
Read Matlab File
背景
以前读取mat文件时,常用的方法是使用scipy.io.loadmat(path)函数。然而近期在读取mat文件中出现了NotImplementError的问题(具体报错信息如下)。这是什么问题呢?
ile D:\software\Anaconda3\envs\py38\lib\site-packages\scipy\io\matlab\_mio.py:225, in loadmat(file_name, mdict, appendmat, **kwargs)
223 variable_names = kwargs.pop('variable_names', None)
224 with _open_file_context(file_name, appendmat) as f:
--> 225 MR, _ = mat_reader_factory(f, **kwargs)
226 matfile_dict = MR.get_variables(variable_names)
228 if mdict is not None:
File D:\software\Anaconda3\envs\py38\lib\site-packages\scipy\io\matlab\_mio.py:80, in mat_reader_factory(file_name, appendmat, **kwargs)
78 return MatFile5Reader(byte_stream, **kwargs), file_opened
79 elif mjv == 2:
---> 80 raise NotImplementedError('Please use HDF reader for matlab v7.3 files')
81 else:
82 raise TypeError('Did not recognize version %s' % mjv)
NotImplementedError: Please use HDF reader for matlab v7.3 files
问题排查
首先查看scipy版本
import scipy
print(scipy.version.version)#1.8.0
查看对应的官方文档
Notes:v4 (Level 1.0), v6 and v7 to 7.2 matfiles are supported.
You will need an HDF5 Python library to read MATLAB 7.3 format mat files. Because SciPy does not supply one, we do not implement the HDF5 / 7.3 interface here.
从该文档可知,当前方法仅支持到7.2。所以解析mat7.3版本需要另行他法。
h5py
解决方案:
import h5py
with h5py.File('test.mat', 'r') as file:
print(list(file.keys()))
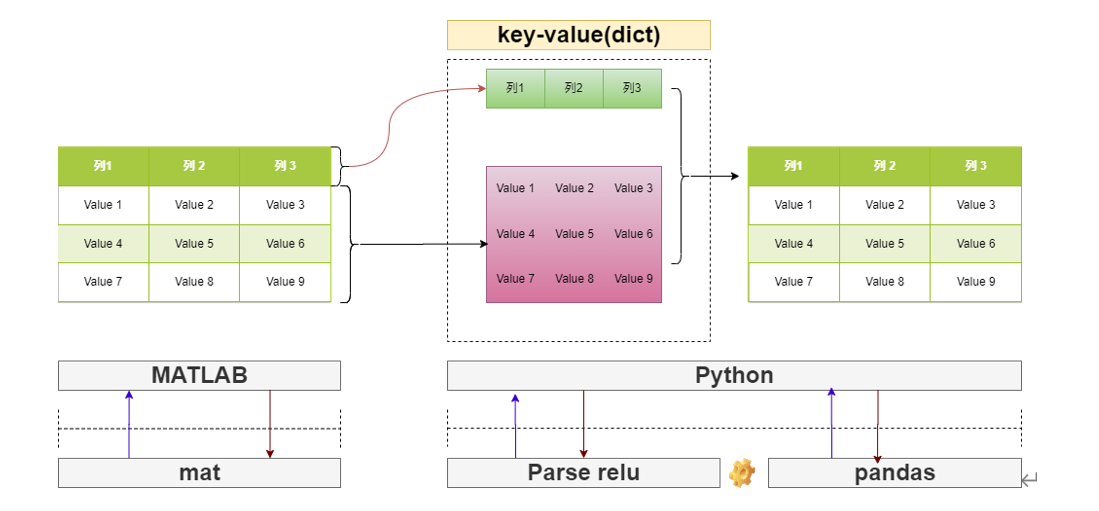
file的结果类型是dict。通过字典的查询类型可以获取对应数据对象的值。
将mat文件对象转换成dataframe
mat
MATLAB 是“matrix laboratory”的缩写形式。MATLAB主要用于处理整个的矩阵和数组,而其它编程语言大多逐个处理数值。所有 MATLAB 变量都是多维数组,与数据类型无关。矩阵是指通常用来进行线性代数运算的二维数组。
dataFrame
Pandas DataFrame是一个包含二维数据及其对应标签的结构。DataFrame 广泛应用于数据科学、机器学习、科学计算和许多其他数据密集型领域。
DataFrame 类似于SQL 表或您在 Excel 或 Calc 中使用的电子表格。在许多情况下,DataFrame 比表格或电子表格更快、更易于使用且功能更强大,因为它们是Python和NumPy生态系统不可或缺的一部分。
综上所述,我们可以发现常见的关系型数据在mat文件中,表头和表体应该是用两个数组分开进行存储的,而Python中是使用Dataframe结构进行存储。应用mat解析规则的本质是将mat文件转化为DataFrame数据对象。所以我们仅需要知道mat文件中表示表头(即列名)和表体(数据部分)的mat命名参数即可。
