Selenium学习
什么是selenium
Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。
selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。
这里要说一下比较重要的PhantomJS,PhantomJS是一个而基于WebKit的服务端JavaScript API,支持Web而不需要浏览器支持,其快速、原生支持各种Web标准:Dom处理,CSS选择器,JSON等等。PhantomJS可以用用于页面自动化、网络监测、网页截屏,以及无界面测试
引用自https://www.jianshu.com/p/3aa45532e179
Selenium安装配置
首先安装Selenium3
python3 -m pip install selenium
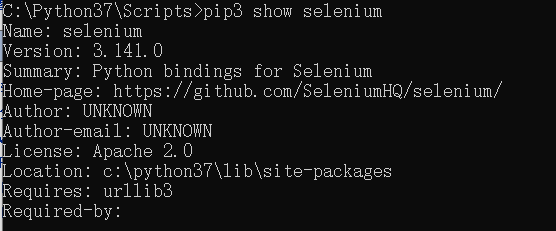
01 安装Firefox驱动
版本对照表:https://firefox-source-docs.mozilla.org/testing/geckodriver/Support.html
驱动releases:https://github.com/mozilla/geckodriver/releases
这里我直接讲驱动geckodriver.exe放入了C:\Program Files\Mozilla Firefox中,并且配置环境变量

02 安装Chrome驱动
版本驱动对照下载表:http://chromedriver.storage.googleapis.com/index.html
不一定要把chromedriver.exe放到浏览器目录中,只要将目录添加到环境变量中
Selenium基本使用
这里跟着RDD师傅的分享视频来学习几个点
像文本框输入/清空文字
demo:
from selenium import webdriver#导入库 browser = webdriver.Firefox()#声明浏览器 url = 'https:www.baidu.com' browser.get(url)#打开浏览器预设网址 print(browser.page_source)#打印网页源代码 browser.close()#关闭浏览器
可直接调用浏览器完成爬虫工作

browser.get(url)
driver.get方法会导向给定的URL的页面
这里我模拟进入百度页面,输入yunying
这里用xpath寻找ID
demo:
from selenium import webdriver#导入库 from time import sleep browser = webdriver.Firefox()#声明浏览器 url = 'https:www.baidu.com' browser.get(url)#打开浏览器预设网址 input_xpath='//*[@id="kw"]' browser.find_element_by_xpath(input_xpath).send_keys('yunying')
###
find_element_by_xpath() #以xpath语法查找element send_keys() #发送一些字符,类似键盘输入
需要用回车的话,需要用到click方法,,模拟点击百度一下的按钮
demo:
from selenium import webdriver#导入库 from time import sleep browser = webdriver.Firefox()#声明浏览器 url = 'https:www.baidu.com' browser.get(url)#打开浏览器预设网址 input_xpath='//*[@id="kw"]' browser.find_element_by_xpath(input_xpath).send_keys('yunying') submit_xpath='//*[@id="su"]' browser.find_element_by_xpath(submit_xpath).click() sleep(2) browser.quit()
###
click() 模拟点击
clear() 清除
###
如果需要清除写入的字符串的话,可以如下定义
from selenium import webdriver#导入库 from time import sleep browser = webdriver.Firefox()#声明浏览器 url = 'https:www.baidu.com' browser.get(url)#打开浏览器预设网址 input_xpath='//*[@id="kw"]' input_element=browser.find_element_by_xpath(input_xpath) input_element.send_keys('yunying') sleep(2) input_element.clear()
执行js脚本
###
execute_script() 是同步方法,用它执行js代码会阻塞主线程执行,直到js代码执行完毕;
execute_async_script()方法是异步方法,它不会阻塞主线程执行
demo:
from selenium import webdriver#导入库 from time import sleep browser = webdriver.Chrome('./chromedriver.exe')#声明浏览器 url = 'https:www.baidu.com' browser.get(url)#打开浏览器预设网址 #browser.execute_script('alert(1)'); browser.execute_async_script('alert(1)')
当需要下拉滚动条的时候可以用如下代码
