
Sklearn笔记:model_selection(一)——交叉验证
————————————————————————————————————————————————
主要内容:
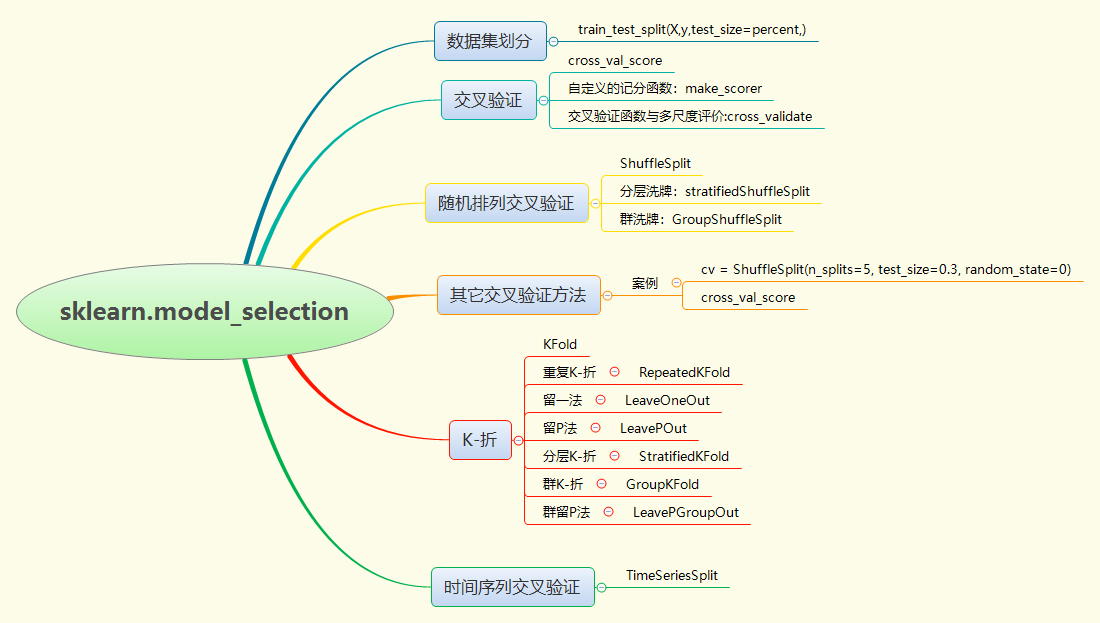
————————————————————————————————————————————————————
交叉验证流程
划分数据集
help(train_test_split):
Split arrays or matrices into random train and test subsets
(将数组或矩阵拆分成随机训练和测试子集).
语法:
train_test_split(X,y,test_size,train_size,shuffle=True,random_state=0)
test_size : float, int or None, optional (default=None)
If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the test split. If int, represents the absolute number of test samples. If None, the value is set to the complement of the train size. If ``train_size`` is also None, it will be set to 0.25.
(如果为Float,则应介于0.0和1.0之间,并表示要包括在测试拆分中的数据集的比例。如果为int,则表示测试样本的绝对数。如果无,则将该值设置为列车大小的补码。如果``RAIN_SIZE``也为NONE,则设置为0.25。)
train_size : float, int, or None, (default=None)
If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the train split. If int, represents the absolute number of train samples. If None, the value is automatically set to the complement of the test size.
