
ES-Search搜索
普通搜索
- 语法如下:
GET /index/_search
/article/_search

查询结果解释
took:执行的时长,毫秒timed_out:是否超时_shards:到几个分片中搜索(也就是到了多少个库中进行了检索),成功几个,跳过几个,失败几个total:查询总数max_score:相关度,越相关,分数越高hits:查询到的 document,也就是查询命中的文档
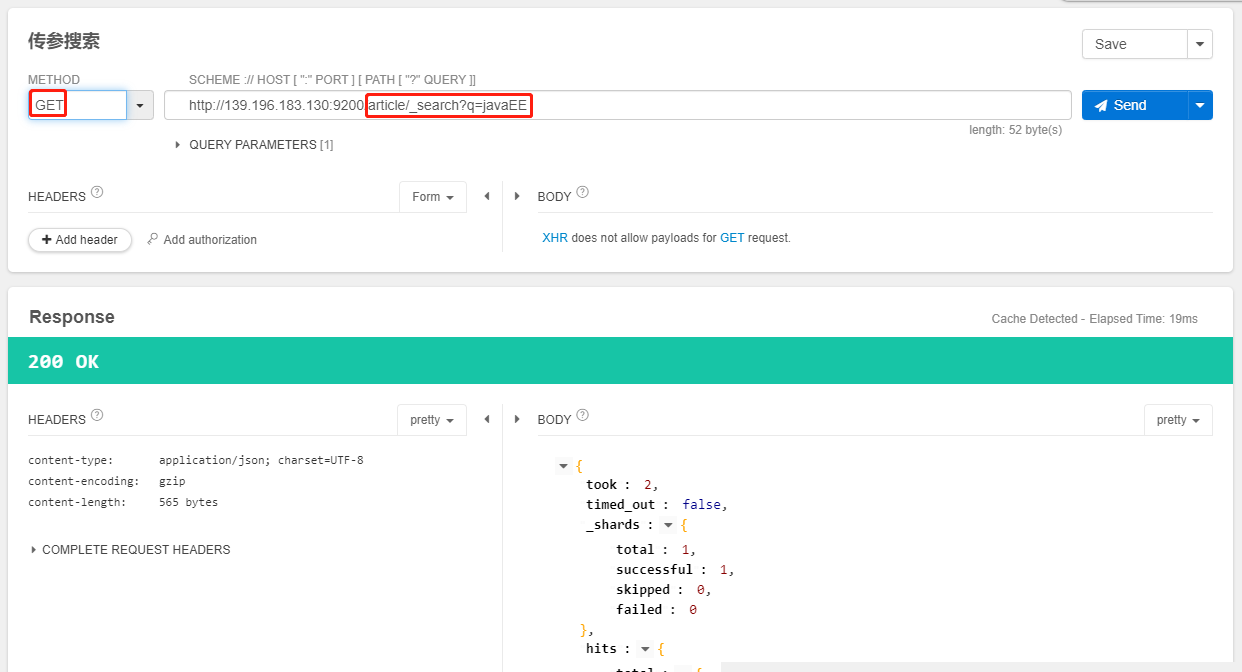
传参搜索
- 语法:
GET /index/_search?q=key:value&sort=key:desc或者asc
/article/_search?q=content:java
/article/_search?q=content:java&sort=red:desc
- 第二种语法:
GET /index/_search?q=value
- 这样可以搜索到所有的字段
- 任意一个字段包含指定的关键字都可以搜索出来
- 注意,这种搜索方式并不是把每个字段遍历了一遍,ES 在建立索引的时候,会将所有的
field值进行全量分词,把这些分词放到 all field 中,在不指定字段的时候,就从 all 中搜索
/article/_search?q=javaEE
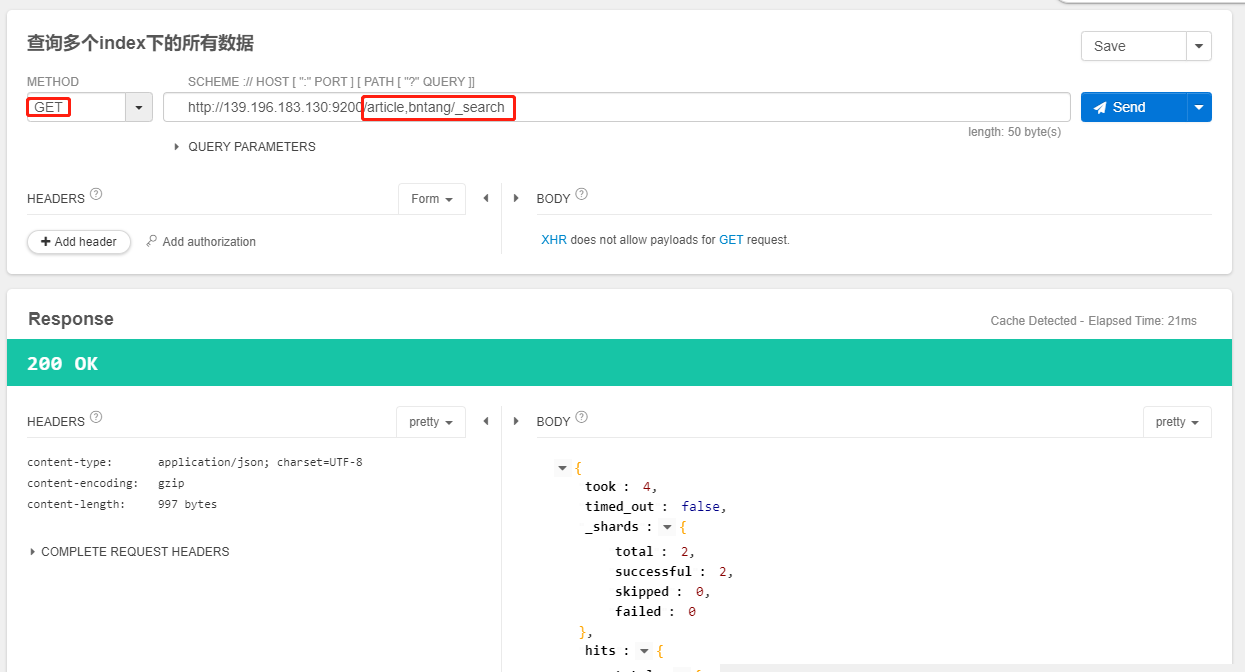
多个索引搜索
- 语法如下:
/_search 查询所有索引下的所有数据

