下载文件
- 直接使用
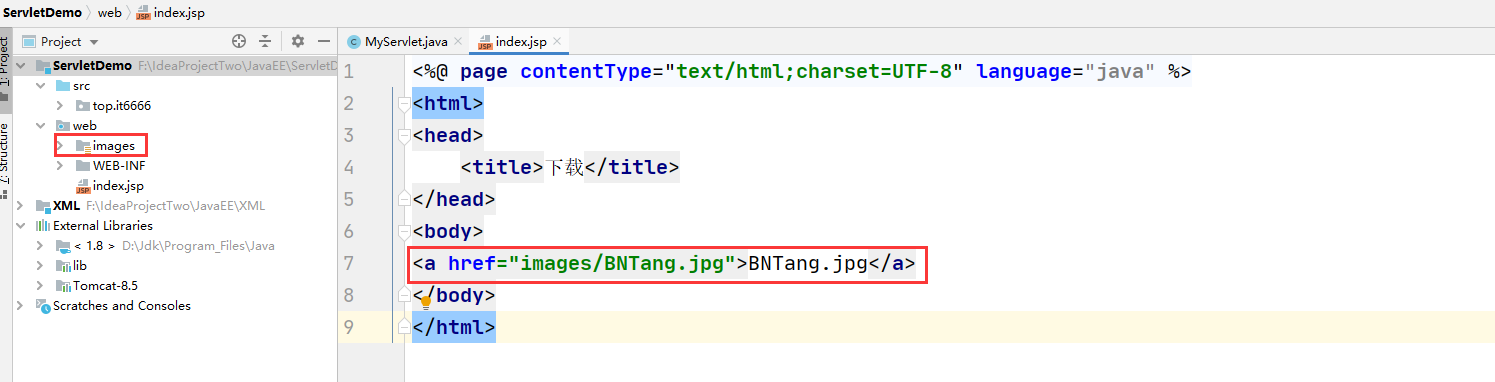
a 标签来去下载
- 有些内容浏览器会自动解析
- 浏览器不能解析的文件才会被下载
.jpg、png、zip、mp4、rar,等等不同的文件格式自己按照如下的方式去试试就知道效果了
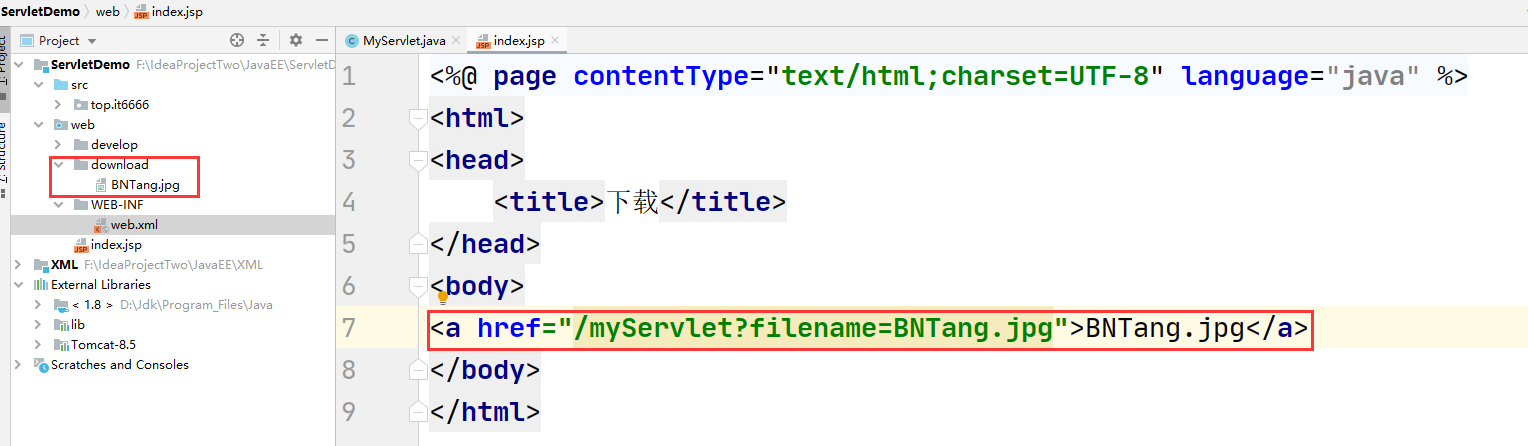
- 通过发送
Servlet 请求来去下载
- 通过发送一个
Servlet 请求,把文件名发送给服务器
- 发送给服务器后,服务器接收到文件名参数,获取文件的绝对地址
- 通过流的形式来去写到浏览器
- 还得要告诉浏览器文件是什么类型
- 浏览器是以
MIME 的类型来去识别的
this.getServletContext().getMimeType("BNTang");
response.setContentType("MIME");

- 设置响应头,告诉浏览器不要去解析,是以附件的形式打开
response.setHeader("Content-Dsiposition", "attachment;filename=" + filename);

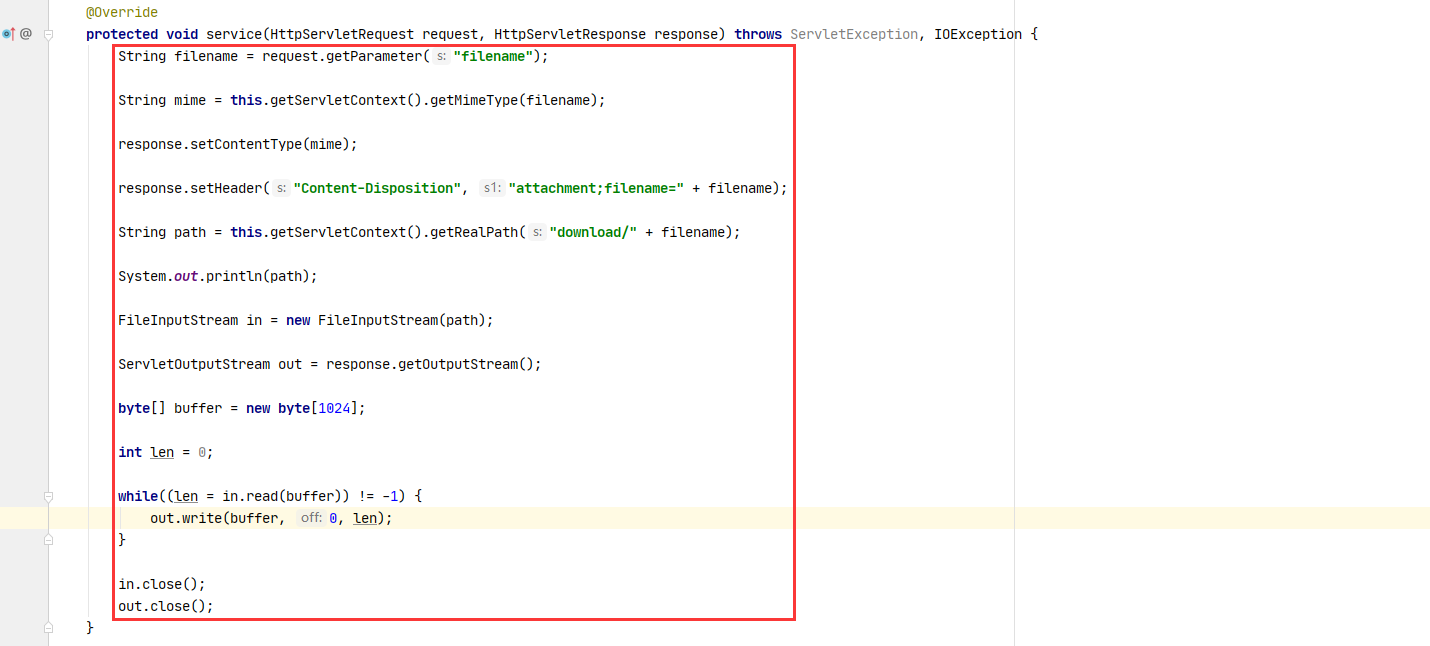
- 接收文件名参数
- 获取 mime 类型
- 设置响应类型,告诉浏览器是以什么类型响应的
- 告诉浏览器是以附件的形式下载
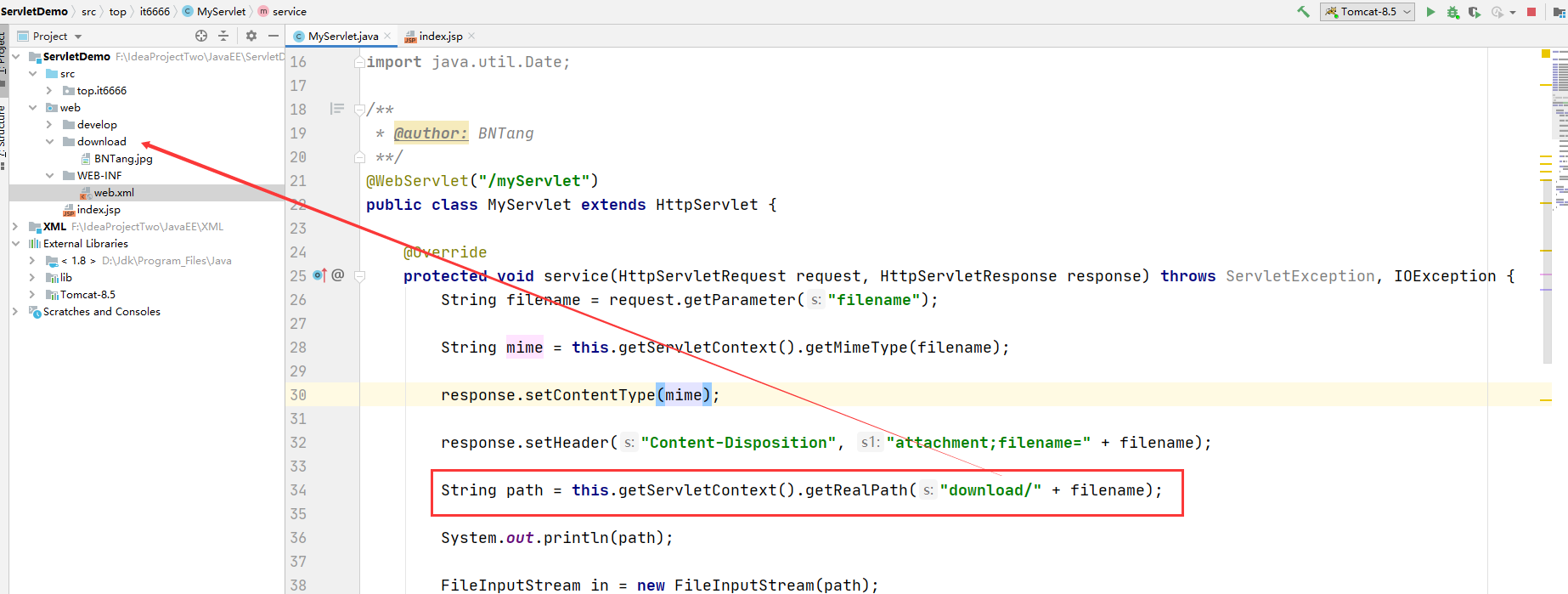
- 获取文件的绝对路径
- 读取文件流
- 获取输出流
- 把内容写出到输出流
@Override
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String filename = request.getParameter("filename");
String mime = this.getServletContext().getMimeType(filename);
response.setContentType(mime);
response.setHeader("Content-Disposition", "attachment;filename=" + filename);
String path = this.getServletContext().getRealPath("download/" + filename);
System.out.println(path);