window.scrollTo(0,10000)# window.scrollTo()方法,直接移动到指定坐标 window.scrollTo(0,document.body.scrollHeight)#直接拉到底部 document.body.scrollHeight 给出整个页面体的高度. window.scrollBy(0,1000)#Window.scrollBy()方法用来移动相对的偏移量 往下翻一页 browser.execute_script('window.scrollBy(0,window.innerHeight)') 往上翻一页: browser.execute_script('window.scrollBy(0,-window.innerHeight)')
但是我们发现,当在执行下拉滚动条的时候,用execute_async_script会出现script timeout的问题
详细的可以阅读这两篇文章解疑:
获取百度关键词标题
demo:
收集
from selenium import webdriver#导入库 from time import sleep browser = webdriver.Chrome('./chromedriver.exe')#声明浏览器 url = 'https:www.baidu.com' browser.get(url)#打开浏览器预设网址 input_xpath='//*[@id="kw"]' browser.find_element_by_xpath(input_xpath).send_keys('星盟安全团队') submit_xpath='//*[@id="su"]' browser.find_element_by_xpath(submit_xpath).click() sleep(2) one_submit='//*[@id]/h3/a' results=browser.find_elements_by_xpath(one_submit) for i in results: print(i.text)
用来收集标题
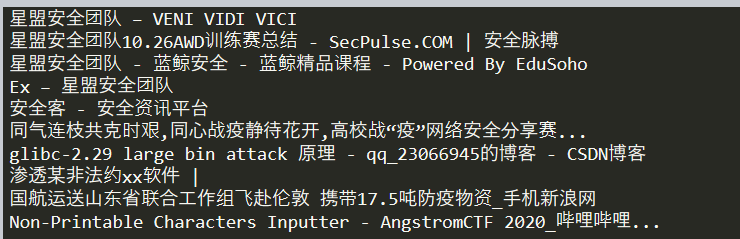
这里呢,如果不知道标题,但是想控制它去点击某个标题如何实现呢,使用input()函数
demo:
from selenium import webdriver#导入库 from time import sleep browser = webdriver.Chrome('./chromedriver.exe')#声明浏览器 url = 'https:www.baidu.com' browser.get(url)#打开浏览器预设网址 input_xpath='//*[@id="kw"]' browser.find_element_by_xpath(input_xpath).send_keys('星盟安全团队') submit_xpath='//*[@id="su"]' browser.find_element_by_xpath(submit_xpath).click() sleep(3) one_submit='//*[@id]/h3/a' results=browser.find_elements_by_xpath(one_submit) M_Element=input('id:') results[int(M_Element)].click()
通过交互,选择你需要的点击的标题链接
demo里有通过sleep()来暂停,因为页面需要加载,如果直接下一句的话,html还未渲染,找不到相关元素,会报错。但是一直要sleep,也不知道需要sleep多少秒,这里提供WebDriverWait()这个方法
demo:
from selenium import webdriver#导入库 from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait browser = webdriver.Chrome('./chromedriver.exe')#声明浏览器 url = 'https:www.baidu.com' browser.get(url)#打开浏览器预设网址 input_xpath='//*[@id="kw"]' browser.find_element_by_xpath(input_xpath).send_keys('星盟安全团队') submit_xpath='//*[@id="su"]' browser.find_element_by_xpath(submit_xpath).click() wait=WebDriverWait(browser,10).until(EC.presence_of_element_located((By.ID,'content_right')))#等到10s,直到某个元素加载完成则继续执行下面的代码 one_submit='//*[@id]/h3/a' results=browser.find_elements_by_xpath(one_submit) M_Element=input('id:') results[int(M_Element)].click()
优势就是不需要自定义sleep多少秒,不需要确定一个sleep时间,只要等元素加载完成,就可以执行下面的代码,更加的快捷
截屏
demo:
from selenium import webdriver#导入库 from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait from time import sleep browser = webdriver.Chrome('./chromedriver.exe')#声明浏览器 url = 'https:www.baidu.com' browser.get(url)#打开浏览器预设网址 input_xpath='//*[@id="kw"]' browser.find_element_by_xpath(input_xpath).send_keys('星盟安全团队') submit_xpath='//*[@id="su"]' browser.find_element_by_xpath(submit_xpath).click() wait=WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,'content_right'))) one_submit='//*[@id]/h3/a' results=browser.find_elements_by_xpath(one_submit) results[0].click() browser.save_screenshot('screen01.png')
