ShardingSphere读写分离与分片操作
经过上一篇 ShardingSphere实现读写分离 博主已经实现了读写分离的一个架构结构了,本文主要介绍的是在读写分离的情况下进行分片,就是分表存储操作,那么该如何实现呢,当然了,要实现读写分离加分片前提条件就是你需要上一篇当中所搭建好的读写分离结构,然后就是把博主之前讲解的分片操作相关配置拿进来即可,基于上一篇文章当中的 application.properties 的内容在添加分片相关的配置,分片配置如下:
# 负载均衡算法配置
spring.shardingsphere.rules.readwrite-splitting.load-balancers.round_robin.type=ROUND_ROBIN
# 配置t_order真实表规则
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds0.t_order_$->{0..1}
# 配置分表策略 主键+分片算法
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=tid
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=table-inline
# 配置 分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expression=t_order_$->{tid % 2}
# 主键盘生成策略
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=tid
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=snowflake
spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKE
spring.shardingsphere.rules.sharding.key-generators.snowflake.props.worker-id=1
然后需要修改一下读写分离的数据源名称即可:
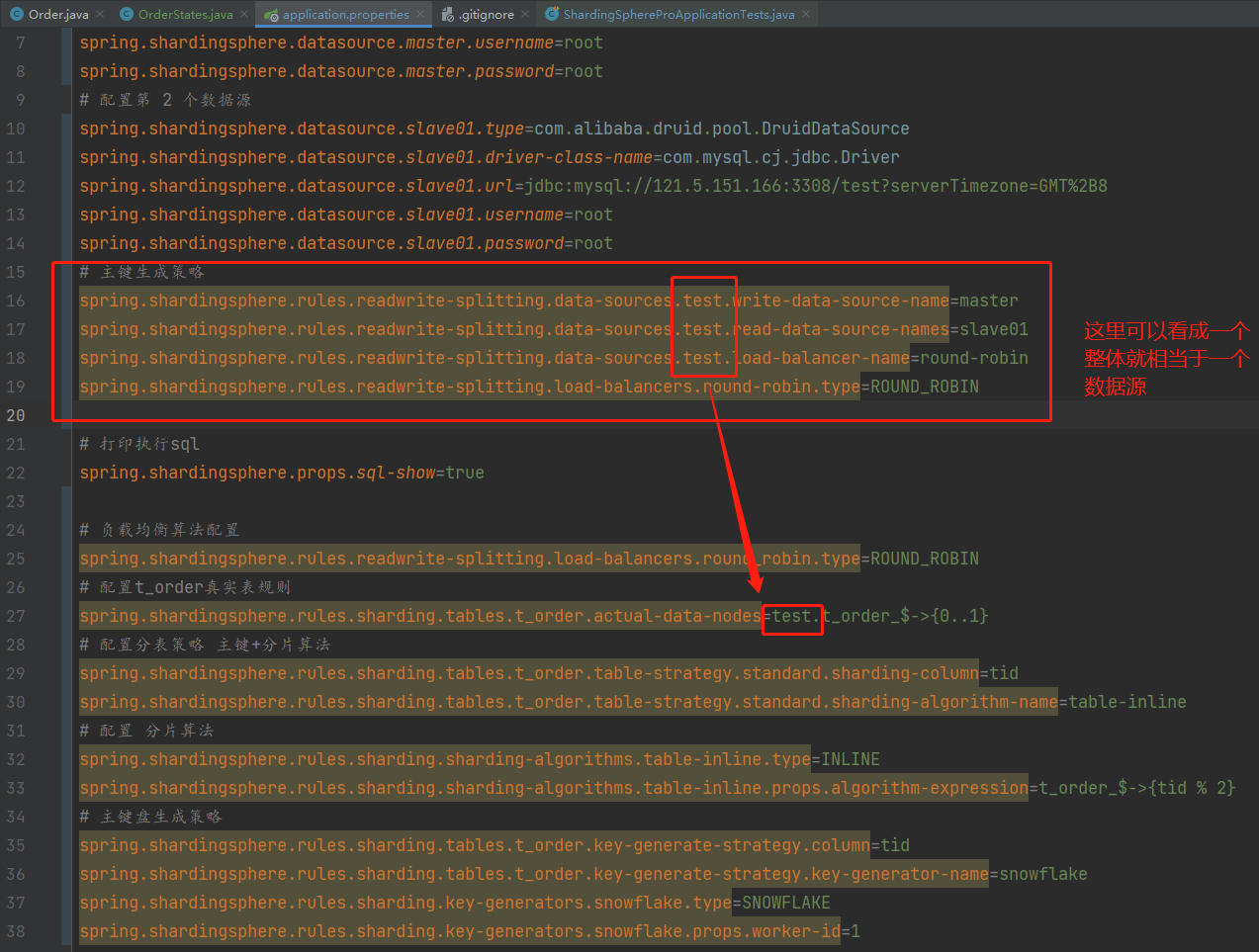
如上的配置含义就是说在主从的模式下,它是一个整体,因为你改变了主当中的信息从库当中会自动进行同步,所以就是一个整体,以后如果你还有其它的主从数据库,你在配置一个即可,例如,我现在配置的是 test, 如果以后你有一个 ds0 你就在配置一下数据源关于 ds0 的即可。
测试
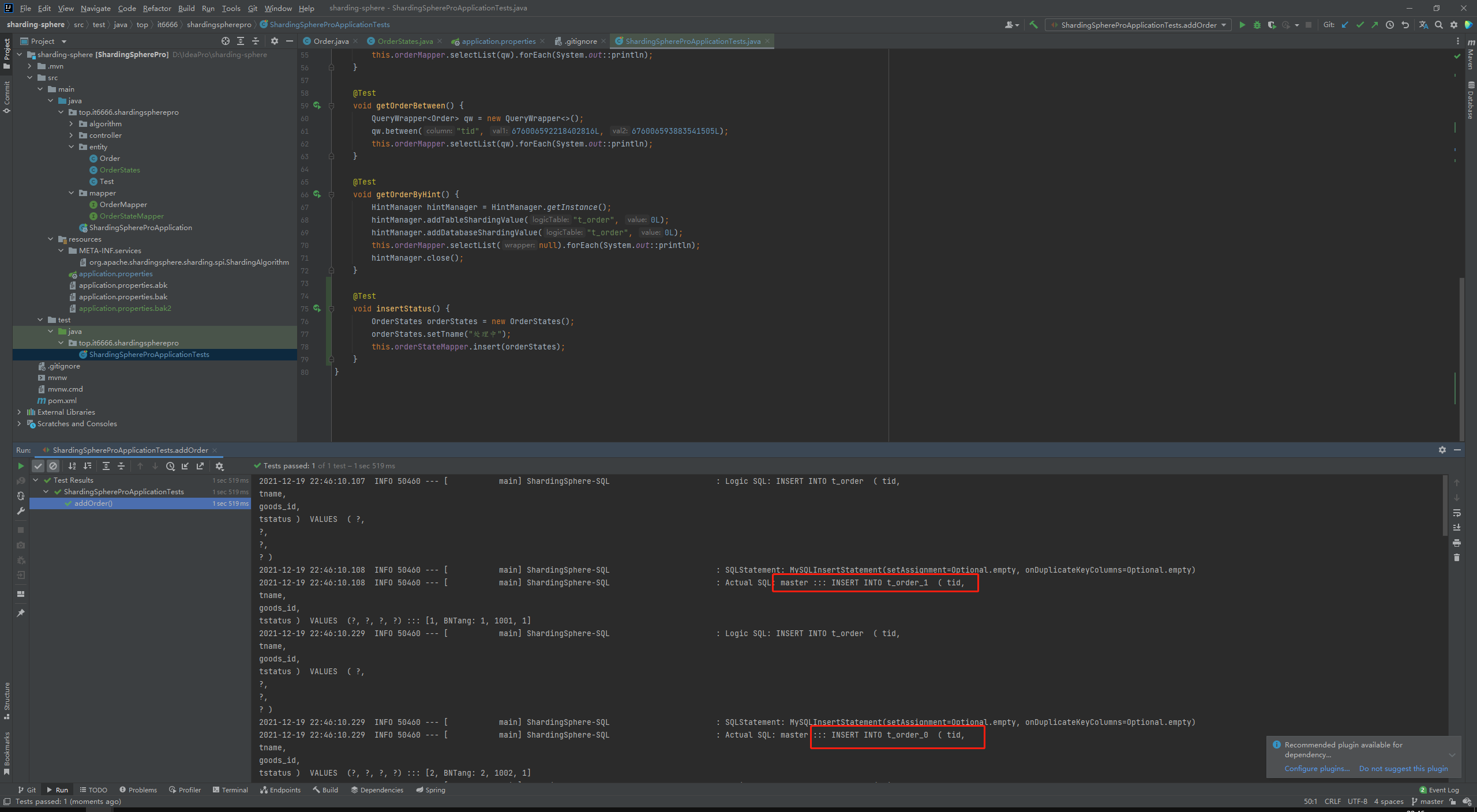
插入数据:
查询数据:
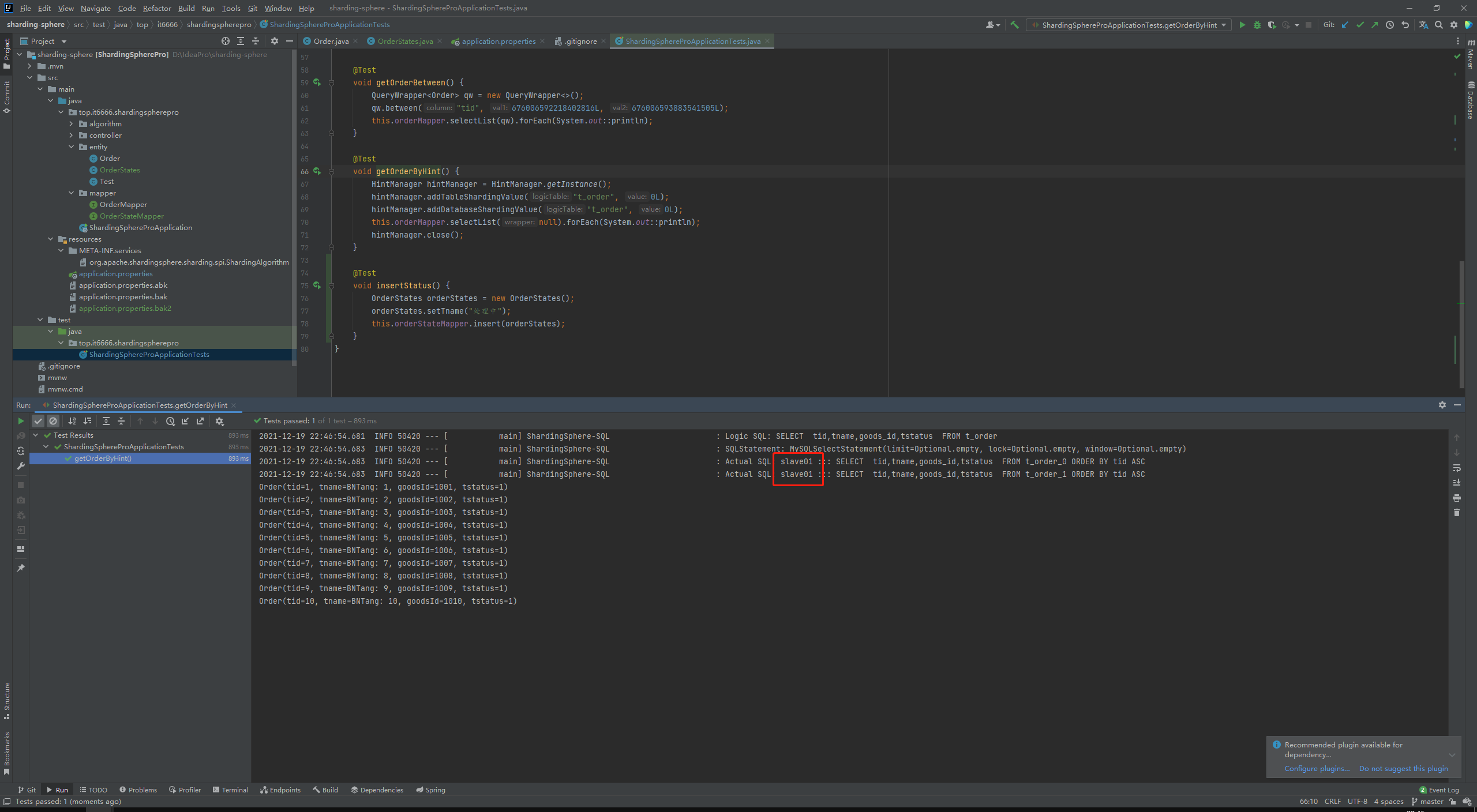
ok,到了这里基本上差不多就这些内容了,插入是往主库当中进行插入的,查询是从从库当中进行查询的,已经成功了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号