在matlab中构建列名
主要有两种方式:char或String,假如有变量A,AA,AAA三个则在matlab中的创建方式如下:
%char方式
var1=char('A','AA','AAA');
%string
var2=string({'A','AA','AAA'});
区别是:
char方法得到的是一个3*3的数组(max_len=len('AAA')=3);
string方法得到一个1*3的数组;

mat文件保存
方法1:在右侧工作区选择目标变量进行另存,默认保存为mat7.3以下(简记为mat73p,当前版本R2016b);
方法2:在命令函数中使用save函数可以指定具体版本,如save(path,'A','B','-v7.3')

链接:save
python读取mat文件
loadmat
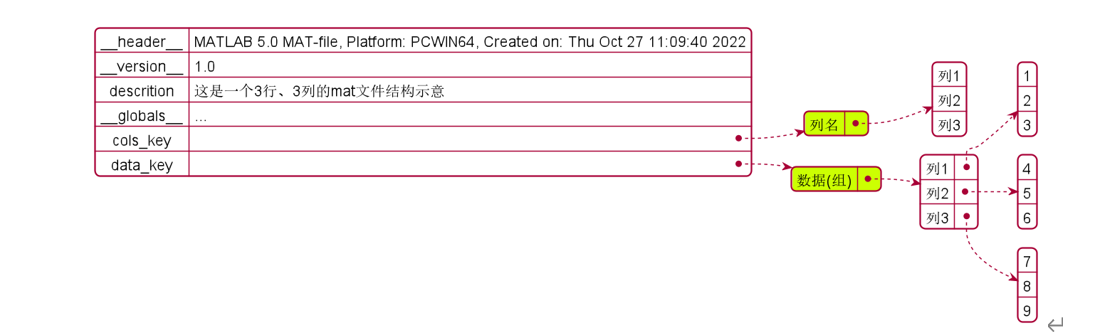
load进来的对象是dict,示意效果如下:
-
双下滑线开始的为文件配置信息
-
普通变量才是保存的真正信息
-
char array变量可以正常加载进来;
-
string array变量加载进来为
None;这个问题,目前没有啥好的解决方案只能选用char方法生成列名数组。
h5py
使用h5py.File的方式我们可以正常解析mat7.3文件,变量访问方式与字典比较类似,但不是字典。存在的问题:
- char array数组被转换成
ascii的形式,数据类型(dtype)为unit*,需要转换才能得到原始信息;
#初步读进来效果
a_data["new_cols"][...]
"""new_cols在matlab中通过char方式生成
array([[116, 118, 114],
[ 32, 105, 112],
[ 32, 98, 109]], dtype=uint16)
"""
# 转换后效果
np.apply_along_axis(lambda x: "".join(map(chr,x)),0,np.array(a_data["new_cols"]))
array(['t ', 'vib', 'rpm'], dtype='<U3')
- string array数组则被转换成引用变量(
'[<HDF5 object reference>]')或者暂时无法识别的数组(具体解读方案尚不明确);
[in]:a_data["new_cols2"][...]
[out]:array([[3707764736, 2, 1, 1, 1,1]], dtype=uint32)
[in]:a_data["new_cols3"][...]
[out]:array([[3707764736, 2, 1, 1, 2,1]], dtype=uint32)
小结
-
mat7.3p版本可以使用
scipy.io.loadmat库进行解析; -
mat7.3版本可以使用
h5py库进行解析 -
mat文件保存时的列信息最好通过
char的方式进行保存;
HDF5
虽然上述问题已经得到了解决,但是还是有必要了解一下HDF5是什么?
[什么是HDF5](HDF5 是一种分层数据格式,它建立在 HDF4 和 NetCDF(另外两种分层数据格式)之上。)
分层数据格式版本 5 (HDF5) 是一种开源文件格式,支持大型、复杂、异构数据。HDF5 使用类似于“文件目录”的结构,允许您以多种不同的结构化方式组织文件中的数据,就像您在计算机上处理文件一样。HDF5 格式还允许嵌入元数据,使其具有自描述性。
HDF5 是一种分层数据格式,它建立在 HDF4 和 NetCDF(另外两种分层数据格式)之上(官网)。

为什么使用HDF5?
层次结构-文件中的文件目录
HDF5 格式可以被认为是在一个文件中包含和描述的文件系统。想一想存储在计算机上的文件和文件夹。您可能有一个数据目录,其中包含多个现场站点的一些温度数据。这些温度数据每分钟收集一次,并按小时、每天和每周汇总。在一个HDF5 文件中,您可以存储一组类似的数据,其组织方式与您在计算机上组织文件和文件夹的方式相同。然而,在 HDF5 文件中,我们在计算机上称为“目录”或“文件夹”的部分称为groups,我们在计算机上称为文件的部分称为datasets.