发现截取的是当前的标签页,而不是刚打开的新标签页
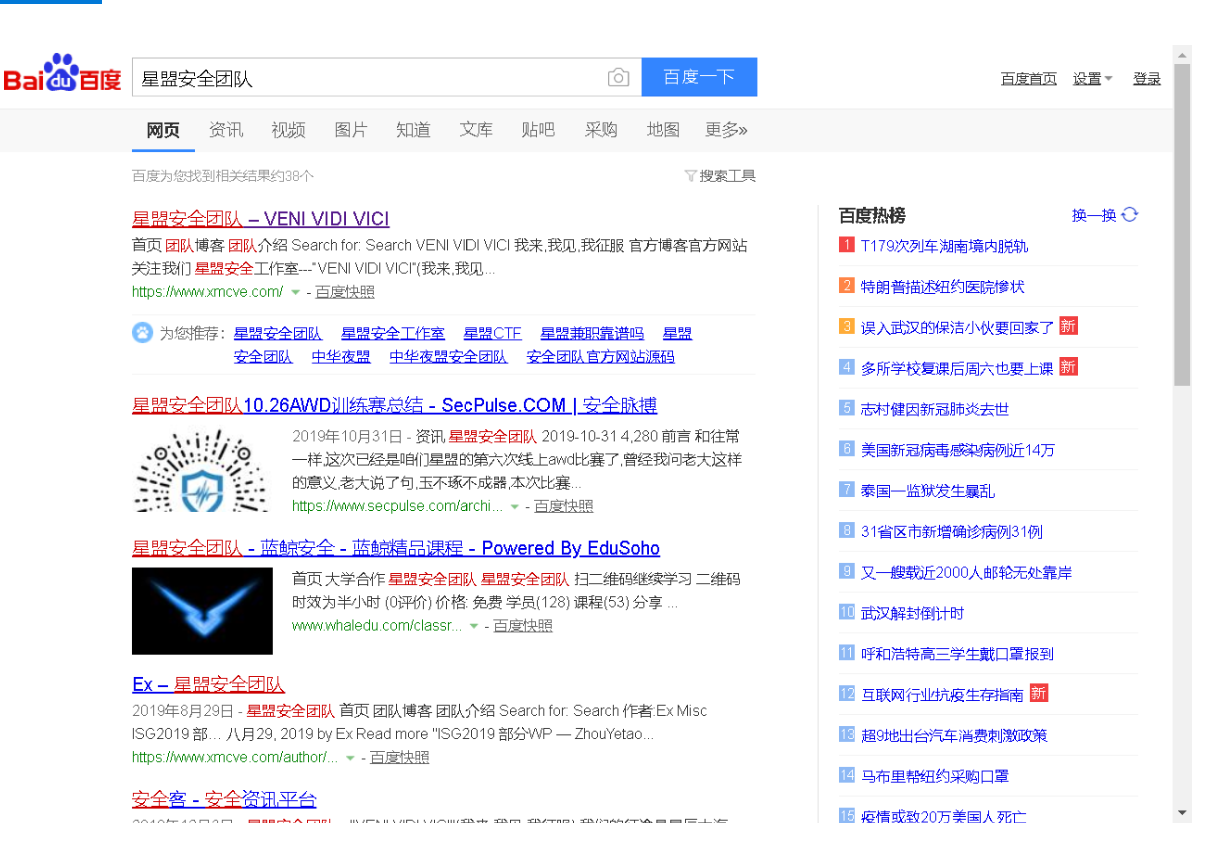
这里需要切换句柄
demo:
from selenium import webdriver#导入库 from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait from time import sleep browser = webdriver.Chrome('./chromedriver.exe')#声明浏览器 url = 'https:www.baidu.com' browser.get(url)#打开浏览器预设网址 input_xpath='//*[@id="kw"]' browser.find_element_by_xpath(input_xpath).send_keys('星盟安全团队') submit_xpath='//*[@id="su"]' browser.find_element_by_xpath(submit_xpath).click() wait=WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,'content_right'))) one_submit='//*[@id]/h3/a' results=browser.find_elements_by_xpath(one_submit) results[1].click() n = browser.window_handles print('当前句柄: ', n) # 会打印所有的句柄 browser.switch_to_window(n[-1]) browser.save_screenshot('screen01.png')

###
save_screenshot():参数是文件名称,截取的屏幕截图会保存在当前的目录下,即与模块在同一个路劲下 get_screenshot_as_file():也是获取屏幕截图,不过保存的是绝对路径 n = browser.window_handles #获取当前句柄 browser.switch_to_window(n[-1]) #切换句柄,即切换标签页 #如果需要关闭某个标签页,切换过去,然后browser.close()
页面回退、前进、刷新
demo:
from time import sleep browser = webdriver.Chrome('./chromedriver.exe')#声明浏览器 url = 'https:www.baidu.com' browser.get(url)#打开浏览器预设网址 input_xpath='//*[@id="kw"]' browser.find_element_by_xpath(input_xpath).send_keys('星盟安全团队') submit_xpath='//*[@id="su"]' browser.find_element_by_xpath(submit_xpath).click() wait=WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,'content_right'))) print('after search: ', browser.current_url) browser.back() print('after back: ', browser.current_url) sleep(2) browser.forward() print('after forward: ', browser.current_url)
#refresh(),刷新页面
因为无法上传视频,录屏软件没有gif输出格式。这里只用言语形容。
back()会控制页面又回到原来的最开始的百度的页面,然后再forward()后又会回到输入了星盟安全团队,并且回车的搜索页面

无界面化
demo:
from selenium import webdriver#导入库 from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.chrome.options import Options import time url = 'https:www.baidu.com' chrome_options=Options() chrome_options.add_argument('--headless') # 谷歌文档提到需要加上这个属性来规避bug chrome_options.add_argument('--disable-gpu') browser=webdriver.Chrome(chrome_options=chrome_options) browser.get(url)#打开浏览器预设网址 input_xpath='//*[@id="kw"]' browser.find_element_by_xpath(input_xpath).send_keys('星盟安全团队') submit_xpath='//*[@id="su"]' browser.find_element_by_xpath(submit_xpath).click() wait=WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,'content_right'))) browser.save_screenshot('screen02.png') time.sleep(6) browser.quit()
可以发现依然可以截到图片


