Hystrix
雪崩问题
- 一个服务, 依赖于另一个服务, 如果这个功能服务挂掉了, 那么依赖的服务就不能再用了
- 这种级联的失败, 我们可以称之为
雪崩
Hystrix概述
- Hystrix 是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败
- 比如超时、异常等
- Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,提高分布式系统的弹性
- 官方地址:https://github.com/Netflix/Hystrix
降级
- 降级是当我们的某个微服务响应时间过长,或者不可用了也就是那个微服务调用不了了
- 我们不能吧错误信息返回出来,或者让他一直卡在那里,所以要在准备一个对应的策略(一个方法)
- 当发生这种问题的时候我们直接调用这个方法来快速返回这个请求,不让他一直卡在那
- 当某个微服务调用不了了要做降级,也就是说,要在
调用方,做降级(不然那个微服务都 down 掉了再做降级也没什么意义了)
降级实现步骤
- 这一步不是必要的,我这个不知道啥原因出现了一个错误
- 考虑重命名其中一个 bean,或者通过设置 spring.main.allow-bean-definiti 来启用覆盖
修改 application.yml 添加如下配置
spring:
main:
allow-bean-definition-overriding: true
- 在服务调用方添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
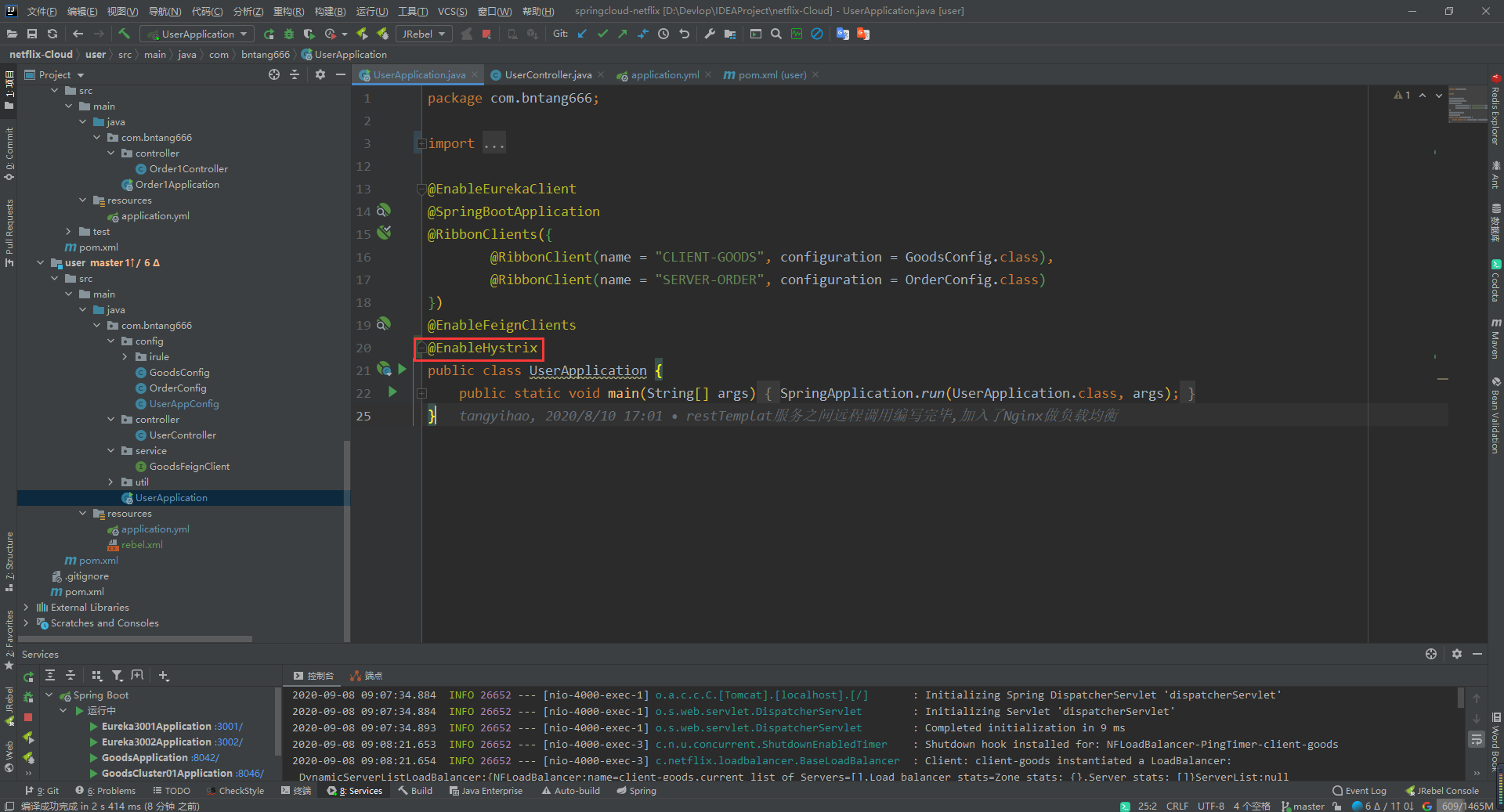
- 启动类加入
@EnableHystrix注解
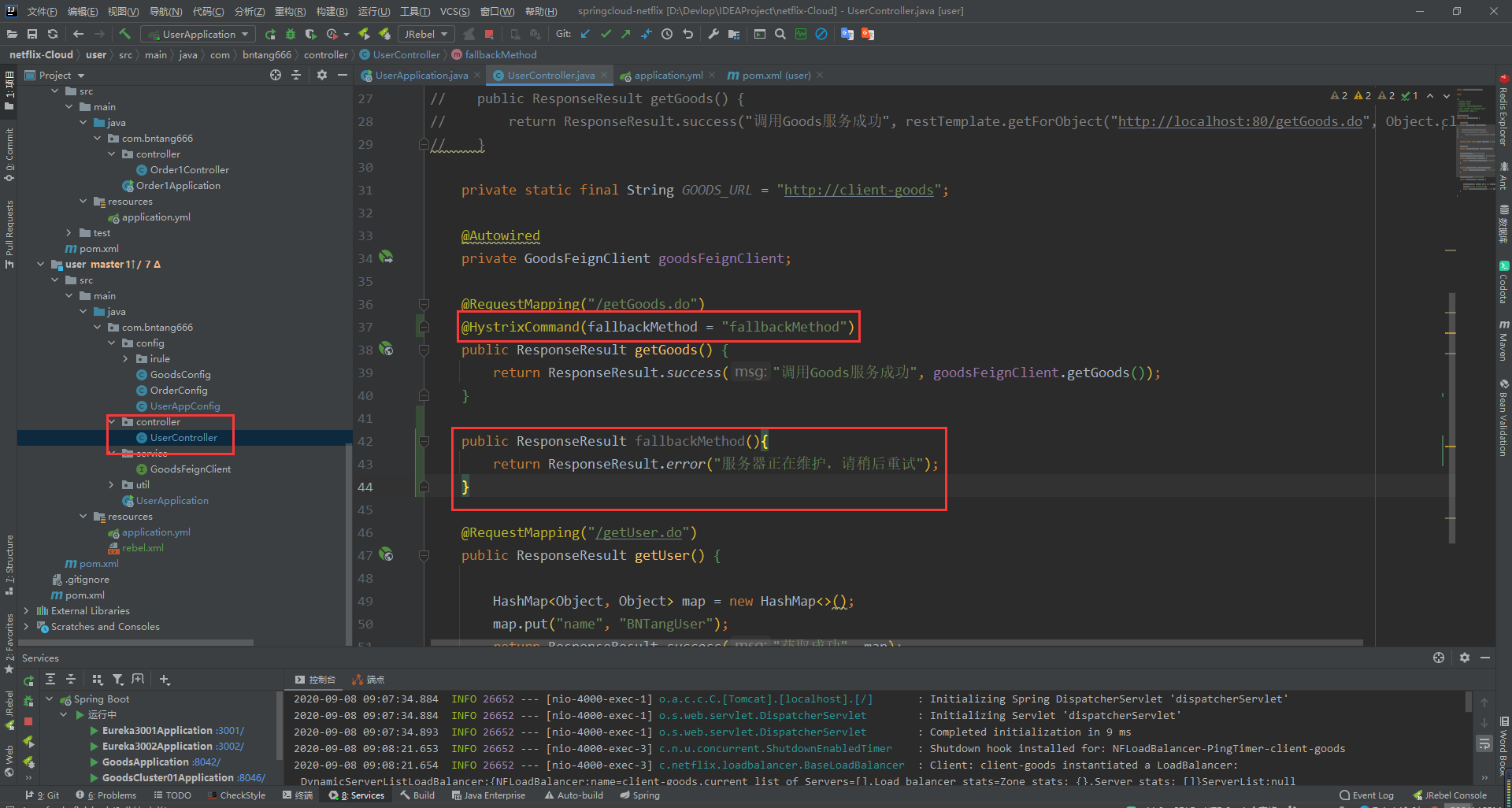
- 在控制器调用方法上添加
@HystrixCommand注解
- 在 goods-cluster-01 服务当中模拟一个异常
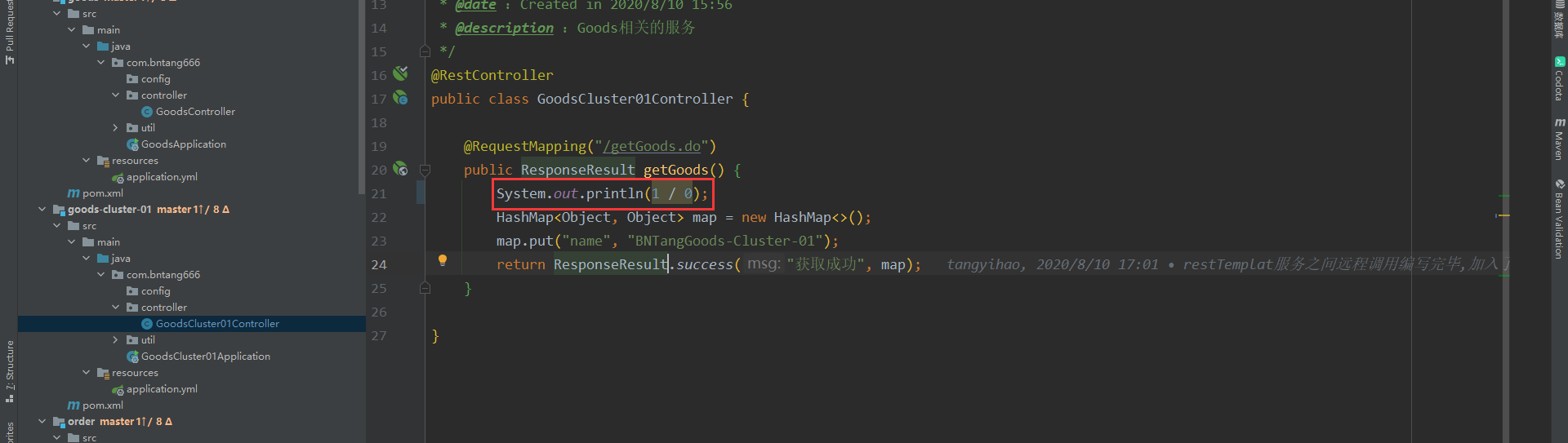
@RequestMapping("/getGoods.do")
public ResponseResult getGoods() {
System.out.println(1 / 0);
HashMap<Object, Object> map = new HashMap<>();
map.put("name", "BNTangGoods-Cluster-01");
return ResponseResult.success("获取成功", map);
}
超时监听
- 模拟响应过慢
- 修改 goods-cluster-01 模块中的 GoodsCluster01Controller
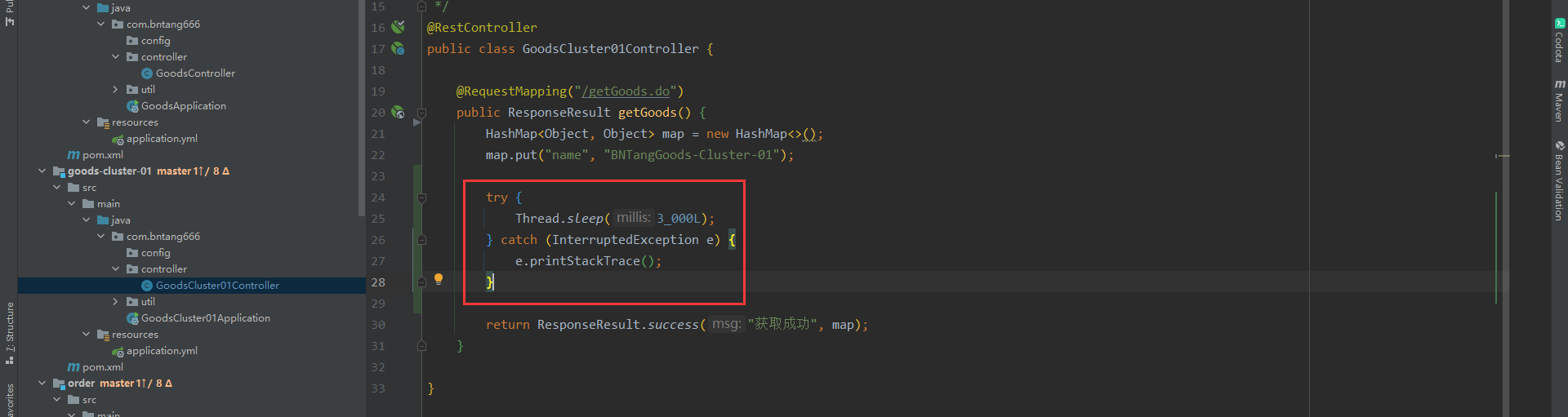
try {
Thread.sleep(3_000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
- 当响应过慢(默认值是1000),超过默认值时会进入到指定的降级方法当中
