
elasticsearch
ElasticSearch 简介
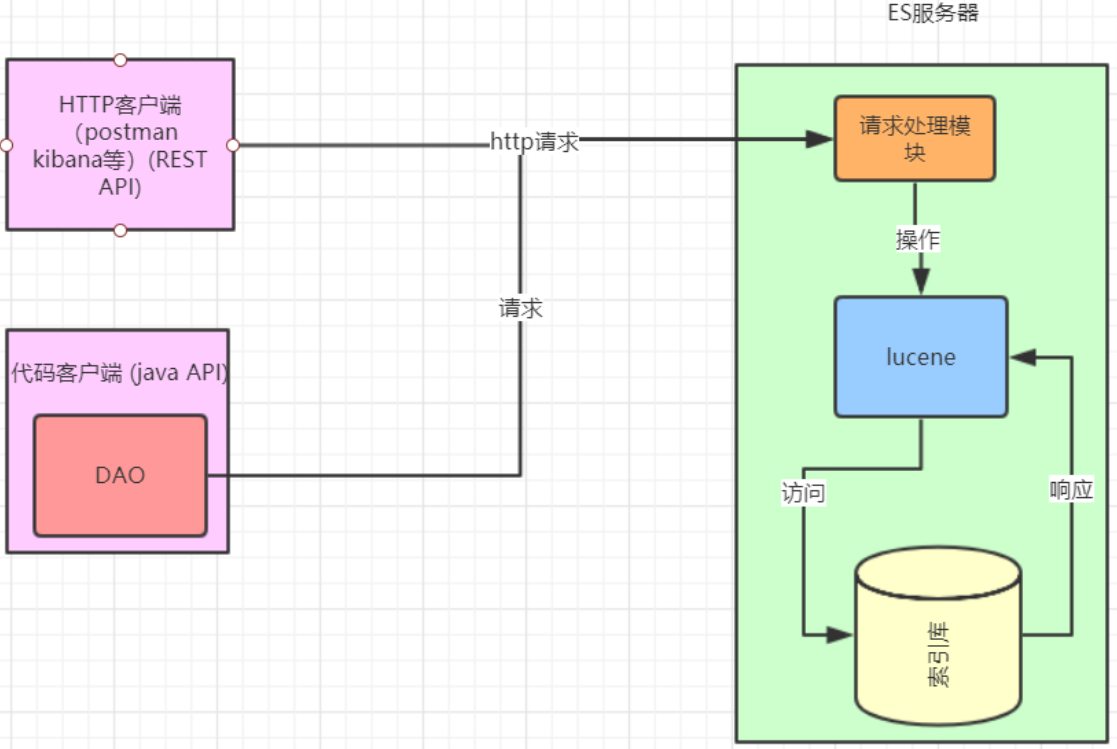
ElaticSearch 简称为 es, 是一个开源的可扩展的全文检索引擎 服务器,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。es 使用 Java 开发并使用 Lucene 作为其核心来实现索引和搜索的功能,但是它通过简单的 RestfulAPI 和 javaAPI 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单
ElasticSearch官网:https://www.elastic.co/cn/products/elasticsearch

ES 企业使用场景
企业使用场景一般分为2种情况:
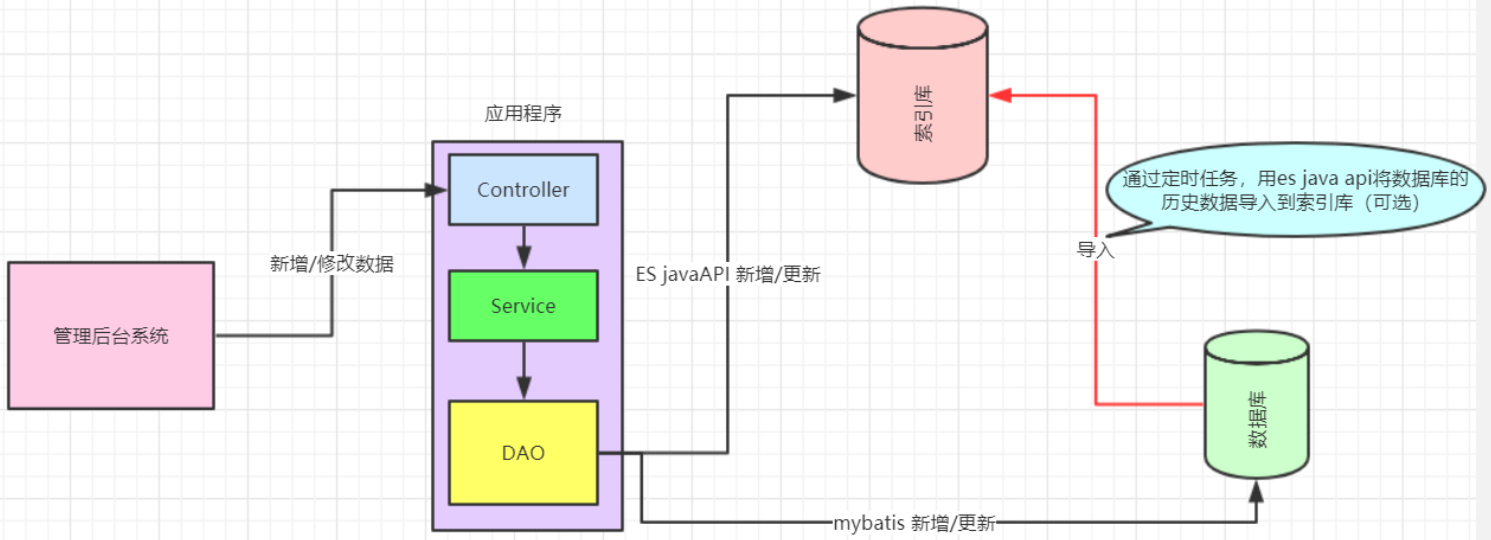
已经上线的系统,某些模块的搜索功能是使用数据库搜索实现的,但是已经出现性能问题或者不满足产品的高亮相关度排序的需求的时候,就会对系统的搜索功能进行技术改造,使用全文检索,而 es 就是首选。针对这种情况企业改造的业务流程如下图
