ES的简介
- ElasticSearch(简称 ES)
- 是使用 Java 开发,基于 Lucene、分布式、通过
Restfu 的方式进行交互的 近实时 的搜索平台框架
- 它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,Restful 风格接口,多数据源,自动搜索负载等
- ELK(ES + Logstash + Kibana)是一个免费的开源的日志分析架构技术栈总称,但实际上 ELK 不仅仅适用于日志分析
- 它还可以支持其它任何数据搜索、分析和收集的场景,日志分析和收集只是更具有代表性
- 随着 Elk 的发展,又有新成员 Beats、elastic cloud 的加入,所以就形成了 Elastic Stack
- 所以说,ELK 是旧的称呼,Elastic Stack 是新的名字
ES的特点
- 处理方式灵活:ES 是目前最流行的准实时全文检索引擎,具有高速检索大数据的能力\
- 接口简单:采用 JSON 的形式 RESTFUL API 接受数据并响应,无关语言
- 性能高效:ES 基于优秀的全文搜索技术
Lucene,采用 倒排索引,可以轻易地在百亿级别数据量下,搜索出想要的内容,并且是秒级响应
- 功能强大:ES 作为传统数据库的一个补充,提供了数据库所不不能提供的很多功能,如全文检索,同义词处理,相关度排名
ES的应用场景
- ES 主要用于 搜索
- 传统的数据库搜索存在以下弊端
- 电商、社交网站数据存储往往是 GB、PB 级
- 存储上亿条数据时,涉及到的单表数据过大就必须
分表,数据库磁盘占用过大就必须 分库
- 当查询 JavaWeb 时,上亿条数据的帖子需要从标题和内容中逐行扫描,性能相当差
- 不能分词,当我搜索 Java Web 时,只能搜到 Java Web 的数据,而搜不到 JavaWeb 的数据
- 而相对的,就可以使用 ES 进行解决
