主函数(train.py)
from sampling import noniid
from Nets import MLP
from params import args_parser
from update import LocalUpdate
from aggregation import FedAvg
from test import img_test
import pdb
import torch
from torchvision import transforms,datasets
import numpy as np
import copy
import matplotlib.pyplot as plt
#引入超参数
args = args_parser()
args.device = torch.device("cuda:{}".format(args.gpu) if torch.cuda.is_available() and args.gpu != -1 else 'cpu')
#处理数据集
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST('../data/mnist',train = True,download=True,transform = trans)
test_dataset = datasets.MNIST('../data/mnist',train = False,download = True,transform = trans)
#数据集分割
user_dict = noniid(train_dataset,100)
img_size = train_dataset[0][0].shape
#设置网络结构
len_in = 1
for x in img_size:
len_in*=x
glob_net = MLP(dim_in = len_in,dim_hidden = 20,dim_out = args.num_classes).to(args.device)
print(glob_net)
glob_net.train()
glob_w = glob_net.state_dict() #全局模型参数
# pdb.set_trace()
#训练
train_loss = []#训练损失
if args.all_clients:
print('所有客户均参与训练')
local_w = [glob_w for i in range(args.num_users)]
for iter in range(args.epochs):
local_loss = []
if not args.all_clients:
local_w = []
m = max( int(args.num_users * args.frac) , 1 )
#随机选择m个客户参与训练
idx_users = np.random.choice(range(args.num_users),m,replace = False)
#每轮中在每个客户端上进行单独训练
for idx in idx_users:
local = LocalUpdate(args = args,dataset = train_dataset,idxs = user_dict[idx])
#传入超参数、训练集、该client的样本集合
w, loss = local.train(net=copy.deepcopy(glob_net).to(args.device))
if args.all_clients:
local_w[idx] = copy.deepcopy(w)
else:
local_w.append(copy.deepcopy(w))
local_loss.append(copy.deepcopy(loss))
# if args.method == 'fedavg':
#联邦平均,更新全局模型参数
glob_w = FedAvg(local_w,local_loss)
glob_net.load_state_dict(glob_w)
#计算平均损失并打印
avg_loss = sum(local_loss)/len(local_loss)
print('第',iter,'轮客户端平均损失:',avg_loss)
train_loss.append(avg_loss)
plt.figure()
plt.plot(range(len(train_loss)),train_loss)
plt.ylabel('avg_loss')
plt.xlabel('iterations')
plt.show()
glob_net.eval()
train_acc,train_los = img_test(glob_net,train_dataset,args)
test_acc,test_los = img_test(glob_net,test_dataset,args)
print('训练集准确度:',train_acc)
print('训练集损失:',train_los)
print('测试集准确度:',test_acc)
print('测试集准确度:',test_los)
print("Training accuracy: {:.2f}".format(train_acc))
print("Testing accuracy: {:.2f}".format(test_acc))
pdb.set_trace()
非独立同分布模拟(sampling.py)
import numpy as np
def noniid(dataset,user_num):
a,b = 200,300
list_a = [i for i in range(a)]
dict_user = {i:np.array([],dtype = 'int64') for i in range(user_num)}
idx = [i for i in range(a*b)]
label = dataset.train_labels.numpy()
tmp = np.vstack((idx,label))
tmp = tmp[:,tmp[1,:].argsort()]
idx = tmp[0,:]
for i in range(user_num):
randset = set(np.random.choice(list_a,2,replace = False))
list_a = list(set(list_a)-randset)
for rand in randset:
dict_user[i] = np.concatenate((dict_user[i],idx[rand*b:(rand+1)*b]),axis = 0)
return dict_user
网络定义(Nets.py)
import torch.nn as nn
import torch.nn.functional as F
class MLP(nn.Module):
def __init__(self,dim_in,dim_hidden,dim_out):
super(MLP,self).__init__()
self.input = nn.Linear(dim_in,dim_hidden)
self.relu = nn.ReLU()
self.dropout = nn.Dropout()
self.output = nn.Linear(dim_hidden,dim_out)
def forward(self,x):
x = x.view(-1, x.shape[1]*x.shape[-2]*x.shape[-1])
return self.output(self.relu(self.dropout(self.input(x))))
参数定义(params.py)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Python version: 3.6
import argparse
def args_parser():
parser = argparse.ArgumentParser()
# federated arguments
parser.add_argument('--epochs', type=int, default=3, help="rounds of training")
parser.add_argument('--num_users', type=int, default=100, help="number of users: K")
parser.add_argument('--frac', type=float, default=0.1, help="the fraction of clients: C")
parser.add_argument('--local_ep', type=int, default=5, help="the number of local epochs: E")
parser.add_argument('--local_bs', type=int, default=10, help="local batch size: B")
parser.add_argument('--bs', type=int, default=128, help="test batch size")
