ES-Mapping映射
什么是Mapping映射
- 概念:自动或手动为
index中的_doc建立的一种数据结构和相关配置,简称为mapping映射- 说白了,就是给我们索引中的某些字段指定一下数据类型
- 插入几条数据,让 es 自动为我们建立一个索引
PUT /website/_doc/1
{
"post_date":"2019-01-01",
"title":"my first article",
"content":"this is my first article in this website",
"author_id":11400
}
PUT /website/_doc/2
{
"post_date":"2019-01-02",
"title":"my second article",
"content":"this is my second article in this website",
"author_id":11400
}
PUT /website/_doc/3
{
"post_date":"2019-01-03",
"title":"my third article",
"content":"this is my third article in this website",
"author_id":11400
}
- 对比 MySQL 数据库建表语句如下:
- 以下语句只是用来对比的方便理解
create table website(
post_date date,
title varchar(50),
content varchar(100),
author_id int(11)
);
- 动态映射:dynamic mapping,自动为我们建立
index,以及对应的 mapping- mapping 中包含了每个
field对应的数据类型,以及如何分词等设置
- 先来尝试一波,各种搜索
GET /website/_search?q=2019
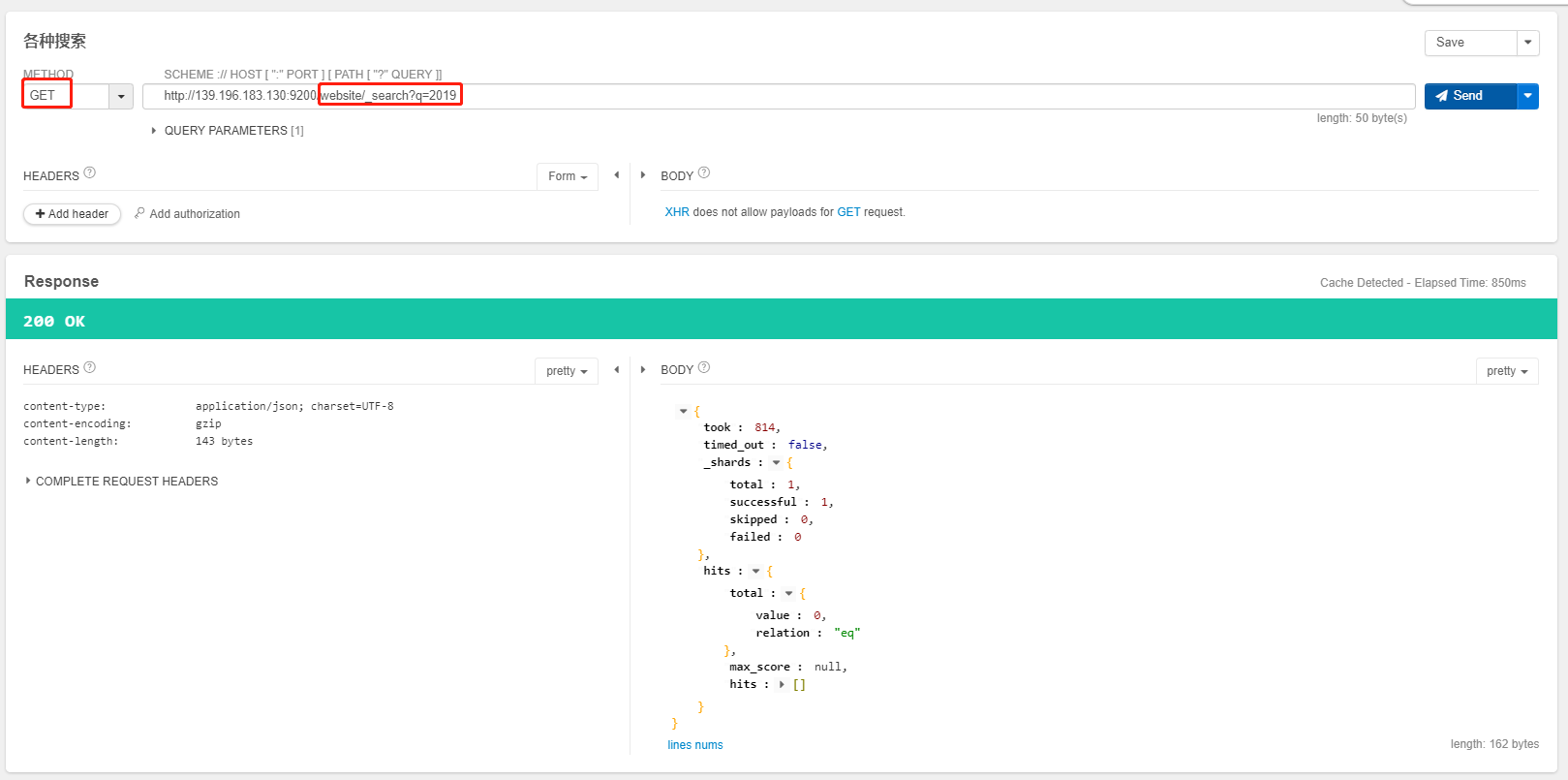
GET /website/_search?q=2019-01-01
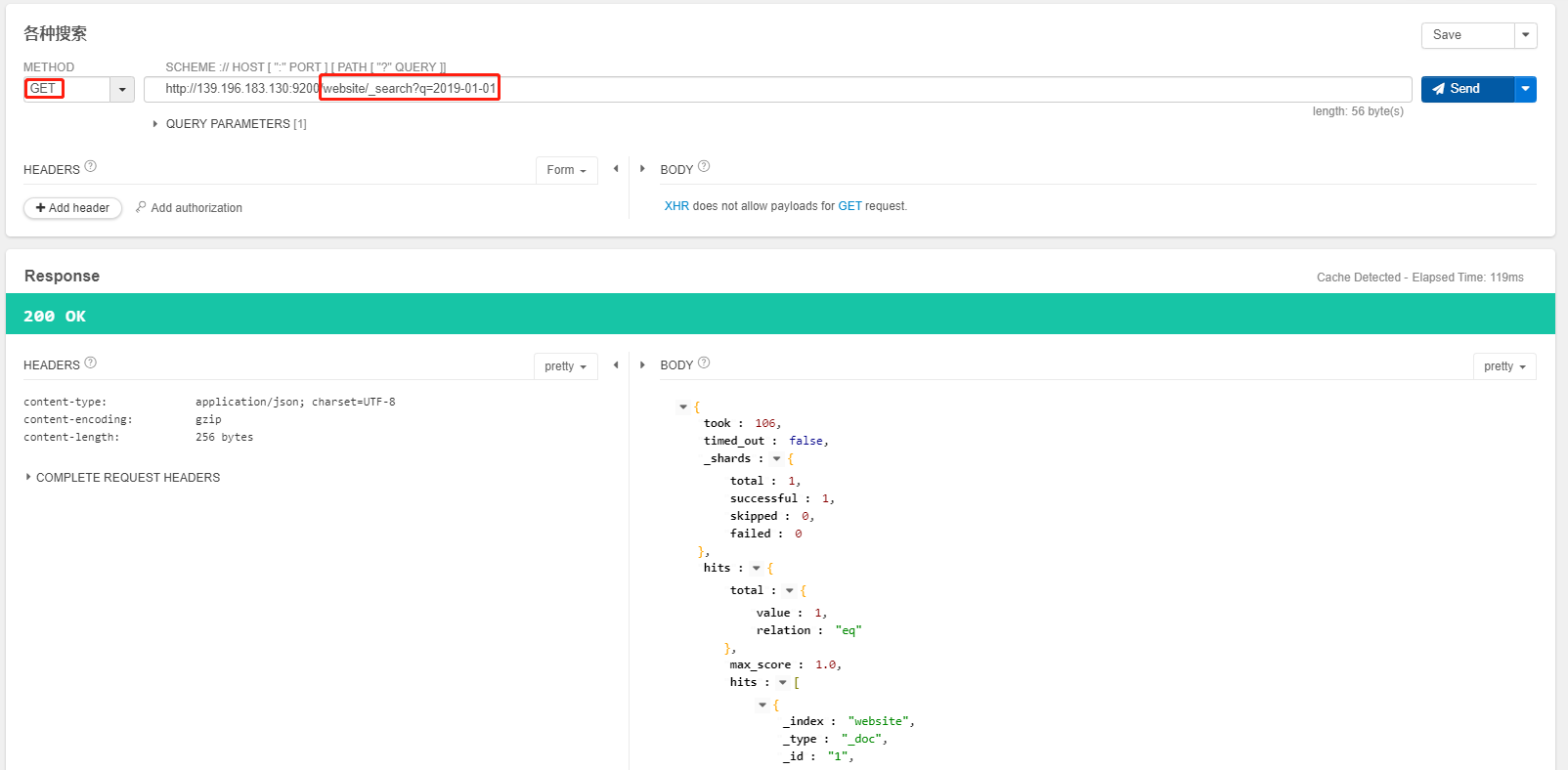
GET /website/_search?q=post_date:2019-01-01
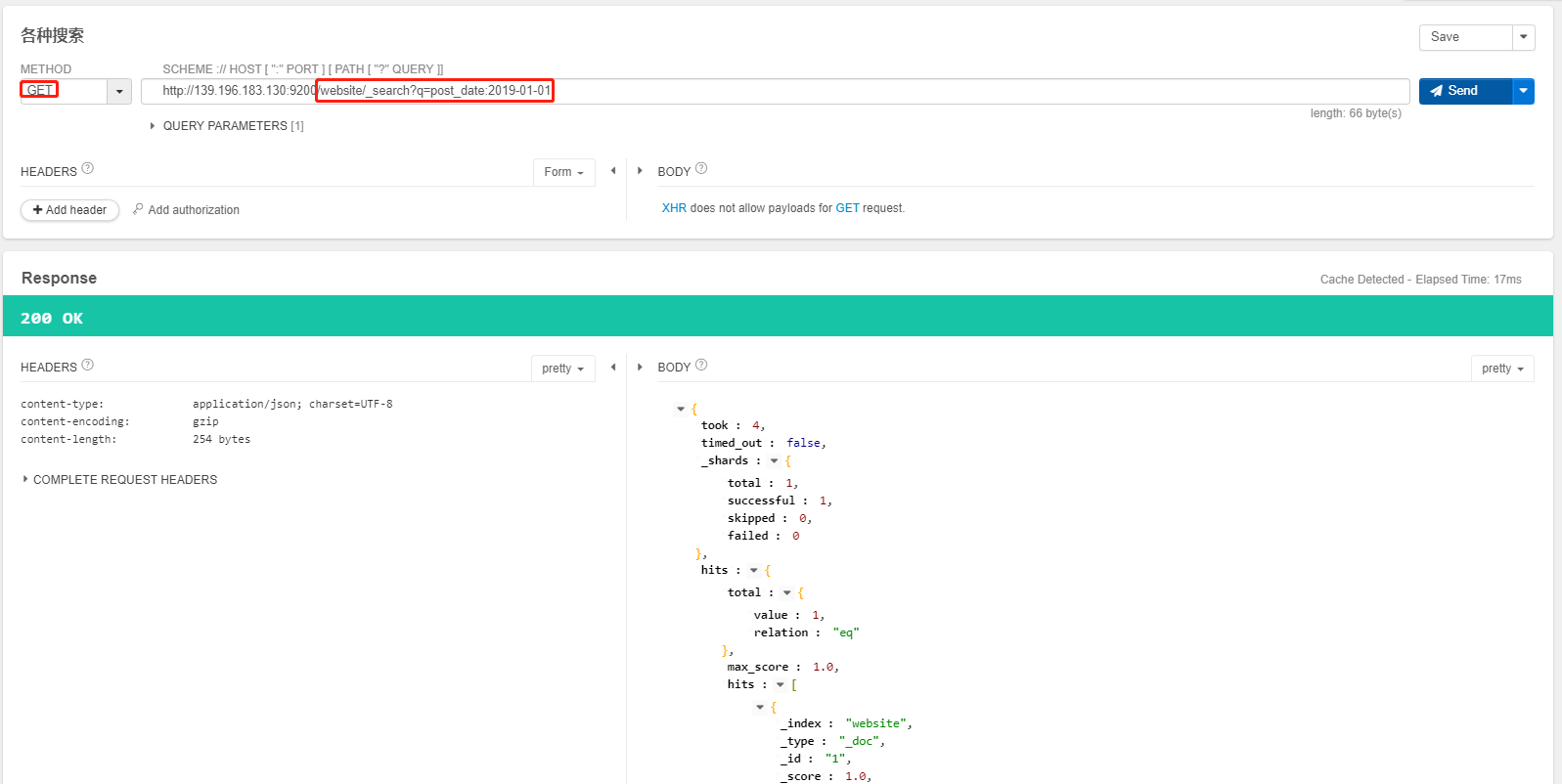
GET /website/_search?q=post_date:2019
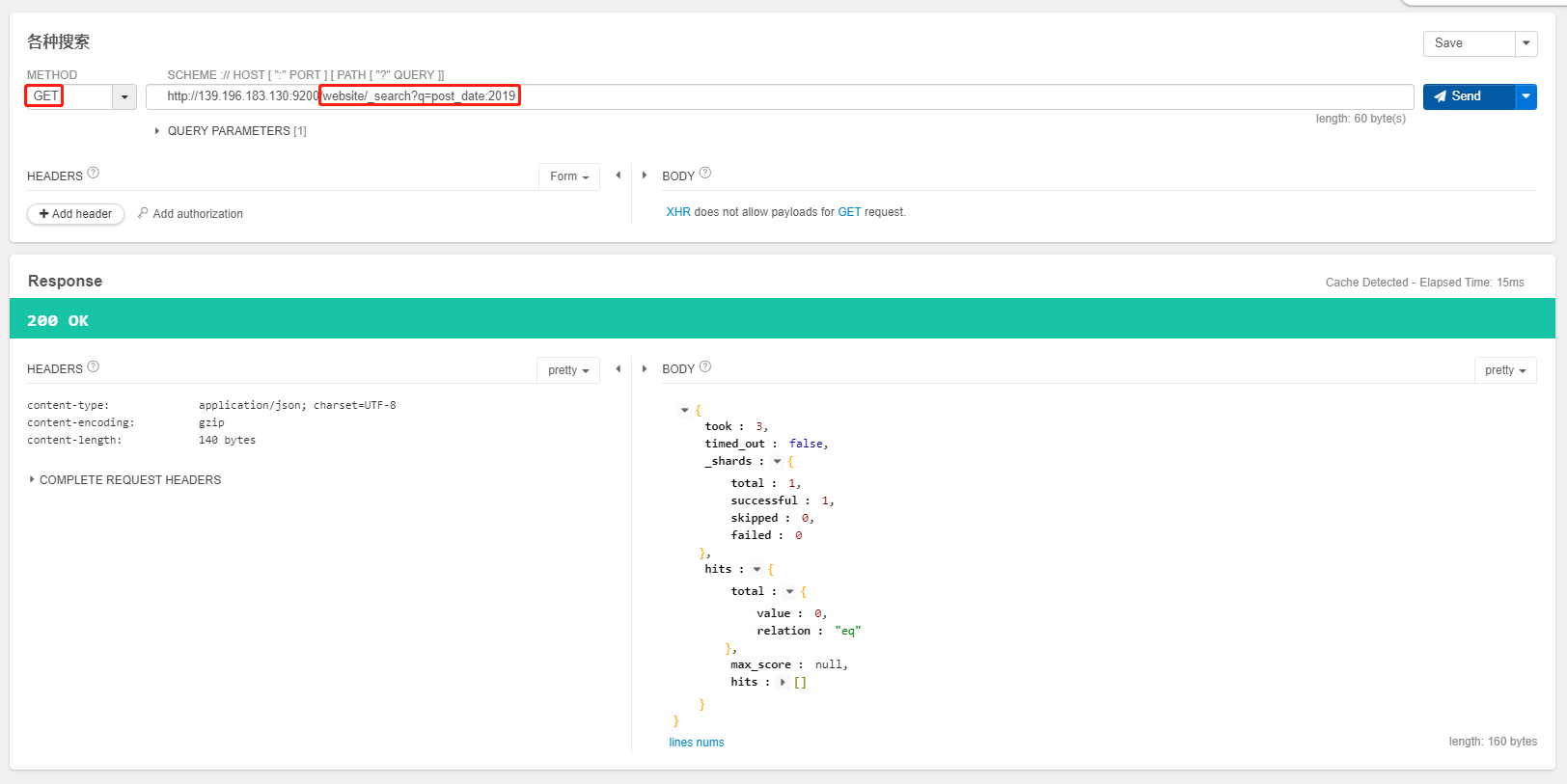
- 搜索结果为什么不一致,因为 es 自动建立 mapping 的时候,设置了不同的
field不同的data type- 不同的
data type的分词、搜索等行为是不一样的- 所以出现了
_all field和post_date field的搜索表现完全不一样
精确搜索与全文搜索对比
exact value 精确匹配
- 2019-01-01,exact value,搜索的时候,必须输入 2019-01-01,才能搜索出来
- 如果你输入一个
01,是搜索不出来的- 类似于下面的 SQL
select * from book where name = 'java'
full text 全文检索
- 缩写 vs. 全称:cn vs. china
- 格式转化:like liked likes
- 大小写:Tom vs tom
- 同义词:like vs love
- 2019-01-01,2019 01 01,搜索2019,或者 01,都可以搜索出来
- china,搜索
cn,也可以将 china 搜索出来- likes,搜索
like,也可以将 likes 搜索出来- Tom,搜索
