掉时作为从库重启时还得先手动打开conf文件添加主库密码
1.5.3 修改从库的conf文件
以6380为例,6381同理
- 打开conf文件
vim /usr/local/redis-3.2.9_6380/6380.conf
- 修改端口
port 6380
- 设置要关联的主库ip和端口号

- 设置要关联的主库的密码

masterauth 主库的密码
- 将从库的端口号加入防火墙
firewall-cmd --permanent --zone=public --add-port=6380/tcp
firewall-cmd --reload
1.5.4 启动
先启动主库,再启动从库
redis-server 6379.conf &
redis-server 6380.conf &
redis-server 6381.conf &
根据需要,可以单独启动客户端
redis-cli -a 访问密码 -p 端口号
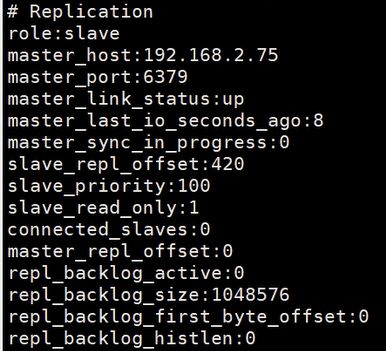
然后使用下面的代码查看当前redis的状态
info replication
状态如图,日志中可以看出,当前角色是slave,master的ip和port都已经显示出来
2 哨兵模式
2.1 主从结构的缺点
主从结构的一大问题就是master只有一个,这个master就是中心节点,如果master挂了,整个结构就瘫痪了。
解决办法就是“去中心化”,拿锁和钥匙比喻,master有钥匙,为了去中心化,就给每台slave都准备一把钥匙,一旦master失踪了,其他slave靠着手中的钥匙,依然能打开锁,但随之而来的问题就是每次换锁,所有人都需要重配一把钥匙。
所以无论是中心化结构还是去中心化结构,都有自己的优缺点。
2.2 哨兵模式介绍
去中心节点的一大难点就是让slave在master挂掉时自动升级为master,而借助redis的哨兵模式(sentinel)就能实现这个需求。
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
Redis Sentinel是一个分布式架构,包含若干个Sentinel节点和Redis数据节点,每个Sentinel节点会对数据节点和其余Sentinel节点进行监控,当发现节点不可达时,会对节点做下线标识。
如果被标识的是主节点,他还会选择和其他Sentinel节点进行“协商”,当大多数的Sentinel节点都认为主节点不可达时,他们会选举出一个Sentinel节点来完成自动故障转移工作,同时将这个变化通知给Redis应用方。
整个过程完全自动,不需要人工介入,所以可以很好解决Redis的高可用问题。
2.3 哨兵模式集群数量
redis 一般启动几个 哨兵_Redis6.0主从、哨兵、集群搭建和原理_守正出奇才的博客-CSDN博客
单个哨兵理论上就可以实现监控redis集群
但是因为网络波动等因素,一个哨兵可能存在误判的情况,所以要再加一个哨兵,但是两个哨兵可能存在平票的情况,此时就会僵持,如果又遇到了网络波动,导致互相接收不到对方的回复,误以为对方弃权,此时两个哨兵都去执行slave升级工作,最终导致redis集群中出现两个maser,显然这是不应该出现的
解决办法一:人工介入,但这会影响redis的高可用性
解决办法二:尽力避免网络波动,这就要从网络协议以及各种其他方面下功夫
解决办法三:再增加一台哨兵
综上所述,哨兵集群的数量必须得是奇数并且最少为3,如下
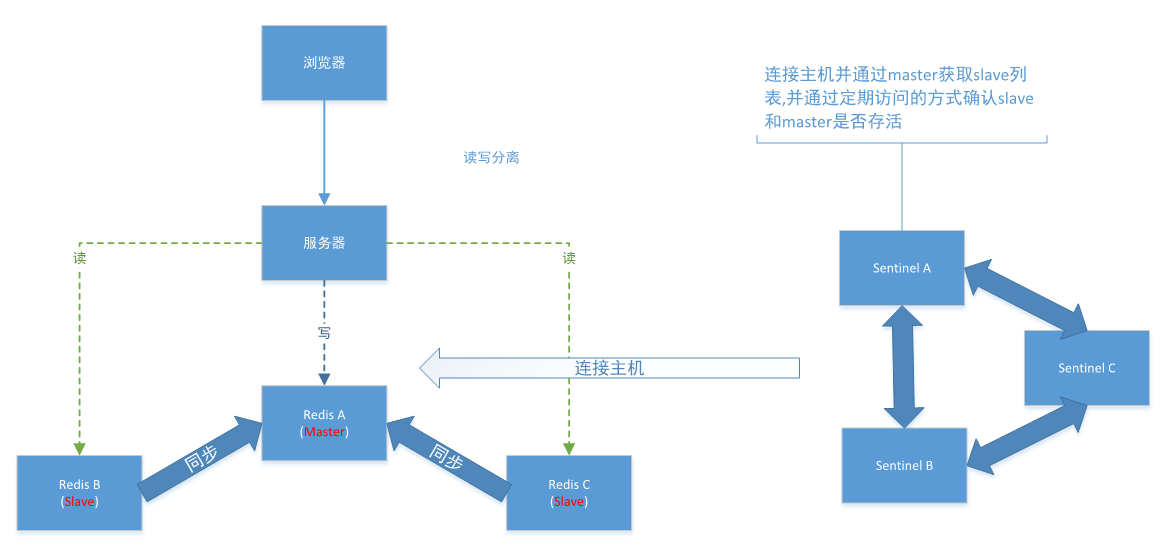
2.4 流言协议
当哨兵集群构建好后,整个集群就会监控redis集群,一旦redis集群中master发生宕机,各个哨兵就会经历判断宕机、选举负责本次升级的哨兵leader、投票选出新maser
这一套流程就是流言协议,所有中心化框架都会有这个协议
2.5 配置哨兵集群
2.5.1 备份conf文件
Linux中, Sentinel就放在redis包下,为了避免操作错误,首先备份sentinel.conf,再用vim编辑器修改参数
2.5.2 配置端口
配置当前哨兵使用的端口
port 26379
默认为26379端口 根据需求修改
2.5.3 设置ip
修改要监控的master的ip
sentinel monitor mymaster 127.0.0.1 6379 2
格式:sentinel <option_name> <master_name> <option_value>
该行的意思是:监控的master的名字叫做T1(自定义),地址为127.0.0.1:26379,行尾最后的一个2代表在sentinel集群中,多少个sentinel认为masters死了,才能真正认为该master不可用了。
修改实例