- ES 具有以下功能
- 分布式的搜索引擎
- 搜索:互联网搜索、站内搜索
- 全文检索,结构化检索,数据分析
- 对海量数据进行近实时的处理
- 分布式:ES 自动可以将海量数据分散到多台服务器上去存储和检索,经行并行查询
Lucene&Solr&ES
- Lucene:最先进、功能最强大的搜索库,直接基于
Lucene 开发,非常复杂,Api 复杂
- Solr:Solr 是一个高性能,采用
Java 开发,基于 Lucene 的全文搜索服务器
- 同时对其进行了扩展,提供了比
Lucene 更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎
- ES:基于
Lucene,封装了许多 Lucene 底层功能,提供简单易用的 Restful Api 接口和许多语言的客户端
- 据说 ES 的搜索性能是 Solr 的 50倍
- 起源:Shay Banon
- 2004 年失业,陪老婆去伦敦学习厨师
- 失业在家帮老婆写一个菜谱搜索引擎
- 封装了
Lucene 的开源项目,compass
- 找到工作后,做分布式高性能项目,再封装 compass,写出了 ES,使得 Lucene 支持分布式
- 现在是 ES 的创始人兼 Elastic 首席执行官
- 当单纯的对已有数据进行搜索,并且数据量不是很大时,Solr 更快
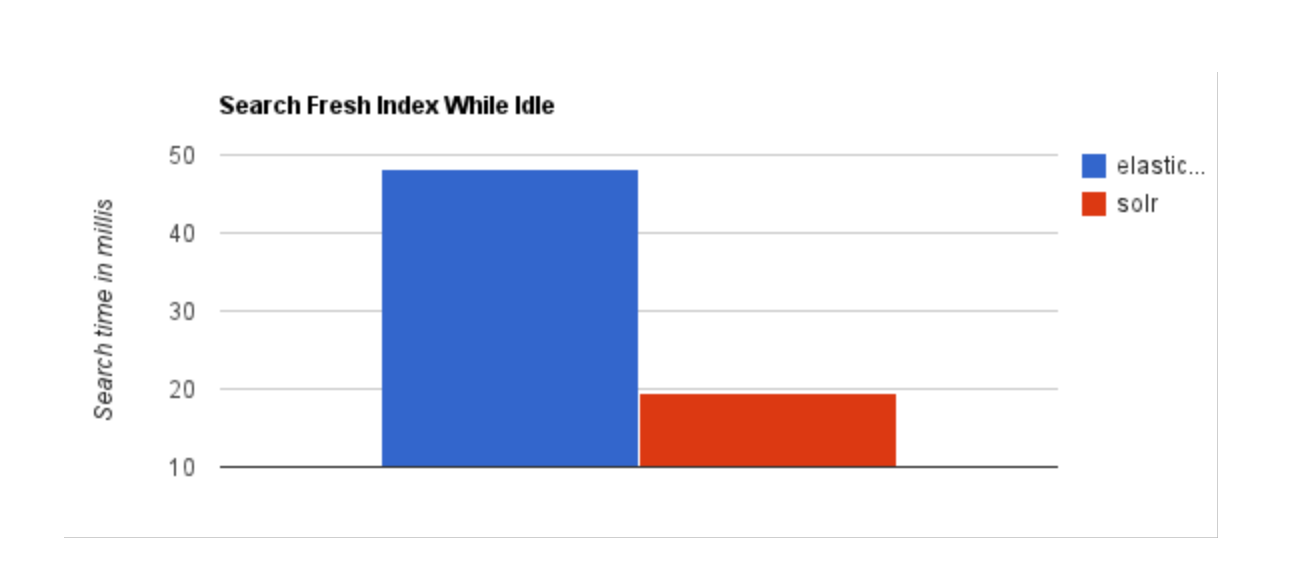
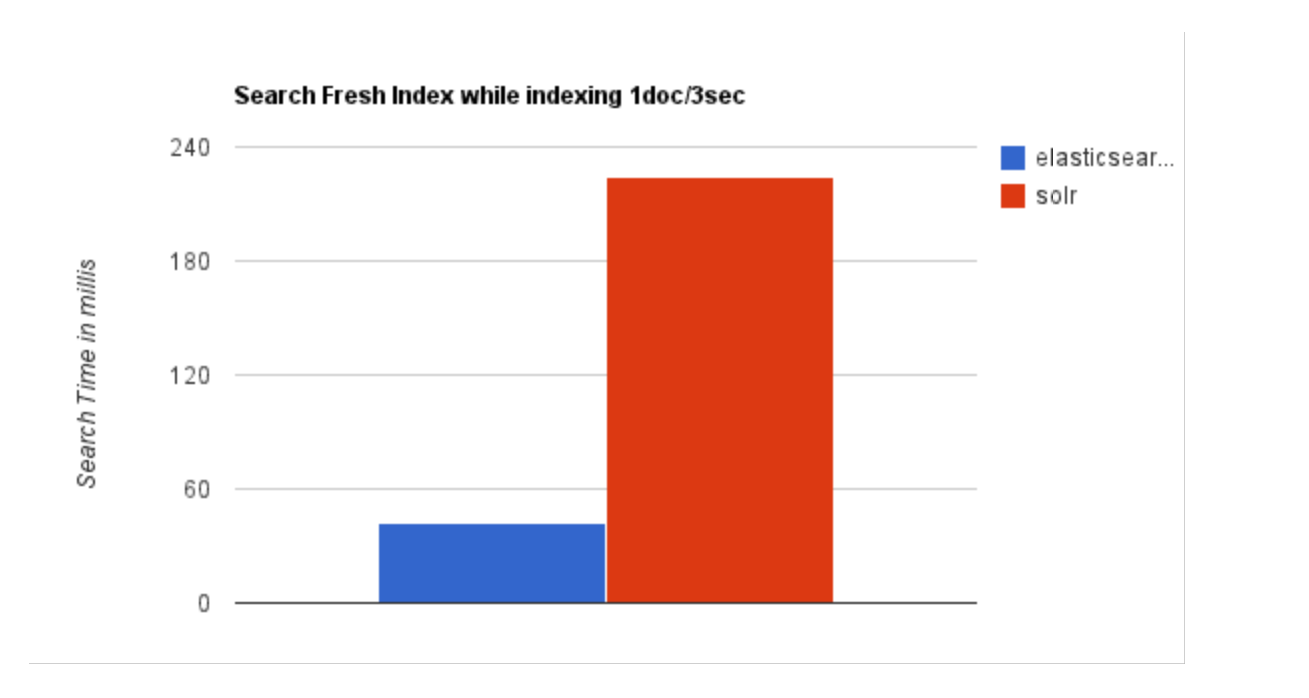
- 当实时建立索引时, Solr 会产生
io阻塞,查询性能较差, ES 具有明显的优势
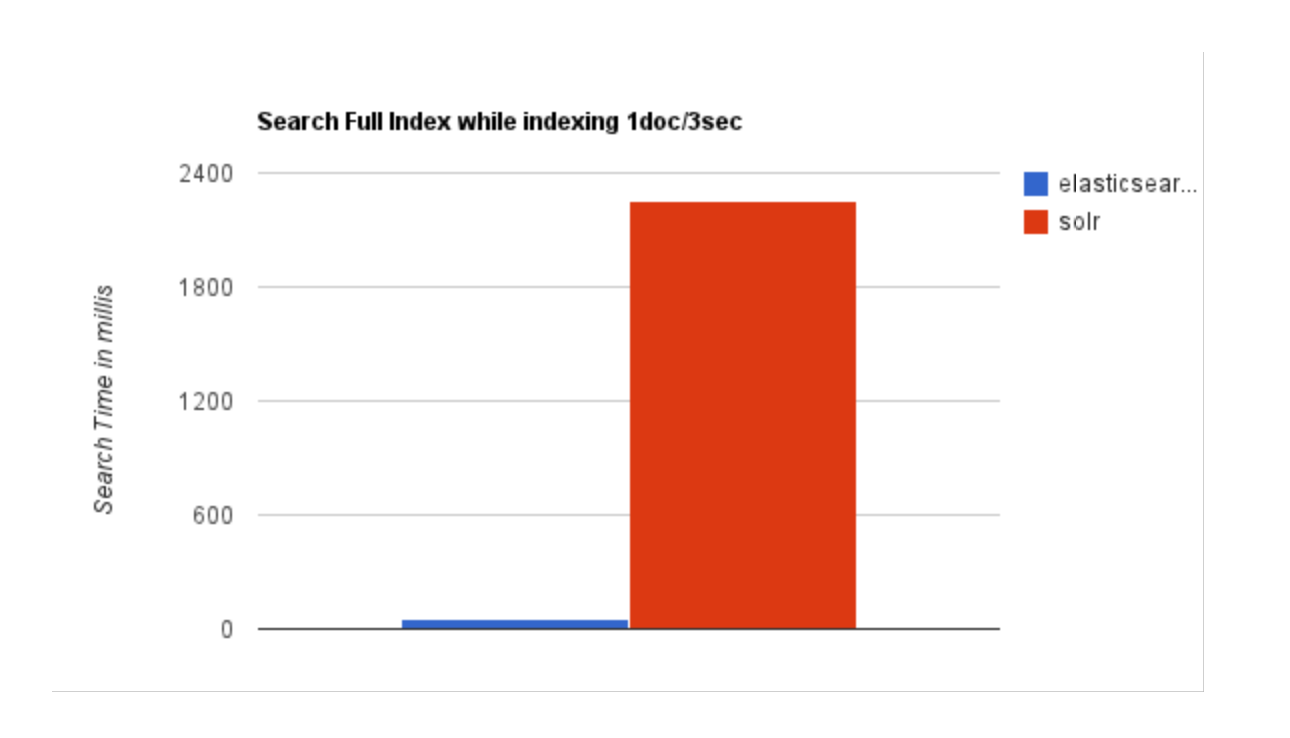
- 随着数据量的增加,Solr 的搜索效率会变得更低,而 ES 却没有明显的变化
倒排索引
正排索引
- 在说倒排索引之前我们先说说什么是正排索引
