
结对第二次—文献摘要热词统计及进阶需求
作业格式
- 课程名称:软件工程1916|W(福州大学)
- 作业要求:结对第二次—文献摘要热词统计及进阶需求
- 结对学号:221600118,221600120
- 分工:共同设计思路,221600118主要负责代码编写,221600120主要负责资料查阅及博客撰写
- 作业目标:
-一、基本需求:实现一个能够对文本文件中的单词的词频进行统计的控制台程序。
-二、进阶需求:在基本需求实现的基础上,编码实现顶会热词统计器。 - Github-221600120
- Github-221600118
- 签入记录:


作业正文
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | ||
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 100 |
| • Design Spec | • 生成设计文档 | 50 | 50 |
| • Design Review | • 设计复审 | 40 | 45 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | ||
| • Design | • 具体设计 | 60 | 60 |
| • Coding | • 具体编码 | 600 | 650 |
| • Code Review | • 代码复审 | 50 | 60 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 50 | 200 |
| Reporting | 报告 | ||
| • Test Report | • 测试报告 | 50 | 100 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 1010 | 1345 |
解题思路
在拿到题目之后,首先考虑的是语言的选择,考虑到由于221600118比较擅长使用Java以及jJava的类库比较强大所以选择使用Java实现;之后就是考虑如何完成需求,由于编程能力不足,最终只能选择完成基础需求。然后就是类的方面,考虑到需求大体可以分成三个功能需求,所以封装了3个类,分别对应字符数统计,行数统计以及单词数统计,最后再将3个类整合起来。在查找资料方面,主要使用百度和Google查找了Java的api以及去图书馆查阅了Java编程的相关书籍。
实现过程
用3个类分别实现字符数统计,行数统计以及单词数统计的功能,最后再由Main调用,字符的总数就是读入文件的总字符数;

行数由读入的换行符确定,再减去行中没有有效字符的行数;
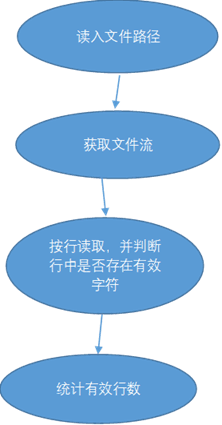
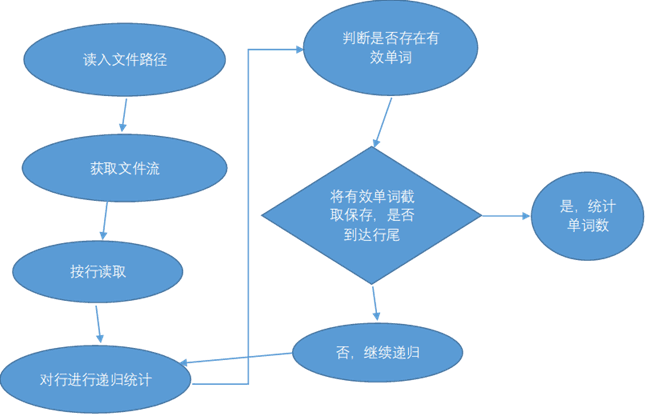
比较难实现的是单词数的统计,按照需求,单词要求满足开头连续4个字符都是字母,碰到分隔符就截断,所以在处理时先对前四个字符特判,如果是则继续将字母或数字字符添加到当前单词上直到遇到分隔符,遇到分隔符后就将这个单词存入HashMap,HashMap的键值对为单词-频率,如果该单词已存在HashMap中则频率加一,再对剩下的字符串进行同样的操作。
性能
由于编程能力不足,无法对程序在进行性能改进;程序中消耗最大的是判断是否是单词的函数。
关键代码
public class CountChar {
public static int getNumber(String path){//字符数统计
int num=0;
try{
File file = new File(path);
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(file)));
int cc;
char ccc;
while((cc=br.read())!=-1) {
ccc=(char)cc;
if(ccc=='\n') {
num--;
}
if(cc>=0&&cc<=127) {
num++;
}
}
br.close();
return num;
}catch(Exception e) {
e.printStackTrace();
}
return 0;
}
}
public class CountLine {//行数统计
public static int getLine(String path) {
int lines=0;
try{
File file = new File(path);
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(file)));
String line;
boolean bline=false;//行是否含有有效字符
char c[];
while ((line = br.readLine()) != null) {
if(line.length()==0) {
continue;
}
bline=false;
c=line.toCharArray();
for(int i=0;i<c.length;i++) {
int ch=(int)c[i];
if(ch>=33&&ch<127) {
bline=true;
}
}
if(bline) lines++;
}
br.close();
return lines;
} catch (IOException e) {
e.printStackTrace();
}
return 0;
}
}
public class CountWords {//词数统计
public static HashMap<String, Integer> hash = new HashMap<String, Integer>();
public static HashMap<String, Integer> getWords(String path) {
try{
File file = new File(path);
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(file)));
String line;
while ((line = br.readLine()) != null) getWord(line);
br.close();
return hash;
} catch (IOException e) {
e.printStackTrace();
}
return new HashMap<String, Integer>();
}
public static void getWord(String line) {//获得词语
if(line.length()<4) return;
String theline=line.toLowerCase();
char c[]=theline.toCharArray();
for(int i=0;i<c.length;i++) {
int ch=(int)c[i];
if(isAZ(ch)) {
if(the4(c,i)) {
int last=0;
for(int j=i+4;j<c.length;j++) {
last=j;
if(!isAZ((int)c[last])&&!isNUM((int)c[last])) {
getWord(theline.substring(last,theline.length()));
break;
}
}
if(last==c.length-1) last++;
String word=theline.substring(i,last);
if(hash.containsKey(word)) {
int nn=hash.get(word);
hash.put(word, nn+1);
}else {
hash.put(word, 1);
}
break;
}
}
}
}
public static boolean the4(char[] line,int index) {//判断是否是单词
int n=0;
for(int i=index+1;i<line.length;i++) {
int ch=(int)line[i];
if(isAZ(ch)) {
if(++n==3) return true;
}else {
return false;
}
}
return false;
}
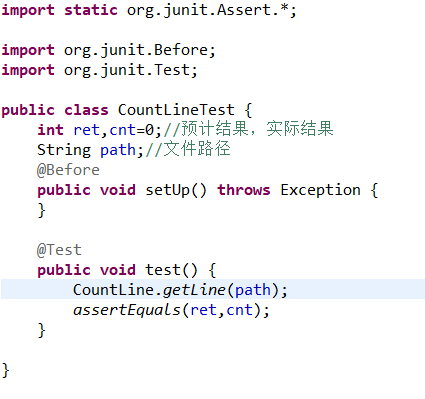
单元测试
单元测试采用的数据包括将已有的样例混合和采用随机数随机生成的文件。
单元测试代码