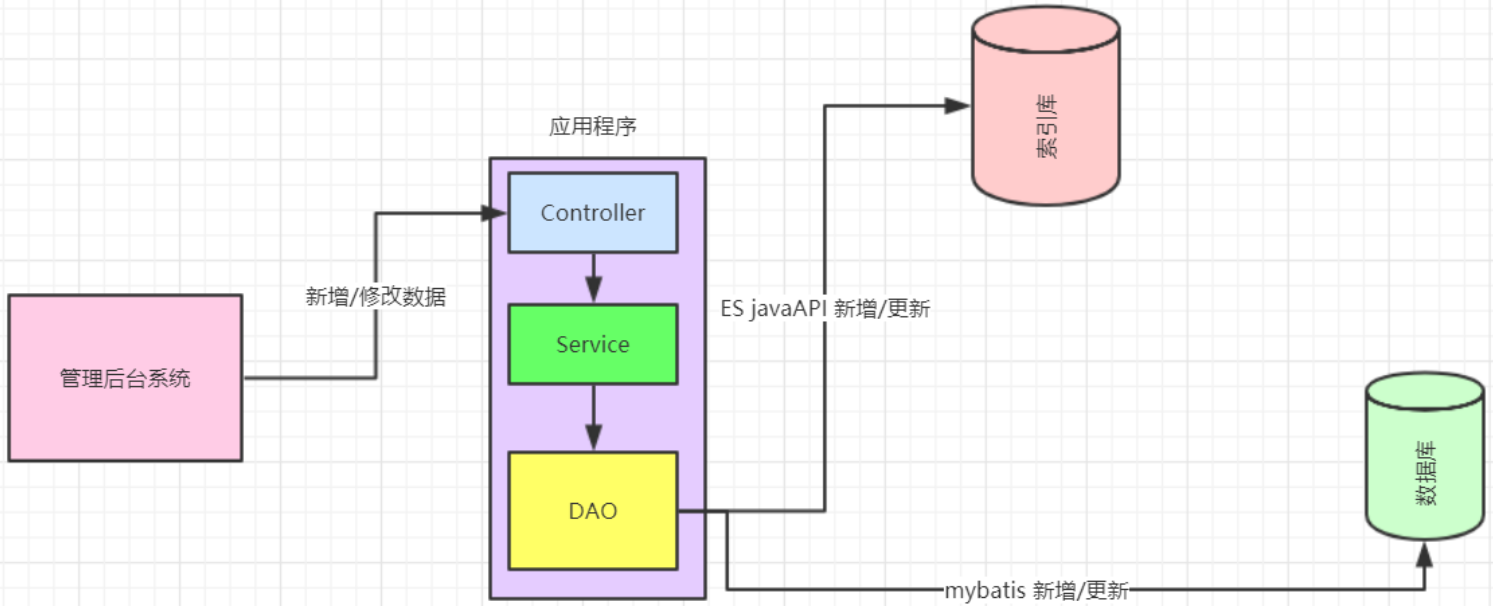
系统新增加的模块,产品一开始就要实现高亮相关度排序等全文检索的功能或者技术分析觉得该模块使用全文检索更适合。针对这种情况企业改造的业务流程如下图
索引库(ES)存什么数据
索引库的数据是用来搜索用的,里面存储的数据和数据库一般不会是完全一样的,一般都比数据库的数据少。那索引库存什么数据呢?以业务需求为准,需求决定页面要显示什么字段以及会按什么字段进行搜索,那么这些字段就都要保存到索引库中
版本
目前 ElasticSearch 最新的版本是 7.10.0,我们使用 6.8.0 版本,建议使用 JDK1.8 及以上
ElasticSearch 安装和配置
为了模拟真实场景,我们将在 Linux 下安装 ElasticSearch, 环境 centos7 64位,JDK8 及以上
新建一个用户
出于安全考虑,elasticsearch 默认不允许以 root 账号运行,新建一个新用户
useradd elastic
设置新用户的密码
passwd elastic
切换到新建的用户
su - elastic
上传安装包并解压