- 官方文档:https://github.com/Netflix/Hystrix/wiki/Configuration
在客户端配置文件当中配置超时时间
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 3000
RestTemplate调用
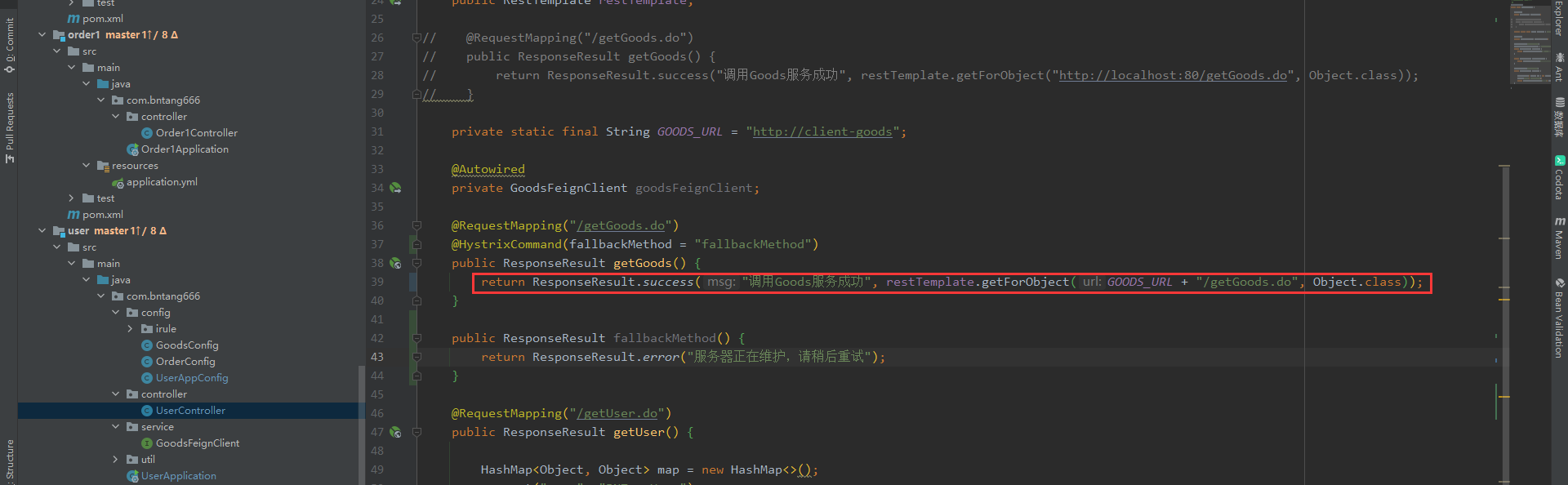
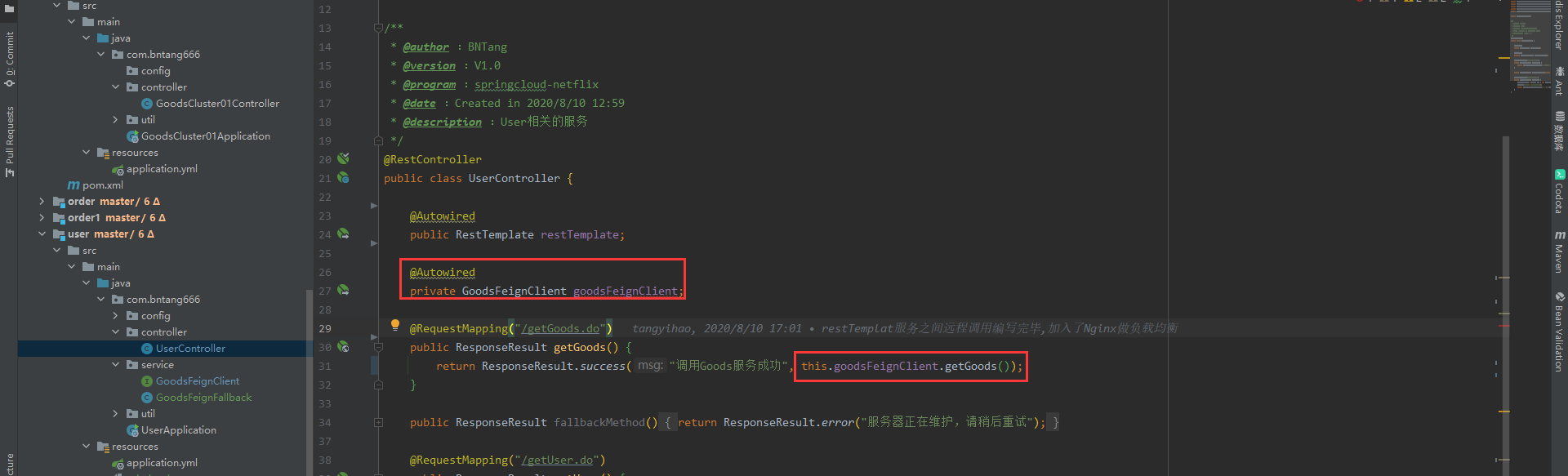
@Autowired
public RestTemplate restTemplate;
private static final String GOODS_URL = "http://client-goods";
@RequestMapping("/getGoods.do")
@HystrixCommand(fallbackMethod = "fallbackMethod")
public ResponseResult getGoods() {
return ResponseResult.success("调用Goods服务成功", restTemplate.getForObject(GOODS_URL + "/getGoods.do", Object.class));
}
public ResponseResult fallbackMethod() {
return ResponseResult.error("服务器正在维护,请稍后重试");
}
Fengin调用
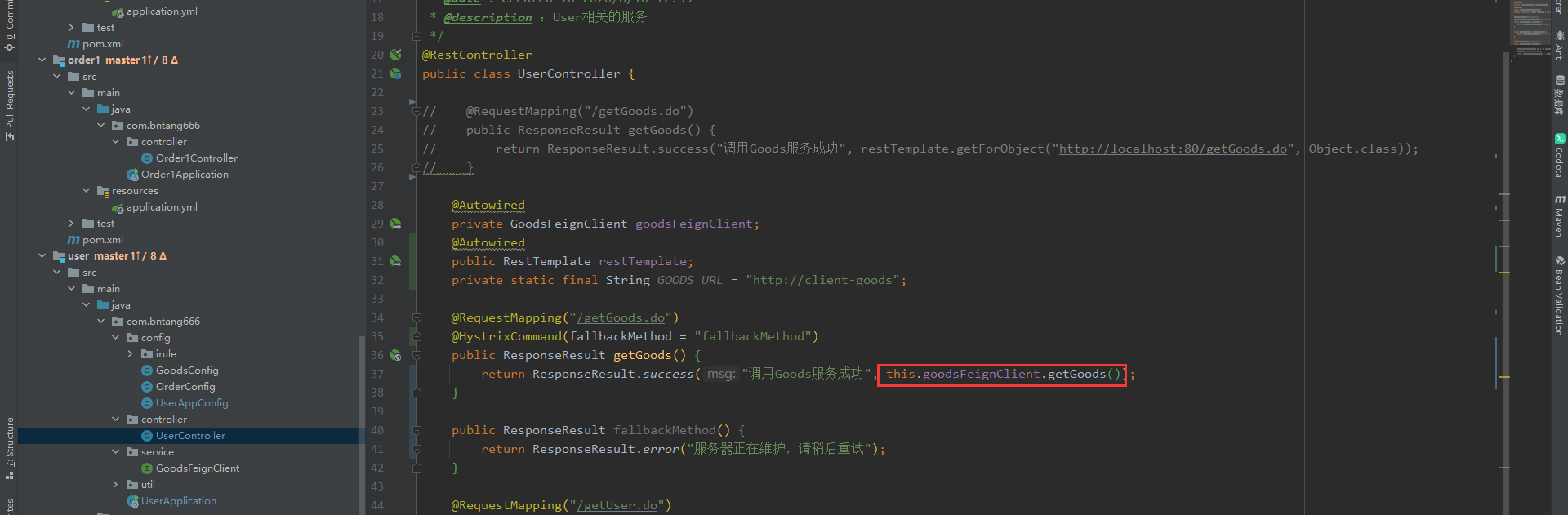
@Autowired
