数据结构——哈希表
数据结构——哈希表
摘要:本篇笔记主要讲解了重要数据结构——哈希表,以及键值对的含义,为什么要用键值对,哈希表的应用场景,以及内存中运行的数据库的基础知识。
1.何为哈希表?
1.1.用于存储的数据结构
在计算机中,数组和链表都可以用于数据的存储,既然有数据存储,那么必然要有数据的查询,因此我们在将数据存储进数组和链表中之后,必然要对它们进行查询操作。一个链表的查询时间复杂度为O(n),而一个无序数组的查询时间复杂度也是O(n),对于数组的查询时间,我们尚有讨论的余地,但是链表的查询时间肯定是更长的,因为链表是不连续的空间,它只能一个接一个的遍历查询,不管链表是否有序。但是数组的查询时间,是可以进行改进的,当数组中数据是有序的,我们就可以使用二分查找的方式查找数组中的数据,进而能大量节省查询时间,对于二分查找,并不是一个困难的问题,因为二分法每次都能甩掉一般的数据,因此其时间复杂度肯定比O(n)低很多,它的时间复杂度是O(logn),随着查询次数的增长,其时间复杂度会明显比O(n)低很多。
因此对于数组而言,我们的研究方向便不再是如何找更优的查找方案,而是如何将其更快的排序,因此引出了排序算法,目前主流的排序算法有八种,实际上大家比较认可的排序方法还有更多,值得学习的排序方法至少有十种。现实告诉我们,矛盾很难消除,它只会转移,有了二分查找的数组,查询时间长的矛盾并不能直接消除,因为排序算法也是耗费时间的,查询的时间跑到了排序的时间里去了。对于排序的时间复杂度,最低的为O(nlogn),看上去也不是特别的少,这也就直接导致了两个算法加起来的时间复杂度,比直接无序状态查还耗费时间。
基于这个问题,有人创造性的提出了一种新的思想,那就是:在存储数据的时候,不再来数就存,而是使用一种巧妙的分类方法,将数据们进行分类,进而达到像二分查找一样的大规模缩减查询范围的效果,这就是哈希存储。
1.2.哈希表
哈希表的物理结构多种多样,在基数排序中用到的桶结构,实际上就是一种哈希表,哈希表通常是基于某种分类规则,为存储的数据进行分类,然后将他们存储在不同的索引下,这样我们在查询一个数据的时候,先拿到索引,然后找到哈希表中索引吻合的数据存储表,然后直接在这个表中查询即可,而不用再遍历所有数据,这就是哈希表的好处。为了助记哈希表,我将使用一个例子来生动的阐述哈希表:在一个图书馆中,存放着很多各种类别的书,有小说,字典,杂志,专业书籍等若干本。在早期,图书管理员并不怎么好好打理这些书籍,它将这些书籍完全无序的堆放在一起,来了借阅的人,就要直接挨个翻找,直到找到自己想要看的书籍为止。在之后的某一天,来了一个新的图书管理员,这个图书管理员为这些书籍进行了分类,他按照这四种类别将这些书放到了不同的区域中,之后,来了借阅的人,首先会报出书名,然后图书管理员按照书名判断这本书的类别,如来了一个人想借阅《人民文学》,图书管理员就会告诉这名读者:该书籍属于杂志,请去杂志区寻找,这名读者就会直接步行至杂志区,这样就他就不用再对整堆书进行翻找,很大程度上的节省了时间。哈希表的工作原理,实际上就是这样的一种过程。其使用到的主要思想,就是索引存储,它按照某一种规则,为数据分类,然后将这些数据放入不同的类别下,这些类别会有相应的索引值,在我们进行查询的时候,首先会查询索引值,查询到索引值之后,便直接将这个数据与索引值对应的存储结构中进行查询,这样就直接缩减了查询范围,缩小了查询规模。