我们将安装包上传到:/home/elastic 目录
cd /home/elastic
解压安装包
tar xvf elasticsearch-6.8.0.tar.gz
把目录重命名一下
mv elasticsearch-6.8.0/ elasticsearch
进入,查看目录结构:
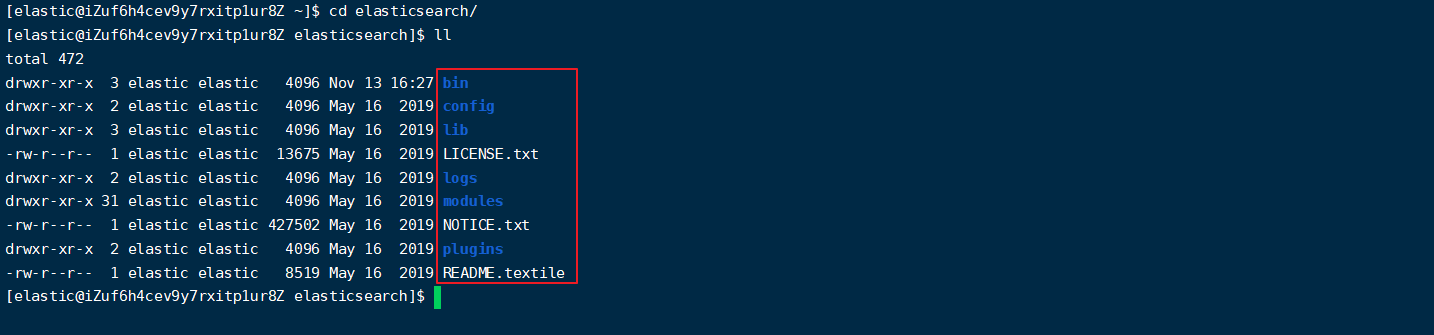
- bin:二进制脚本,包含启动命令等
- config:配置文件目录
- lib:依赖包目录
- logs:日志文件目录
- modules:模块库
- plugins:插件目录,这里存放一些常用的插件比如 IK 分词器插件
- data:数据储存目录(暂时没有,需要在配置文件中指定存放位置,启动 es 时会自动根据指定位置创建)
修改配置
我们进入 config 目录:
cd config
需要修改的配置文件有两个:

修改 jvm 配置:
ElasticSearch 基于 Lucene的,而Lucene底层是 Java实现,因此我们需要配置 jvm 参数设置堆区的大小
vim jvm.options
默认配置如下:
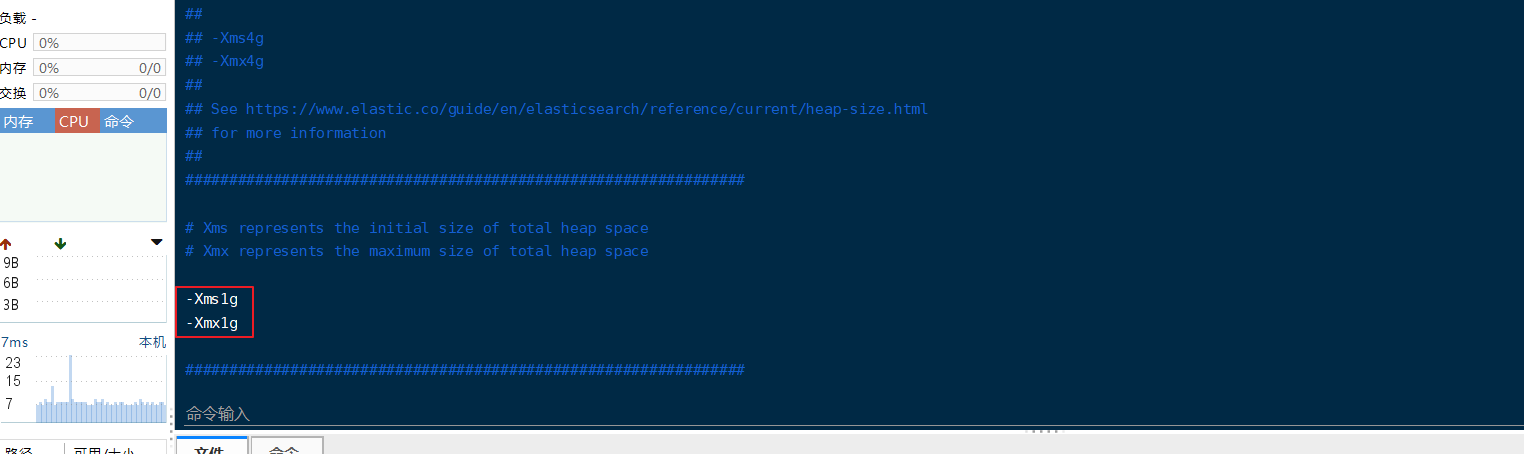
