
写完原型大概只花了不到1天的时间,之后就一直在卡常,接下来说说我卡常的心路历程。
先说说生成数独的部分,这部分主要的时间开销不是生成棋盘的部分,而是输出棋盘的部分,刚开始用printf输出的,但是printf中要做没必要的正则匹配,很浪费时间,输出1e6个棋盘我本机大概需要400s,后来改成了putc输出,只用了5s。
再说说解数独的部分,这部分卡常是最艰难的。最开始的实现跑1e6组数独大概需要20min,这个效率显然是无法接受的。后来我发现在读入数独后构造DLX时可以预处理每一步的状态,改进之后跑1e6组数独只花了80s,可以说时很大的提升。用VS的性能测试跑了一下,发现大部分的时间开销都在DLX的递归回溯过程,还有一小半时间花在构造DLX的过程上,但是结合理论和时间改了改发现这两部分已经没办法再改了,于是就开始加入多线程。开始的时候加入了输入和输出的多线程,但是刚加入这两部分的时候运行时间并没有明显的改变,因为数据传输和输入输出的效率差别不是很大。最后想了想如何多开几个线程来算数独。多线程这部分请教了一下实验室某大佬Lancern,在他的帮助下,完成了多线程的同步,最后解1e6组数独大概只需要30s的时间。
下面给出一个VS的性能分析
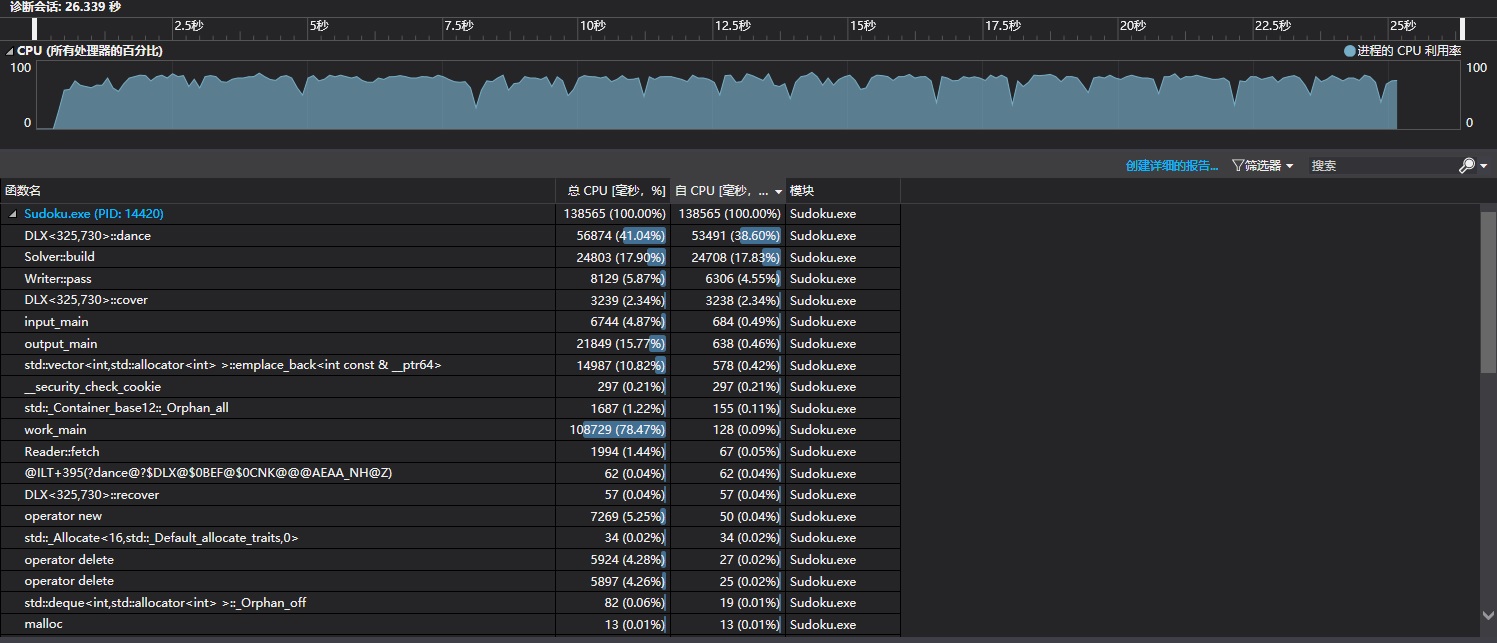
可以看出,整个程序耗时最多的部分还是DLX的递归回溯过程,其次就是构造部分,我觉得毕竟算法复杂度在那摆着呢,也没办法再有什么很大的提升了。
欢迎各位dalao批评指点。