1.3.什么是哈希表
哈希表是一种计算机中常用的存储结构,其存储方式为索引存储。在进行数据存储的时候,首先会根据某种规则,对数据进行分类,然后将数据放入至相应类别的存储结构中去,在哈希表中,每一个类别都会有一个自己的存储空间,专门存放类别符合索引的数据们,在查询的时候,同样是按照规则先得到类别,然后直接查相应类别对应的存储结构中的数据,进而缩小查询范围,达到节省时间的目的。
2.哈希表的一般构造
哈希表通常是什么样的呢?我们举一个非常简单的例子,我们以某个数字对5取余数的结果对数字进行分类,进而绘制一个哈希表。既然是对5取余运算,我们知道,其结果只能是有0,1,2,3,4五个数,因此分类有五种,索引也就是五种:

而当传入数据:23,12,43,15,24,33,79的时候,他们首先会被分类规则运算并分类,然后存放在自己相应的类别下,如23取余操作之后,结果为3,因此将其存放在索引为3的分类下;12求余之后为2,因此将其存放在索引为2的分类下;43求余结果为3,因此将其存放在索引为3的分类下;15求余结果为0,将其存放在索引为0的分类下;24求余结果为4,将其存放在索引为4的分类下;33求余结果为3,将其存放在索引为3的分类下;79求余结果为4,将其存放在索引为4的分类下。因此整个数据在存入之后,我们便得到了一个这样的结构:
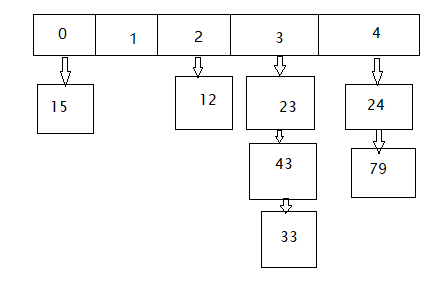
当我们要查询一个数据33的时候,首先就会根据规则对33进行运算,获取到其分类索引值:3,然后我们在分类索引表中搜索到索引为3的分类,然后再在它对应的表中进行查找,这样一来,我们就缩小了查找范围,进而节省了时间。
3.自己书写一套哈希表
显而易见的是,在计算机编程中,哈希表往往不是简单的一个数据结构,而是一个搭配数据结构并具备一套完整的操作的方法的套组,乃至是一个库,在Java中,就存在一个叫hashMap的类,用于进行哈希表结构的操作,因此,我们要书写一个简单的哈希表,其实也是书写了一个套组,接下来,我将分享我自己书写的一个简单的哈希表套组,进而加深对于哈希表的理解与知识点印象。
/*员工类:哈希表中的存储节点,是我写的哈希表中最基础的存在,直接存储数据的单元*/
package y2022.m3.d19.hash;
public class Employee {
public int id;//id号,本质上就是我的哈希表中进行分类的依托,对于表中数据的唯一识别码
public String name;//姓名,表中想要存储的具备价值的信息
public Employee next;//next指针,因为该哈希表是链式结构,所以有这个指针
public Employee(int id, String name){//构造方法
this.id = id;
this.name = name;
}
}
/*值得思考之处:
1.在一个哈希表节点中,我们为何要设定一个id字段,这个字段是干什么用的?
2.我们为什么要用链式结构存储一个哈希表?用数组不香吗?
