Explain
使用方法
explain sql语句
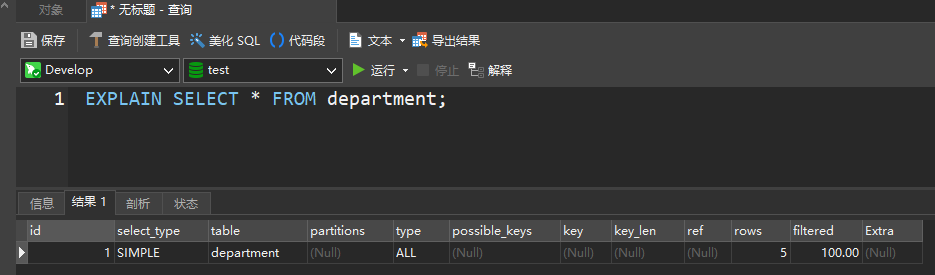
EXPLAIN SELECT * FROM department;
创建 customer 表,SQL 如下
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for customer
-- ----------------------------
DROP TABLE IF EXISTS `customer`;
CREATE TABLE `customer` (
`id` int(11) NOT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of customer
-- ----------------------------
INSERT INTO `customer` VALUES (1, 'zs');
SET FOREIGN_KEY_CHECKS = 1;
分析包含信息
id
- select 查询的序列号
- 包含一组数字,表示查询中执行 select 子句或操作表的顺序
值的三种情况
id 相同
EXPLAIN SELECT
*
FROM
employee e,
department d,
customer c
WHERE
e.dep_id = d.id