内存占用的太多了,我们调小一些,最小设置 128m,如果虚机内存允许的话可以设置为 512m
-Xms128m
-Xmx128m
然后在修改 elasticsearch.yml
vim elasticsearch.yml
修改数据和日志的存放目录:
path.data: /home/elastic/elasticsearch/data # 数据目录位置
path.logs: /home/elastic/elasticsearch/logs # 日志目录位置
修改绑定的 IP:
network.host: 0.0.0.0 # 绑定到0.0.0.0,允许任何 ip 来访问
默认只允许本机访问,修改为 0.0.0.0 后则可以远程访问, 目前我们是做的单机安装,如果要做集群,只需要在这个配置文件中添加其它节点信息即可
elasticsearch.yml 的其它可配置信息如下:
| 属性名 | 说明 |
|---|---|
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群节点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主节点数量的最少值, 此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主节点,那么这里要设置为2 |
启动运行
切换回root用户,然后修改配置文件
su - root

vim /etc/security/limits.conf
添加下面的内容, 注意下面的 * 号不要去除了要保留
# 可打开的文件描述符的最大数(软限制)
* soft nofile 65536
# 可打开的文件描述符的最大数(硬限制)
* hard nofile 131072
# 单个用户可用的最大进程数量(软限制)
* soft nproc 4096
# 单个用户可用的最大进程数量(硬限制)
* hard nproc 4096
继续修改配置文件
vim /etc/sysctl.conf
添加下面内容
vm.max_map_count = 262144
然后执行如下命令
sysctl -p
在进入到 es 存储日志及数据的目录
cd /home/elastic/elasticsearch/data/
将data目录以及它的子目录赋予权限,在data目录下执行

chmod -R a+rw *