/index/_search 查询index下的所有数据

/index1,index2/_search 查询多个index下的所有数据
/index*/_search 通配符去搜索多个索引
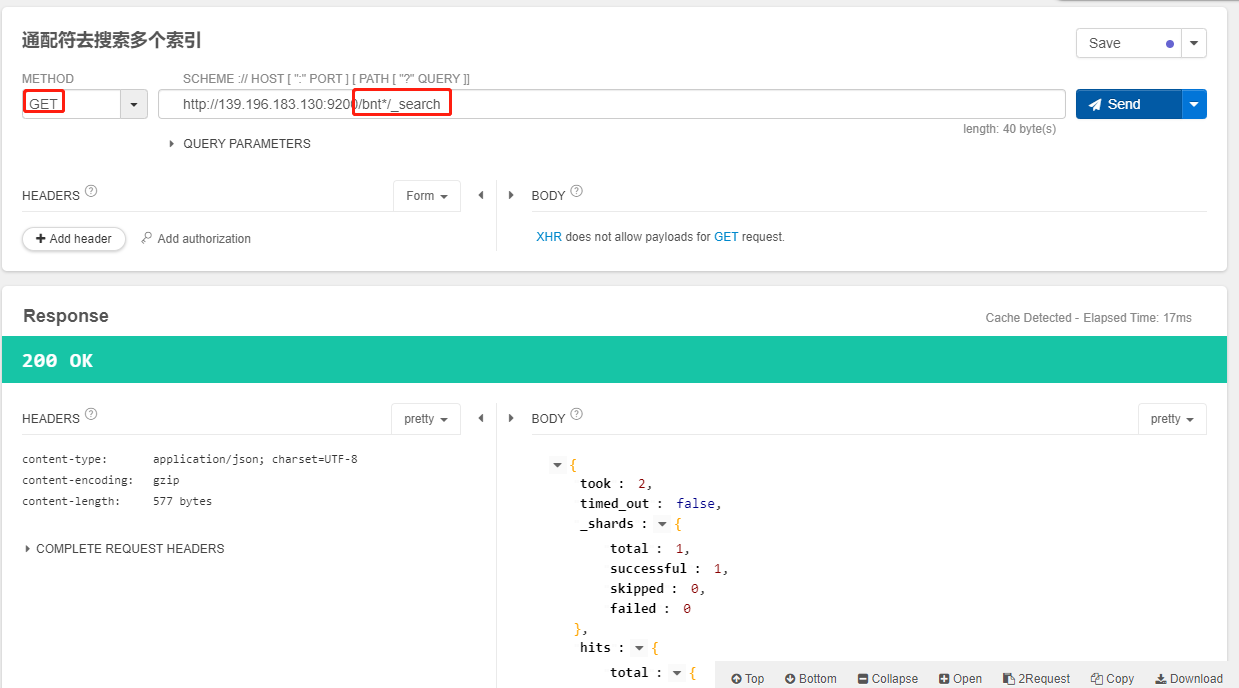
- 应用场景:如日志表,会按照日期拆分,每天一个日志
分页搜索
- 语法如下:
- MySQL语法:select * from article limit 4, 2
GET /index/_search?from=1&size=2