*/
对于上述两个值得思考的点,我们依次说明:首先,在哈希表中,我们为什么要单独设定一个id值?在初学阶段,我们都会写数组或链表,面对的问题也大多是一些基础的排序算法,总之就是象牙塔里搞的学术问题,也就是说很少面向实际,因此在做题的时候,面向的东西大多都是单纯的数字,没有额外的操作字段,实际上他们如果用于存储一些实际生活中的信息,也是应该有除了数字之外的字段的,还有就是在数组中,每一个节点中都有一个隐含的索引,也就是它的位置,即使是在链表当中,每个链表节点也是拥有属于自己的索引的,并且由于这两位的查找方式,多是穷举遍历然后对比的思想,即使是巧妙的二分查找,实际上也是直接通过数组位置进行计算,然后进行对比,因此他们使用线性结构中的隐藏索引:下标,就可以解决查找问题,但是哈希表中不一样,在哈希表中,我们首先就需要一个分类的依据,没有这个分类的依据,我们自然无法完成分类,也就无法完成哈希表的构建,其次,在真正的哈希表中,我们很少使用到线性结构,而是使用到一种充满灵性的结构:红黑树,并且我们不会使用基于顺序结构的树,而是使用链式结构的树,在这种树中下标概念会显得非常鸡肋,因此我们通常定义一个唯一识别码,这个唯一识别码最主要的作用就是用于分类,以及查找时的索引,这个唯一识别码可以是有意义的字段,比如姓名,我们完全可以自行设计一个可以对姓名进行分类的规则,然后按照姓名存储,但是由于哈希表的存储结构,当两个姓名重复,但两个人不是同一个人的时候,两个人就无法区分,在自己设计着玩的时候,可能伤害不大,然而一旦面临实际问题,面向用户的查找,我们必须保证结果准确无误,所以我们应该尽量保证分类依据是独一无二的数字。
然后,我们为什么要使用链式结构呢?这是因为哈希表本身的结构,并不是一个规则的网格表,根据前文中的图片,大家就可以看出来,哈希表的每个分类下的数据表都又长又短,使用数组可能会导致浪费与不可预估的数据溢出,因此我们选择了链式存储结构,与此同时的,在更好的哈希表中,每项数据一旦过长,就不会再使用链表,而是使用红黑树进行存储,红黑树是一种非常好的数据存储结构,其查找速度非常快。使用链式结构,也意味着我们需要自定义一个索引字段,我们通常是根据这个索引字段进行查找。
实际上,产生第一个疑问的原因,大多是因为很少接触实际问题,实际上,在数组和链表中,我们的数组或链表中的那一个数字,实际上就是我们的索引字段,只不过是为了简化问题,在学习排序或链表操作的时候,我们很少加入其他字段。
/*员工链表类:这个数据结构就是每一个分类索引下的那个表的实体,也就是存储数据的那个表,这个类里边就是表的一些操作*/
package y2022.m3.d19.hash;
import javax.swing.text.Style;
public class EmpLinkedList {
public Employee head;//上边定义的员工类的头结点
public void add(Employee newEmployee){
if(this.head==null){
head = newEmployee;
return;
}//通过这里的添加方法可以看出这是一个无头节点的链表
Employee tempEmp = head;
while(true){
if(tempEmp.next == null){
break;
}
tempEmp = tempEmp.next;
}
tempEmp.next = newEmployee;
}
public void list(){//链表展示方法,不是关键代码
if(head == null){
System.out.println("链表为空");
return;
}
Employee tempEmp = head;
int count = 0;
while(true){
System.out.print(" | ID = "+tempEmp.id +" | 姓名:"+tempEmp.name+" | ");
count++;
if(tempEmp.next == null){
System.out.println("共"+count+"个");
return;
}
tempEmp = tempEmp.next;
}
}
}
接下来是哈希表类的定义:
package y2022.m3.d19.hash;
public class HashTab {
//定义数组
private EmpLinkedList[] empLinkedLists;//这是一个链表类型的数组,需要注意的是,这个链表类型的数组中的元素并不是节点类型的,而是上面定义的链表类型的,这个数组中会有多个EmpLinkedList类型的对象,这些对象中的head字段才是节点类型的变量
//定义数组的大小
private int size;
public HashTab(int size){
this.size = size;
empLinkedLists = new EmpLinkedList[size];//声明好数组之后,默认值是null
//这里的一个小细节需要注意,引用类型的变量在声明后如果不初始化那默认值就是null,数组也不例外,因此在这里声明好数组之后,还要初始化