- 正排索引也称为
前向索引,它是创建倒排索引的基础
- 这种组织的方法在建立索引的时候结构比较简单,建立比较方便并且易于维护,因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面
- 若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除
- 他适合根据文档 ID 来查询对应的内容
- 但是在查询一个 keyword 在哪些文档里包含的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下
| 文档 ID |
文档内容 |
| 1 |
ElasticSearch 是最流行的搜索引擎 |
| 2 |
PHP 是世界上最好的语言 |
| 3 |
搜索引擎是如何诞生的 |
- 优点:工作原理非常的简单
- 缺点:检索效率太低,只能在一起简单的场景下使用
倒排索引
- 根据字面意思可以知道他和正序索引是反的
- 在搜索引擎中每个文件都对应一个文件 ID,文件内容被表示为一系列关键词的集合(文档要除去一些无用的词,比如
的 这些,剩下的词就是关键词,每个关键词都有自己的 ID)
- 例如
文档1 经过分词,提取了 3 个关键词,每个关键词都会记录它所在在文档中的出现频率及出现位置
- 那么上面的文档及内容构建的倒排索引结果会如下图:
| 单词 |
文档 ID |
| ElasticSearch |
1 |
| 流行 |
1 |
| 搜索引擎 |
1,3 |
| PHP |
2 |
| 世界 |
2 |
| 最好 |
2 |
| 语言 |
2 |
| 如何 |
3 |
| 诞生 |
3 |
如何查询
- 比如我们要查询
搜索引擎 这个关键词在哪些文档中出现过
- 首先我们通过倒排索引可以查询到该关键词出现的文档位置是在
1 和 3 中,然后再通过正排索引查询到文档 1 和 3 的内容并返回结果
