

日志分析中的 awk、sort、uniq 和 grep 应用
awk简介
awk是一种强大的文本处理工具,其功能与sed和grep相似,但更加灵活。它使用类似C语言的语法,并且适用于处理结构化文本数据,如表格数据。awk是一种模式扫描和处理语言,可以轻松提取、操作和格式化文本数据,特别是适用于处理日志文件中的结构化信息。
sort简介
sort用于对文本数据进行排序。它可以对文件内容进行排序,也可以从标准输入中读取数据并对其排序,然后将结果输出到标准输出或指定的文件中。
uniq简介
uniq命令用于删除文件中的重复行,经常与sort命令一起使用,因为uniq要求重复的行一定相邻。所以在使用uniq命令之前,请使用sort命令使所有重复行相邻。
grep简介
grep是一个强大的文本搜索工具,它的主要功能是进行字符串数据的比较,并将符合条件的行打印出来。grep在数据中查找一个字符串的时候,是以整行为单位进行筛选的。
日志分析中的应用
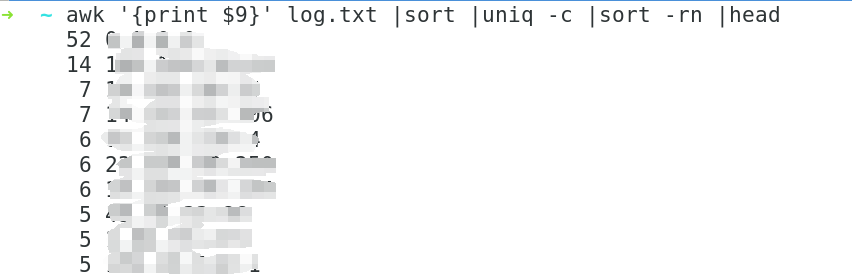
1、查找请求次数最多的IP前十
awk '{print $9}' log.txt |sort |uniq -c |sort -rn |head
#打印文件的IP字段,排序、去重、倒序、列出前十行
sort 对输入进行排序。 默认情况下,它会按照字典顺序对文本进行排序
sort -r 倒序,用于反向排序
-n 按照数字排序
uniq 用于从已排序的文本中删除重复的行
-c 用于计数每个行重复出现的次数
head 用于从排序的结果中选取头部行,默认为10
2、查找访问成功状态码为200的IP
awk '$17=="200"{print $9}' log.txt |sort |uniq -c |sort -rn