for(int i = 0;i<size;i++){//这个循环体就是在初始化
empLinkedLists[i] = new EmpLinkedList();//在这里必须要逐一为每一个元素再进行实例化,否则它就没有,就是空,不能进行存储
}
}
public int hash(int id){
return id % size;
}//哈希存储规则,这个就是分类规则,因为我们在上边定义了一个数组,因此我们的数组下标就可以与求余结果相对应,返回的值,即使数字类型
public void add(Employee employee){//添加方法,这个方法是调用链表数组中的一个链表元素的添加方法,它首先是调用了hash方法取得分类,然后根据这个分类结果进行数组元素定位,然后添加的,分类添加的原则就体现在了这里
int num = hash(employee.id);
empLinkedLists[num].add(employee);
}
public void list(){//展示方法,这里调用了链表的展示方法,算是一种方法加强吧,并不重要
for(int i = 0;i<size;i++){
System.out.print("第"+i+"个链表状况:");
empLinkedLists[i].list();
}
}
}
接下来我们来测试一下这套简单的哈希表效果如何,我们使用代码:
package y2022.m3.d19.hash;
public class Test {
public static void main(String[] args) {
HashTab hashtab = new HashTab(8);
Employee employee1 = new Employee(10,"社会虎");
Employee employee2 = new Employee(18,"废物刀");
Employee employee3 = new Employee(26,"黑牛");
Employee employee4 = new Employee(3,"白牛");
Employee employee5 = new Employee(193,"小亮");
Employee employee6 = new Employee(231,"唐老鸭");
Employee employee7 = new Employee(12,"百特曼");
Employee employee8 = new Employee(1,"独爱小尹");
Employee employee9 = new Employee(123,"丽丽");
Employee employee10 = new Employee(126,"带篮子");
Employee employee11 = new Employee(29,"刘墉");
Employee employee12 = new Employee(86,"丁真");
Employee employee13 = new Employee(800,"王冰冰");//定义数据
hashtab.add(employee1);
hashtab.add(employee2);
hashtab.add(employee3);
hashtab.add(employee4);
hashtab.add(employee5);
hashtab.add(employee6);
hashtab.add(employee7);
hashtab.add(employee8);
hashtab.add(employee9);
hashtab.add(employee10);
hashtab.add(employee11);
hashtab.add(employee12);
hashtab.add(employee13);//插入数据
hashtab.list();//显示数据
}
}
输出结果如下:
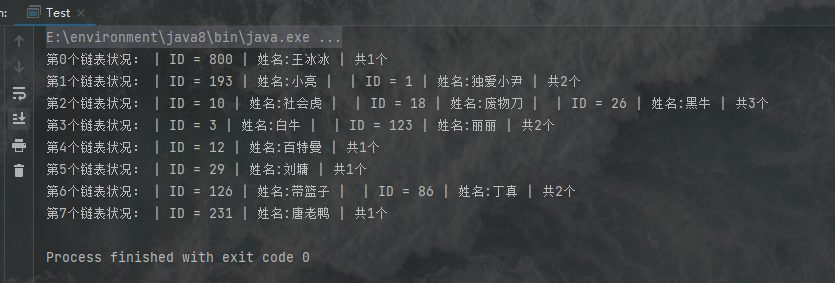
在这个哈希表的实现过程中,我们定义了两个字段,id和name,在哈希表插入数据的过程中,是通过id进行分类,并进行放置,并进行查找的,因此我们可以发现id这个字段,是哈希表中的一个很重要的存在,因此在之后,人们称哈希表中这种决定存储和查询的关键字段为键,而键对应的一些有意义的信息我们称之为:值,两者在一起就是键值对,好,我们已经引出了哈希表中至关重要的一个概念:键值对。
4.HashMap与键值对
在Java中,存在一种现成的哈希表类:HashMap,我们直接声明并使用它,使用这个类,我们就可以在其对象内部的哈希表中插入一个键值对,然后通过键来进行值的查找,同时在这个类中,键名不可重复,如果重复插入同样键名而值不同的键值对,会对已有的键值对进行更新,而不会添加新的键值对,也就是说:键是唯一的标识。接下来我们举个例子来看看Java中的HashMap类:
package y2022.m3.d19.hash;
import java.util.HashMap;