tom,也可以将 Tom 搜索出来- like,搜索
love,同义词,也可以将 like 搜索出来
- 就不是说单纯的只是匹配完整的一个值,而是可以对值进行拆分词语后(分词)在进行匹配
- 也可以通过缩写、时态、大小写、同义词等进行匹配
- 深入
NPL,自然语义处理
全文检索下倒排索引是如何建立的
- doc1:I really liked my small dogs, and I think my mom also liked them.
- doc2:He never liked any dogs, so I hope that my mom will not expect me to liked him.
- 分词,初步的倒排索引的建立
| term | doc1 | doc2 |
|---|---|---|
| I | * | * |
| really | * | |
| liked | * | * |
| my | * | * |
| small | * | |
| dogs | * | |
| and | * | |
| think | * | |
| mom | * | * |
| also | * | |
| them | * | |
| He | * | |
| never | * | |
| any | * | |
| so | * | |
| hope | * | |
| that | * | |
| will | * | |
| not | * | |
| expect | * | |
| me | * | |
| to | * | |
| him | * |
- 演示了一下倒排索引最简单的建立的一个过程
- 搜索:mother like little dog,不可能有任何结果
- mother
- like
- little
- dog
- 这不是我们想要的结果
- 同义词 mom \ mother 在我们人类看来是一样
- 想进行标准化操作
- 重新建倒排索引
normalization 正规化,建立倒排索引的时候,会执行一个操作,也就是说对拆分出的各个单词进行相应的处理,以提升后面搜索的时候能够搜索到相关联的文档的概率
- 时态的转换,单复数的转换,同义词的转换,大小写的转换
- mom → mother
- liked → like
- small → little
- dogs → dog
- 重新建立倒排索引,加入
normalization,再次用 mother liked little dog 搜索,就可以搜索到了
| word | doc1 | doc2 | normalization |
|---|---|---|---|
| I | * | * | |
| really | * | ||
| like | * | * | liked → like |
| my | * | * | |
| little | * | small → little | |
| dog | * | dogs → dog | |
| and | * | ||
| think | * | ||
| mother | * | * | mom → mother |
| also | * | ||
| them | * | ||
| He | * | ||
| never | * | ||
| any | * | ||
| so | * | ||
| hope | * | ||
| that | * | ||
| will | * | ||
| not | * | ||
| expect | * | ||
| me | * | ||
| to | * | ||
| him | * |
- 重新搜索
- 搜索:mother liked little dog
- 对搜索条件经行分词