- 这里的 from 1 size 1 相当于 MySQL 中的 limit 1, 1
QUERY DSL
- 我们上面的搜索方式,是把查询条件用问号拼接到后面,当参数越来越多的时候,搜索条件越来越复杂的时候,操作起来很麻烦
- ES 可以在请求体携带搜索条件,功能强大
- DSL:Domain Specified Language,特定领域的语言
查询全部
POST /index/_search
{
"query":{
"match_all":{
}
}
}

条件查询
- 例如下面的语法是我们之前用的
POST /index/_search?q=name:java
- 现在的查询方式如下:
{
"query":{
"match":{
"title":"java PHP"
}
}
}

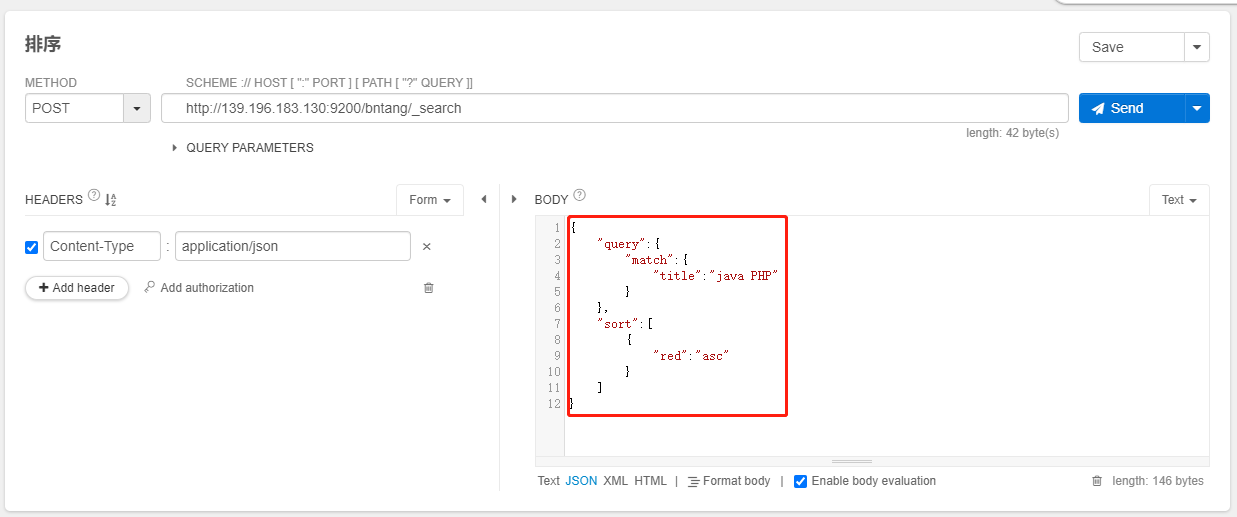
排序
- 之前写法
POST /index/_search?sort=read
- 现在写法如下:
{
"query":{
"match":{
"title":"java PHP"
}
},
"sort":[
{
"red":"asc"
}
]
}
分页查询
- 之前写法
POST /index/_search?size=10&from=0
- 现在写法如下:

指定查询返回的字段
- 之前的写法
POST /index/_search?_source=title,content
- 现在的写法
{
"query":{
"match_all":{
}
},
"_source":[
"title",
"content"
]
}

