IK分词器安装
ES 的默认分词设置的是 standard,会单字拆分进行拆分。
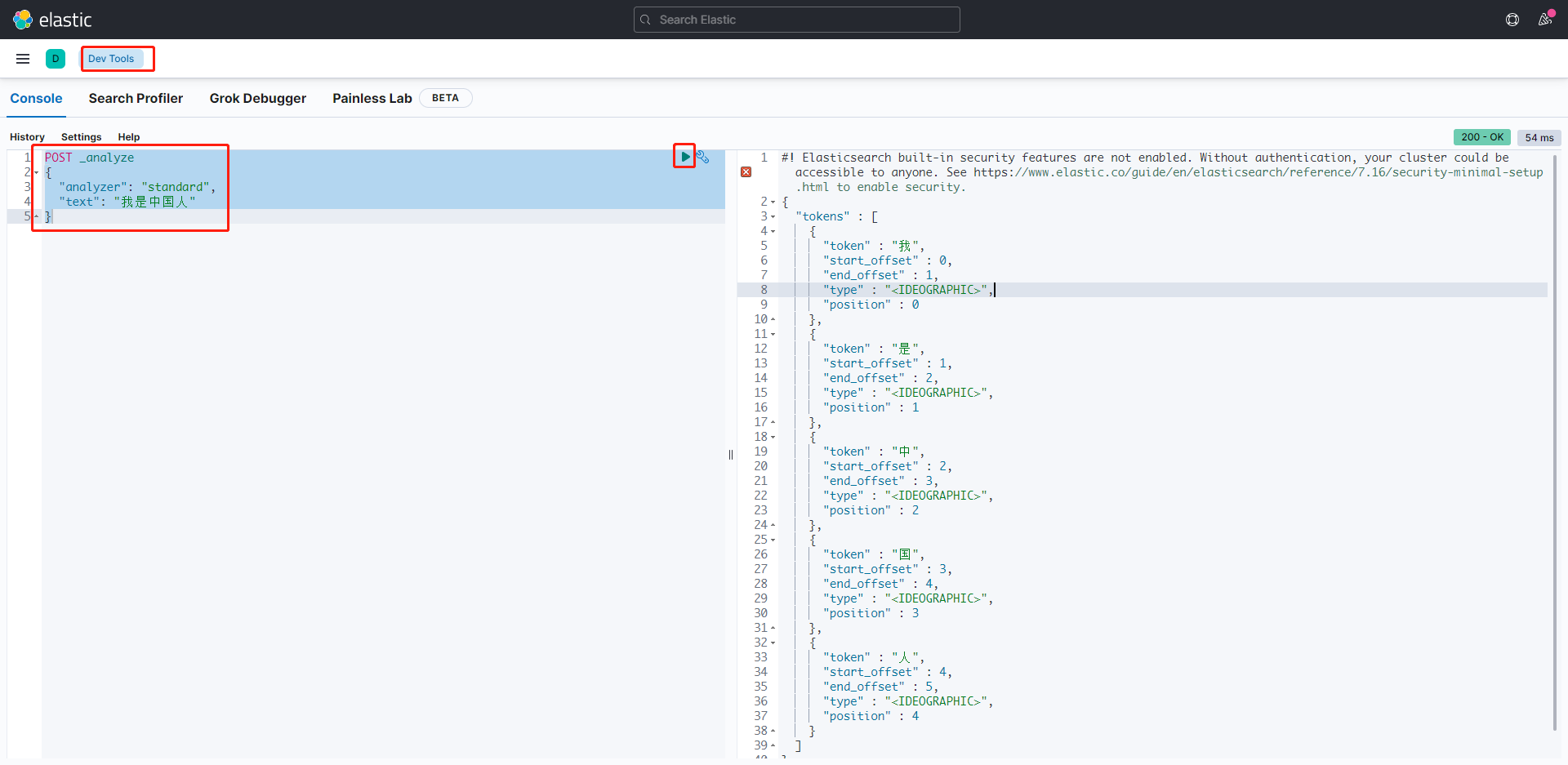
POST _analyze
{
"analyzer": "standard",
"text": "我是中国人"
}
概述
IKAnalyzer 是一个开源的,基于 Java 语言开发的轻量级的中文分词工具包。
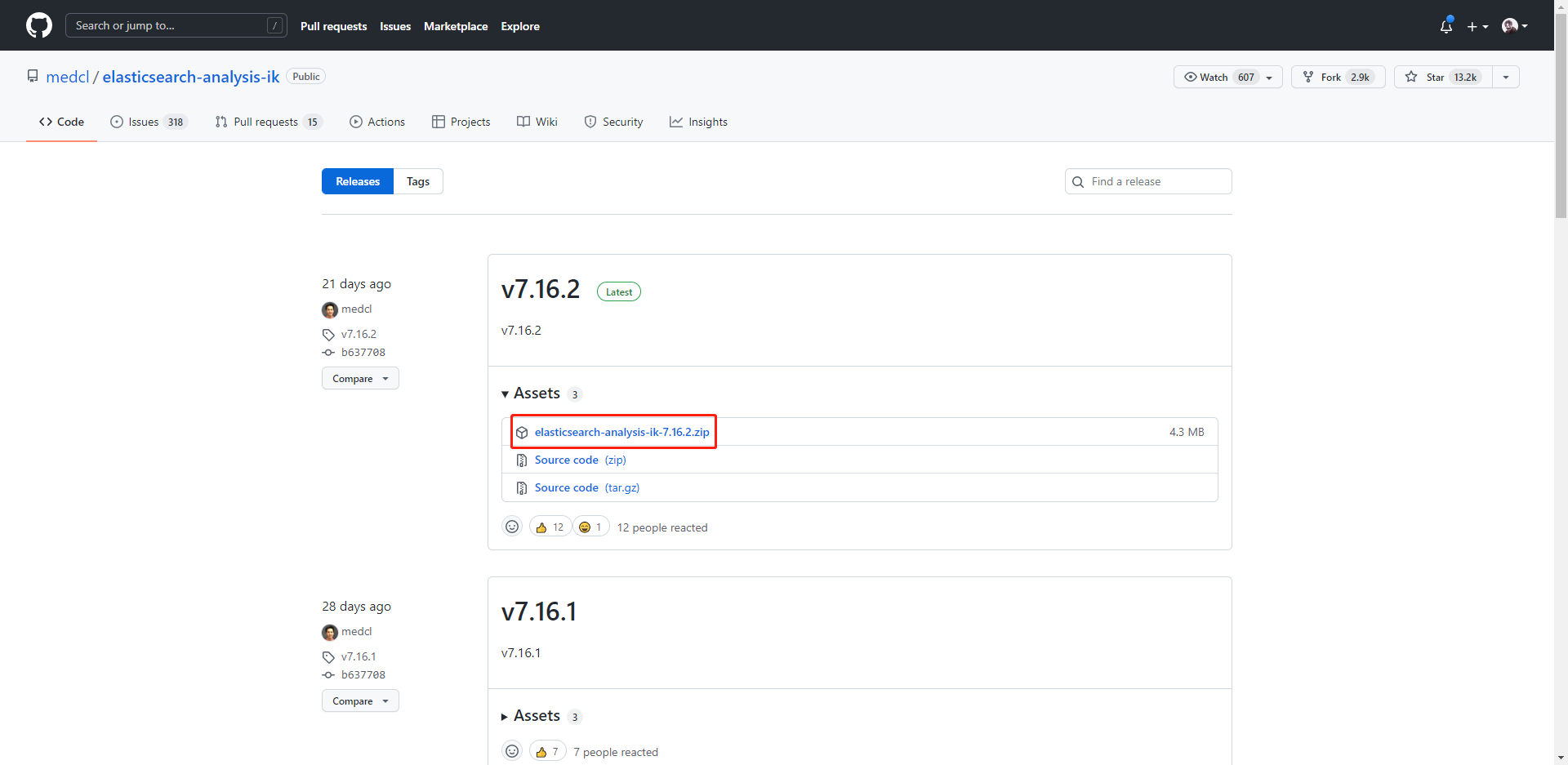
下载 Ik 分词器
