搭建ES集群
为什么要搭建集群
假如 ElasticSearch 只放在一台服务器上,即单机运行,假如这台主机突然断网了或者被攻击了,那么整个 ElasticSearch 的服务就不可用了。但如果改成 ElasticSearch 集群的话,有一台主机宕机了,还有其他的主机可以支撑,这样就仍然可以保证服务是可用的。
集群简介
接下来我们再来了解下集群的结构是怎样的,首先我们应该清楚多台主机构成了一个集群,每台主机称作一个节点(Node)如下图就是一个三节点的集群:
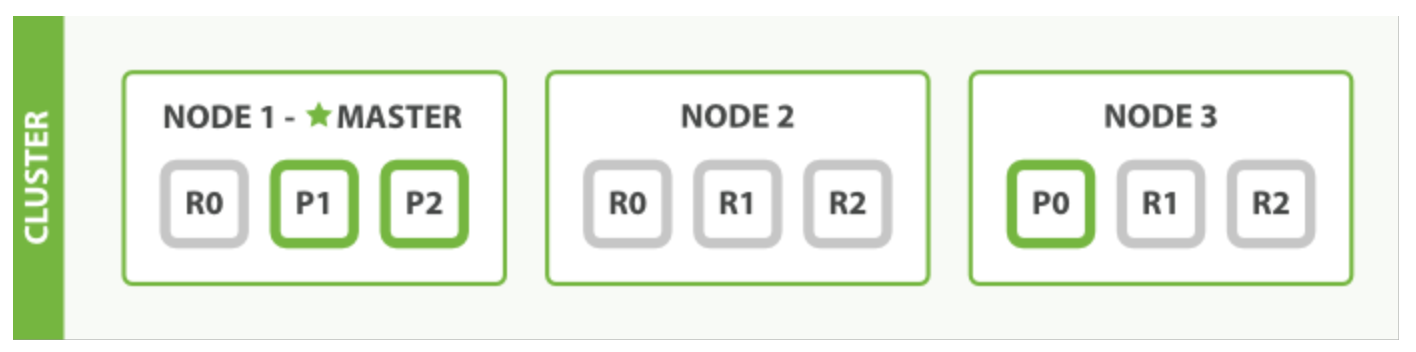
在图中,每个 Node 都有三个分片,其中 P 开头的代表 Primary 分片,即主分片,R 开头的代表 Replica 分片,即副本分片。所以图中主分片 1、2,副本分片 0 储存在 1 号节点,副本分片 0、1、2 储存在 2 号节点,主分片 0 和副本分片 1、2 储存在 3 号节点,一共是 3 个主分片和 6 个副本分片。同时我们还注意到 1 号节点还有个 MASTER 的标识,这代表它是一个主节点,它相比其他的节点更加特殊,它有权限控制整个集群,比如资源的分配、节点的修改等等。
这里就引出了一个概念就是节点的类型,我们可以将节点分为如下这四个类型:
主节点:即 Master 节点。主节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康是非常重要的。默认情况下任何一个集群中的节点都有可能被选为主节点。索引数据和搜索查询等操作会占用大量的 cpu,内存,io资源,为了确保一个集群的稳定,分离主节点和数据节点是一个比较好的选择。虽然主节点也可以协调节点,路由搜索和从客户端新增数据到数据节点,但最好不要使用这些专用的主节点。一个重要的原则是,尽可能做尽量少的工作。
数据节点:即 Data 节点。数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对 CPU、内存、IO 要求较高,在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
负载均衡节点:也称作 Client 节点,也称作客户端节点。当一个节点既不配置为主节点,也不配置为数据节点时,该节点只能处理路由请求,处理搜索,分发索引操作等,从本质上来说该客户节点表现为智能负载平衡器。独立的客户端节点在一个比较大的集群中是非常有用的,他协调主节点和数据节点,客户端节点加入集群可以得到集群的状态,根据集群的状态可以直接路由请求。
预处理节点:也称作 Ingest 节点,在索引数据之前可以先对数据做预处理操作,所有节点其实默认都是支持 Ingest 操作的,也可以专门将某个节点配置为 Ingest 节点。
以上就是节点几种类型,一个节点其实可以对应不同的类型,如一个节点可以同时成为主节点和数据节点和预处理节点,但如果一个节点既不是主节点也不是数据节点,那么它就是负载均衡节点。
搭建集群
首先创建数据目录和日志目录用来存放相关信息

mkdir -p /usr/local/es/data
mkdir -p /usr/local/es/log
修改文件的所有者,命令如下所示:
chown -R es:es /usr/local/es/
chown -R es:es /usr/local/soft/elasticsearch-7.3.0/
搭建集群标题开始,可以参考:https://www.cnblogs.com/BNTang/articles/13785625.html
如上推荐的这篇文章呢,你可以在搭建的时候进行配置好紧接着就是搭建ES的各个节点的配置了如下。
配置文件
集群配置中最重要的两项是 node.name 与 network.host,每个节点都必须不同。其中 node.name 是节点名称主要是在ElasticSearch自己的日志加以区分每一个节点信息。discovery.seed_hosts 是集群中的节点信息,可以使用IP地址、可以使用主机名(必须可以解析)
编辑 elasticsearch.yml
# 如下是每个节点的配置文件内容,自行记得按自己的需求进行修改
cluster.name: my-application
node.name: node-1
# 主节点
node.master: true
# 数据节点
node.data: true
network.host: 该节点ip
# http 通讯端口
http.port: 9200
# tcp 通讯端口
transport.port: 9300