DSL语法深入
全查询 match_all
POST /index/_search
{
"query":{
"match_all":{
}
}
}

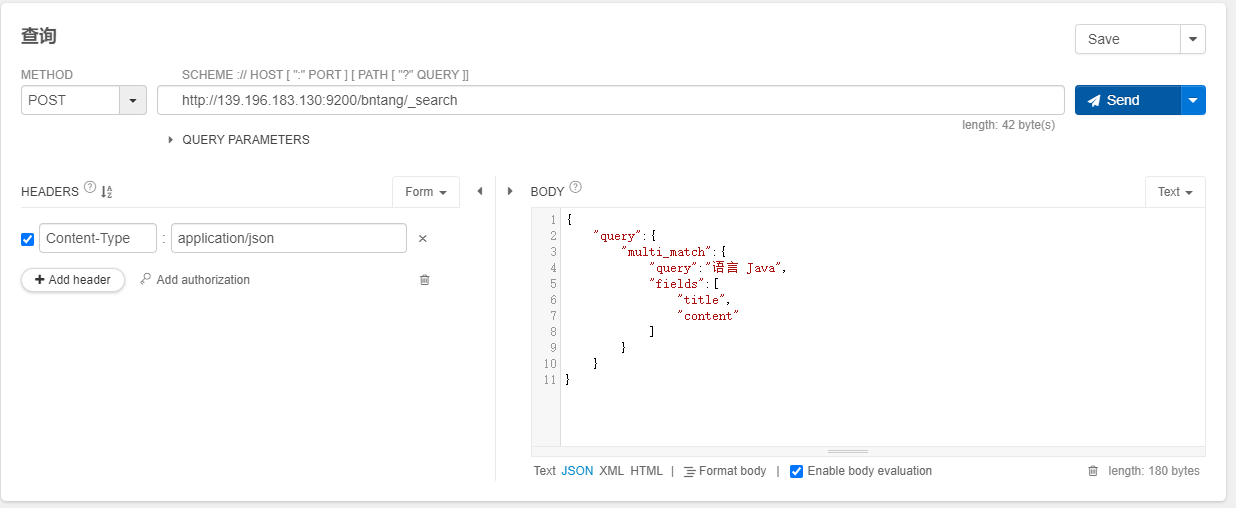
查询 match
POST /index/_search
{
"query":{
"multi_match":{
"query":"语言 Java",
"fields":[
"title",
"content"
]
}
}
}
范围查询 range query
POST /index/_search
{
"query":{
"range":{
"red":{
"lt":110,
"gt":50
}
}
}
}

gte:大于等于gt:大于lte:小于等于lt:小于boost:设置查询的推动值(boost)默认为1.0
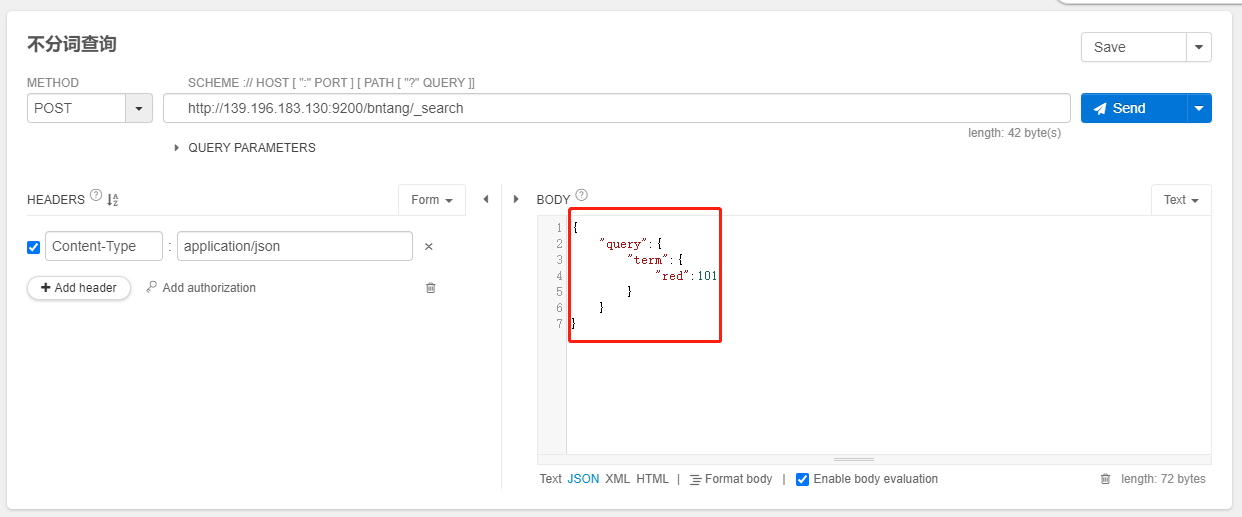
不分词查询 term query
- 字段为
keyword时,存储和搜索都不分词
POST /index/_search
{
"query":{
"term":{
"red":101
}
}
}
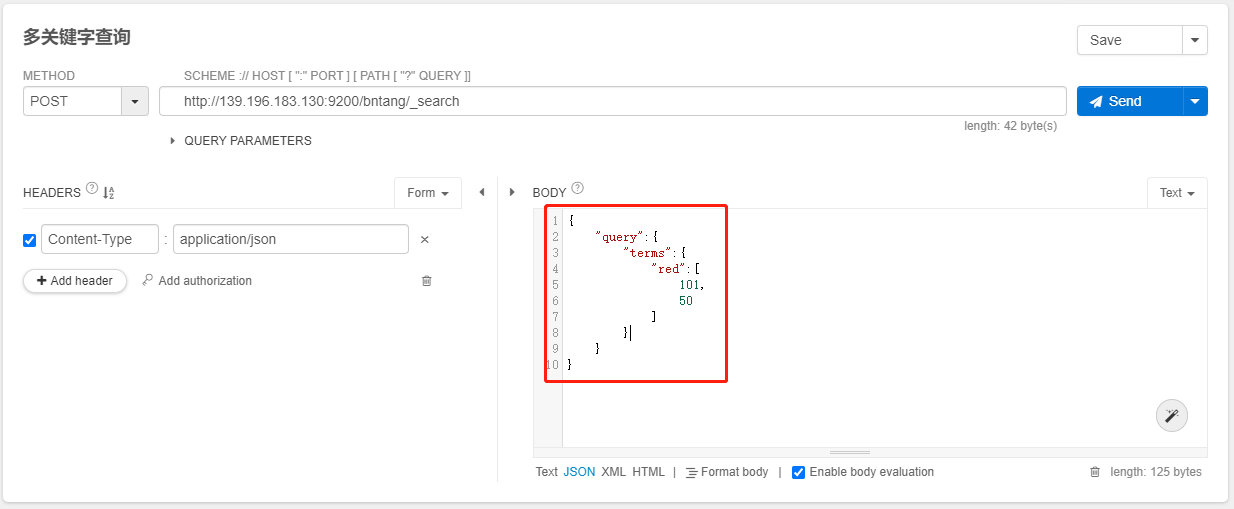
多关键字查询 terms query
POST /index/_search
{
"query":{
"terms":{
"red":[
101,
50
]
}
}
}
查询包含某些字段的文档 exist query
POST /_search
{
"query":{
"exists":{
"field":"red"
}
}
}