private GoodsFeignClient goodsFeignClient;
@RequestMapping("/getGoods.do")
@HystrixCommand(fallbackMethod = "fallbackMethod")
public ResponseResult getGoods() {
return ResponseResult.success("调用Goods服务成功", this.goodsFeignClient.getGoods());
}
public ResponseResult fallbackMethod() {
return ResponseResult.error("服务器正在维护,请稍后重试");
}
- 使用Fegin调用时,发现没有效果
- Feign默认也有对 Hystix 的集成,默认情况下是关闭的。我们需要通过下面的参数来开启
feign:
hystrix:
# 开启Feign的熔断功能
enabled: true
熔断
- 也叫断路器,CirleBreak
- 熔断,就像我们生活中的跳闸一样, 比如说你的电路出故障了,为了防止出现大型事故,直接切断了你的电源以免意外继续发生
- 当一个微服务调用多次出现问题时(默认是10秒内20次,当然这个也能配置)hystrix就会采取熔断机制
- 不再继续调用你的方法,而是直接调用降级方法,这样就一定程度上避免了服务雪崩的问题
- 会在默认 5 秒钟内和电器短路一样,5 秒钟后会试探性的先关闭熔断机制,但是如果这时候再失败一次(之前是20次)那么又会重新进行熔断
- 线程隔离降级处理,如果请求延迟过高,如果超时,返回一个异常信息
- 假设超时 2 秒,但是用户也要等 3 秒才会返回异常信息
- 正常情况下,一个请求只需要 30ms 就够了,因为超时,导致要多等 2 秒多并发能力急剧下降
- 如果每次来都超时,就认为这个服务可能存在问题,就可以认为电路中负载最高的电压
- 此时,就把此服务断开,再去访问时,就不需要等待 3 秒,直接返回异常信息,把失败的时长急剧缩短保证其它服务的高可用,这个服务就被临时断掉
- 断开很容易,解决如何断开后,再去给它连接回来,Hystrix 就可以去解决这种问题
熔断配置
修改客户端 yaml 配置文件的配置
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 3000
circuitBreaker:
# 10 秒访问5次都失败的话,会断开服务,不调用方法,直接进入fallback方法
requestVolumeThreshold: 5
# 默认是 5 秒,5秒后尝试再访问一次服务器
sleepWindowInMilliseconds: 5000
- 启动 goods 一台,负载均衡换成随机
@Bean
public IRule iRule() {
return new RandomRule();
}
- goods-cluster-01 模拟异常

user 调用

测试方式
- 调用 5 次后,就不再在调用 goods 方法了,会进入到熔断方法中,过一段时间后调用
- 默认 5 秒钟后会试探性的先关闭熔断机制,但是如果这时候再失败一次(之前是20次)那么又会重新进行熔断
