
Eureka注册中心
Eureka注册中心
- eureka是Netflix的子模块之一,也是一个核心的模块
- eureka里有2个组件
- 一个是EurekaServer(一个独立的项目) 这个是用于定位服务以实现中间层服务器的负载平衡和故障转移
- 一个便是EurekaClient(我们的微服务)它是用于与Server交互的,可以使得交互变得非常简单,只需要通过服务标识符即可拿到服务
- Eureka负责管理、记录服务提供者的信息
- 服务调用者无需自己寻找服务,而是把自己的需求告诉Eureka,然后Eureka会把符合你需求的服务告诉你
- 类似家政中心,物业
🐤与SpringCloud的关系
- SpringCloud封装了Netflix公司开发的Eureka模块来实现服务注册和发现
Eureka原理
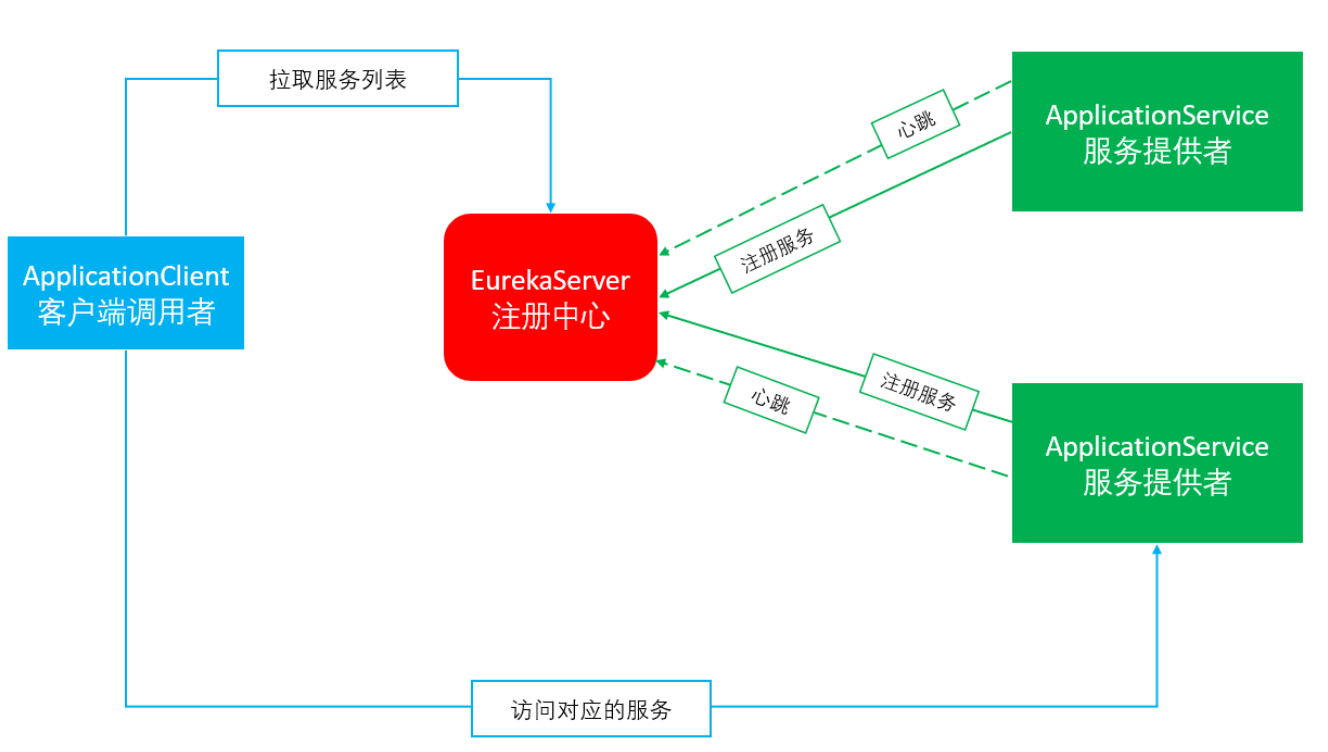
- Eureka:就是服务注册中心(可以是一个集群),对外暴露自己的地址
- 提供者:启动后向Eureka注册自己信息(地址,提供什么服务)
- 消费者:向Eureka订阅服务,Eureka会将对应服务的所有提供者地址列表发送给消费者,并且定期更新
- 心跳(续约):提供者定期通过http方式向Eureka刷新自己的状态,会监听有没有定期更新,如果长时间没有心跳,就会自动把该服务移除
Eureka使用
- 在之前工程中添加一个子模块名称为Eureka
- 在该工程下的pom中添加
eureka依赖,首先在父工程当中定义Cloud版本号,注意一下Cloud的版本号中间不是空格是以.来选择版本
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>
- 在resources当中创建配置文件
application.yml
server:
port: 3000
eureka:
server:
# 关闭自我保护机制
enable-self-preservation: false
# 设置清理间隔(单位:毫秒 默认是60*1000)
eviction-interval-timer-in-ms: 4000
instance:
hostname: localhost
- 创建启动类,并在启动器上添加
@EnableEurekaServer注解
@SpringBootApplication
@EnableEurekaServer
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EnableEurekaServer.class, args);
}
}
- 直接启动
- 启动时如果报
com.sun.jersey.api.client.ClientHandlerException - 可直接在浏览器当中输入地址访问
http://localhost:3000/
🐤原因
- Eureka做为注册中心,做为服务的管理,它不能挂掉,如果它挂掉,整个服务全部访问不了
- 因此Eureka也要搭建集群多台Eureka服务,集群之间要进行相互之间通信,通信靠的就是Eureka-client
- Eureka是一个服务端,也是一个客户端,以后相互注册,现在没有其它的可注册,所以就会报ClientException
- 也就是目前只有一个Eureka他要把自己当作成一个客户端进行注册,在这里这个Eureka是一个服务的提供者的身份
🦄解决
- 想要让它不报错,就不让它注册到自己身上
client:
# 不把自己作为一个客户端注册到自己身上
registerWithEureka: false
# 不需要从服务端获取注册信息(因为在这里自己就是服务端,而且已经禁用自己注册了)
fetchRegistry: false
# 微服务要注册到的地址
serviceUrl:
# http://localhost:3000/eureka
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka
- 运行,在浏览器地址栏直接访问
http://localhost:3000/
服务注册
🐤注册user
- 在user工程中添加eureka客户端相关依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
- 在启动器上添加注解
@EnableEurekaClient - 创建
application.yml配置文件,配置eureka的服务端地址
eureka:
client:
serviceUrl:
# eureka服务端提供的注册地址 参考服务端配置的这个路径
defaultZone: http://localhost:3000/eureka
instance:
# 此实例注册到eureka服务端的唯一的实例ID
instance-id: user-1
# 是否显示IP地址
prefer-ip-address: true
# eureka客户需要多长时间发送心跳给eureka服务器,表明它仍然活着,默认为30 秒 (与下面配置的单位都是秒)
leaseRenewalIntervalInSeconds: 10
# Eureka服务器在接收到实例的最后一次发出的心跳后,需要等待多久才可以将此实例删除,默认为90秒
leaseExpirationDurationInSeconds: 30
spring:
application:
# 此实例注册到eureka服务端的name
name: client-user
🐸注册goods
- 步骤同上,注册到服务中心
常用配置
🐤服务注册
- 服务提供者在启动时,会检测配置属性中的:eureka.client.register-with-erueka=true 参数是否正确
- 事实上默认就是true。如果值确实为true,则会向EurekaServer发起一个Rest请求
🦄获取服务列表
- 当服务消费者启动后,会检测 eureka.client.fetch-registry=true 参数的值
- 如果为true,则会从Eureka Server服务的列表只读备份,然后缓存在本地。并且每隔30秒会重新获取并更新数据
- eureka.client.registry-fetch-interval-seconds: 5 生产环境中,我们不需要修改这个值
🐪服务续约
- 在注册服务完成以后,服务提供者会维持一个心跳
eureka:
instance:
# 服务续约(renew)的间隔,默认为30秒
lease-expiration-duration-in-seconds: 90
# 服务失效时间,默认值90秒
lease-renewal-interval-in-seconds: 30
- 也就是说,默认情况下每隔30秒服务会向注册中心发送一次心跳,证明自己还活着。如果超过90秒没有发送心跳
- EurekaServer就会认为该服务宕机,会从服务列表中移除,这两个值在生产环境不要修改,默认即可
🐱🐉失效剔除
- 有些时候,我们的服务提供方并不一定会正常下线,可能因为内存溢出、网络故障等原因导致服务无法正常工作
- Eureka Server需要将这样的服务剔除出服务列表。因此它会开启一个定时任务,每隔60秒对所有失效的服务(超过90秒未响应)进行剔除
- 可以通过 eureka.server.eviction-interval-timer-in-ms 参数 对其进行修改,单位是毫秒
🎁自我保护机制
- 当把一个服务停掉后,并不会立马从服务列表当中移除,默认是90秒清除一次
- 有可以注册中心和微服务之间出现了网络波动,网络不好,没有收到心跳,有可能是网络不好,但是微服务还在,所以它不会立马把服务给移除
- 当15分钟内85%的心跳都没有正常心跳,那么eureka认为客户端与注册中心出现了网络问题,此时会出现以下情况
- 1.Eureka不再从注册列表中移除因为长时间没有收到的心跳而过期的服务
- 2.Eureka仍然能够接收服务的注册和查询请求,但是不会被同步到其它节点上
