python3爬虫 爬取动漫视频
起因
因为本人家里有时候网速不行,所以看动漫的时候播放器总是一卡一卡的,看的太难受了。闲暇无聊又F12看看。但是动漫网站却无法打开控制台。这就勾起了我的兴趣。正好反正无事,去寻找下视频源。
但是这里事先说明,站长也不容易,提供这么好的动漫分享网站。这里就不把网站发出来了。喜欢这个站。只是想实践中锻炼,没有教授什么的含义。
第一天
思路
网站就匿了。F12无法打开,用开发者工具查看控制台,view-source查看源代码。
随便进入一部动漫查看源代码,发现加了调试,并且禁止了F12,禁止了右键等。(防止偷看QAQ)

利用Chrome的Deactivate breakpoints(使所有断点临时失效),然后刷新查看
选择集数后会跳转到播放器的html页面,重复相同的步骤。
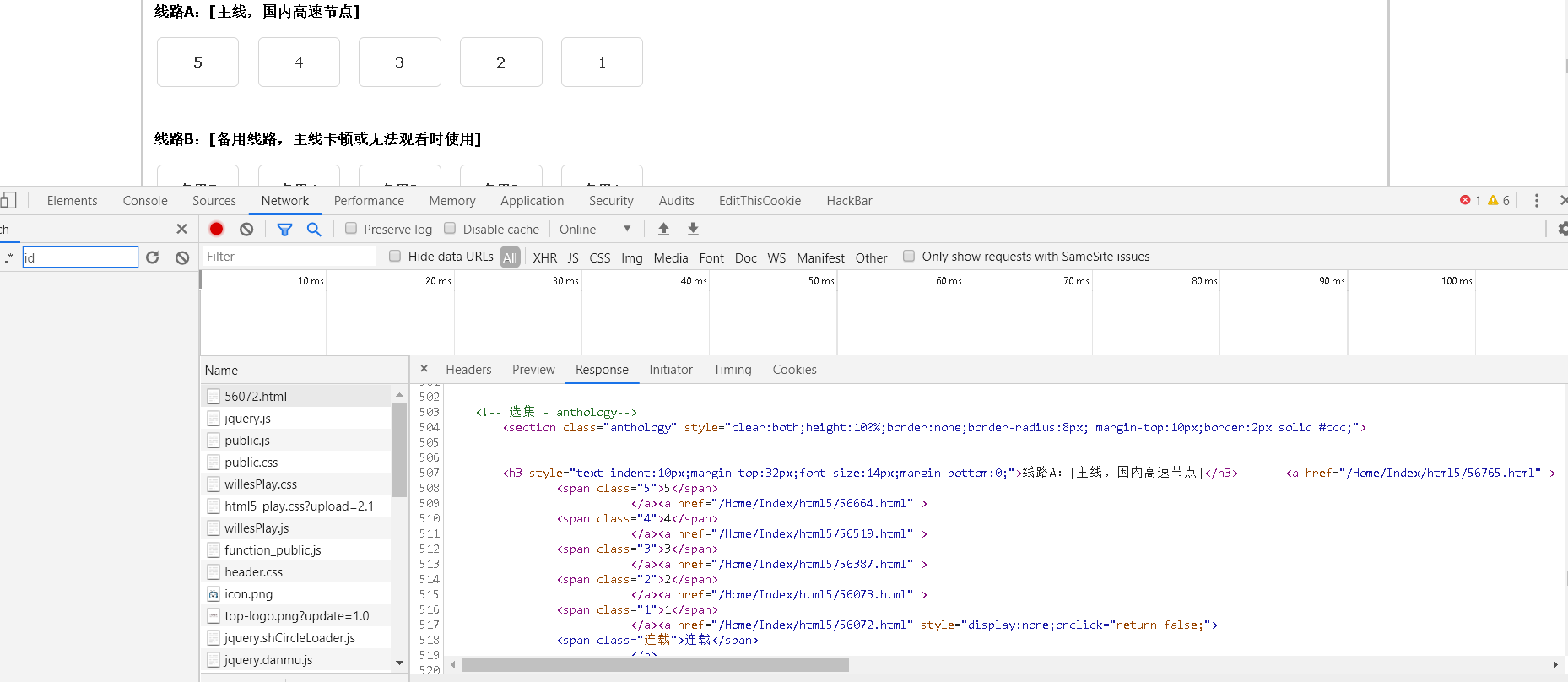
找到了相关api


发现这个api是播放器的地址
getData.html?video_id=56073&json=xml是弹幕的数据
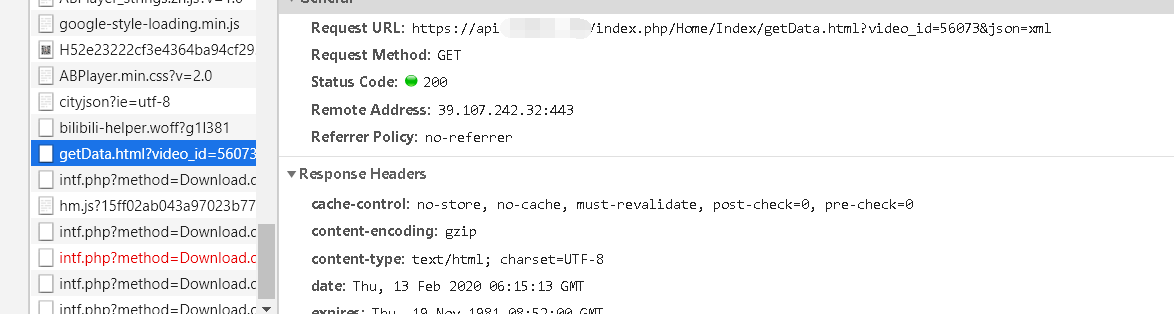
然后在api的主页源代码中发现了另一个动漫网站的地址


两个站竟然几乎一摸一样相差无几,难道是同一个站长。
然后api还是站点播放器的页面都有一串请求。发现是360云盘。
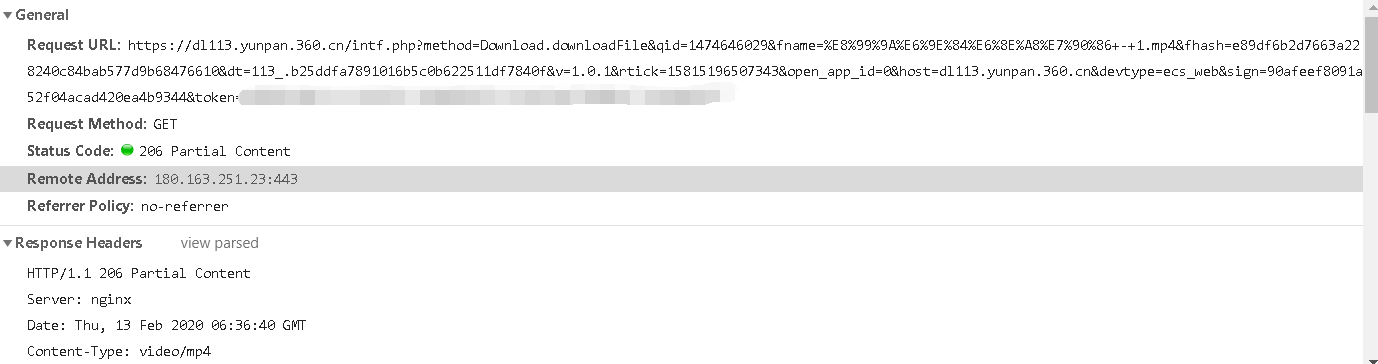
参数中的filename就是中文的urlencode了一下。
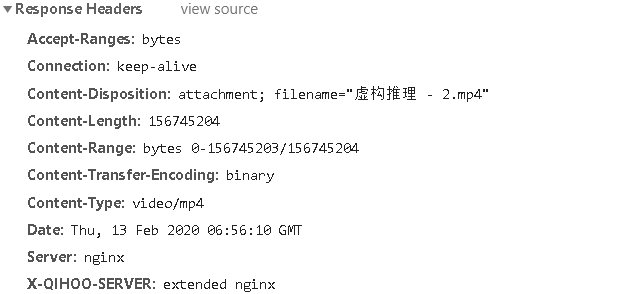
打开链接,就是Download的方法,而且直接是mp4格式。下载下来,可以直接观看。


所以该站点就是通过将api站点用播放器加载请求云盘资源,然后主站iframe嵌套过来。
如果这里要抓取的话,首先要知道动漫的id数字标识

然后进入页面获取不同集数的链接的ID即可,即56177,56714等。
这些数字ID对应了api链接中的nk参数,nk参数id对应了每部不同的动漫。简单的说,就是每部MP4的标识


获取完集数ID后,进入api界面,通过NK对应数字ID参数。一集一集的获取360云盘内的mp4资源链接保存下来。

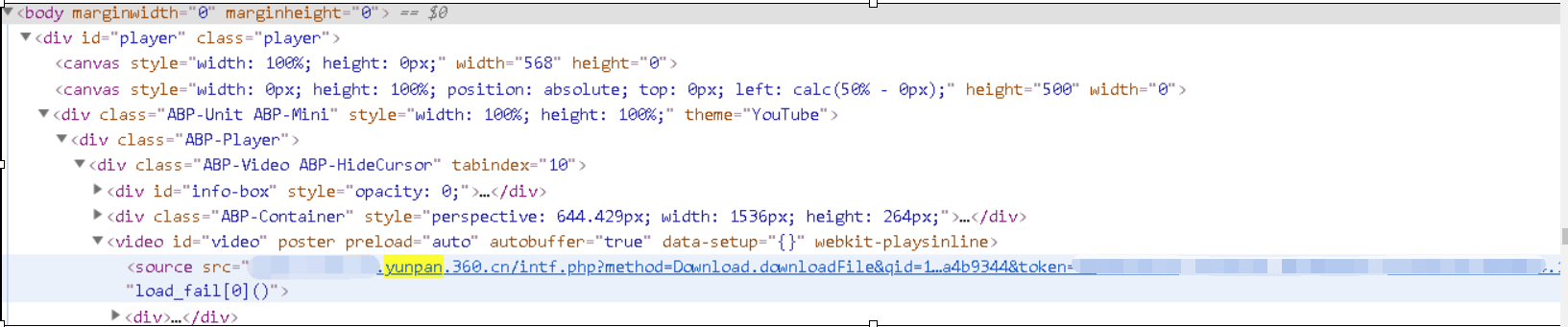