熔断状态机
🐸Closed:关闭状态
- 断路器关闭,所有请求都正常访问
🦄Open:打开状态
- 断路器打开,所有请求都会被降级
- Hystix 会对请求情况计数
- 当一定时间内失败请求百分比达到阀值
- 则触发熔断,断路器会完全关闭,默认失败比例阀值是50%,请求次数最少不低于20次
🐤HalfOpen:半开状态
- Closed 状态不是永久的,关闭后进入休眠,时间(默认是5s)
- 随后断路器会进入半开状态
- 此时会释放部分请求通过,若这些请求都是健康的,则完成打开断路器,否则继续保持关闭
- 再次进行休眠倒计时
限流
- 限流,顾名思义,就是限制你某个微服务的使用量(可用线程)
- hystrix 通过线程池的方式来管理你的微服务调用,他默认是一个线程池(10 大小)管理你的所有微服务
- 一个线程可以理解为一个请求,当 10个请求同时访问,都没有得到响应的时候,就会自动调用 fallback 方法
🐸实现默认什么都不设置,更改超时时间

在 goods-cluster-01 工程当中,设置睡眠时间为10秒
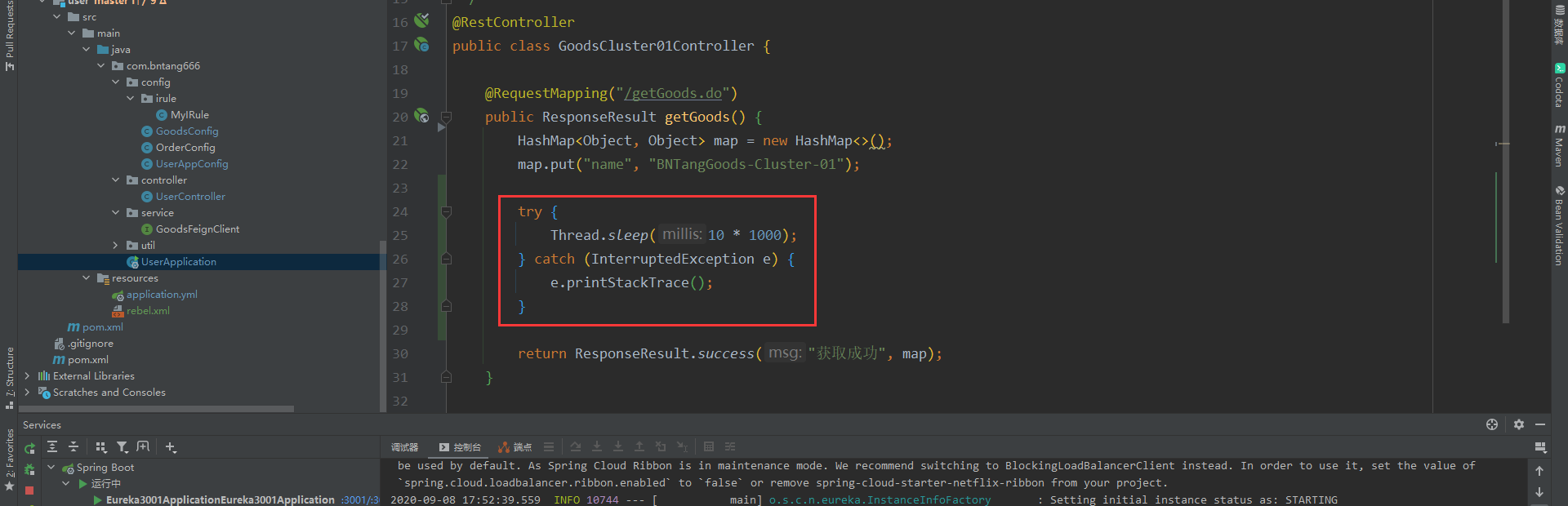
启动后,连续访问,当访问请求次数超过 10次的时候,会调用 fallback 方法,自行在浏览器中一直请求即可
🐤自己手动进行配置
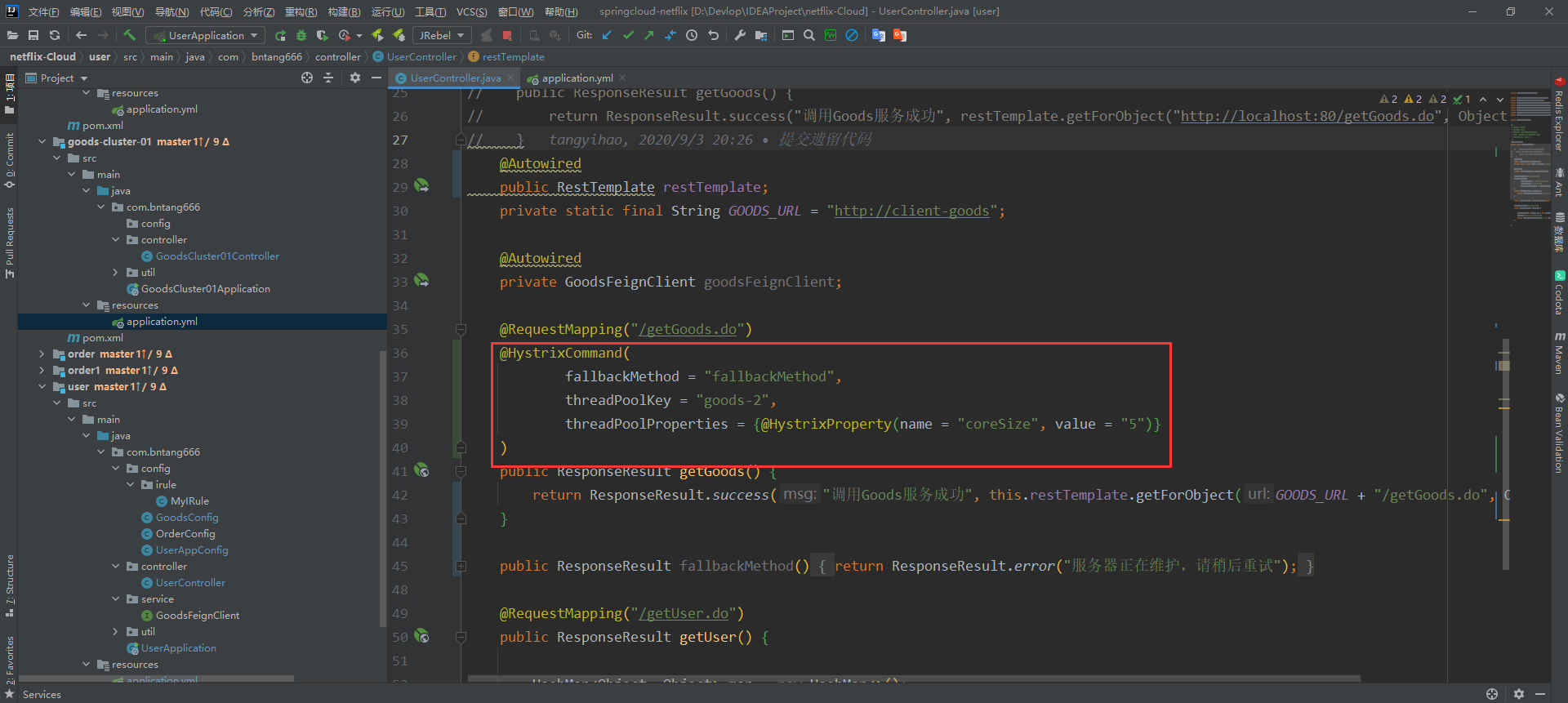
@HystrixCommand(
fallbackMethod = "fallbackMethod",
threadPoolKey = "goods-2",