transport.tcp.compress: true
discovery.seed_hosts: [ "139.196.183.130:9200", "139.196.183.130:9201","139.196.183.130:9202" ]
cluster.initial_master_nodes: [ "node-1" ] # 确保当前节点是主节点
path.data: /usr/local/es/data
path.logs: /usr/local/es/log
# 开启 cors 跨域访问支持,默认为 false
http.cors.enabled: true
# 跨域访问允许的域名地址,(允许所有域名)这里我使用的正则
http.cors.allow-origin: /.*/
如下是我每个节点所配置的内容,Master
# 如下是每个节点的配置文件内容,自行记得按自己的需求进行修改
cluster.name: my-application
node.name: node-1
# 主节点
node.master: true
# 数据节点
node.data: true
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
transport.tcp.compress: true
discovery.seed_hosts: [ "139.196.183.130:9200", "139.196.183.130:9201","139.196.183.130:9202" ]
cluster.initial_master_nodes: [ "node-1" ] # 确保当前节点是主节点
path.data: /usr/local/es/data
path.logs: /usr/local/es/log
# 开启 cors 跨域访问支持,默认为 false
http.cors.enabled: true
# 跨域访问允许的域名地址,(允许所有域名)这里我使用的正则
http.cors.allow-origin: /.*/
Node2
# 如下是每个节点的配置文件内容,自行记得按自己的需求进行修改
cluster.name: my-application
node.name: node-2
# 数据节点
node.data: true
network.host: 0.0.0.0
http.port: 9201
transport.port: 9301
transport.tcp.compress: true
discovery.seed_hosts: [ "139.196.183.130:9200", "139.196.183.130:9201","139.196.183.130:9202" ]
path.data: /usr/local/es/data
path.logs: /usr/local/es/log
# 开启 cors 跨域访问支持,默认为 false
http.cors.enabled: true
# 跨域访问允许的域名地址,(允许所有域名)这里我使用的正则
http.cors.allow-origin: /.*/
Node3
# 如下是每个节点的配置文件内容,自行记得按自己的需求进行修改
cluster.name: my-application
node.name: node-3
# 数据节点
node.data: true
network.host: 0.0.0.0
http.port: 9202
transport.port: 9302
transport.tcp.compress: true
discovery.seed_hosts: [ "139.196.183.130:9200", "139.196.183.130:9201","139.196.183.130:9202" ]
path.data: /usr/local/es/data
path.logs: /usr/local/es/log
# 开启 cors 跨域访问支持,默认为 false
http.cors.enabled: true
# 跨域访问允许的域名地址,(允许所有域名)这里我使用的正则
http.cors.allow-origin: /.*/
如上的节点都是在一台机子上的,如果你的集群每个节点是在不同的机器上的自己需要注意一下IP和端口的改变问题即可,每个节点都这么去部署,启动所有节点,使用可视化界面连接节点测试,也就是启动Head插件或者Dejavu连接其中一台ES即可验证。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号