倒排索引的组成
- 倒排索引主要由单词词典(Term Dictionary)和倒排列表(Posting List)及倒排文件(Inverted File)组成
- 他们三者的关系如下图:
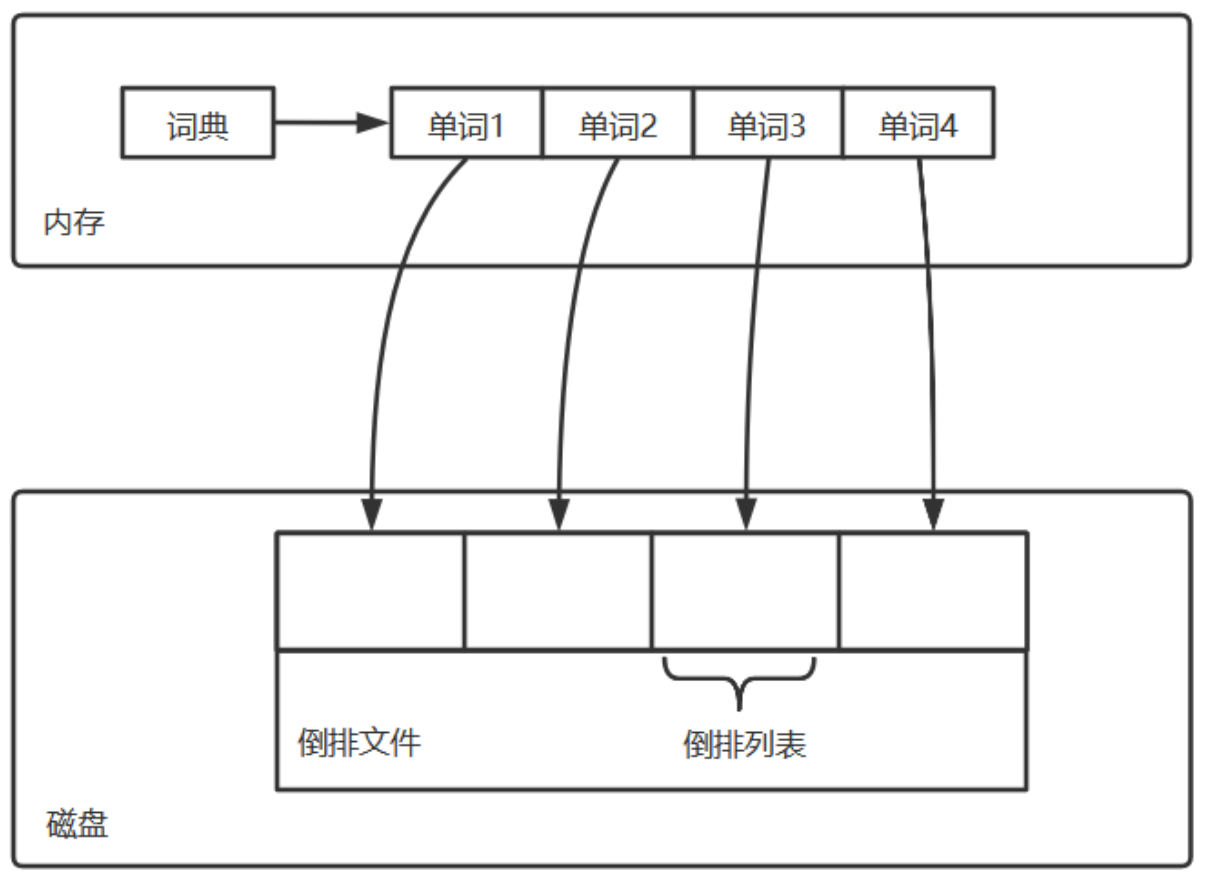
- 单词词典(Term Dictionary)搜索引擎的通常索引单位是 单词,单词词典是由文档集合 出现过的所有单词 构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向
倒排列表 的指针
- 倒排列表(PostingList)倒排列表记载了出 现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息及频率,每条记录称为一个 倒排项(Posting)根据倒排列表,即可获知哪些文档包含某个单词
- 倒排文件(Inverted File)所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件
ES核心概念
近实时
- 近实时(NRT)
- 写入数据时,内部在分词、录入索引,一般过 1 秒左右才会被搜索到
- ES 在搜索时,搜索和分析数据基本秒级出结果
集群
- 集群(Cluster)
- 包含一个或者多个启动着 ES 的机器群,同一网络下、集合一样的多个ES实例 自动组成集群,自动分片 等行为
节点
- 节点(Node)
- 每个 ES 实例称为一个节点
- 节点名称可以手动设置,默认自动分配
索引
- 索引(Index)
- 包含一堆有相似结构的文档数据
- 相当于数据库(也相当于表)
- 索引创建规则:
- 仅限小写字母
- 不能包含
\、/、 *、?、"、<、>、|、# 以及 空格 符等特殊符号
- 从
7.0 版本开始不再包含 冒号
- 不能以
-、_ 或 + 开头
- 不能超过