threadPoolProperties = {@HystrixProperty(name = "coreSize", value = "5")}
)
Feign整合Hystrix
- Feign 默认是支持 Hystrix的,但是在Spring Cloud Dalston 版本之后就默认关闭了,因为不一定业务需求要用的到
开启Feign 对 Hystrix 的支持,修改客户端的 application.yml
feign:
hystrix:
# 开启 Feign当中的 Hystrix
enabled: true
- 方式1 → fallback
- 创建一个类实现服务FeignClient接口
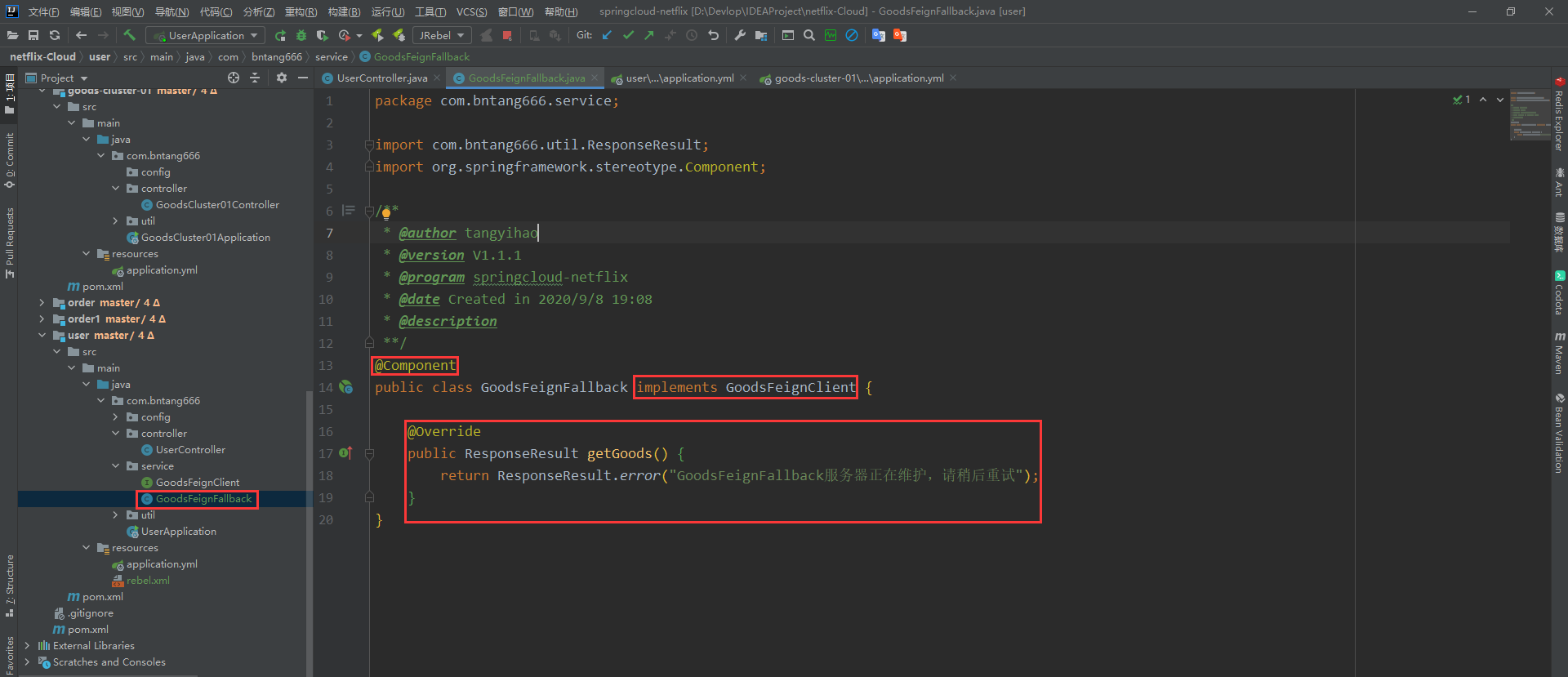
@Component
public class GoodsFeignFallback implements GoodsFeignClient {
@Override
public ResponseResult getGoods() {
return ResponseResult.error("GoodsFeignFallback服务器正在维护,请稍后重试");
}
}
- 在服务FeignClient接口上配置实现类
@FeignClient(name = "client-goods", fallback = GoodsFeignFallback.class)
public interface GoodsFeignClient {
@RequestMapping("/getGoods.do")