(如果为Float,则应介于0.0和1.0之间,并表示训练数据集划分的比例。如果为int,则表示训练样本的绝对数。如果为None,则该值将自动设置为测试大小的补码。)
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import svm
X,y=datasets.load_iris(return_X_y=True)
print(X.shape,y.shape)
(150, 4) (150,)
#划分数据集
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.4,random_state=0)
print(X_train.shape,y_train.shape)
(90, 4) (90,)
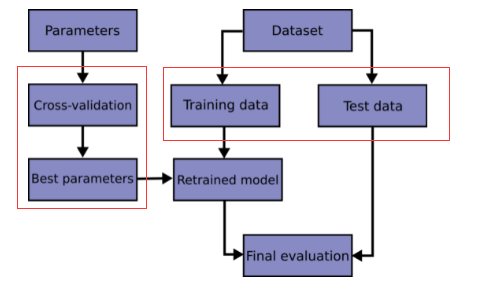
交叉验证
K-folds(如图所示):
- 使用k-1折作为训练数据;
- 得到的模型在数据的其他部分上进行验证(即被用作测试集)
##### 交叉验证的度量(cross_val_score)
from sklearn.model_selection import cross_val_score
help(cross_val_score):
语法:
cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=None, verbose=0, fit_params=None, pre_dispatch='2*n_jobs', error_score=nan)
Parameters:
estimator : (估计器,即训练的模型)estimator object implementing 'fit'。
``cv`` default value if None changed from 3-fold to 5-fold.
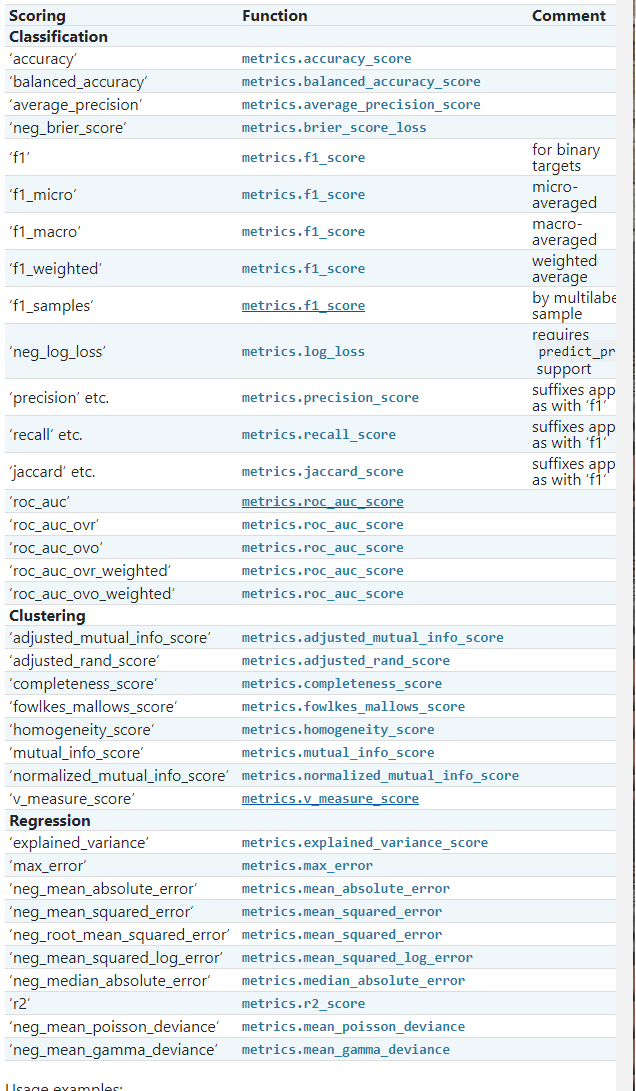
scoring (计分,即衡量指标): string, callable or None, optional, default: None
A string (see model evaluation documentation) or a scorer callable object / function with signature ``scorer(estimator, X, y)`` which should return only a single value(它应该只返回单个值).