3、查找访问成功状态码为200的总次数
awk '$17==200' log.txt |wc -l
wc -l 用于统计文件中的行数

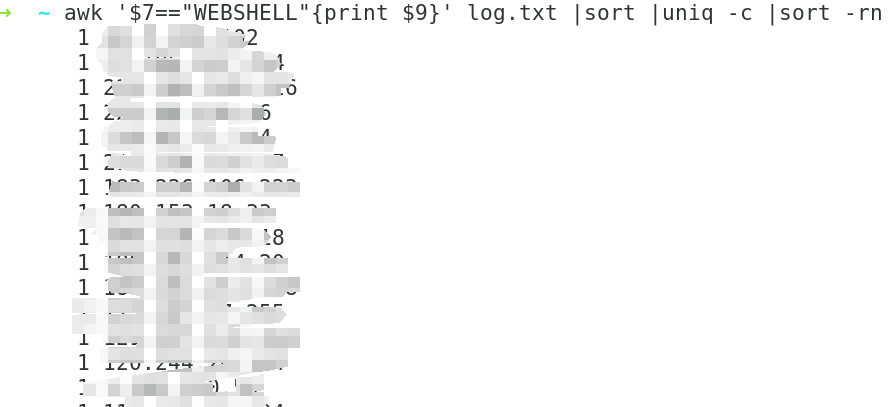
4、查找攻击类型为WEBSHELL的IP
awk '$7=="WEBSHELL"{print $9}' log.txt |sort |uniq -c |sort -rn
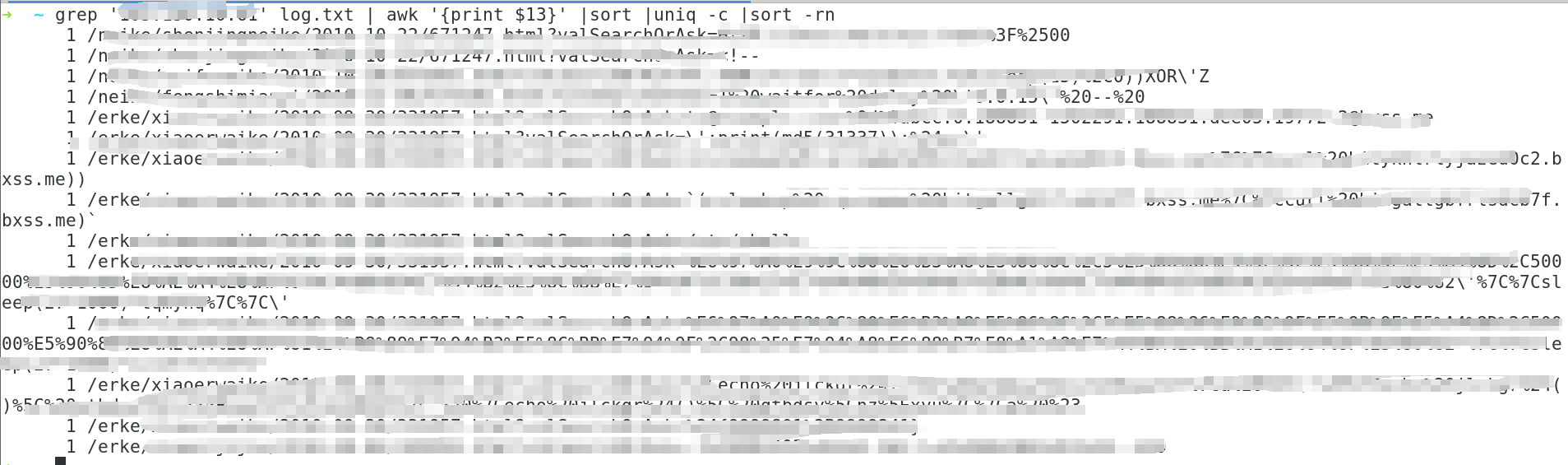
5、查找某个IP访问过的URL
grep 'xxx.xx.xx.xx' log.txt | awk '{print $13}' |sort |uniq -c |sort -rn
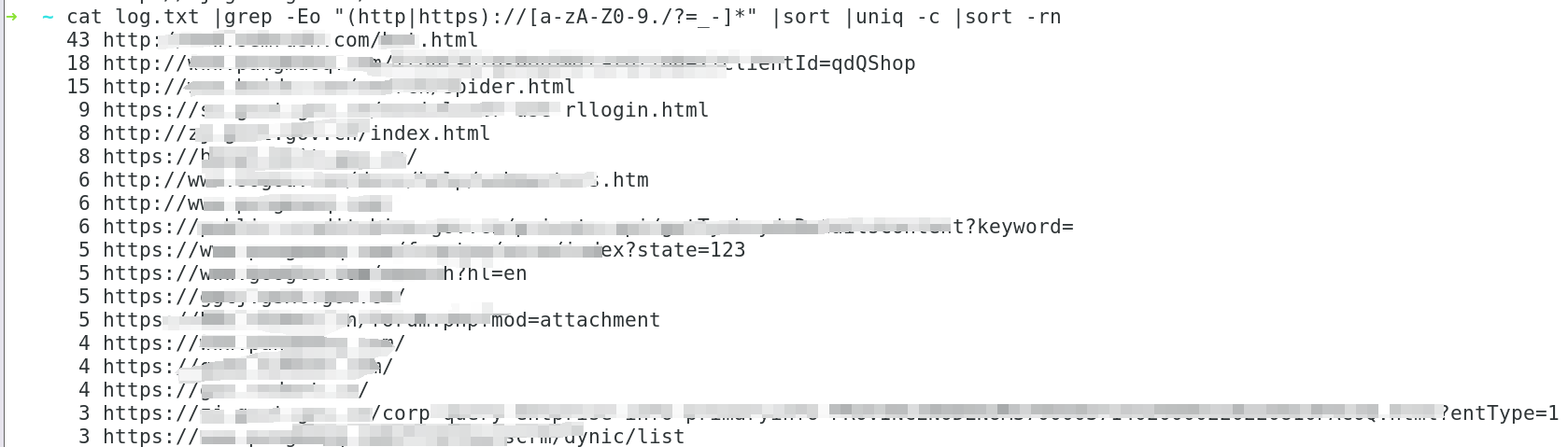
6、提取文件中所有出现过的URL
cat log.txt |grep -Eo "(http|https)://[a-zA-Z0-9./?=_-]*" |sort |uniq -c |sort -rn
-E 使用扩展正则表达式(Extended Regular Expression)进行匹配
-o 仅输出匹配到的文本,而不是整行
7、查找某一IP有关的所有URL
awk '$9=="xxx.xx.xx.xx"' log.txt |grep -Eo "(http|https)://[a-zA-Z0-9./?=_-]*" |sort |uniq -c |sort -rn

8、查找访问过某个URL的IP
grep "/etc/shells" log.txt |awk '{print $9,$13}'