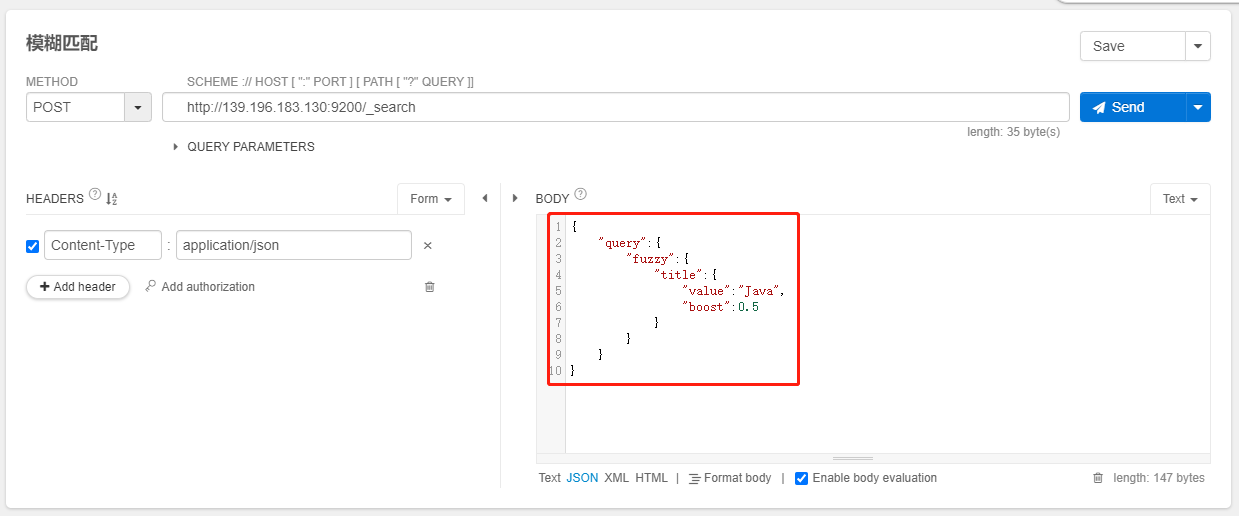
模糊匹配 Fuzzy query
- 返回包含与搜索词类似的词的文档,该词由 Levenshtein 编辑距离度量
value:查询的关键字boost:查询的权值,默认值是1.0min_similarity:设置匹配的最小相似度,默认值0.5,对于字符串,取值 0-1(包括0和1)对于数值,取值可能大于 1 对于日期取值为1d,1m等,1d 等于 1 天prefix_length:指明区分词项的共同前缀长度,默认是 0
- 包括以下几种情况:
- 更改角色(big → pig)
- 删除字符(good → god)
- 插入字符(god → good)
- 调换两个相邻字符(god → dog)
POST /index/_search
{
"query":{
"fuzzy":{
"title":{
"value":"Java",
"boost":0.5
}
}
}
}
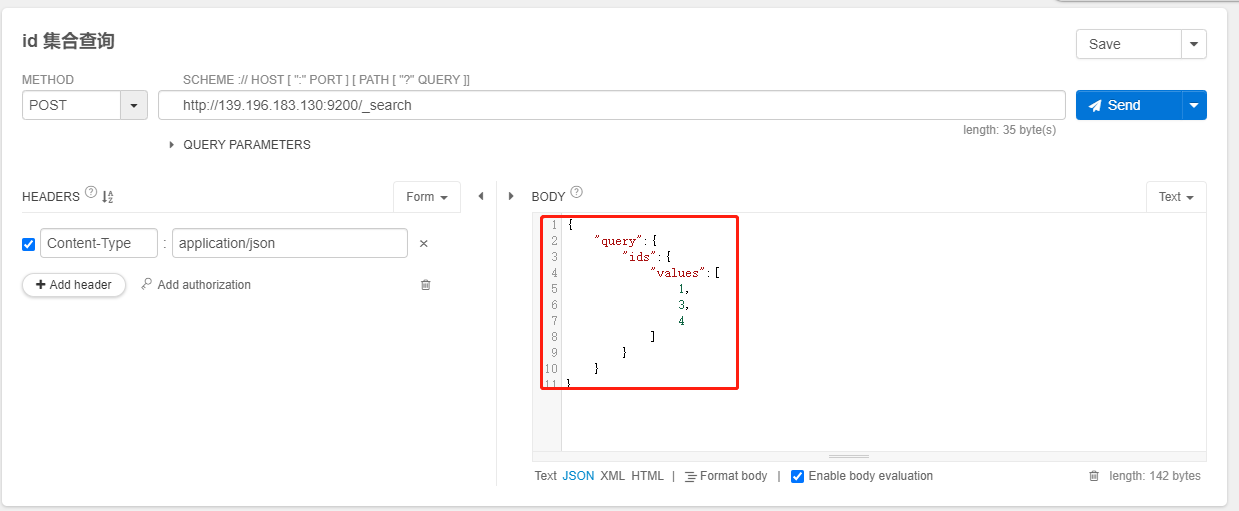
id 集合查询 ids
POST /index/_search
{
"query":{
"ids":{
"values":[
1,
3,
4
]
}
}
}
前缀查询 prefix
POST /index/_search
{
"query":{
"prefix":{
"title":{
"value":"java"
}
}
}
}