normalization- mother
- liked → like
- little
- dog
- doc1 和 doc2 都会搜索出来
Mapping核心数据类型
- text,keyword
- byte,short,integer,long,float,double
- boolean
- date
dynamic mapping 推测规则
- 当我们不手动配置映射时,索引会为我们自动配置映射
- 自动映射会依据字段的值去推测这个字段的数据类型
- true or false → boolean
- 123 → long
- 123.45 → double
- 2019-01-01 → date
- "hello world" → text / keywod
手动管理Mapping
查看Mapping
GET /index/_mapping/

查看所有索引的映射
GET /_mapping

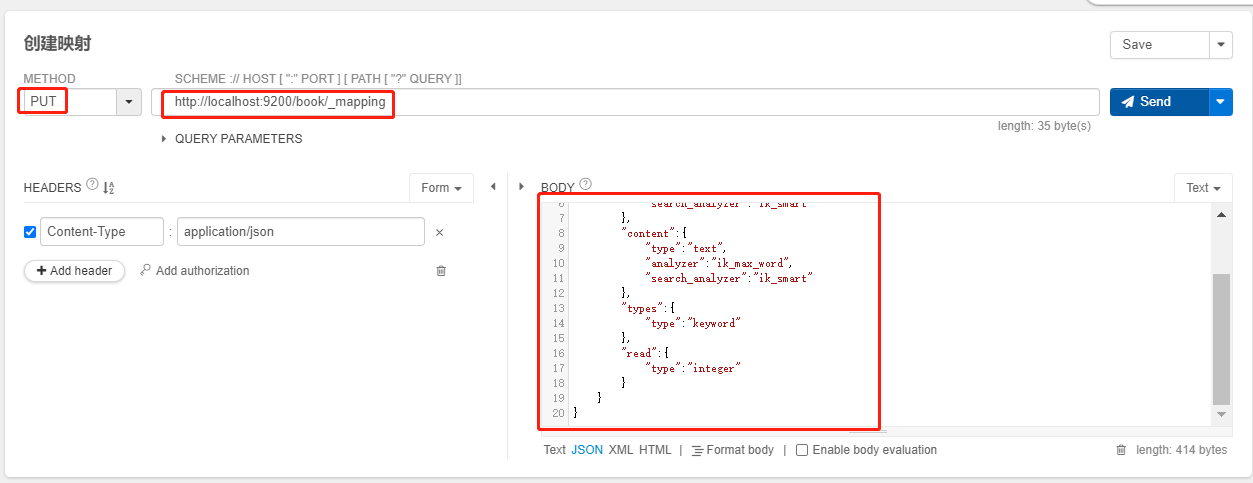
创建映射
- 就像我们编写 java 代码一样,创建了类之后就需要提供属性
- 我们创建索引后,也应该立即手动创建映射
- 先创建好索引
- 还需要安装好 IK 分词器
- 在执行如下指令即可创建
PUT book/_mapping
{
"properties":{
"title":{
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"content":{
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"types":{
"type":"keyword"
},
"read":{
"type":"integer"
}
}
}
Text文本类型
- 通过
analyzer属性指定分词器- 上边指定了