然后紧接着就是启动 ES 了,命令如下,首先需要进入到 ES 的 bin 目录下
cd /home/elastic/elasticsearch/bin/
然后在输入如下指令启动 ES, -d 代表在后台运行
./elasticsearch -d
如果在如上的步骤中出现启动错误可参考该文章进行解决:https://www.cnblogs.com/liujinqq7/p/12656949.html
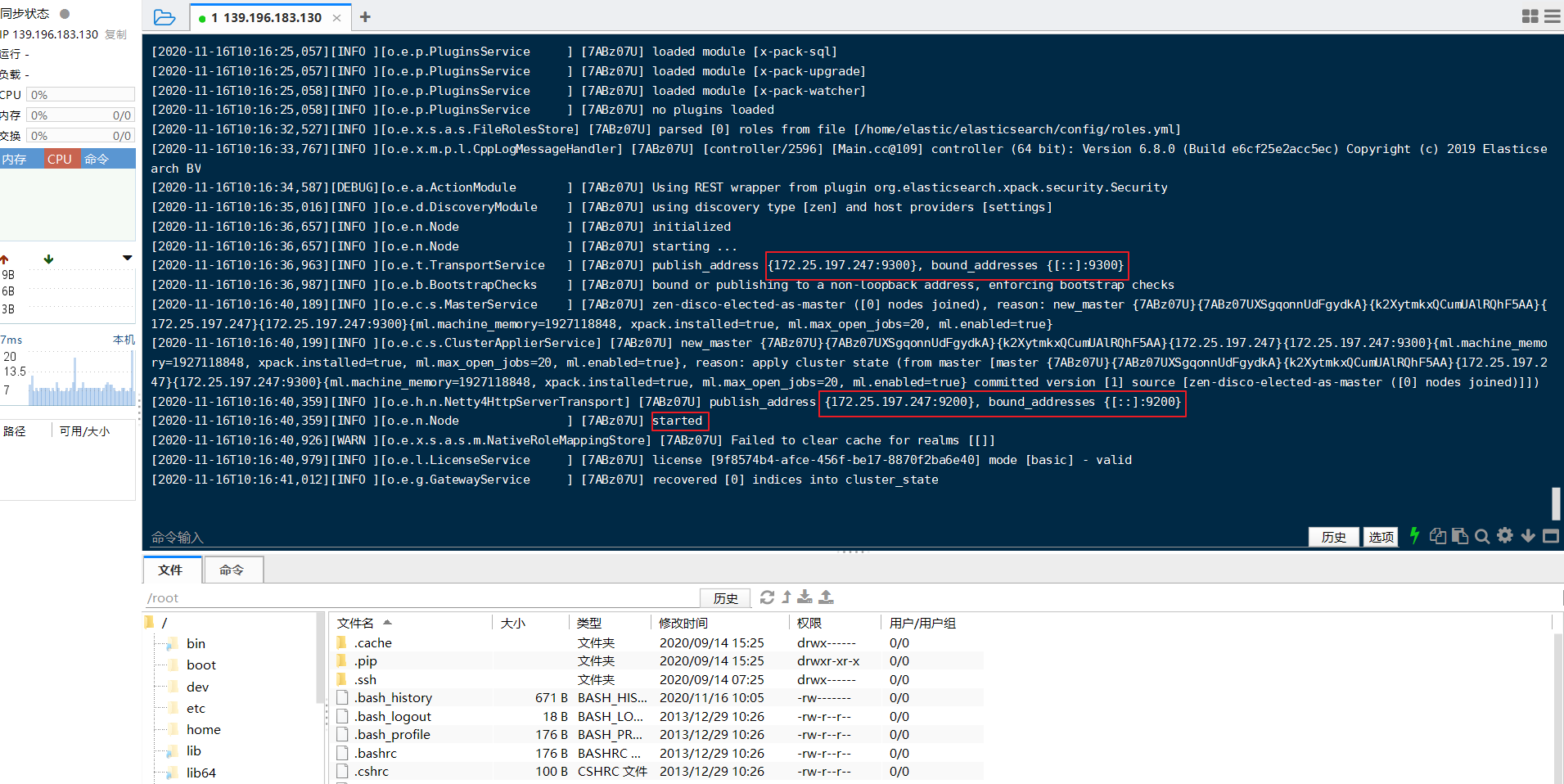
启动完成之后可以看到绑定了两个端口
- 9300:集群节点间通讯的端口,接收
tcp协议 - 9200:客户端访问端口,接收
Http协议
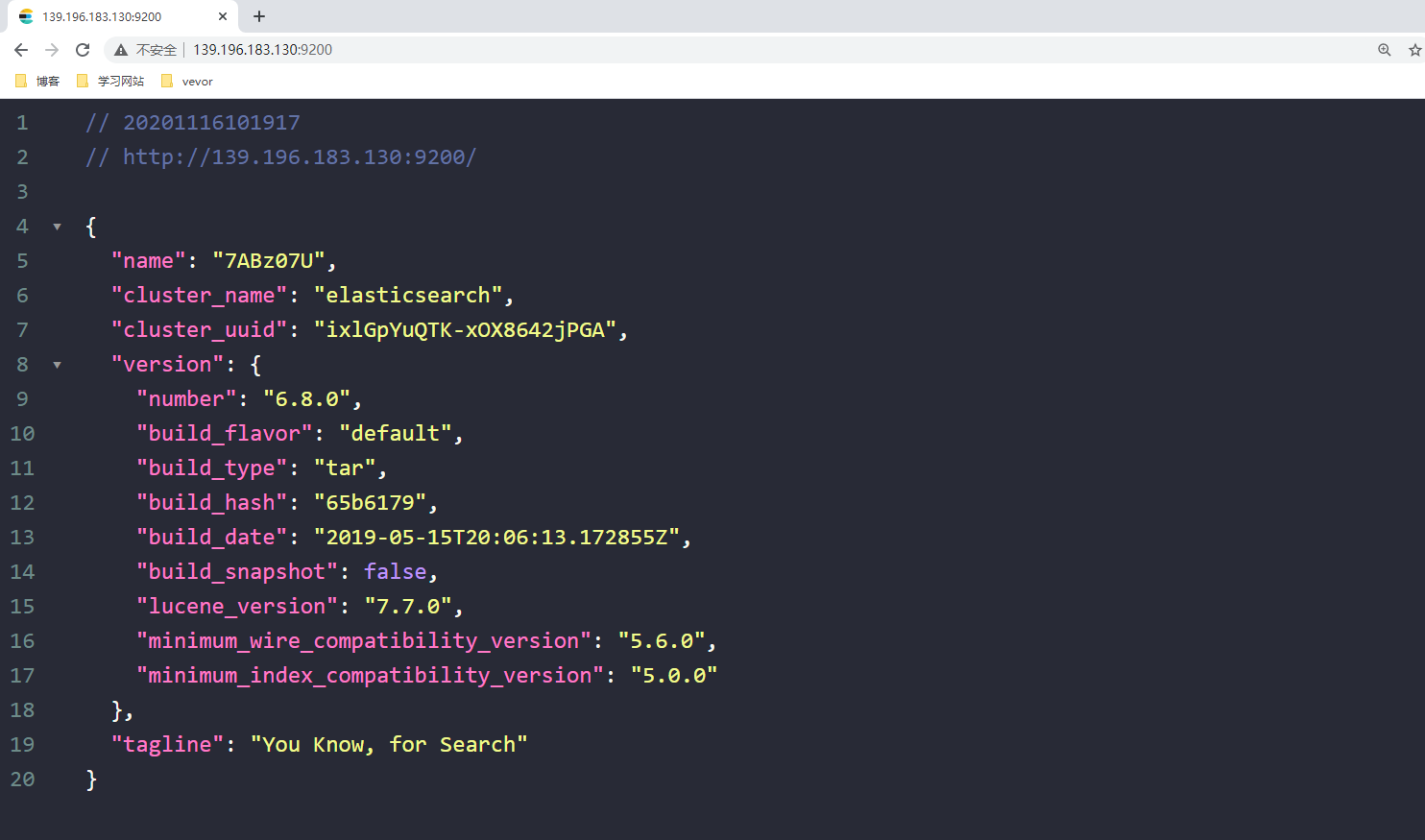
验证是否启动成功, 在浏览器中访问:http://192.168.200.128:9200/ 前面的 IP 改为你自己的 ES 服务器地址,如果不能访问,则需要关闭虚拟机防火墙, 需要root权限,使用云服务器的就是去开放端口即可
图形化可视化工具安装
可参考如下文章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号