正则查询 regexp query
POST /index/_search
{
"query":{
"regexp":{
"title":{
"value":"j.*a.*"
}
}
}
}

组合查询
在 es 中,使用组合条件查询是为了作为搜索引擎检索数据的一个强大之处,上面的内容,简单的演示了 es 的查询语法,但基本的增删改查功能并不能很好的满足复杂的查询场景,比如说我们期望像 MySQL 那样做到拼接复杂的条件进行查询该如何做呢?es 中有一种语法叫 bool,通过在 bool 里面拼接 es 特定的语法可以做到大部分场景下复杂条件的拼接查询,也叫 复合查询
- 首先简单的介绍 es 中常用的
组合查询用到的关键词
must:如果有多个条件,这些条件都必须满足,相当于andshould:如果有多个条件,满足一个或多个即可,相当于ormust_not:和 must 相反,必须都不满足条件才可以匹配到,相当于非
- 搜索需求:
title必须包含 elasticsearch,content可以包含 elasticsearch 也可以不包含,author_id必须不为 111
- 相当于 MySQL 中的:sql where and or !=
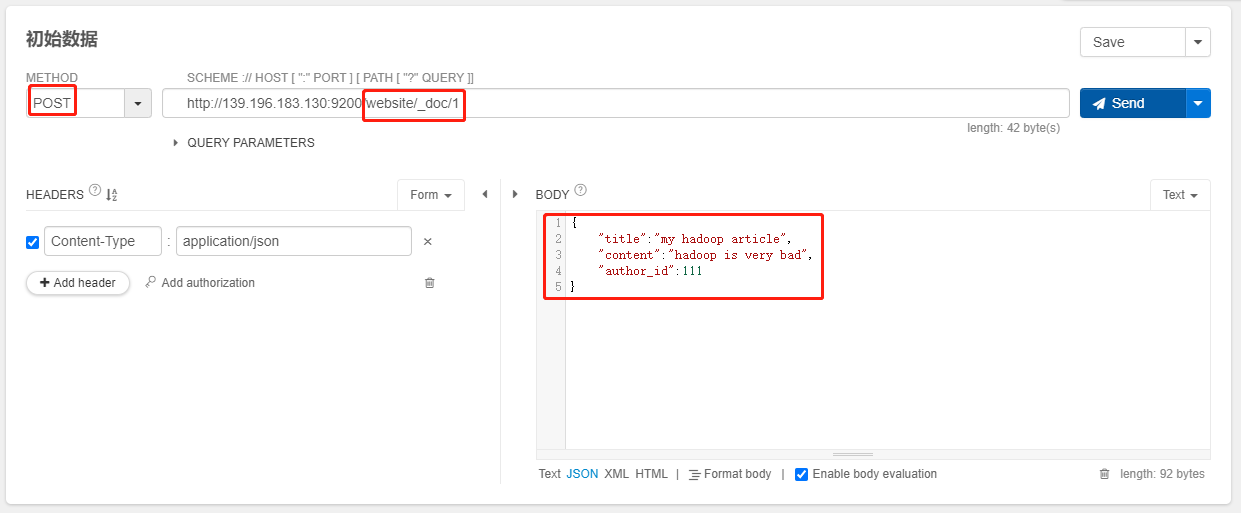
- 初始数据:
POST /website/_doc/1
{
"title":"my hadoop article",
"content":"hadoop is very bad",
"author_id":111
}
POST /website/_doc/2
{
"title":"my elasticsearch article",
"content":"es is very bad",
"author_id":112
}
POST /website/_doc/3
{
"title":"my elasticsearch article",
"content":"es is very goods",
"author_id":111
}
- 搜索:
POST /website/_doc/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"title":"elasticsearch"
}
}
],
"should":[
{
"match":{
"content":"elasticsearch"
}
}
],
"must_not":[
{
"match":{
"author_id":111
}
}
]
}
}
}