ResponseResult getGoods();
}
- 在控制器当中调用
- 方式2 → fallbackFactory
- 创建一个类实现 FallbackFactory
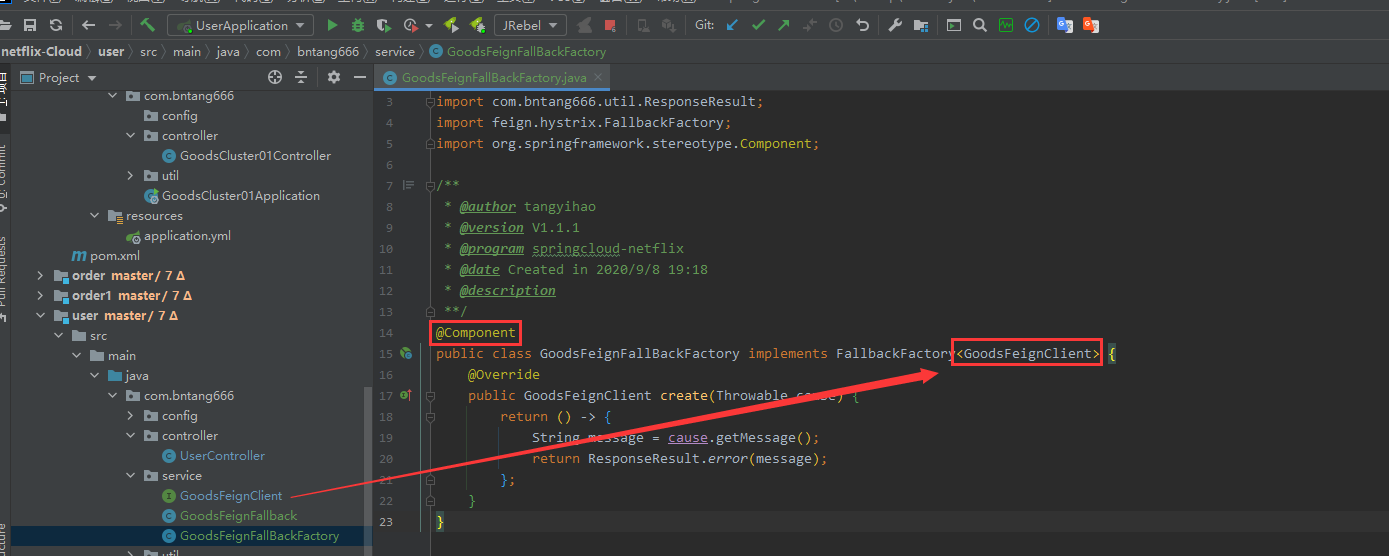
@Component
public class GoodsFeignFallBackFactory implements FallbackFactory<GoodsFeignClient> {
@Override
public GoodsFeignClient create(Throwable cause) {
return () -> {
String message = cause.getMessage();
return ResponseResult.error(message);
};
}
}
- 在服务 FeignClient 接口上配置实现类
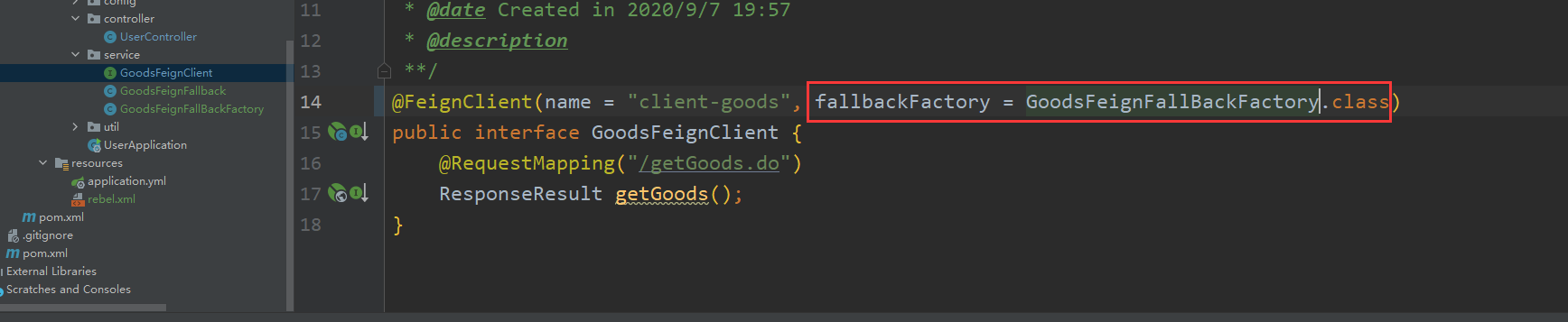
@FeignClient(name = "client-goods", fallbackFactory = GoodsFeignFallBackFactory.class)
public interface GoodsFeignClient {
@RequestMapping("/getGoods.do")
ResponseResult getGoods();
}
- 在控制器当中调用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号