2个重要的HDF5术语
- 组: HDF5 文件中的类似元素的文件夹,其中可能包含其他组或数据集。
- 数据集: HDF5 文件中包含的实际数据。数据集通常(但不一定)存储在文件的组中。
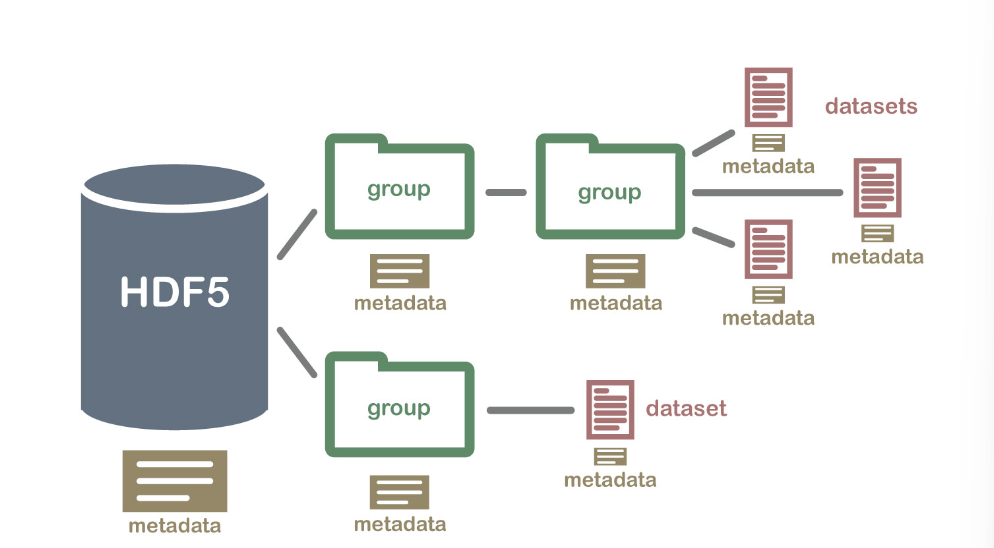
包含组、数据集和关联元数据的示例 HDF5 文件结构。
包含数据集的 HDF5 文件的结构可能如下所示:
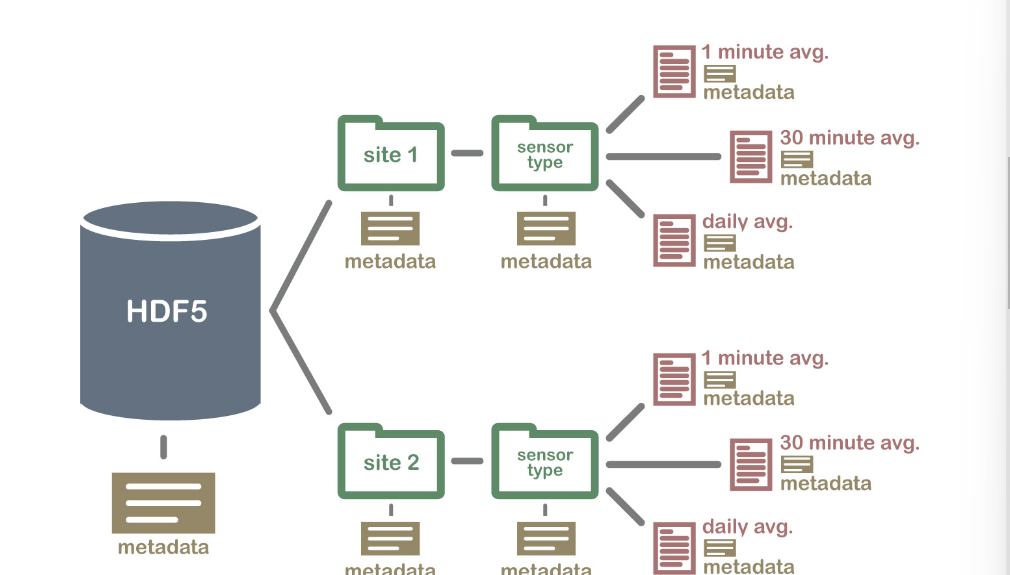
示例 HDF5 文件结构,包含多个现场站点的数据,还包含各种数据集(在不同时间间隔取平均值)。
HDF5是一种自描述格式
HDF5 格式是自描述的。这意味着每个文件、组和数据集都可以有关联的元数据来准确描述数据是什么。按照上面的例子,我们可以将每个站点的信息嵌入到文件中,例如:
- 站点的全名和 X、Y 位置
- 网站的描述。
- 任何感兴趣的文档。
同样,我们可能会添加有关如何收集数据集中数据的信息,例如用于收集温度数据的传感器的描述。我们还可以将信息附加到站点组中的每个数据集,说明如何执行平均以及在什么时间段内数据可用。
将元数据附加到每个文件、组和数据集的一个主要好处是,这有助于实现自动化,而无需单独的(和额外的)元数据文档。使用编程语言,如 R 或 Python,我们可以从已经与数据集关联的元数据中获取信息,并且我们可能需要处理数据集。
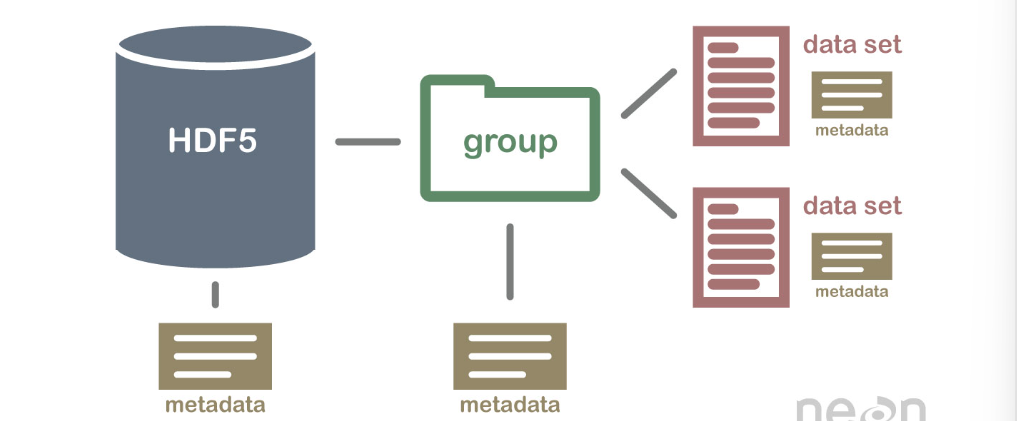
HDF5 文件是自描述的——这意味着所有元素(文件本身、组和数据集)都可以有关联的元数据来描述元素中包含的信息。
压缩和高效子集
HDF5 格式是一种压缩格式。HDF5 中包含的所有数据的大小都经过优化,这使得整体文件大小更小。然而,即使压缩后,HDF5 文件通常包含大数据,因此仍然非常大。HDF5 的一个强大属性是data slicing,通过它可以提取数据集的特定子集进行处理。这意味着不必将整个数据集读入内存 (RAM);非常有助于让我们更有效地处理非常大(千兆字节或更多)的数据集!