AND e.cus_id = c.id;
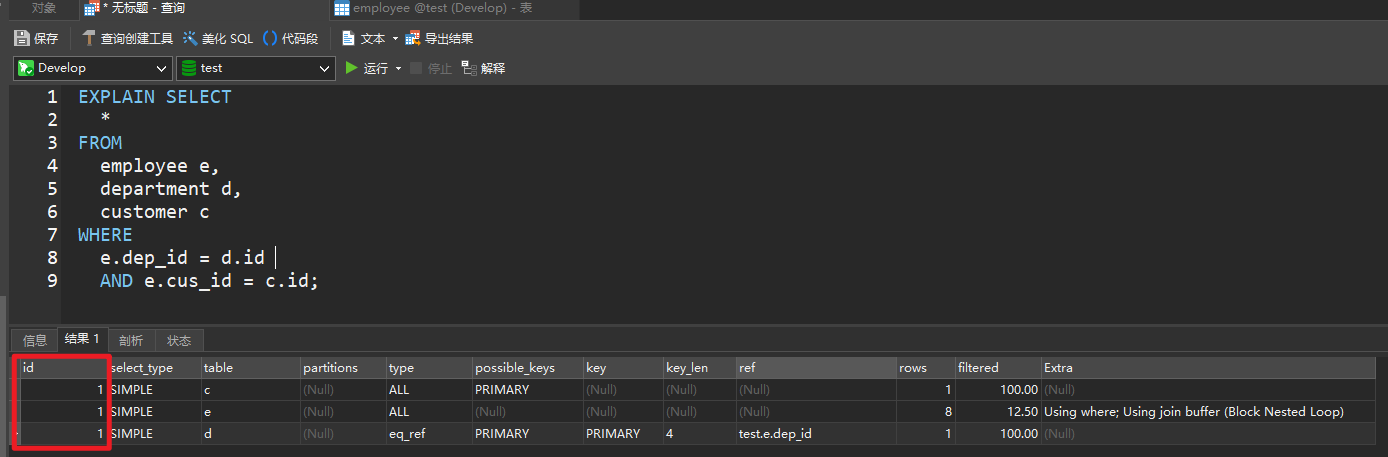
执行顺序由上到下
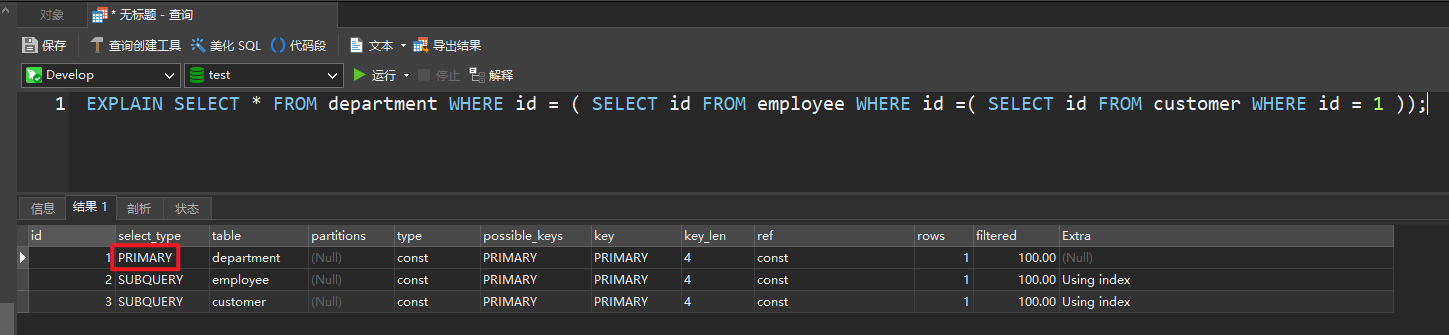
id 不同
EXPLAIN SELECT * FROM department WHERE id = ( SELECT id FROM employee WHERE id =( SELECT id FROM customer WHERE id = 1 ));
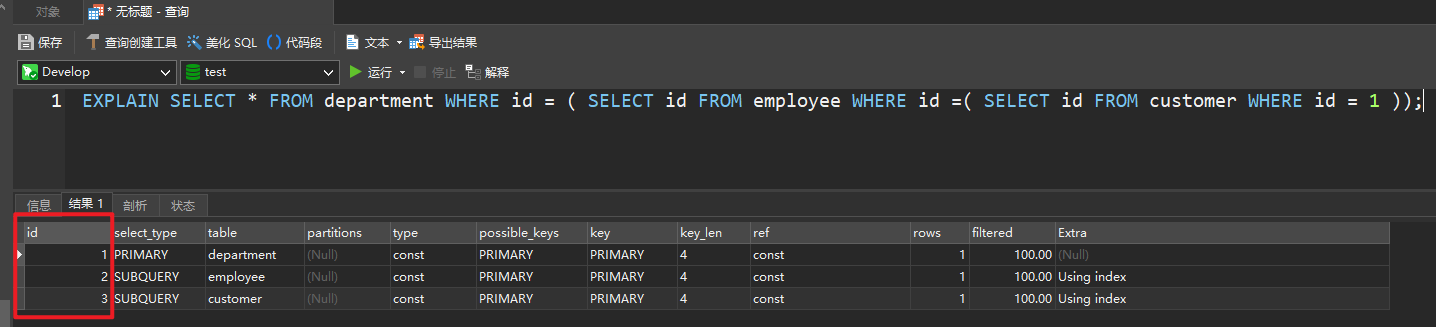
如果是子查询,id 的序号会递增,id 值越大优先级越高,优先会被执行
id 相同与不同,同时存在
- 可以认为是一组,从上往下的顺序执行
- 在所有组中,id 值越大,优先级越高,越先执行
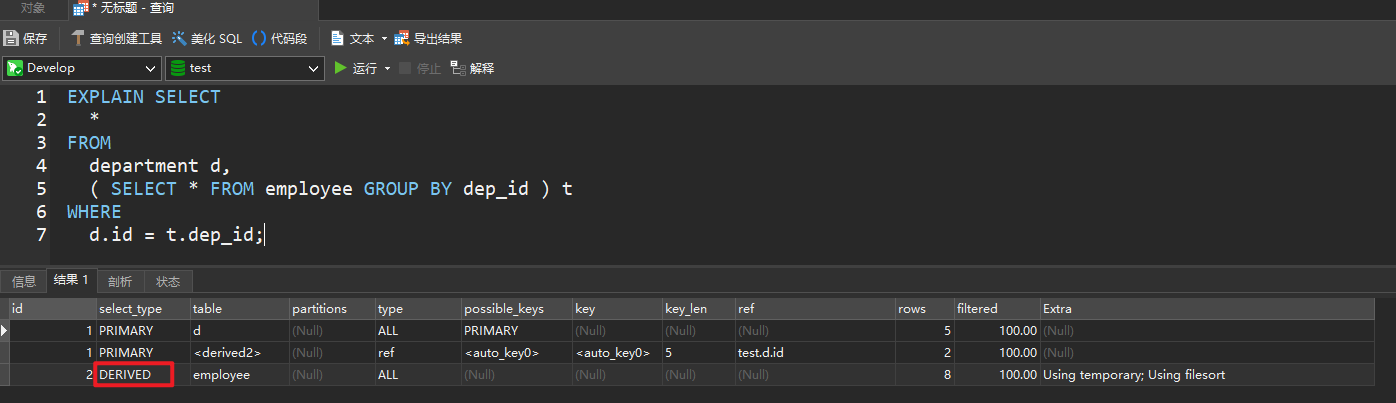
deriverd衍生出来的虚表
EXPLAIN SELECT
*
FROM
department d,
( SELECT * FROM employee GROUP BY dep_id ) t
WHERE
d.id = t.dep_id;
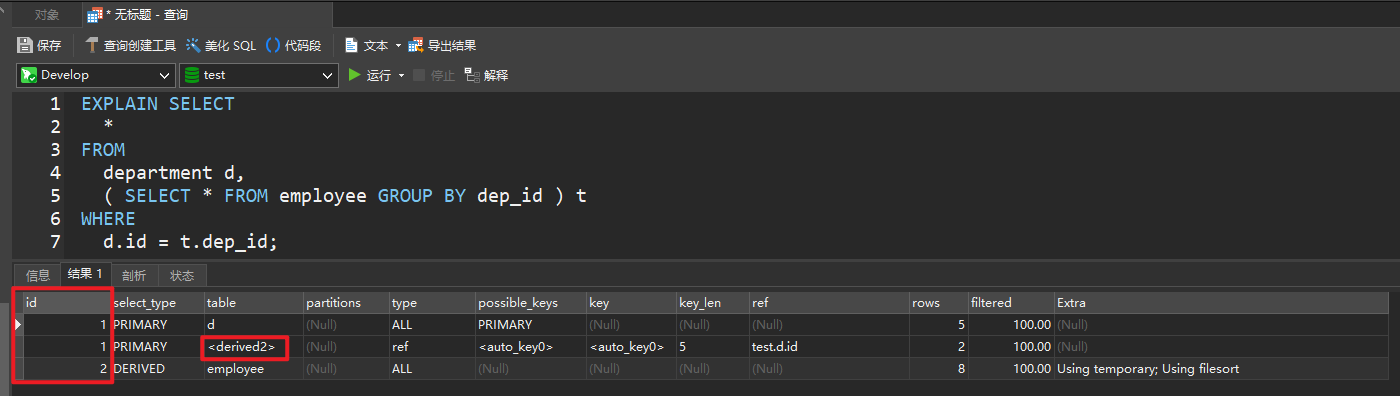
总结
- id 值相同,按照顺序走
- id 值不同,看谁大,就谁先执行
- id 值大的先执行