查询计划
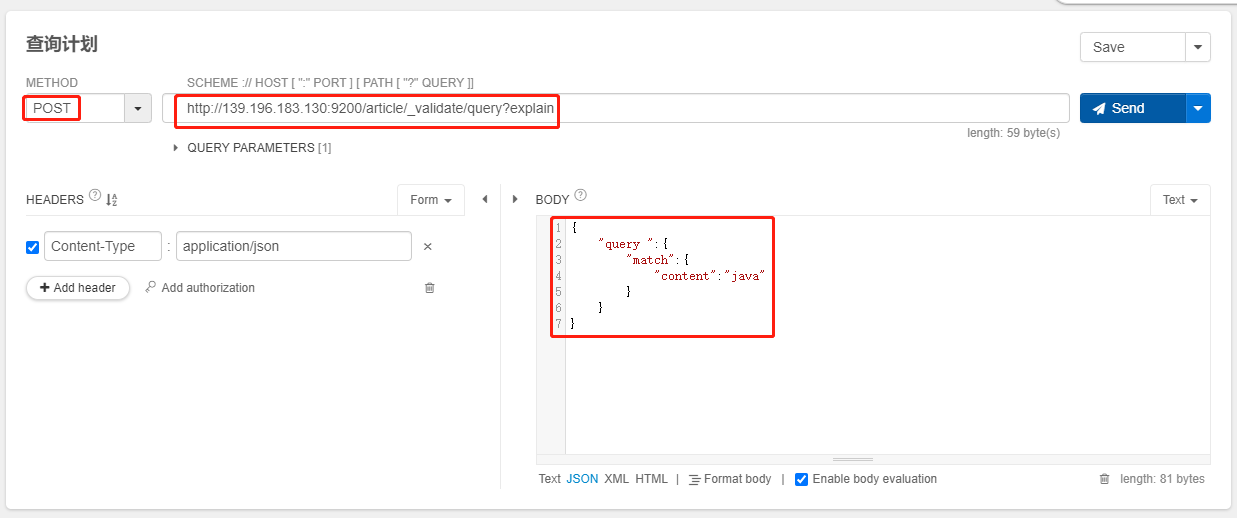
explain可以用来反映本次查询的一些信息,也可以用来定位查询错误- 验证错误语句:
POST /article/_validate/query?explain
{
"query ":{
"match":{
"content":"java"
}
}
}
正确
POST /bntang/_validate/query?explain
{
"query":{
"match":{
"content":"java"
}
}
}
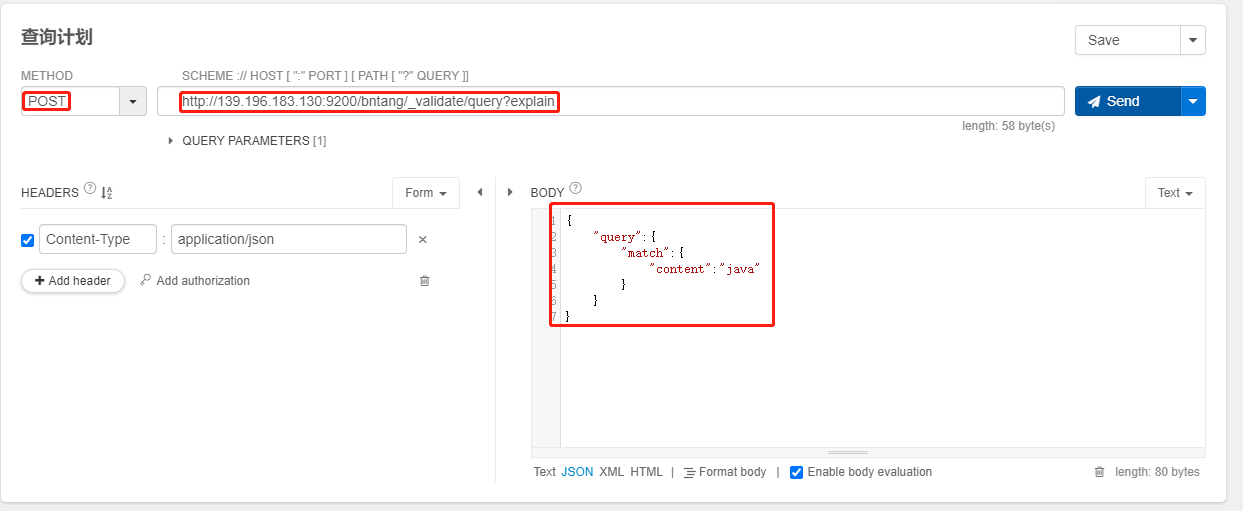
- 一般用在那种特别复杂庞大的搜索下,比如你一下子写了上百行的搜索,这个时候可以先用
validate api去验证一下,搜索是否合法- 合法以后,
explain就像 MySQL 的执行计划,可以看到搜索的目标等信息
滚动搜索
- 现在有一个需求,把某个索引中 1 亿条数据下载下来存到数据库中
- 如果一次查询出来,极有可能导致内存溢出,因此需要分批查询
- 除了我们上面说的分页查询以外,还可以使用滚动搜索技术
scroll
scroll搜索会在第一次搜索时,保留一个当时的快照,之后只会基于这个快照提供数据,这个时间段如果发生了数据的变更,用户不会感知- 每次发送
scroll请求,我们还需要指定一个 scroll 参数和一个时间窗口- 每次请求只要在这个时间窗口内完成就可以了
POST /article/_search?scroll=1m
{
"query":{
"match_all":{
}
},
"size":2
}