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
IKAnalyzer 两种分词模式
ik_max_word:会将文本做最细粒度的拆分。ik_smart:会做最粗粒度的拆分。
配置 IK
将下载好的 zip 上传到 linux 当中,上传到之前新建的 plugins 目录当中,上传之前首先新建一个 ik 的文件夹然后上传到新建的 ik 文件夹当中:
mkdir ik
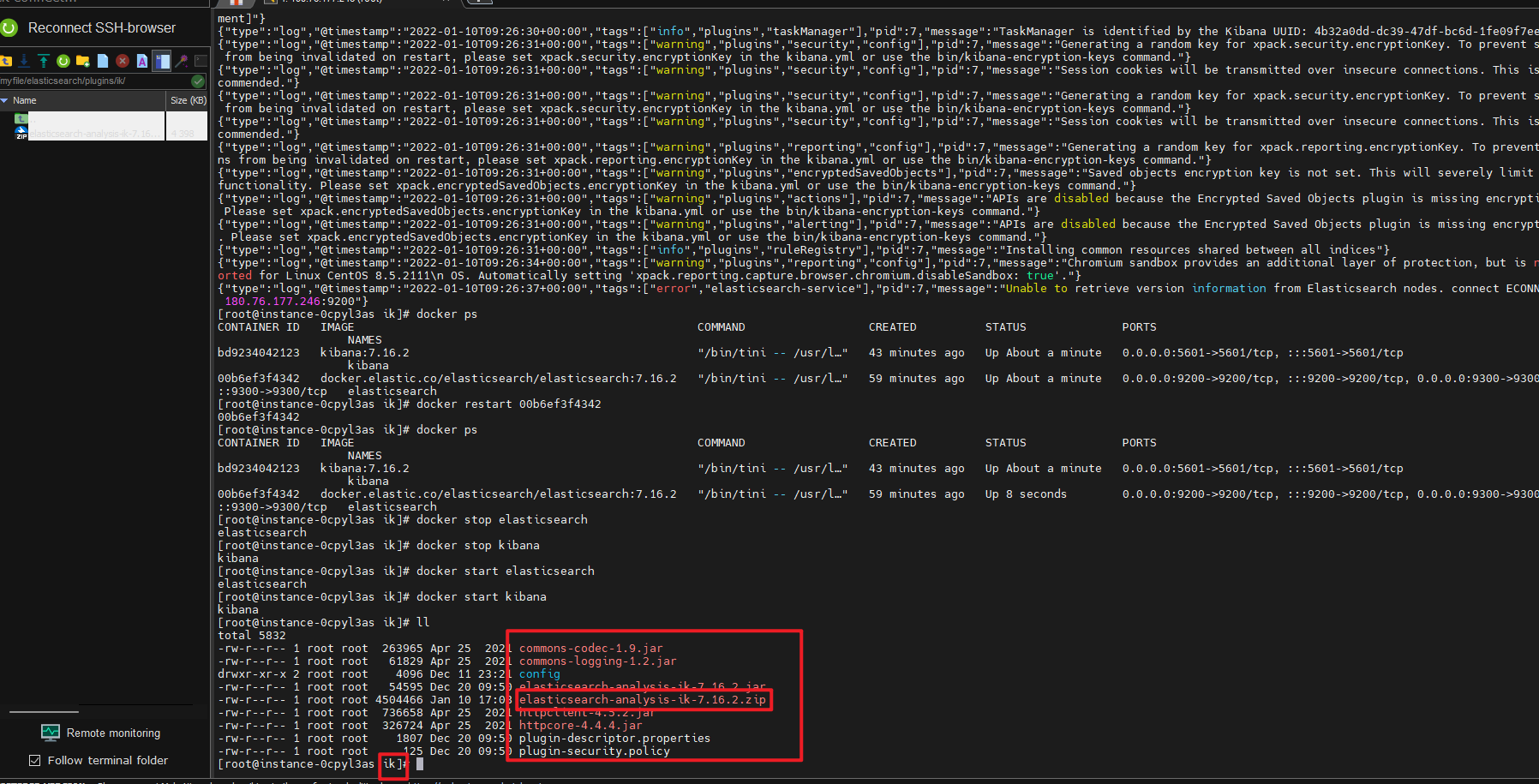