clf=svm.SVC(kernel='linear',C=1)
scores=cross_val_score(clf,X,y,cv=5)
scores
array([0.96666667, 1. , 0.96666667, 0.96666667, 1. ])
#得分估计的平均分数和95%置信区间
print("Accuracy:%0.2f+(+/-%0.2f)"%(scores.mean(),scores.std()*2))
Accuracy:0.98+(+/-0.03)
#自定义
def custom_cv_2foldf(X):
n=X.shape[0]
i=1
while i<=2:
idx=np.arange(n*(i-1)/2,n*i/2,dtype=int)
yield idx,idx
i+=1
custom_cv=custom_cv_2foldf(X)
cross_val_score(clf,X,y,cv=custom_cv)
array([1. , 0.97333333])
#数据划分与数据预处理相结合
from sklearn import preprocessing
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.4,random_state=0)
scaler=preprocessing.StandardScaler().fit(X_train)
X_train_transformed=scaler.transform(X_train)
clf=svm.SVC(C=1).fit(X_train_transformed,y_train)
X_test_transformed=scaler.transform(X_test)
clf.score(X_test_transformed,y_test)
0.9333333333333333
#通过管道函数调用
from sklearn.pipeline import make_pipeline
clf=make_pipeline(preprocessing.StandardScaler(),svm.SVC(C=1))
cross_val_score(clf,X,y,cv=10)
array([1. , 0.93333333, 1. , 0.93333333, 1. ,
0.93333333, 0.86666667, 1. , 1. , 1. ])
交叉验证函数与多尺度评价
这个cross_validate功能不同cross_val_score有两种方式:
-
它允许为评估指定多个指标。
-
除了测试分数之外,它还返回包含拟合次数、分数次数(以及可选的训练分数以及拟合估计器)的数据集。
from sklearn.model_selection import cross_validate
from sklearn.metrics import recall_score
scoring=['precision_macro','recall_macro']
clf=svm.SVC(kernel='linear',C=1,random_state=0)
scores=cross_validate(clf,X,y,scoring=scoring)
for i in sorted(scores.keys()):
print(i,scores[i])
fit_time [0.00299907 0.00299883 0.00299811 0.00199699 0.00200033]
score_time [0.00699735 0.00599766 0.00399637 0.00399947 0.00599527]
test_precision_macro [0.96969697 1. 0.96969697 0.96969697 1. ]
test_recall_macro [0.96666667 1. 0.96666667 0.96666667 1. ]
#自定义计分函数
from sklearn.metrics import make_scorer
scoring={'prec_macro':'precision_macro',
'rec_macro':make_scorer(recall_score,average='macro')}
scores=cross_validate(clf,X,y,scoring=scoring,
cv=5,return_train_score=True)
for i in sorted(scores.keys()):
print(i,scores[i])
fit_time [0.00299978 0.00200081 0.0039978 0.00099802 0.00297999]
score_time [0.0050025 0.00199771 0.00599599 0.00601339 0.00899601]
test_prec_macro [0.96969697 1. 0.96969697 0.96969697 1. ]
test_rec_macro [0.96666667 1. 0.96666667 0.96666667 1. ]
train_prec_macro [0.97674419 0.97674419 0.99186992 0.98412698 0.98333333]
train_rec_macro [0.975 0.975 0.99166667 0.98333333 0.98333333]
#cross_validate使用单一指标
scores=cross_validate(clf,X,y,scoring='precision_macro',cv=5,return_estimator=True)
sorted(scores.keys())
['estimator', 'fit_time', 'score_time', 'test_score']
再次查看cross_validate函数帮助
help(cross_validate):
语法:
cross_validate(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=None, verbose=0, fit_params=None, pre_dispatch='2*n_jobs', return_train_score=False, return_estimator=False, error_score=nan)
Evaluate metric(s) by cross-validation and also record fit/score times.
(通过交叉验证评估指标,并记录匹配/得分时间。)
两个比较重要的参数:
return_train_score : boolean, default=False
Whether to include train scores.Computing training scores is used to get insights on how different parameter settings impact the overfitting/underfitting trade-off. However computing the scores on the training set can be computationally expensive and is not strictly required to select the parameters that yield the best generalization performance.
return_estimator : boolean, default False
Whether to return the estimators fitted on each split(是否返回在每个拆分上估计器的拟合。).