parser.add_argument('--lr', type=float, default=0.01, help="learning rate")
parser.add_argument('--momentum', type=float, default=0.5, help="SGD momentum (default: 0.5)")
parser.add_argument('--split', type=str, default='user', help="train-test split type, user or sample")
parser.add_argument('--method',type=str,default='fedavg',help='aggregation methods')
# model arguments
parser.add_argument('--model', type=str, default='mlp', help='model name')
parser.add_argument('--kernel_num', type=int, default=9, help='number of each kind of kernel')
parser.add_argument('--kernel_sizes', type=str, default='3,4,5',
help='comma-separated kernel size to use for convolution')
parser.add_argument('--norm', type=str, default='batch_norm', help="batch_norm, layer_norm, or None")
parser.add_argument('--num_filters', type=int, default=32, help="number of filters for conv nets")
parser.add_argument('--max_pool', type=str, default='True',
help="Whether use max pooling rather than strided convolutions")
# other arguments
parser.add_argument('--dataset', type=str, default='mnist', help="name of dataset")
parser.add_argument('--iid', action='store_true', help='whether i.i.d or not')
parser.add_argument('--num_classes', type=int, default=10, help="number of classes")
parser.add_argument('--num_channels', type=int, default=3, help="number of channels of imges")
parser.add_argument('--gpu', type=int, default=0, help="GPU ID, -1 for CPU")
parser.add_argument('--stopping_rounds', type=int, default=10, help='rounds of early stopping')
parser.add_argument('--verbose', action='store_true', help='verbose print')
parser.add_argument('--seed', type=int, default=1, help='random seed (default: 1)')
parser.add_argument('--all_clients', action='store_true', help='aggregation over all clients')
args = parser.parse_args()
return args
客户端训练(update.py)
import torch
from torch.utils.data import Dataset, DataLoader
from torch import nn
class DataSplit(Dataset):
def __init__(self, dataset,idxs):
self.dataset = dataset
self.idxs = list(idxs)
def __len__(self):
return len(self.idxs)
def __getitem__(self,item):
image, label = self.dataset[self.idxs[item]]
return image, label
class LocalUpdate(object):
def __init__(self,args,dataset = None,idxs = None):
self.args = args
self.loss_fun = nn.CrossEntropyLoss()
self.train_batch = DataLoader(DataSplit(dataset,idxs),batch_size=self.args.local_bs,shuffle = True)
def train(self,net):
net.train()
optimizer = torch.optim.SGD(net.parameters(),lr = self.args.lr,momentum=self.args.momentum)
epoch_loss = []
for iter in range(self.args.local_ep):
batch_loss = []
for tmp, (images,labels) in enumerate(self.train_batch):
images, labels = images.to(self.args.device), labels.to(self.args.device)
net.zero_grad()
label_pre = net(images)
loss = self.loss_fun(label_pre,labels)
loss.backward()
optimizer.step()
batch_loss.append(loss.item())
epoch_loss.append(sum(batch_loss)/len(batch_loss))
return net.state_dict(), sum(epoch_loss) / len(epoch_loss)
本地客户端聚合—fedavg(aggregation.py)
import copy
import torch
def FedAvg(w,loss):
avg_w = copy.deepcopy(w[0])
for k in avg_w.keys():
for i in range(1,len(w)):
avg_w[k] += w[i][k]
avg_w[k] = torch.div(avg_w[k],len(w))
return avg_w
准确性测试(test.py)
from torch.utils.data import DataLoader
import torch.nn.functional as F
def img_test(glob_net,dataset,args):
glob_net.eval()
test_loss = 0
correct = 0
dataloader = DataLoader(dataset,batch_size=args.bs)
l = len(dataloader)
for idx,(images,labels) in enumerate(dataloader):
if args.gpu != -1:
images,labels = images.cuda(),labels.cuda()
pre_labels = glob_net(images)
test_loss += F.cross_entropy(pre_labels,labels,reduction='sum').item()
y_pred = pre_labels.data.max(1, keepdim=True)[1]
correct += y_pred.eq(labels.data.view_as(y_pred)).long().cpu().sum()
test_loss /= len(dataloader.dataset)
accuracy = 100 * correct/len(dataloader.dataset)
return accuracy,test_loss
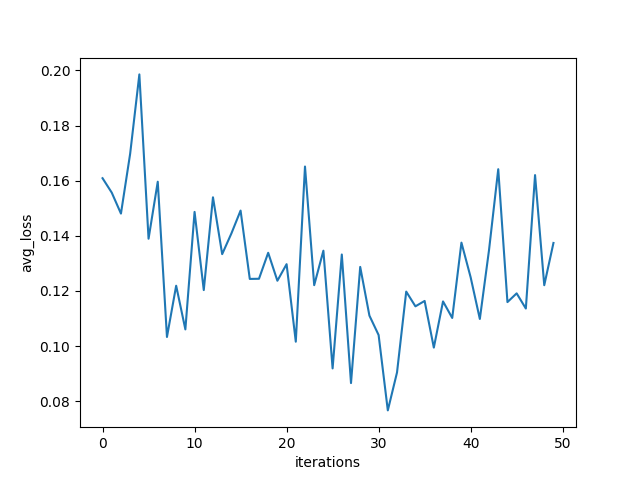
实验结果:50轮noniid


 浙公网安备 33010602011771号
浙公网安备 33010602011771号