- 3.当网络稳定后,当前实例新注册的信息会被同步到其它节点上
CAP定理
🐤什么是CAP定理
- CAP定理又称CAP原则
- 指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)
- 最多只能同时满足三个特性中的两个,三者不可兼得
🐐Consistency(一致性)
- “all nodes see the same data at the same time”
- 即更新操作成功并返回客户端后,所有节点在同一时间的数据完全一致,这就是分布式的一致性
🐏Availability(可用性)
- 可用性指
Reads and writes always succeed - 即服务一直可用,而且是正常响应时间
- 好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况
🐕Partition tolerance(分区容错性)
- 大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区
- 分区容错的意思是,区间通信可能失败。比如,一台服务器放在本地,另一台服务器放在外地(可能是外省,甚至是外国),这就是两个区,它们之间可能无法通信
- 两台跨区的服务器。Server1 向 Server2 发送一条消息,Server2 可能无法收到。系统设计的时候,必须考虑到这种情况
- 一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立
- 即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务
- 分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体
🐬Consistency 和 Availability 的矛盾
- 如果保证 Server2 的一致性,那么 Server1 必须在写操作时,锁定 Server2 的读操作和写操作。只有数据同步后,才能重新开放读写。锁定期间,Server2 不能读写,没有可用性
- 如果保证 Server2 的可用性,那么势必不能锁定 Server2,所以一致性不成立
取舍策略
CAP三个特性只能满足其中两个,那么取舍的策略就共有三种
- CA without P
- 如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的
- 但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点
- 这是违背分布式系统设计的初衷的
- CP without A
- 如果不要求A(可用),相当于每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长
- (也就是等待数据同步完才能正常访问服务)
- 一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统
- AP wihtout C
- 要高可用并允许分区,则需放弃一致性
- 一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务
- 而这样会导致全局数据的不一致性
- 抢购商品时,可能前几秒你浏览商品的时候页面提示是有库存的,当你选择完商品准备下单的时候,系统提示你下单失败,商品已售完。这其实就是先在 A(可用性)方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,虽然多少会影响一些用户体验,但也不至于造成用户购物流程的严重阻塞
没有最好的策略,好的系统应该是根据业务场景来进行架构设计的,只有适合的才是最好的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号