最后通过请求下载下来。
无意间测试了下搜索栏的xss,网站有宝塔。对于宝塔从没有研究过。网站是Thinkphp3.2.1框架。看似都是html,是tp的伪静态机制。
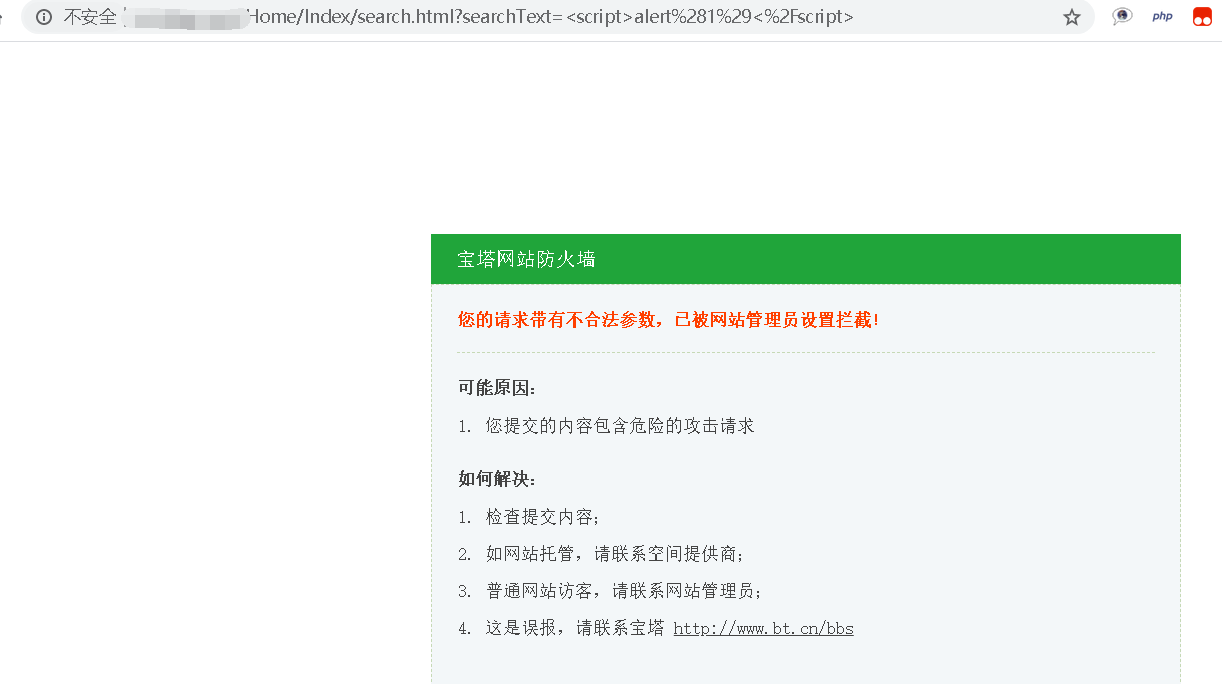
既然这里有搜索栏,那我们更加懒一下,不要自己去找动漫ID了,直接通过搜索栏中文搜索,然后得到动漫不同集数的不同ID保存,通过API调用获取资源链接,后请求下载。
实现
写爬虫废眼睛,脑子疼,关键是不同的动漫进去有的是有正版版权的链接,有的没有。
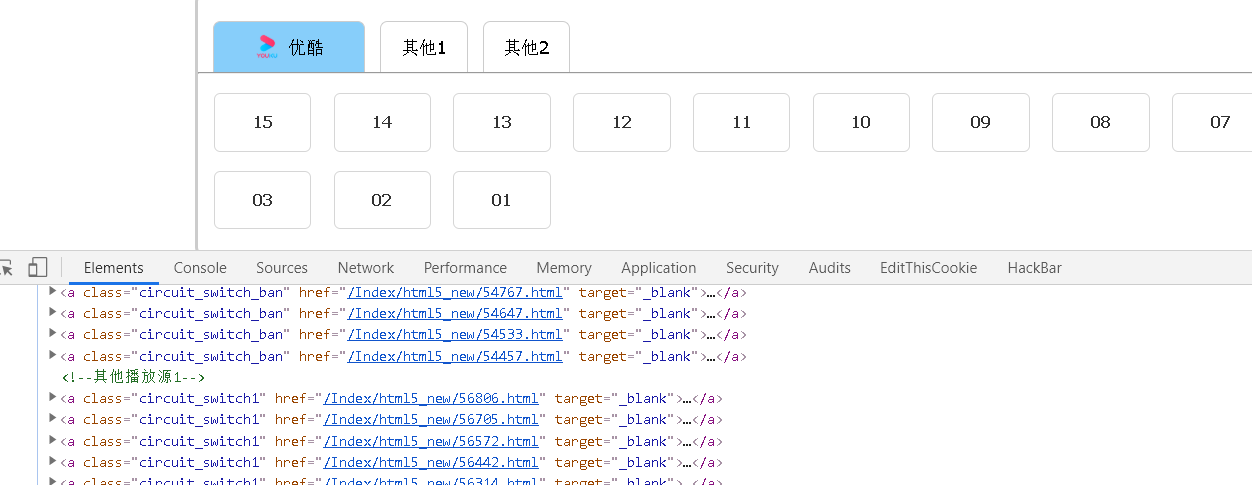
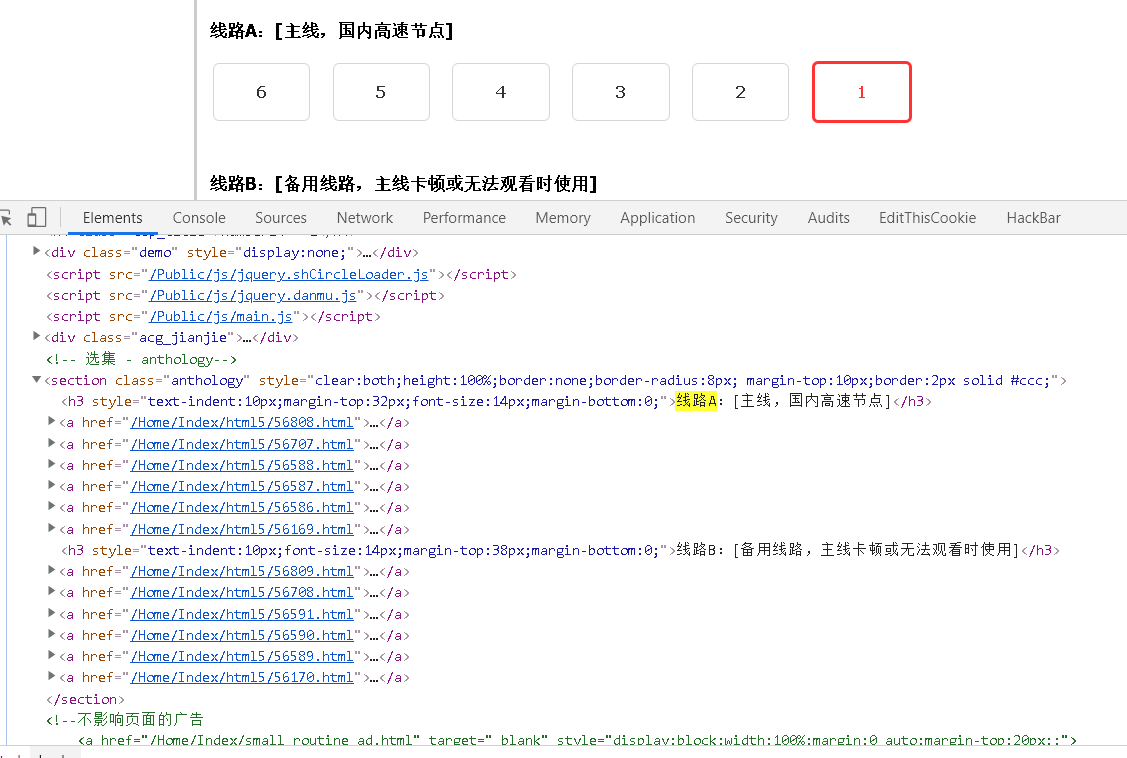
所以这里还得分情况。下面的代码只是自己打了个草稿,想写成类,写了一小部分,就先打个草稿。
import random import requests import re from bs4 import BeautifulSoup def getheaders(): user_agent_list = [ \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" \ "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \ "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \ "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \ "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \ "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \ "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] UserAgent=random.choice(user_agent_list) headers = {'User-Agent': UserAgent} return headers #url='http://www.xxxx.com DongM='虚构推理' list0=[] #集数的NK标识 