public class HashMapStudy {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<String, Integer>();
HashMap<String, Integer> map1 = new HashMap<String, Integer>();
map.put("杀马特团长",100);
map.put("社会虎",0);
//System.out.println(map.get("Tom"));
map.put("废物刀",10);
map.put("唐老鸭",101);
map.remove("杀马特团长");
System.out.println(map.containsValue(10));
map1.putAll(map);
System.out.println(map1.get("社会虎"));
map1.replace("社会虎",200);
System.out.println(map1.get("社会虎"));
}
}
运行结果为:
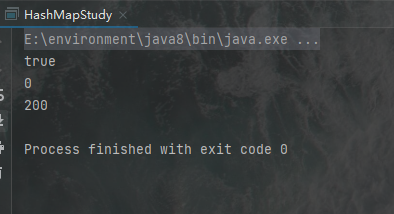
可见它的键可以为字符串类型,这说明其内部肯定有一个针对字符串进行分类并存储的机制,关于这个机制在源码中可以找到,由于我现在还没有怎么看源码,这里先略过,但是我们可以知道的是,这个类的实现,必然包含了一个根据字符串进行分类的机制,同时我们需要知道的是其内部的键值对节点信息的存储,其存储结构是一种叫红黑树的存储结构,关于红黑树的具体知识,我会在以后进行分享。
5.哈希表与键值对的应用场景
好了,我们现在已经知道哈希表是怎么用了,也知道了哈希表中的键值对思想了,那么这些东西,我们苦哈哈的学会了,到底有什么用呢?答案是用于做数据库,你可能会说:啊?哈希表还能做数据库?是的,哈希表的思想被广泛应用于各种非关系型数据库中,根据上面的学习,我们可以感受到哈希表是为了存储数据而生的,其次是我们发现,哈希表的查询速度一定是比关系型数据库快的,为什么?因为关系型数据中是一张一张的表,而表中的信息实际上就是一个连续的数组:
如图所示的表,实际上就是一块连续空间,其本质上就是一个数组。因此在数据库中,总会按照一个主键值进行排序,然后在select的时候使用二分搜索进行查找,这个过程上面也论述了,并不快,而且二分搜索属于一种查询时间比较恒定的算法,而使用哈希表,如果结合红黑树或者跳表进行实现,时间复杂度其实和二分搜索是不分上下的,其次是当某一个分类中的数据更少的时候,哈希表还会花费更少的时间,因此使用哈希表进行数据存储肯定是比数据库快,那这么好,这么快的数据库结构,为啥没有吧mysql和oracle那些传统数据库顶替了呢?道理很简单:存储密度低,那问题又来了:既然他们代替不了oracle,他们能干啥呢?答案是:用哈希表思想实现的数据库,通常在内存中进行数据存储,一些非关系型数据库如MangoDB,Redis等,通常会在内存中而非在磁盘中进行数据存储,为什么要让它们在内存中进行数据存储呢?这个问题值得我们好好讨论一下。所以我打算花费下边的一个小节讲一讲。
6.为什么要有在内存中存储数据的数据库
根据调查研究表明,一个系统中数据库里的数据,被经常查询到的数据,也就占20%作用,此所谓二八原则。既然这些数据经常被查询到,那肯定存在非常高的并发查询次数,如果这些数据被存在硬盘里,那速度肯定是极慢的,事实上,它就是极慢的,从磁盘中检索数据的时间比从内存中检索数据的速度慢了大概好几倍,甚至上十倍,在检索高峰期,很可能长时间查不出来,用户如果感觉查询速度很慢,比如我现在想搜一下滇红茶,如果它被存放在磁盘中,其查询速度可能是10秒,而如果放在内存中,其查询速度可能不到1秒,因为这9秒的时间差,我很可能就会改变心意,甚至骂这个网商公司,说搜个东西还这么慢,必须倒闭奥。因此为了提升用户体验,很多提供查询服务的大型企业,会专门配置一个内存存储阵列,在这个阵列中,可能有上百T的内存空间,而这个内存空间里边,存放的就是那20%的常用信息,用户在查询这些信息的时候非常快速,而管理这些数据的数据库,就是这些基于hash表的数据库,hash加内存,那速度肯定是杠杠的。这些数据库同时也具备持久化的能力,比如将非关系型数据转化成关系数据并放入传统数据库中,这些都是有可能的,关键是这里体现出的思想,实际上就是缓冲区思想,这这个用户与数据的系统中,我们把用户看成了计算机中的CPU,用户从数据库中请求信息,直接从磁盘中请求,每次的速度恒定,但是可能很慢,如果加上了一个内存阵列,作为信息缓冲区,当用户查询一些常用信息的时候就会非常快,查询20%以外的时候,速度就和磁盘中的恒定时间一样,但总体上,用户体验提升了。总之,内存中的数据库就是为了提升20%数据的查询速度。同时内存的实际原则很符合哈希表存储密度低的特点,因为在内存中为了提升速度,本来就已经将存储单元划分的比较大了,这可能正和哈希表中链式结构的意,非常的相得益彰。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号