
dataframe局部赋值
背景
问题描述
如下图所示:(A)上图表示某仪器随开关开闭前后的变化曲线;(B)下图表示开关闭状态。现在的需求有三个:
- 不考虑开关状态下超过指定阈值时的监测值统计特征
- 开关打开状态(B=1,粉色区域)下超过指定阈值的监测值值局部信息统计
- 开关闭合(B=0,空白区域)状态下超过指定阈值的监测值值局部信息统计
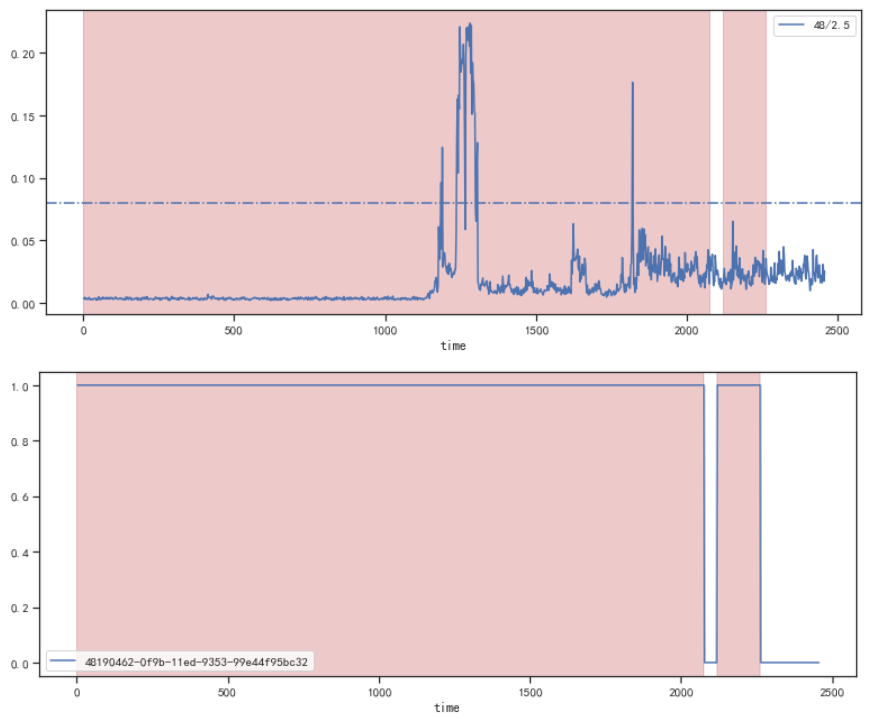
直观上看,(2)和(3)的结果统计结果应该存在明显的差异。但实际实现过程中,得到的结果却是完全一致。甚是烦恼,通过定位,发生了一个神奇的代码,如下:
temp_data[temp_data['time'].between(tmp_start_time, tmp_end_time)][
'sig'] = tmp_value - 1
"""
temp_data:为我们的仪器检测值
start_time:开始时间
end_time:表示结束时间
tmp_value:为我们关注的一种状态
这里tmp_value-1的目的是基于检测值以更显眼的方式区分目标状态
"""
看上去没啥问题,就是一个简单的datafram赋值语句,接下来让我们通过模拟数据进行问题定位。
问题定位
a=pd.DataFrame({'a':range(10),'b':range(2,12)})
#备份一份a
b=a.copy()
a[a['a'].between(2,6)]['b']=100
#比较赋值前后a的变换
np.allclose(a.values,b.values)#True
赋值前后,dataframe a居然完全一样。
pandas官方解释
示例:
访问
dfmi = pd.DataFrame([list('abcd'),
list('efgh'),
list('ijkl'),
list('mnop')],
columns=pd.MultiIndex.from_product([['one', 'two'],
['first', 'second']]))
dfmi
Out[357]:
one two
first second first second
0 a b c d
1 e f g h
2 i j k l
3 m n o p
# 第一种访问方式
dfmi['one']['second']
"""
0 b
1 f
2 j
3 n
Name: second, dtype: object
"""
#第二种访问方式
dfmi.loc[:, ('one', 'second')]
"""
0 b
1 f
2 j
3 n
Name: (one, second), dtype: object
"""
这些都产生相同的结果,那么你应该使用哪个?了解这些操作的顺序以及为什么方法 2 ( .loc) 比方法 1 (chained []) 更受青睐是很有启发性的。
dfmi['one']选择列的第一级并返回单索引的 DataFrame。然后另一个 Python 操作dfmi_with_one['second']选择由 索引的系列'second'。这由变量表示,dfmi_with_one因为 pandas 将这些操作视为单独的事件。例如,对 的单独调用__getitem__,因此必须将它们视为线性操作,它们一个接一个地发生。