通过交叉验证获得预测
功能cross_val_predict具有类似的接口cross_val_score,但是对于输入中的每个元素,返回该元素在测试集中时获得的预测。
功能cross_val_predict适用于:
- 从不同的模型中得到的预测的可视化。
- 模型混合:当使用一个监督估计量的预测来训练另一个估计器时,采用集合方法。
案例:Receiver Operating Characteristic (ROC) with cross validation — scikit-learn 0.22.2 documentation
交叉验证迭代器
基础知识介绍

常见做法是将大约2/3~4/5的样本用于训练,剩余样本用于测试。
——————————————————————————————————————————————————————————

留一法是交叉验证发的特例
留一法:不受随机样本划分的影响,因为m个样本只唯一的方式划分为m个子集——每个子集包含一个样本;留一法使用的训练集与初始样本集相比至少了一个样本,这就使得在绝大多数情况下,留一法中被实际评估的模型与期望评估的用D训练出来很相似。因此,留一法的评估结果往往被认为比较准确。当数据集极大时,训练m个模型的开销可能时难以忍受的。
————————————————————————————————————————————

自助法在数据集较小、难以有效划分训练/测试集时比较有用;自助法产生的数据集改变了数据集的初始数据集分布,这会引入估计偏差。因此,在初始数据量足够时,留出法和交叉验证发更常用一些。
KFold
KFold把所有的样本样本组,称为折叠(如果k=n,这相当于留一法),大小相等(如果可能的话)。预测函数是通过k-1折建模,用剩余的一折(份)进行测试
import numpy as np
from sklearn.model_selection import KFold
help(KFold):K-Folds cross-validator
Provides train/test indices to split data in train/test sets. Split dataset into k consecutive folds (without shuffling by default). Each fold is then used once as a validation while the k - 1 remaining folds form the training set.
(提高训练集\测试集索引);将数据集划分成连续的K折(默认的不洗牌,即不打乱顺序);
(每一折将被用作一次验证集,其它折将被作为训练集)
参数:
n_splits : int, default=5 至少为2;
X=['a','b','c','d']
kf=KFold(n_splits=2)
for train,test in kf.split(X):
print("%s %s"%(train,test))
[2 3] [0 1]
[0 1] [2 3]
重复KFolds
RepeatedKFold 重复KFold n次
from sklearn.model_selection import RepeatedKFold
help(RepeatedKFold):Repeated K-Fold cross validator.
Repeats K-Fold n times with different randomization in each repetition.
(在每次重复中使用不同的随机性重复K次n次。)
X=np.array([[1,2],[3,4],[1,2],[3,4]])
random_state=12883823
rkf=RepeatedKFold(n_splits=2,n_repeats=2,random_state=random_state)
#rkf.split: Generates indices to split data into training and test set.
for train,test in rkf.split(X):
print("%s %s"%(train,test))
[2 3] [0 1]
[0 1] [2 3]
[0 2] [1 3]
[1 3] [0 2]
#同样,RepeatedStratifiedKFold重复分层K-折叠n次,在每次重复中具有不同的随机化.
##### 留一法
from sklearn.model_selection import LeaveOneOut
X=[1,2,3,4]
loo=LeaveOneOut()
for train,test in loo.split(X):
print('%s %s'%(train,test))
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
##### 留P法
from sklearn.model_selection import LeavePOut
X=[1,2,3,4]
lpo=LeavePOut(p=2)
for train,test in lpo.split(X):
print('%s %s'%(train,test))
[2 3] [0 1]
[1 3] [0 2]
[1 2] [0 3]
[0 3] [1 2]
[0 2] [1 3]
[0 1] [2 3]
随机交叉验证
这个ShuffleSplit迭代器将生成用户定义的独立训练/测试数据集分割数。首先对样本进行洗牌,然后将其分割成一对训练和测试集。
可以通过随机数种子控制结果重复性的随机性
from sklearn.model_selection import ShuffleSplit
X=np.arange(10)
ss=ShuffleSplit(n_splits=5,test_size=0.25,random_state=0)
for train_index,test_index in ss.split(X):
print("%s %s"%(train_index,test_index))
[9 1 6 7 3 0 5] [2 8 4]
[2 9 8 0 6 7 4] [3 5 1]
[4 5 1 0 6 9 7] [2 3 8]
[2 7 5 8 0 3 4] [6 1 9]
[4 1 0 6 8 9 3] [5 2 7]
分层K-折
应用数据不平衡情况下。
from sklearn.model_selection import StratifiedKFold,KFold
import numpy as np
X,y=np.ones((50,1)),np.hstack(([0]*45,[1]*5))
skf=StratifiedKFold(n_splits=3)
for train,test in skf.split(X,y):
print("train -{} | test - {}".format(np.bincount(y[train]),np.bincount(y[test])))
train -[30 3] | test - [15 2]
train -[30 3] | test - [15 2]
train -[30 4] | test - [15 1]
np.info(np.bincount)
Count number of occurrences of each value in array of non-negative ints(统计非负整数数组中每个值的出现次数).