异构数据存储
HDF5 文件可以在同一个文件中存储许多不同类型的数据。例如,一个组可能包含一组数据集以包含整数(数字)和文本(字符串)数据。或者,一个数据集可以包含异构数据类型(例如,一个数据集中的文本和数字数据)。这意味着 HDF5 可以在一个文件中存储以下任何一项(以及更多):
- 一个站点或多个站点的温度、降水和 PAR(光合有效辐射)数据
- 一组覆盖一个或多个区域的图像(每个图像都可以具有与之关联的特定空间信息 - 所有这些都在同一个文件中)
- 包含数百个波段的多光谱或高光谱空间数据集。
- 描述昆虫、哺乳动物、植被和气候特征的几个地点的实地数据。
- 一组覆盖一个或多个区域的图像(每个图像都可以具有与之关联的唯一空间信息)
- 以及更多!
开放格式
HDF5 格式是开放的,可以免费使用。支持库(和免费查看器)可以从 HDF Group 网站下载。因此,HDF5 在许多程序中得到广泛支持,包括 R 和 等开源编程语言,以及 和等Python商业编程工具。以 HDF5 格式存储的空间数据可用于 GIS 和成像程序,包括Matlab``IDL``QGIS``ArcGIS``ENVI等。
总结要点 - HDF5 的优势
- 自描述具有 HDF5 文件的数据集是自描述的。这使我们能够高效地提取元数据,而无需额外的元数据文档。
- 支持异构数据:不同类型的数据集可以包含在一个 HDF5 文件中。
- 支持大型、复杂的数据:HDF5 是一种压缩格式,旨在支持大型、异构和复杂的数据集。
- 支持数据切片: “数据切片”,或根据需要提取数据集的一部分进行分析,意味着大文件不需要完全读入计算机内存或 RAM。
- 开放格式 - 许多工具的广泛支持:由于 HDF5 格式是开放的,因此它受到许多编程语言和工具的支持,包括 R 、
Python和QGIS等开源语言.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号