部分文件测试结果
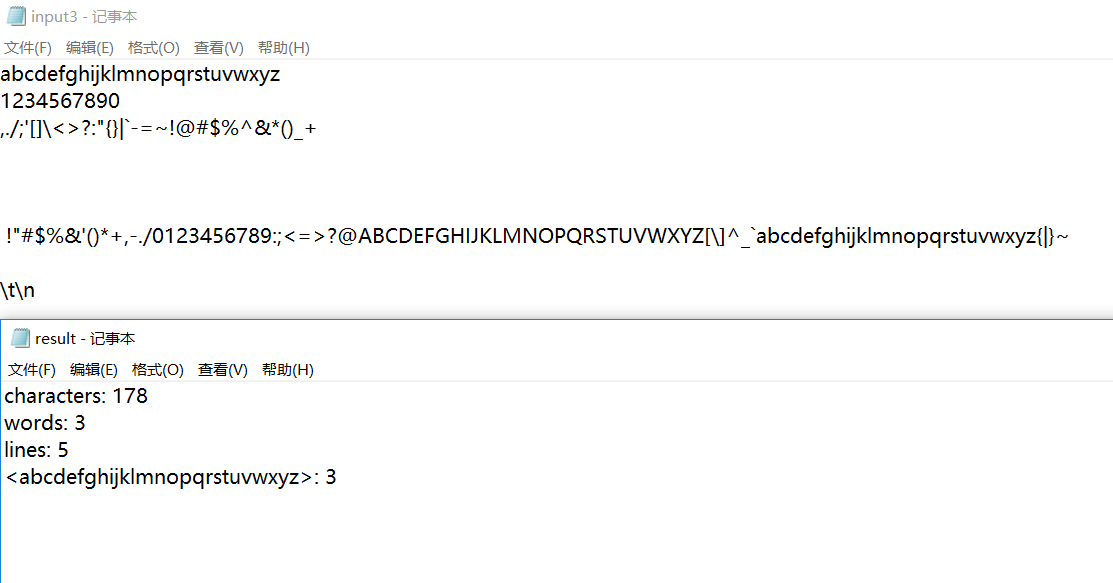
遇到的困难
在一开始的时候采用readline读入一整行的字符串,结果由于readline会消除换行符导致字符数统计错误,后来改用read直接读入整个文件中的字符再进行处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号