【BIGDATA】将普通文本文件导入ElasticSearch
以《刑法》文本.txt为例。
一、格式化数据
1,首先,ElasticSearch只能接收格式化的数据,所以,我们需要将文本文件转换为格式化的数据---json。
下图为未处理的文本文件。

2,这里,使用python文件操作,将文本格式化为ElasticSearch可识别的json格式。
#python 3.6 #!/usr/bin/env python # -*- coding:utf-8 -*- __author__ = 'BH8ANK' ''' 最终将输出格式改为 {"index":{"_index":"xingfa","_id":1}} {"text_entry":"犯罪的行为或者结果有一项发生在中华人民共和国领域内的,就认为是在中华人民共和国领域内犯罪。"} ''' '''读取文件 ''' a = open(r"D:\xingfa.txt", "r",encoding='utf-8') out = a.read() #print(out) TypeList = out.split('\n') #print(TypeList) lenth = len(TypeList) print(lenth) number = 1 ju_1 = '{"index":{"_index":"xingfa","_id":' ju_2 = '{"text_entry":"' # print(ju_1) for x in TypeList: res_1 = ju_1 + str(number) + '}}'+'\n' print(res_1) a = open(r"D:\out.json", "a", encoding='UTF-8') a.write(res_1) res_2 = ju_2 + x + '"}'+'\n' print(res_2) a = open(r"D:\out.json", "a", encoding='UTF-8') a.write(res_2) a.close() number+=1
3,执行后,输出的json内容为:
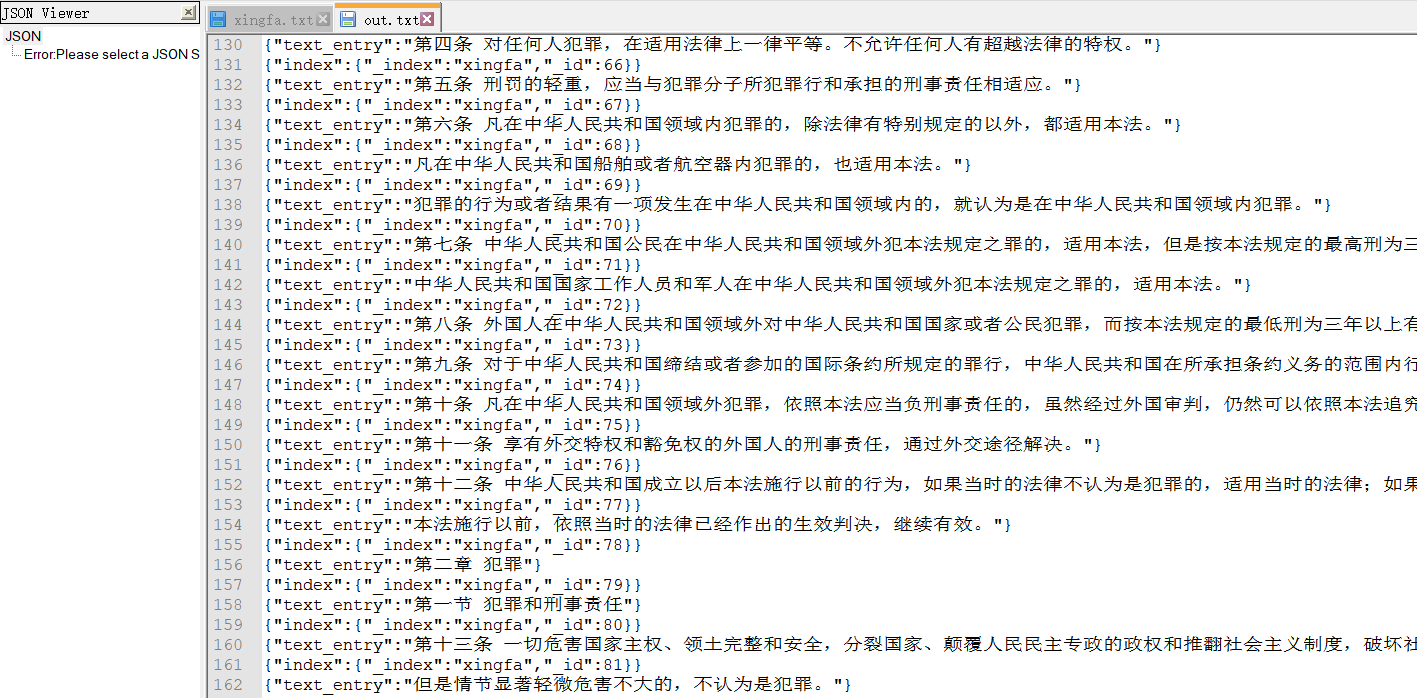
二、将数据导入ElasticSearch
1,我们要为即将导入的数据,建立映射。此操作可以在kibana或命令行完成。
PUT /xingfa
{
"mappings": {
"doc": {
"properties": {
"text_entry":{"type":"keyword"}
}
}
}
}
2,登录虚拟机,将之前生成的out.json文件,导入到对应ElasticSearch集群中。
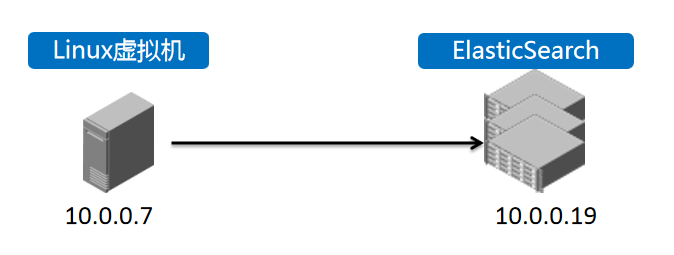
我们的ES组网情况如上图。