- 请求结果如下图:

- 获得的结果会有一个
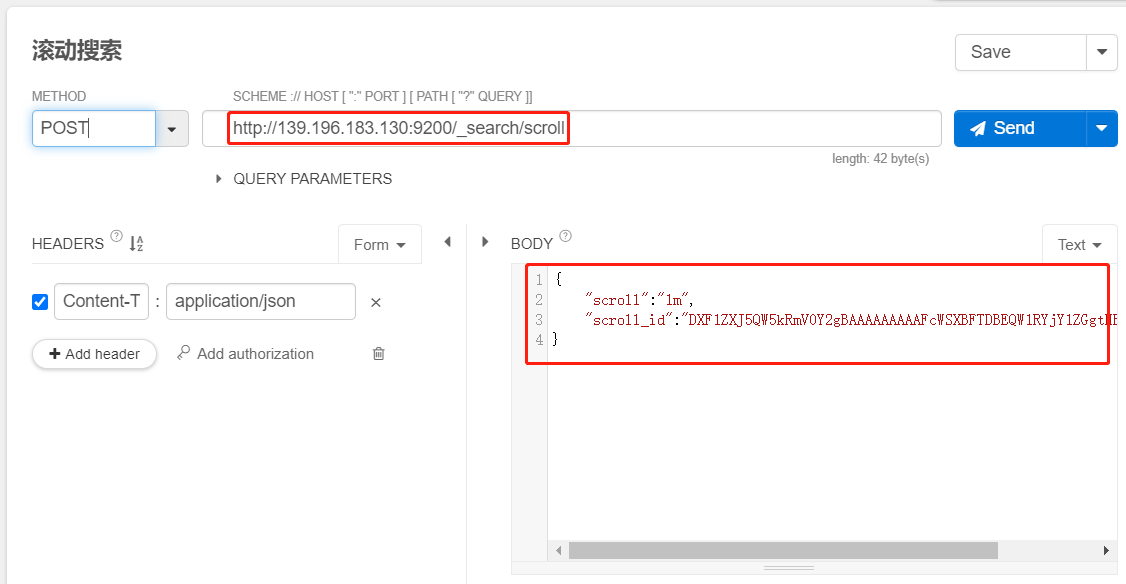
scoll_id,下一次再发送scoll请求的时候,必须带上这个scoll_id
POST /_search/scroll
{
"scroll":"1m",
"scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAFcWSXBFTDBEQW1RYjY1ZGgtMExDWk9ndw=="
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号