number=0 #统计集数 pattern = re.compile(r'/(\d+).html') #re规则 params={"searchText":DongM} headers=getheaders() fireq0=requests.get(url=url+'/Home/Index/search.html',params=params,headers=headers) html0=fireq0.text bf = BeautifulSoup(html0,"html.parser") texts=bf.find_all('div',style="margin-left:18px;")[0].a['href'] fireq1=requests.get(url=url+texts,headers=headers) html1=fireq1.text bf = BeautifulSoup(html1,"html.parser") texts=bf.find_all('section',class_="anthology") if '其他1' in str(texts[0]) and '线路A' not in str(texts[0]): texts=texts[0].find_all('a',class_="circuit_switch1") number=int(texts[0].span['class'][0]) for i in range(number): list0.append(pattern.findall(texts[i]['href'])[0]) print(list0,'其他1线路') elif '线路A' in str(texts[0]) and '其他1' not in str(texts[0]): texts=texts[0].find_all('a') number=int(texts[0].span['class'][0]) for i in range(number): list0.append(pattern.findall(texts[i]['href'])[0]) print(list0,'线路A') else: print('解析线路出现问题') #print(texts[0].find_all('a')[0]['href'])
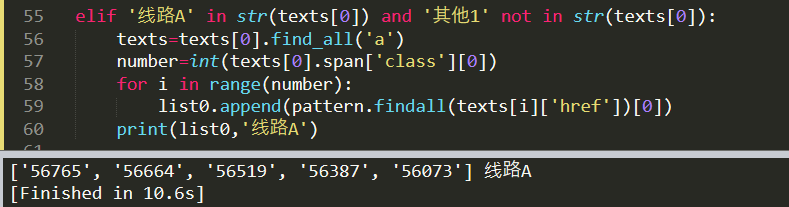
这样就获取到了动漫的集数的NK标识
第二天
今天尝试了下用urlretrieve去下载mp4动漫,发现应该是太大了。导致一直报错。
今天又看到了一些文章,找一下还有没有其他的下载方式。找到了requests的iter_content分块传输,相当于下载字节流的方式。而不是整个mp4下下来。
还有直接可以调用浏览器selenium库,这个后面再看。现场使用iter_content分块传输尝试。
并且发现了一些东西。
api界面的播放器请求头中会带着cookie和Range标识。但是探索发现,会发这么多请求,是因为你手动调整了播放器播放的位置,导致他会去重新请求,并且Range的位置,byte会改变到相应的位置对应的大小。
Range:0-
就是指定片头加载到片尾,就是表示0- 。大致意思是
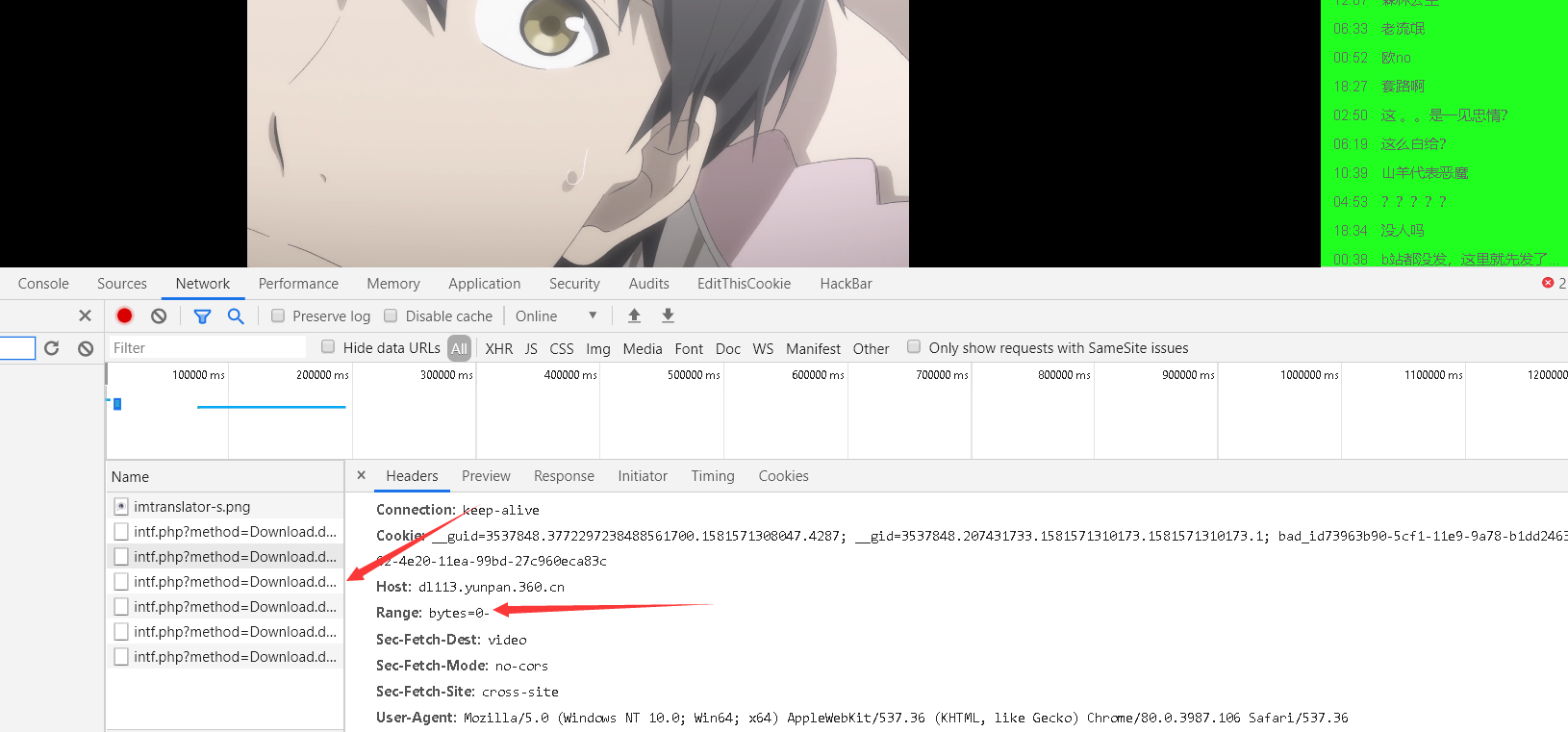
一但修改播放的进度,就会增加一个请求,Range也会从修改的地址,调节bytes
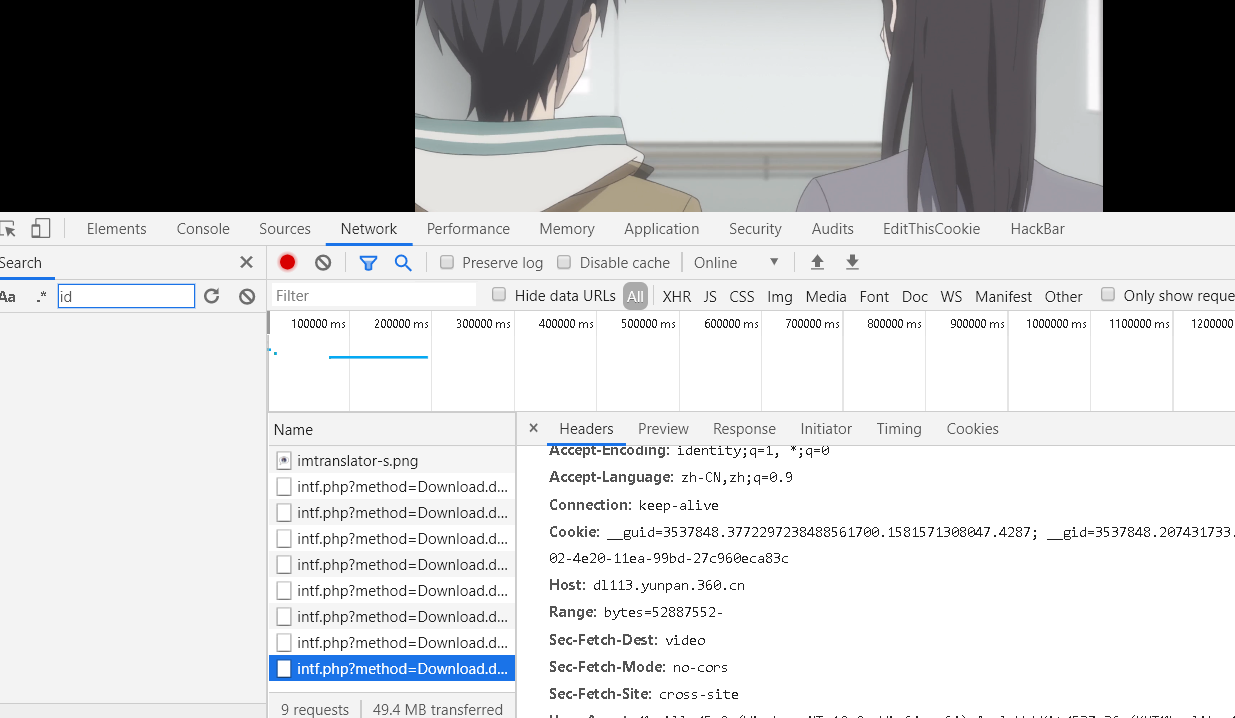
那如何知道总共需要下载的bytes有多大呢?可以从返回的Content-Length找到
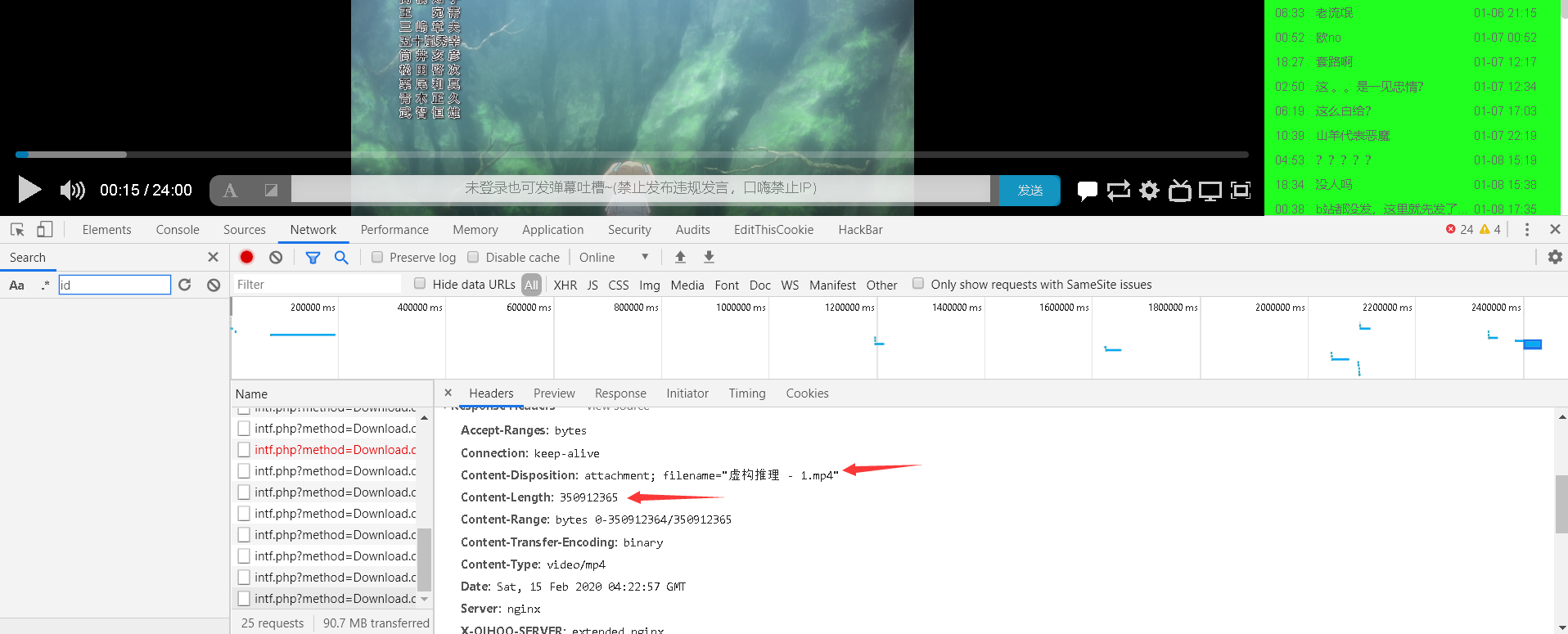
再根据学习的一篇文章(下面给出了链接)可以实现类似断点续传。但是我发现只下载一分钟的视频流的话,无法观看,应该是视频完整性的加密的一些东西。只能一整部下下来才可以。
看文章的时候又看到了一个方便的库,就不需要手动写user-agent了
from fake_useragent import UserAgent ua = UserAgent() print(ua.ie) #随机打印ie浏览器任意版本 print(ua.firefox) #随机打印firefox浏览器任意版本 print(ua.chrome) #随机打印chrome浏览器任意版本 print(ua.random) #随机打印任意厂家的浏览器
这里我也想自动获取它的片名,看到返回信息的headers头中有,就通过切片获得,不过需要小小的转码


测试出现错误
fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached
解决办法:
下载: https://fake-useragent.herokuapp.com/browsers/0.1.11 并另存为:fake_useragent.json
def get_header():
location = os.getcwd() + '/fake_useragent.json'
ua = fake_useragent.UserAgent(path=location)
return ua.random
这里就不用fake_useragent了。不如直接手动了=-=
通过tqdm模块变成可视化进度条

基本的几个功能已经完成了。获取api功能,获取视频链接功能,下载功能。
这里呢我是想多线程去下载集数,每集用一个线程去下载。提高速度。
初稿完成。第三天改成类,看着舒服。这个与类的区别就是没有变成函数。一开始就是没这么想。没搞函数。明天改成类,看的更清爽。
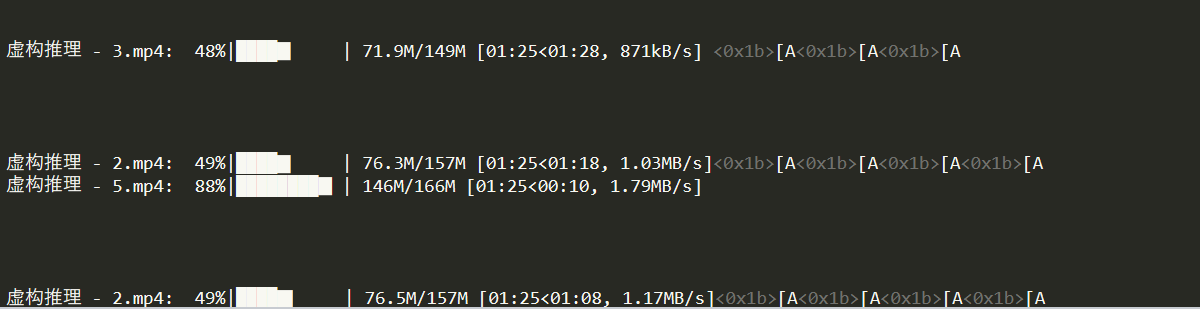
代码部分(url,api已打码):
import random import os import requests import re from bs4 import BeautifulSoup from tqdm import tqdm import threading def getheaders(): user_agent_list = [ \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" \ "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \ "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \ "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \ "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \ "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \ "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] UserAgent=random.choice(user_agent_list) headers = {'User-Agent': UserAgent} return headers #下载功能 def down_from_url(url, dst="test.mp4"): response = requests.get(url, stream=True) dst=response.headers['Content-Disposition'][22:-1].encode('raw-unicode-escape').decode() file_size = int(response.headers['content-length']) if os.path.exists(dst): first_byte = os.path.getsize(dst) else: first_byte = 0 if first_byte >= file_size: return file_size header = {"Range": f"bytes={first_byte}-{file_size}","user-agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'} pbar = tqdm(total=file_size, initial=first_byte, unit='B', unit_scale=True, desc=dst) req = requests.get(url, headers=header, stream=True) with open(dst, 'ab') as f: for chunk in req.iter_content(chunk_size=1024): if chunk: f.write(chunk) pbar.update(1024) pbar.close() def main(): threading_list=[] for i in list0: req0=requests.get(url='https://xxx.com/xxx.php?nk={0}'.format(i),headers=addheaders).text bf1=BeautifulSoup(req0,"html.parser") video_url=bf1.find_all('video',id="video")[0].source['src'] #多线程 added_Thread=threading.Thread(target=down_from_url,args=(video_url,)) threading_list.append(added_Thread) for i in threading_list: i.start() for i in threading_list: i.join() #搜索功能 url='http://www.xxxx.com' DongM='虚构推理' list0=[] #集数的NK标识 number=0 #统计集数 pattern = re.compile(r'/(\d+).html') #re规则 params={"searchText":DongM} addheaders=getheaders() fireq0=requests.get(url=url+'/Home/Index/search.html',params=params,headers=addheaders) html0=fireq0.text bf0 = BeautifulSoup(html0,"html.parser") texts=bf0.find_all('div',style="margin-left:18px;")[0].a['href'] #获取ID功能 fireq1=requests.get(url=url+texts,headers=addheaders) html1=fireq1.text bf = BeautifulSoup(html1,"html.parser") texts=bf.find_all('section',class_="anthology") if '其他1' in str(texts[0]) and '线路A' not in str(texts[0]): texts=texts[0].find_all('a',class_="circuit_switch1") number=int(texts[0].span['class'][0]) for i in range(number): list0.append(pattern.findall(texts[i]['href'])[0]) print(list0,'其他1线路') elif '线路A' in str(texts[0]) and '其他1' not in str(texts[0]): texts=texts[0].find_all('a') number=int(texts[0].span['class'][0]) for i in range(number): list0.append(pattern.findall(texts[i]['href'])[0]) print(list0,'线路A') else: print('解析线路出现问题') if __name__ == '__main__': main()
学习文章:
https://blog.csdn.net/qq_38534107/article/details/89721345
很感谢您看到最后,代码已经放到github
https://github.com/hui1314/python-spider
知识科普:
206状态码
HTTP/1.1 206状态码表示的是:"客户端通过发送范围请求头Range抓取到了资源的部分数据".这种请求通常用来:
- 学习http头和状态.
- 解决网路问题.
- 解决大文件下载问题.
- 解决CDN和原始HTTP服务器问题.
- 使用工具例如lftp,wget,telnet测试断电续传.
- 测试将一个大文件分割成多个部分同时下载.
这种响应是在客户端表明自己只需要目标URL上的部分资源的时候返回的.这种情况经常发生在客户端继续请求一个未完成的下载的时候(通常是当客户端加载一个体积较大的嵌入文件,比如视屏或PDF文件),或者是客户端尝试实现带宽遏流的时候。
urlretrieve
鉴于一些网站会检查user-agent的反爬机制。那就需要添加user-agent头部标识
opener = urllib.request.build_opener()
opener.addheaders=[('user-agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36')]
urllib.request.install_opener(opener)
req=urllib.request.urlretrieve(url='',filename='',reporthook=loading)