操作如下:
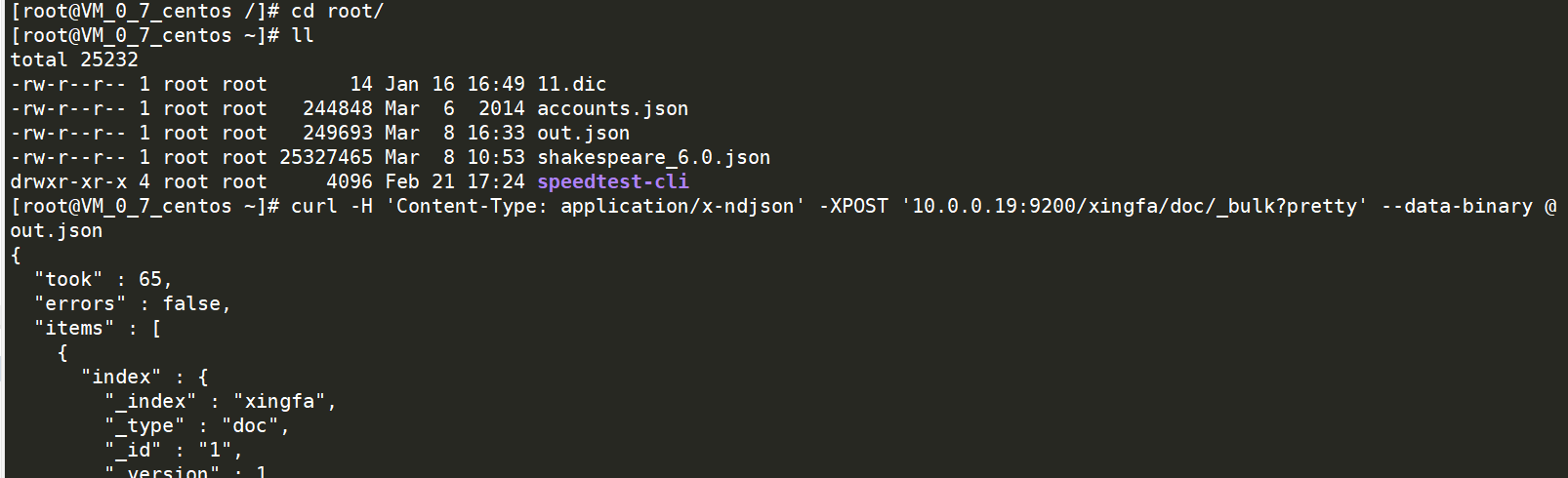
命令如下:
curl -H 'Content-Type: application/x-ndjson' -XPOST '10.0.0.19:9200/xingfa/doc/_bulk?pretty' --data-binary @out.json
等待命令执行完成后,即可登录kibana去查询对应的数据了。
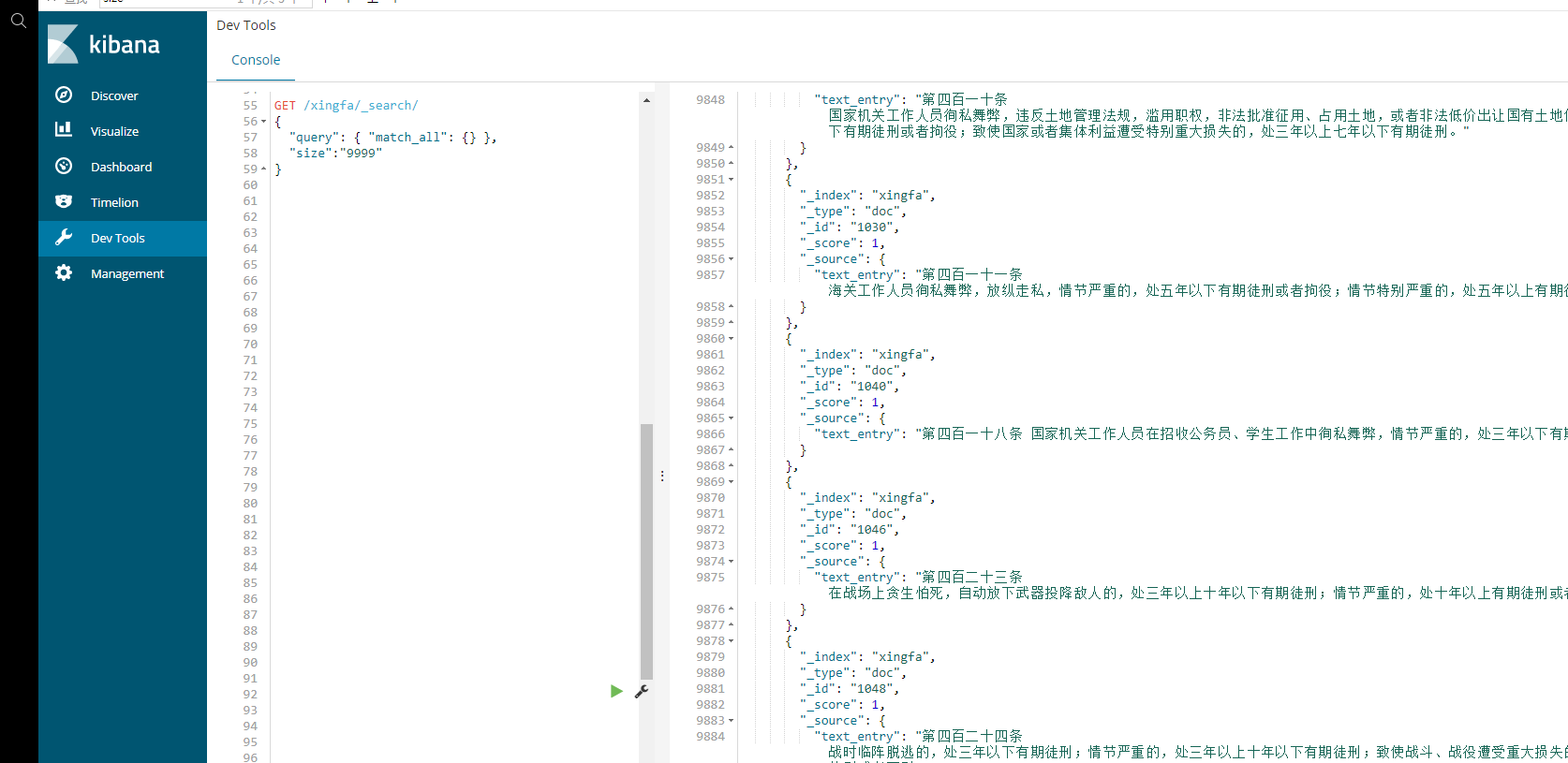
使用查询语句:
GET /xingfa/_search/
{
"query": { "match_all": {} },
"size":"9999" //此处设置为9999,主要原因是,不加参数的话,默认搜索结果仅显示部分,一般是5.
}
也可以直接在虚拟机命令行里,查询这个索引,确认数据是否已经完成上传。
使用查询语句:
curl -XGET "http://10.0.0.19:9200/xingfa/_search/" -H 'Content-Type: application/json' -d'
{
"query": {
"match_all": {}
},
"size": "9999"
}'
至此,完成数据导入。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号