2.5.4 设置访问密码
若监听的端口有密码则需要配置
sentinel auth-pass <master-name> <password>
说明
要把自定义的master名字和master访问密码填入,与上面定义的master名字保持一致
修改实例

2.5.5 启用保护者模式
打开保护者模式(默认被注释)

2.5.6 设置心跳检测时间间隔
修改心跳检测间隔时间(可选)
sentinel down-after-milliseconds T1 15000
说明
sentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应PING 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了(subjectively down, 也简称为SDOWN)。而这个down-after-milliseconds就是用来指定这个“一定时间范围”的,单位是毫秒,默认30秒(30000)
2.5.7 设置淘汰过期时间
修改淘汰操作的过期时间(可选)
sentinel failover-timeout T1 120000
说明
failover指的是master宕机时,哨兵将其淘汰,默认180秒,即3分钟,如果超过这个时间还没有触发任何淘汰操作,当前sentinel将会认为此次failoer失败
2.5.8 设置主从同步速度
修改slave对新master进行同步的速度(可选)
sentinel parallel-syncs T1 1
说明
在发生failover主备切换时,这个选项指定了最多可以有多少个slave同时对新的master进行同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。
这个设置就要根据业务追求时效性还是一致性进行抉择,可以通过将这个值设为 1 来保证每次只有一个slave处于不能处理命令请求的状态
2.5.9 配置日志文件输出目录
为了便于查看操作记录,需要设置日志输出目录
logfile "/var/log/redis/sentinel-26379.log"
2.5.10 配置slave哨兵
把配置好的master的sentinel.conf复制出2份,使用vim编辑器打开,分别修改端口和日志输出目录的26379为26380、26381,这样就配好了两个slave哨兵
2.6 启动哨兵集群
逐一启动哨兵
src/redis-sentinel sentinel-26379.conf --sentinel &
src/redis-sentinel sentinel-26380.conf --sentinel &
src/redis-sentinel sentinel-26381.conf --sentinel &
启动完毕,查看进程

通常情况下,每台redis单独部署在一台电脑,哨兵集群部署在一台电脑
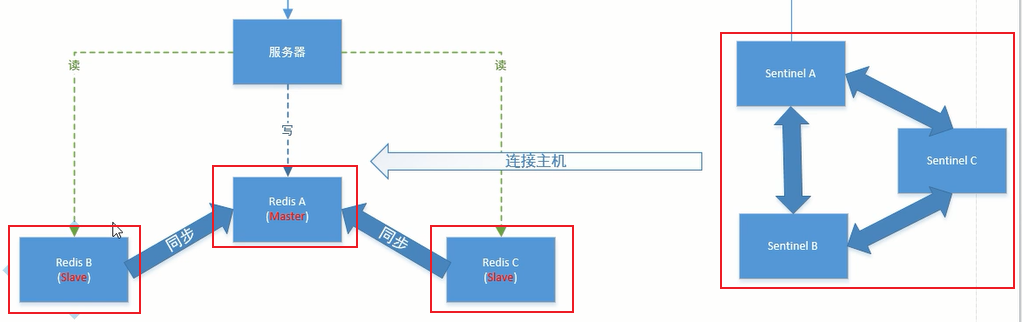
2.7 哨兵集群监控redis集群
为了模拟master宕机,手动使用kill指令让master挂掉,此时sentinel投票确认master宕机了,接着会选出新的master(试验时发现,被选中的slaver是随机的)
此时有以下举动
-
被选中的slave升级为master,反应到conf中,就是“slaver of”字段被删除
-
所有slaver连接新的master,反应到conf中就是“slaver of”后面接的地址被改变
-
宕机的旧master只能手动或运维使用脚本重启,哨兵无法帮忙重启
-
宕机的旧master重启后身份回退为slave,反应在conf中,就被加上了“slaver of ”字段