FileInputStream in = new FileInputStream(path);
ServletOutputStream out = response.getOutputStream();
byte[] buffer = new byte[1024];
int len = 0;
while((len = in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
in.close();
out.close();
}
解决中文文件名称乱码的问题
- 获取中文参数报错的问题
- 高版本
tomcat 中的新特性:就是严格按照 RFC 3986 规范进行访问解析
- 而
RFC 3986 规范定义了 url 中只允许包含英文字母(a-zA-Z)数字(0-9)-_.~ 4个特殊字符
- 以及所有保留字符(RFC3986 中指定了以下字符为保留字符 →
! * ’ ( ) ; : @ & = + $ , / ? # [ ])
.../conf/catalina.properties 中,找到最后注释掉的一行
# tomcat.util.http.parser.HttpParser.requestTargetAllow=|

- 改成
tomcat.util.http.parser.HttpParser.requestTargetAllow=|{},表示把{}放行

- 把获取的字符串参数的字节码获取,再重新使用
utf-8 编码
- 在设置以附件形式打开时,不同的浏览器会对默认的名字进行解码
- 所以根据不同的浏览器,要对名称进行编码之后,再放入文件名
- 对文件名进行编码,不同的浏览器编码方式不一样,要先获取
agent,取出浏览器的类型
- 根据不同的浏览器类型设置对应的编码方式
- 步骤如下:
- 接收文件名称
- 获取
mimeType
- 设置浏览器响应类型
- 先对传入的参数转成二进制流,再使用
UTF-8 进行编码
- 获取浏览器的信息
- 判断是哪一种浏览器,根据不同的浏览器获取一个编码的文件名
- 设置以附件的形式下载,传的名称是编码过的名称
- 获取文件的绝对路径
- 读取文件流
- 获取输出流
- 把文件写到响应当中
@Override
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String filename = request.getParameter("filename");
String mime = this.getServletContext().getMimeType(filename);
response.setContentType(mime);
filename = new String(filename.getBytes("ISO8859-1"), "UTF-8");
String agent = request.getHeader("User-Agent");
String filenameEncoder = "";
if (agent.contains("MSIE")) {
// IE编码
filenameEncoder = URLEncoder.encode(filename, "utf-8");
filenameEncoder = filenameEncoder.replace("+", " ");
} else if (agent.contains("Firefox")) {
// 火狐编码
BASE64Encoder base64Encoder = new BASE64Encoder();
filenameEncoder = "=?utf-8?B?" + base64Encoder.encode(filename.getBytes("utf-8")) + "?=";
} else {
// 浏览器编码
filenameEncoder = URLEncoder.encode(filename, "utf-8");
}
response.setHeader("Content-Disposition", "attachment;filename=" + filename);
String path = this.getServletContext().getRealPath("download/" + filename);
FileInputStream in = new FileInputStream(path);
ServletOutputStream out = response.getOutputStream();
byte[] buffer = new byte[1024];
int len = 0;
while((len = in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
in.close();
out.close();
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号