analyzer是指在索引和搜索都使用english- 如果单独想定义搜索时使用的分词器则可以通过
search_analyzer属性
index属性指定是否索引- 默认为
index = true,即要进行索引,只有进行索引才可以从索引库搜索到- 但是也有一些内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片
- 此时可以将
index设置为false- 删除索引,重新创建映射,将
pic的index设置为false,尝试根据pic去搜索,结果搜索不到数据
- 开始测试,插入文档
PUT /book/_doc/1
{
"name":"Bootstrap开发框架",
"description":"Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。",
"pic":"group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"studymodel":"201002"
}
GET /book/_search?q=name:开发
GET /book/_search?q=description:开发
GET /book/_search?q=pic:group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg
GET /book/_search?q=studymodel:201002
- 通过测试发现:
name和description都支持全文检索,pic不可作为查询条件
keyword关键字
- 目前已经取代了
"index": false- 上边介绍的
text文本字段在映射时要设置分词器,keyword字段为关键字字段,通常搜索keyword是按照整体搜索,所以创建keyword字段的索引时是不进行分词的- 比如:邮政编码、手机号码、身份证等
keyword字段通常用于过虑、排序、聚合等
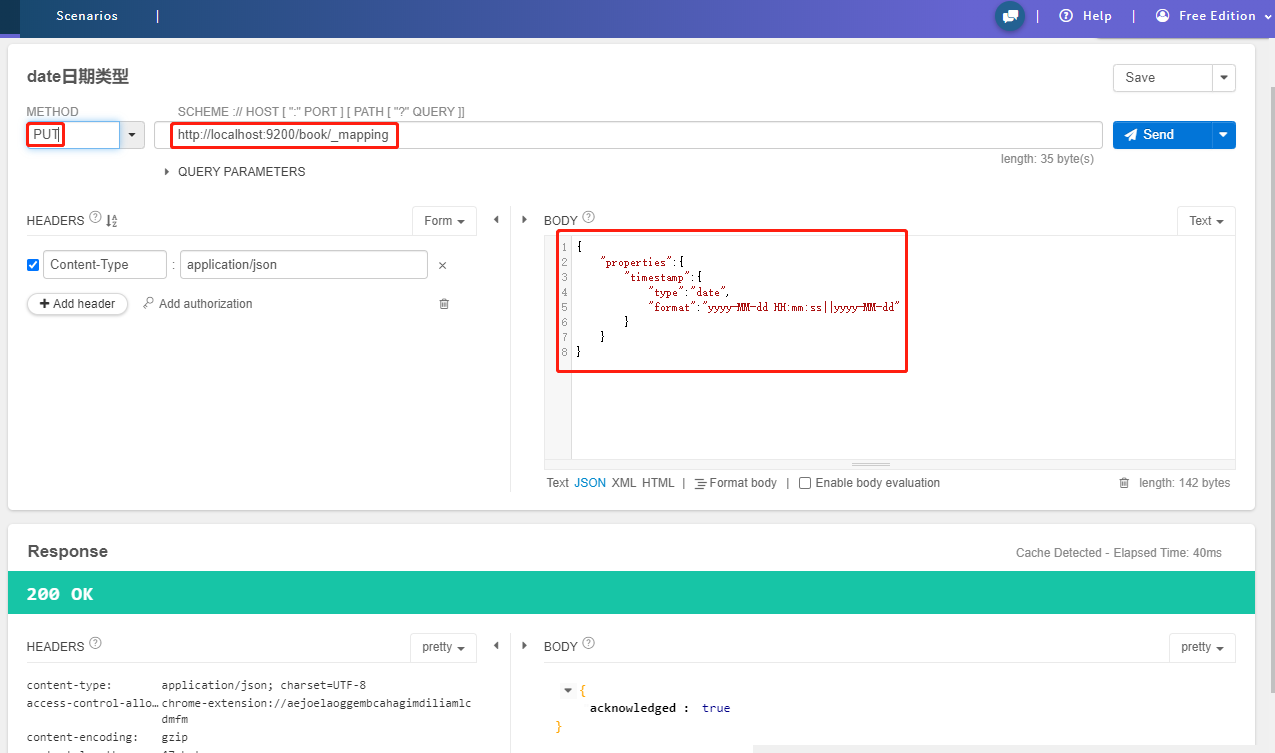
date日期类型
- 日期类型不用设置分词器
- 通常日期类型的字段用于排序
- 通过
format设置日期格式- 例子如下:
- 下边的设置允许
date字段存储 年月日时分秒、年月日及毫秒三种格式
PUT /book/_mapping
{
"properties":{
"timestamp":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
}
}
}
- 插入文档:
PUT /book/doc/3
{
"name":"spring开发基础",
"description":"spring 在java领域非常流行,java程序员都在用。",
"studymodel":"201001",
"pic":"group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"timestamp":"2018-07-04 18:28:58"
}
- 数值类型
- ES 支持以下几种数值类型
- long、integer、short、byte、double、float、half_float、scaled_float
修改和删除映射
- 只能创建
index时手动建立 mapping,或者新增field mapping- 但是不能
update field mapping- 因为已有数据按照映射早已分词存储好
- 如果修改,那这些存储好的数据就会出问题
- 同样,映射也不能删除,如果想删除映射,只能通过删除索引的方式进行删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号