x=np.array([0, 1, 1, 3, 2, 1, 7])
np.bincount(np.array([0, 1, 1, 3, 2, 1, 7]))
输出结果:array([1, 3, 1, 1, 0, 0, 0, 1])
理解:
np.bincount:先生成数组:[0,1,2,3,4,5,6,7](size:range(max(x)+1))
然后按顺序统计每一个数字出现的次数
kf=KFold(n_splits=3)
for train,test in kf.split(X,y):
print('train- {}| test--{}'.format(
np.bincount(y[train]),np.bincount(y[test])))
train- [28 5]| test--[17]
train- [28 5]| test--[17]
train- [34]| test--[11 5]
分组数据的交叉验证迭代器
群KFold
from sklearn.model_selection import GroupKFold
# StratifiedShuffleSplit是…的变化ShuffleSplit它返回分层分裂,i.e它通过为每个目标类保留与完整集合中相同的百分比来创建拆分。
help(GroupKFold):
K-fold iterator variant with non-overlapping groups.
具有非重叠组的k重迭代器变体。
The same group will not appear in two different folds (the number of distinct groups has to be at least equal to the number of folds). The folds are approximately balanced in the sense that the number ofdistinct groups is approximately the same in each fold.
(同一组不会出现在两个不同的折叠中(不同组的数量必须至少等于折叠的数量)。在每个褶皱中不同组的数目大致相同的意义上,褶皱是大致平衡的。)
X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]
y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"]
groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
gkf = GroupKFold(n_splits=3)
for train, test in gkf.split(X, y, groups=groups):
print("%s %s" % (train, test))
#索引[0,1,2]属于‘1’组;[2,3,4,5]属于'2'组;[6,7,8,9]属于'3'组
[0 1 2 3 4 5] [6 7 8 9]
[0 1 2 6 7 8 9] [3 4 5]
[3 4 5 6 7 8 9] [0 1 2]
群留一法
from sklearn.model_selection import LeaveOneGroupOut
#强调的是组
X = [1, 5, 10, 50, 60, 70, 80]
y = [0, 1, 1, 2, 2, 2, 2]
groups = [1, 1, 2, 2, 3, 3, 3]
logo = LeaveOneGroupOut()
for train, test in logo.split(X, y, groups=groups):
print("%s %s" % (train, test))
[2 3 4 5 6] [0 1]
[0 1 4 5 6] [2 3]
[0 1 2 3] [4 5 6]
help(LeaveOneGroupOut): Leave One Group Out cross-validator
Provides train/test indices to split data according to a third-party provided group. This group information can be used to encode arbitrary domain specific stratifications of the samples as integers.
(根据第三方提供的组提供训练/测试索引以拆分数据。该组信息可用于将样本的任意域特定分层编码为整数。)
For instance the groups could be the year of collection of the samples and thus allow for cross-validation against time-based splits.
