
数据类型校验——schema
背景
一般情况下,我们都是按照既定的数据结构和输入参数进行在程序开发。但是往往在调试过程中,我们会发现大部分情况下,都是传入的参数不符合预期。那么针对该问题,我们就需要引入数据类型校验工具。
如果参数数量较少,限制比较简单,我们可以使用以下三种方式进行解决:
- 第一种:通过
try...except(或者assert)直接粗暴处理; - 第二种:基于枚举的思想,通过
if-else处理各种可能;
但上述两种处理在复杂情况下不具备友好的推广价值。
那么在Python中有没有现成的库可以解决该问题呢?通过查询,最终发现了Schema。其是一个用于验证Python数据结构的库。
接下来将对Schema进行重点介绍。
库信息
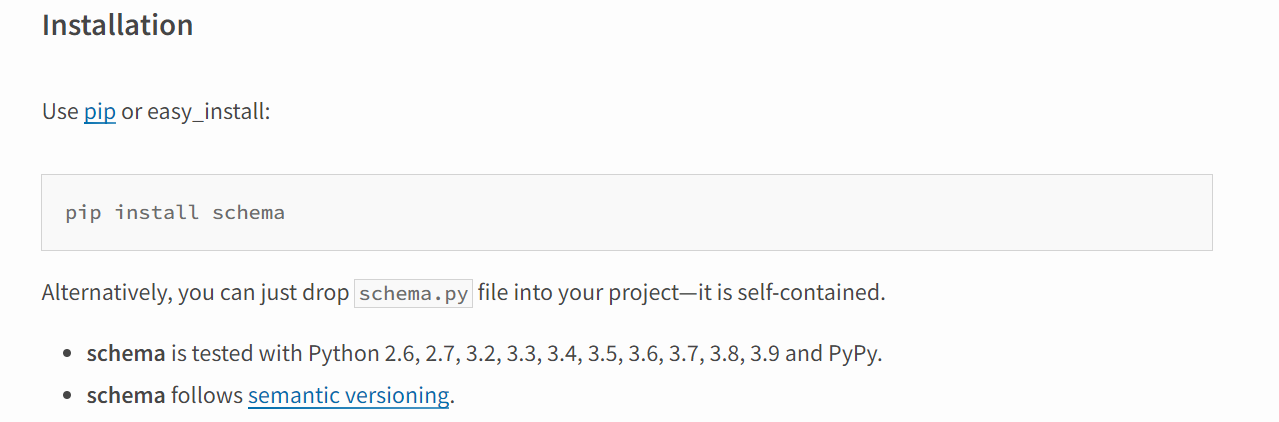
安装
基本介绍
-
基本数据类型介绍(校验合格返回对应数据;否则返回
SchemaError)>>> from schema import Schema >>> Schema(int).validate(123) 123 >>> Schema(int).validate('123') Traceback (most recent call last): ... schema.SchemaUnexpectedTypeError: '123' should be instance of 'int' >>> Schema(object).validate('hai') 'hai' -
Callables(可调用对象):
Scema(func),其中func()-->Boole,此时如果为真(True),则返回被校验对象;否则返回SchemaError
>>> import os
>>> Schema(os.path.exists).validate('./')
'./'
>>> Schema(os.path.exists).validate('./non-existent/')
Traceback (most recent call last):
...
schema.SchemaError: exists('./non-existent/') should evaluate to True
-
Validatables(可验证)
- 正则表达式
>>> from schema import Regex >>> import re >>> Regex(r'^foo').validate('foobar') 'foobar' >>> Regex(r'^[A-Z]+$', flags=re.I).validate('those-dashes-dont-match') Traceback (most recent call last): ... schema.SchemaError: Regex('^[A-Z]+$', flags=re.IGNORECASE) does not match 'those-dashes-dont-match'-
加工后的数据,
func可以是Use(int):表示将原始数据转换成int后进行校验;如果想保持原始不被修改,可以使用
Const; -
也可以使用
lambda匿名函数,示例:
>> from schema import Use, Const, And, Schema >> from datetime import datetime >> is_future = lambda date: datetime.now() > date >> to_json = lambda v: {"timestamp": v} >> Schema(And(Const(And(Use(datetime.fromtimestamp), is_future)), Use(to_json))).validate(1234567890) {"timestamp": 1234567890} -
LIsts,similar containers(列表,类似容器)
如果
func是list、tuple、set对象,它将验证相应数据容器的内容 针对该容器中列出的所有模式,并聚合所有错误。>>> Schema([1, 0]).validate([1, 1, 0, 1]) [1, 1, 0, 1] >>> Schema((int, float)).validate((5, 7, 8, 'not int or float here')) Traceback (most recent call last): ... schema.SchemaError: Or(<class 'int'>, <class 'float'>) did not validate 'not int or float here' 'not int or float here' should be instance of 'int' 'not int or float here' should be instance of 'float' -
字典
- 对键和值的值的校验
>>> d = Schema({'name': str, ... 'age': lambda n: 18 <= n <= 99}).validate({'name': 'Sue', 'age': 28}) >>> assert d == {'name': 'Sue', 'age': 28}- 对字典所有对象都进行校验,即键、值以及它们的值;
```python >>> schema = Schema({str: int, # string keys should have integer values ... int: None}) # int keys should be always None >>> data = schema.validate({'key1': 1, 'key2': 2, ... 10: None, 20: None}) >>> schema.validate({'key1': 1, ... 10: 'not None here'}) Traceback (most recent call last): ... schema.SchemaError: Key '10' error: None does not match 'not None here' ``` -
选择性参数校验
>>> from schema import Optional >>> Schema({Optional('color', default='blue'): str, ... str: str}).validate({'texture': 'furry'} ... ) == {'color': 'blue', 'texture': 'furry'} True -
And,Or
>>> from schema import And, Or
>>> Schema({'age': And(int, lambda n: 0 < n < 99)}).validate({'age': 7})
{'age': 7}
>>> Schema({'password': And(str, lambda s: len(s) > 6)}).validate({'password': 'hai'})
Traceback (most recent call last):
...