上传完毕之后利用 unzip 进行解压:
unzip elasticsearch-analysis-ik-7.16.2.zip
之后在重启 es 与 kibana 然后在 devTools 当中进行使用 ik 的 ik_max_word 进行查询效果如下:
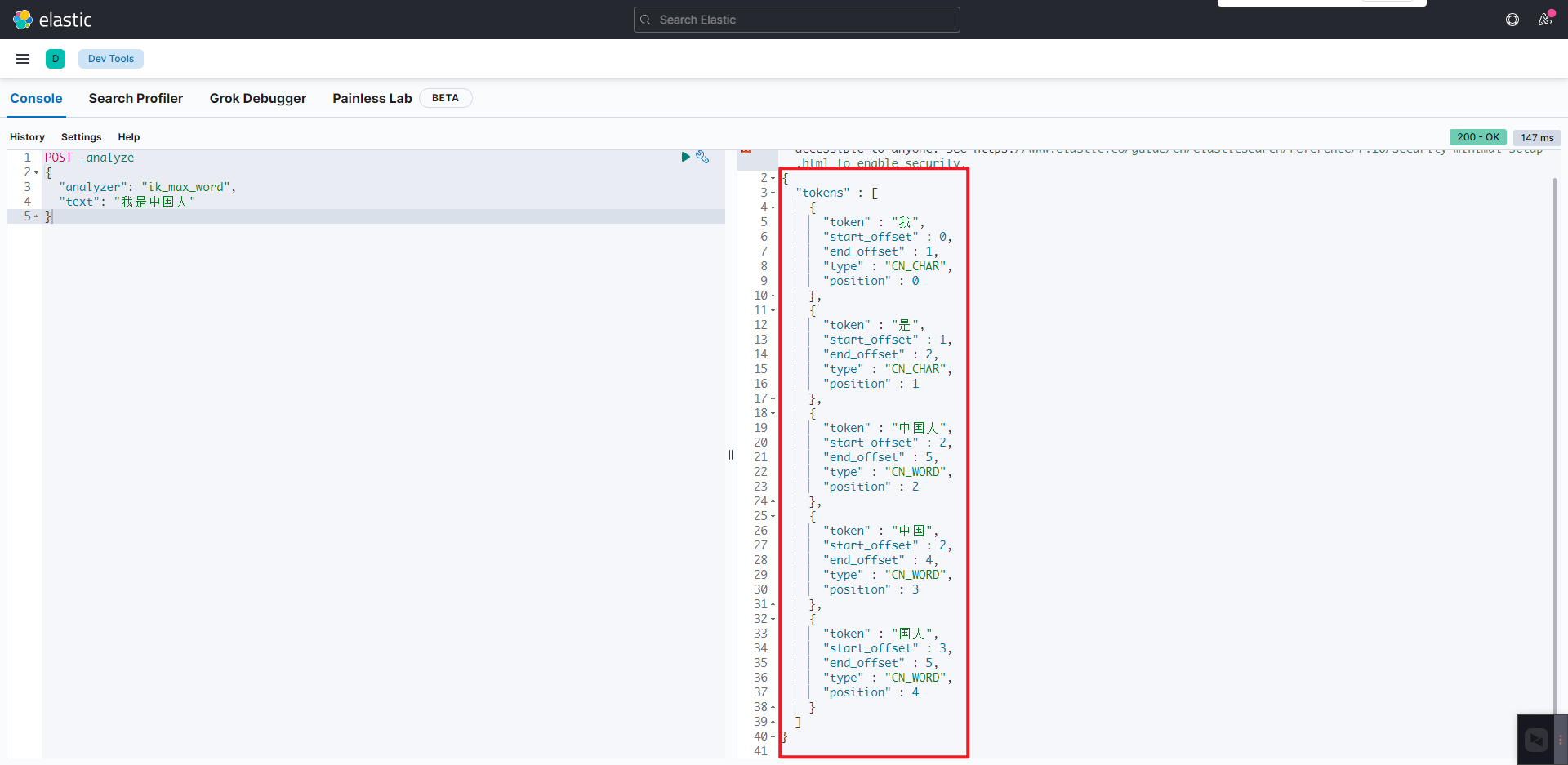
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
扩展词与停用词