select_type
作用:查询类型,主要用于区别普通查询,联合查询,子查询等复杂查询,结果值如下:
SIMPLE
- 简单 select 查询,查询中不包含子查询或者
UNION
PRIMARY
- 查询中若包含任何复杂的子查询,最外层查询则被标记为
primary
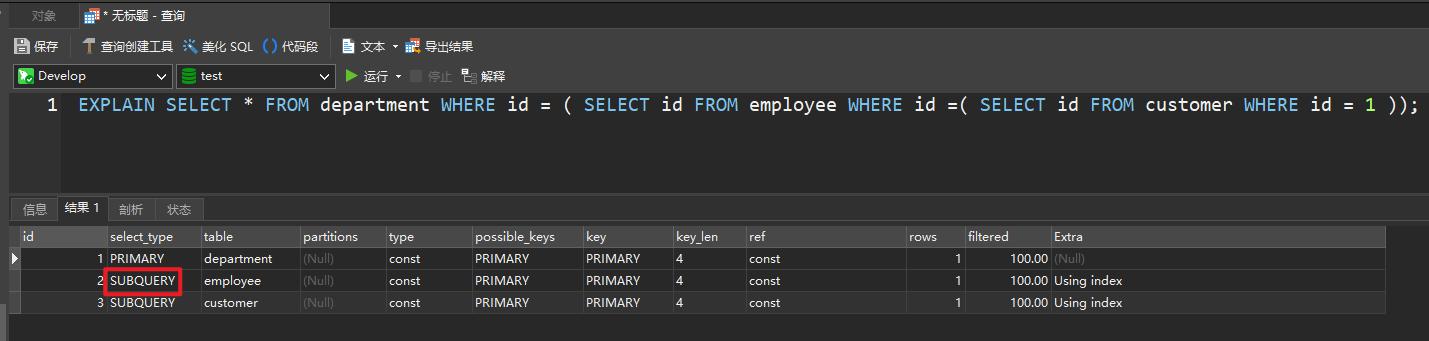
SUBQUERY
- 在 select 或 where 中包含了子查询
DERIVED
- 在 from 列表中包含的子查询被标记为
derived(衍生)- 把结果放在临时表当中
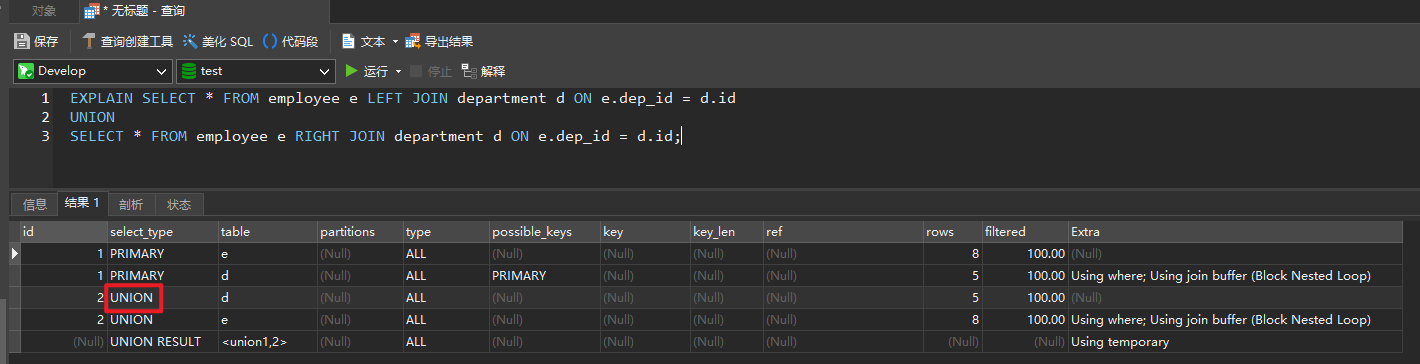
UNION
- 若第二个 select 出现在 union 之后,则被标记为 union
EXPLAIN SELECT * FROM employee e LEFT JOIN department d ON e.dep_id = d.id
UNION
SELECT * FROM employee e RIGHT JOIN department d ON e.dep_id = d.id;
- 若
union包含在from子句的子查询中,外层 select 将被标记为derived
EXPLAIN SELECT
*
FROM
( SELECT * FROM employee UNION SELECT * FROM employee ) a