schema.SchemaError: Key 'password' error:
<lambda>('hai') should evaluate to True
>>> Schema(And(Or(int, float), lambda x: x > 0)).validate(3.1415)
3.1415
-
输入数据中多余参数的处理机制
如本来
func是用来校验a,b,c三个参数的输入,那么用户在输入的数据中包含a,b,c,d多了一个d参数,此时我们如何进行处理?Schema提供了ignore_extra_keys用于处理该问题。#False:会触发schema.SchemaWrongKeyError >>> schema = Schema({'name': str}, ignore_extra_keys=True) >>> schema.validate({'name': 'Sam', 'age': '42'}) #age被过滤掉 {'name': 'Sam'} -
自定义验证
class EventSchema(schema.Schema):
def validate(self, data, _is_event_schema=True):
data = super(EventSchema, self).validate(data, _is_event_schema=False)
if _is_event_schema and data.get("minimum", None) is None:
data["minimum"] = data["capacity"]
return data
events_schema = schema.Schema(
{
str: EventSchema({
"capacity": int,
schema.Optional("minimum"): int, # default to capacity
})
}
)
data = {'event1': {'capacity': 1}, 'event2': {'capacity': 2, 'minimum': 3}}
events = events_schema.validate(data)
assert events['event1']['minimum'] == 1 # == capacity
assert events['event2']['minimum'] == 3
-
报错信息处理
such as
Schema,And,Or,Regex,Use可以传递error关键字参数,输出对应的报错信息。>>> Schema(Use(int, error='Invalid year')).validate('XVII') Traceback (most recent call last): ... schema.SchemaError: Invalid year
示例
示例1
JSON字符串的多层校验:
- 第一步使用:
json.loads将其转换成{}; - 然后对键值进行值类型校验,其中存在可选性参数(
Optional)和嵌套型参数(files对象)
>>> gist = '''{"description": "the description for this gist",
... "public": true,
... "files": {
... "file1.txt": {"content": "String file contents"},
... "other.txt": {"content": "Another file contents"}}}'''
>>> from schema import Schema, And, Use, Optional
>>> import json
>>> gist_schema = Schema(And(Use(json.loads), # first convert from JSON
... # use str since json returns unicode
... {Optional('description'): str,
... 'public': bool,
... 'files': {str: {'content': str}}}))
>>> gist = gist_schema.validate(gist)
# gist:
{u'description': u'the description for this gist',
u'files': {u'file1.txt': {u'content': u'String file contents'},
u'other.txt': {u'content': u'Another file contents'}},
u'public': True}
这是一个信号分析场景,算法要求如下:
- 窗函数只支持:hann,hamming,boxcar,triang,gaussian五种;
- 输入的数据类型:支持:dB和Pvar;
- 测点名称:批量输入(list),且每个都是字符型;
- 采样率与测点保持一致,但数据本身是float;
- 常量值E,范围(0,100),不包含边界
- 谱分析类型有两种;
应用场景:
- 第一种情况:需要除谱分析以外的所有参数;
- 第二种情况:所有参数
目标:
定义一个数据校验器,用来处理上述应用场景涉及到的所有参数。
from schema import And, Const, Schema, Use, Optional
# 定义传参数据类型以及基本格式要求
VALIDATE_FORMAT = Schema({
"window_name" : And(str,
lambda x: x in "hann hamming boxcar triang gaussian".split(),
error=""
),
"mode" : And(str,
lambda x: x in "dB Pvar".split(),
error=""),
"stations" : And(list,
lambda x: isinstance(x[0], str),
error=""),
"sample_rates" : And(list,
lambda x: isinstance(float(x[0]), float),
error=""
),
"E" : And(Use(float),
lambda x: 0 < x < 100,
error=""),
Optional("spectral_type"): And(str,
lambda x: x in "PK RMS".split(),
error="")
}, ignore_extra_keys=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号