扩展词
就是不想让哪些词被分开,让他们分成一个词。
停用词
有些词在文本中出现的频率非常高。但对本文的语义产生不了多大的影响。例如英文的 a、an、the、of 等。或中文的 ”的、了、呢等”。这样的词称为停用词。
设置扩展词或停用词
进入到 config 目录创建扩展词与停用词文件。
扩展词:
vim my_ext_dict.dic

假如如上的词它不是一个词,而我们又需要它是一个具体的词那么就可以像如上一样,添加到扩展词当中即可。
停用词:
vim my_stop_dict.dic
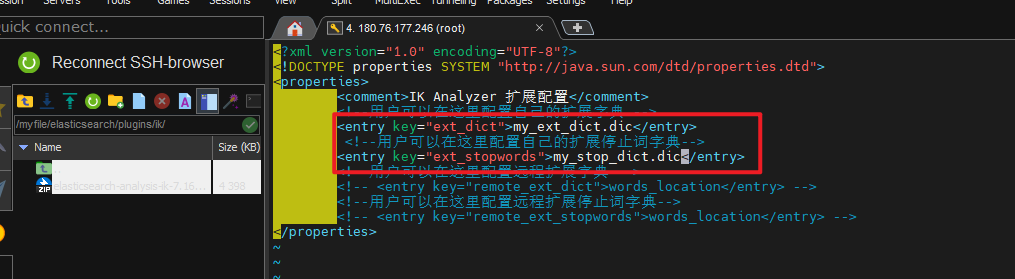
将自定义的扩展词典文件添加到 IKAnalyzer.cfg.xml 配置中。
重启 es 与 kibana 然后进行查询结果如下:
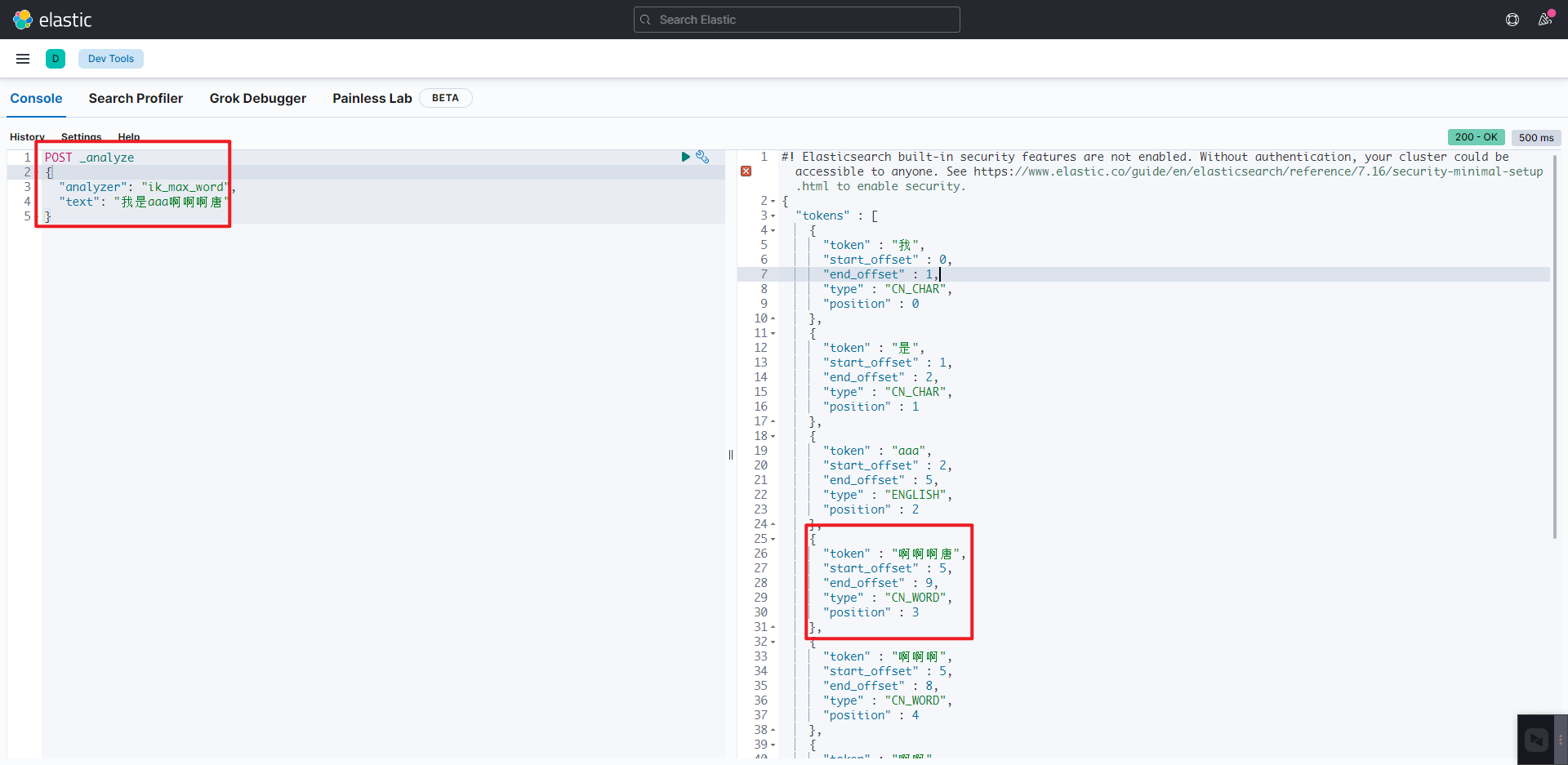
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是aaa啊啊啊唐"
}
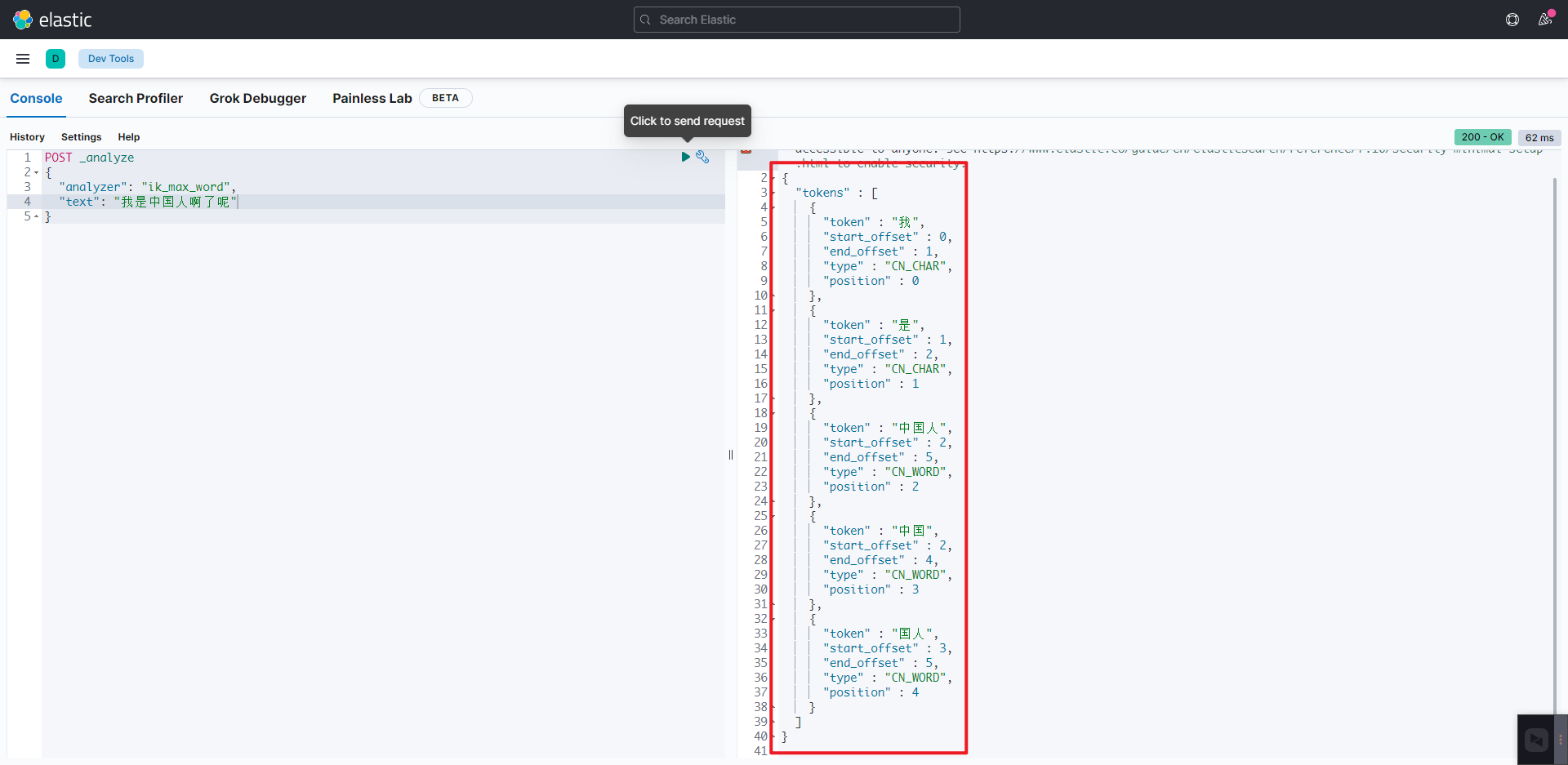
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人啊了呢"
}
设置 IK 分词器作为默认分词器
PUT /my_index
{
"settings": {
"index" :{
"analysis.analyzer.default.type": "ik_max_word"
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号