(例如,这些组可以是样本的收集年份,从而允许对照基于时间的分割进行交叉验证。)
群留P法
from sklearn.model_selection import LeavePGroupsOut
X = np.arange(6)
y = [1, 1, 1, 2, 2, 2]
groups = [1, 1, 2, 2, 3, 3]
lpgo = LeavePGroupsOut(n_groups=2)
for train, test in lpgo.split(X, y, groups=groups):
print("%s %s" % (train, test))
[4 5] [0 1 2 3]
[2 3] [0 1 4 5]
[0 1] [2 3 4 5]
群洗牌
from sklearn.model_selection import GroupShuffleSplit
X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 0.001]
y = ["a", "b", "b", "b", "c", "c", "c", "a"]
groups = [1, 1, 2, 2, 3, 3, 4, 4]
gss = GroupShuffleSplit(n_splits=4, test_size=0.5, random_state=0)
for train, test in gss.split(X, y, groups=groups):
print("%s %s" % (train, test))
[0 1 2 3] [4 5 6 7]
[2 3 6 7] [0 1 4 5]
[2 3 4 5] [0 1 6 7]
[4 5 6 7] [0 1 2 3]
from sklearn.model_selection import GroupShuffleSplit
X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 0.001]
y = ["a", "b", "b", "b", "c", "c", "c", "a"]
#修改组标记
groups = [1, 1, 2, 2, 3, 3, 3, 4]
gss = GroupShuffleSplit(n_splits=4, test_size=0.5, random_state=0)
for train, test in gss.split(X, y, groups=groups):
print("%s %s" % (train, test))
[0 1 2 3] [4 5 6 7]
[2 3 7] [0 1 4 5 6]
[2 3 4 5 6] [0 1 7]
[4 5 6 7] [0 1 2 3]
时间序列分裂
TimeSeriesSplit是KFold的变化,它首先返回第k折作为训练集和(k+1)折作为测试集。注意,与标准的交叉验证方法不同,连续训练集是它们之前的超集。此外,它还将所有剩余数据添加到第一个训练分区中,该分区通常用于训练模型。
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
tscv = TimeSeriesSplit(n_splits=3)
print(tscv)
for train, test in tscv.split(X):
print("%s %s" % (train, test))
TimeSeriesSplit(max_train_size=None, n_splits=3)
[0 1 2] [3]
[0 1 2 3] [4]
[0 1 2 3 4] [5]
帮助文档:help(TimeSeriesSplit):Time Series cross-validator
Provides train/test indices to split time series data samples that are observed at fixed time intervals, in train/test sets. In each split, test indices must be higher than before, and thus shuffling in cross validator is inappropriate.
(....以分割训练/测试集中以固定时间间隔观察的时间序列数据样本....)
This cross-validation object is a variation of :class:KFold. In the kth split, it returns first k folds as train set and the (k+1)th fold as test set.
Note that unlike standard cross-validation methods, successive training sets are supersets of those that come before them.
(请注意,与标准交叉验证方法不同,连续训练集是它们之前的训练集的超集。)
注:
如果数据排序不是任意的(例如,具有相同类别标签的样本是连续的),则首先对其进行混洗对于获得有意义的交叉验证结果可能是必不可少的。然而,如果样本不是独立且相同分布的,则情况可能正好相反。
例如,如果样本对应于新闻文章,并按它们的发布时间排序,那么混洗数据可能会导致模型过度拟合和验证分数膨胀:它将在人为类似(在时间上接近)训练样本的样本上进行测试。
一些交叉验证迭代器(如KFold)有一个内置选项,可以在拆分数据索引之前对其进行混洗。
请注意:
- 这比直接混洗数据消耗更少的内存。
- 默认情况下,不会发生混洗,包括通过指定cv=ome_INTEGER TO CROSS_VAL_SCORE、网格搜索等执行的(分层)K折交叉验证。请记住,TRAIN_TEST_SPLIT仍返回随机拆分。
- RANDOM_STATE参数缺省为NONE,这意味着每次迭代KFold(.,Shuffle=True)时,混洗都会不同。但是,GridSearchCV将对通过一次调用其Fit方法验证的每组参数使用相同的随机洗牌。
- 要获得每次拆分的相同结果,请将RANDOM_STATE设置为整数。
———————————————————————————————————————————————————————————————————————————————————————
参考:
3.1. Cross-validation: evaluating estimator performance — scikit-learn 0.22.2 documentation
周志华《机器学习》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号