255 个字节(注意它是字节,因此多字节字符将计入 255 个限制)
文档
- 文档(Document)
- ES 中最小的数据单元,对应着数据库中的一条记录
- ES 的文档通常用 JSON 格式展示,多个文档存储于一个索引中
字段
类型
- 类型(Type)
- 每个索引里都可以有一个或多个
type,type 是 index 中的一个逻辑数据分类,一个 type 下的 document,都有相同的 field
- ES 官方将在
9.0 版本之后彻底删除 type
分片
- 分片(shard)
- 索引的数据量过大时,可以将索引中的数据分成多个分片,存储在多个服务器上
- 支持海量数据和高并发,提升性能和吞吐量
副本
- 副本(replica)
- 在分布式的环境下,任何一台机器都会随时宕机,如果宕机,就会导致此索引不能搜索
- 所以,为了保证数据的安全,我们会将每个索引的分片经行备份,存储在另外的机器上
- 保证少数机器宕机 ES 集群仍可以搜索
- 能正常的提供查询和插入的分片我们叫做
主分片(primary shard)
- 其余的我们就管他们叫做备份的分片(replica shard)
- ES 6.0 默认新建索引时是一主一备,2 副本 5 分片,总计 10 个集群
- 因此 ES 集群 至少需要 2 台服务器
MySQL与ES的对应关系
| MySQL |
ElasticSearch |
| 数据库 Database |
索引 Index |
| 表 Table |
索引 Index(旧版本中对应 type) |
| 数据行 row |
文档 Document |
| 数据列 Column |
字段 Field |
posted @
2020-10-09 10:10
BNTang
阅读(
369)
评论()
收藏
举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号