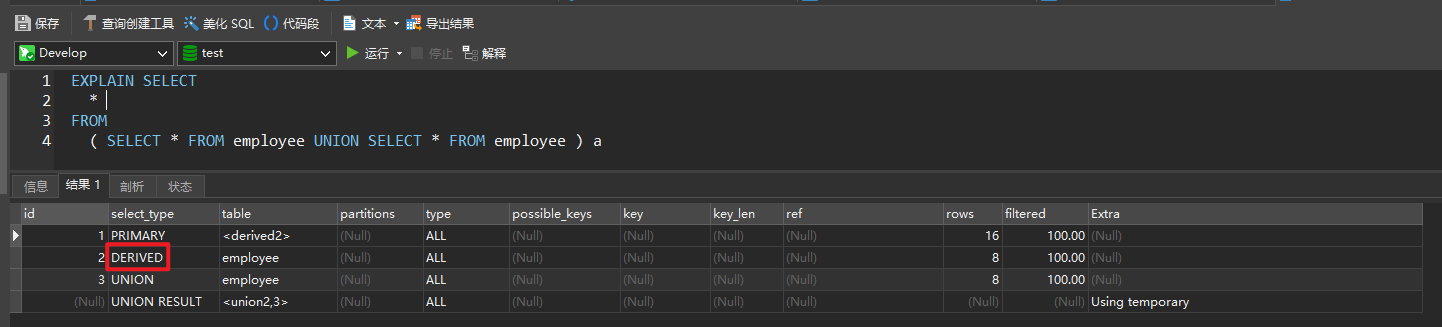
UNION RESULT
- 从 union 表获取结果 select
- 两个 UNION 合并的结果集在最后

table
- 显示这一行的数据是关于哪张表的
partitions
- 如果查询是基于分区表的话,会显示查询访问的分区
type
- 访问类型排列
- 结果值最好到最差,如下所示
system
- 表中有一行记录 (系统表) 这是
const类型的特例,平时不会出现
const
- 表示通过索引一次就找到了
const用于比较primary或者unique索引,直接查询主键或者唯一索引- 因为只匹配一行数据,所以很快

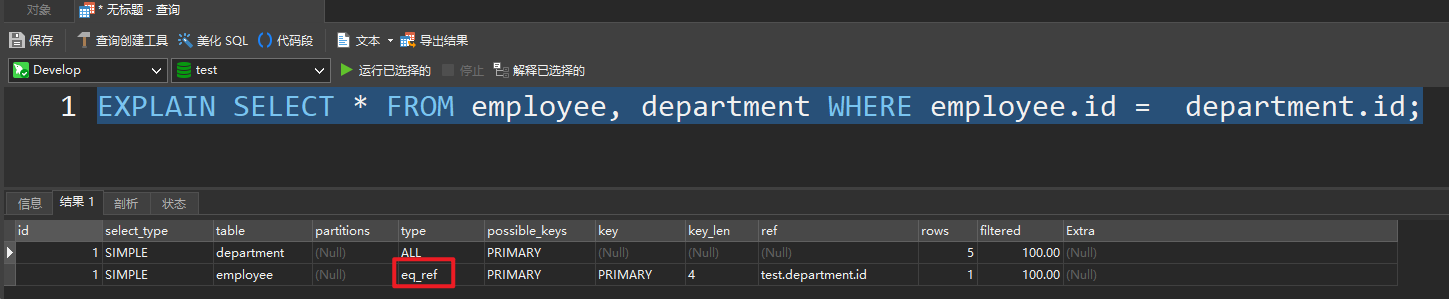
eq_ref
- 唯一性索引扫描
- 对于每个索引键,表中只有一条记录与之匹配
- 常见于主键或唯一索引扫描
ref
- 非唯一性索引扫描,返回匹配某个单独值的所有行
- 本质上也是一种索引访问
- 它返回所有匹配某个单独值的行
- 可能会找到多个符合条件的行
- 所以它应该属于查找和扫描的混合体
修改 employee 表,添加一个外键,然后在运行如下 SQL 即可出现 ref

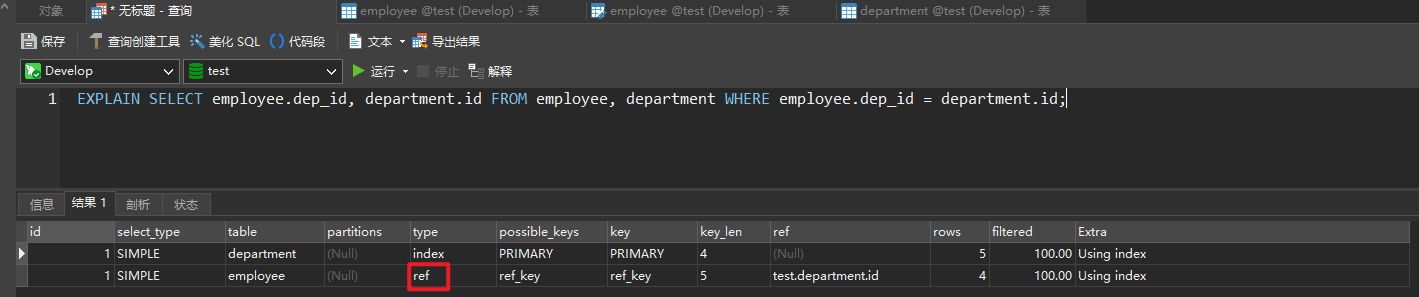
EXPLAIN SELECT employee.dep_id, department.id FROM employee, department WHERE employee.dep_id = department.id;
range
- 只检索给定范围的行,使用一个索引来选择行
- key 列显示使用了哪个索引
- 一般就是在你的
where语句中出现between、<、>、in等查询- 这种范围扫描索引比全表扫描要好
- 因为它只需要开始于索引的某一点,而结束于另一点
- 不用扫描全部索引
EXPLAIN SELECT * FROM employee WHERE id BETWEEN 1 AND 3;

index
- Full Index Scan
index与All区别为 index 类型只遍历索引树,通常比All要快,因为索引文件通常比数据文件要小- all 和 index 都是读全表,但 index 是从索引中读取,all 是从硬盘当中读取
EXPLAIN SELECT id FROM employee;

ALL
- 将全表进行扫描,从硬盘当中读取数据
- 如果出现了
All切数据量非常大,一定要去做优化
EXPLAIN SELECT * FROM employee;

🐤type 要求
- 一般来说,保证查询至少达到
range级别- 最好能达到
ref

 浙公网安备 33010602011771号
浙公网安备 33010602011771号