相比之下df.loc[:,('one','second')],将嵌套元组传递(slice(None),('one','second'))给单个调用 __getitem__. 这使得 pandas 可以将其作为一个整体来处理。此外,这种操作顺序可以显着加快,并且如果需要,可以对**两个轴进行索引。
重新赋值
访问时两种方式只是性能问题,赋值时第二种方式回触发SettingWithCopy警告是,并且原始数据对象并未发生小改。
#第一种
dfmi.loc[:, ('one', 'second')] = 100
# becomes
dfmi.loc.__setitem__((slice(None), ('one', 'second')), 100)
"""
one two
first second first second
0 a 100 c d
1 e 100 g h
2 i 100 k l
3 m 100 o p
"""
#第二种:
dfmi['one']['second'] = 1000
# becomes
dfmi.__getitem__('one').__setitem__('second', 1000)
"""
C:\Users\B_Hanan\AppData\Local\Temp\ipykernel_4124\431561245.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
dfmi['one']['second'] = 100
C:\Users\B_Hanan\AppData\Local\Temp\ipykernel_4124\431561245.py:3: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
dfmi.__getitem__('one').__setitem__('second', 100)
one two
first second first second
0 a 100 c d
1 e 100 g h
2 i 100 k l
3 m 100 o p
"""
如何理解?
其实核心是当前数据对象是副本还是视图?在numpy中我们已经介绍了视图和副本的区别,从这里我们可以直接看出链式查询([]的方式)实际上返回的是副本(赋值不会改变原数据),而.loc返回的实际上是视图(view,会发生数据的更改)。
问题解决
所以针对上述问题,我们应该用loc进行赋值。
temp_data.loc[temp_data['time'].between(tmp_start_time, tmp_end_time),
'sig'] = tmp_value - 1
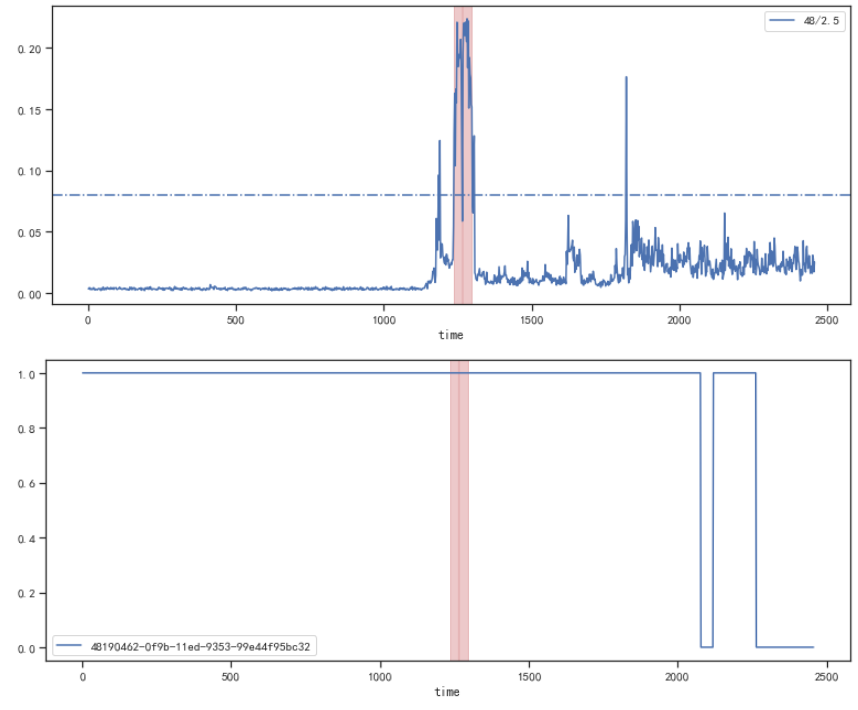
最终效果图:
- 打开状态下存在超限情况
- 关闭状态下无超限情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号