
基于selenium的爬虫
该爬虫用来实现指定关键词 以及特定时间区间的搜狗微信搜索_订阅号及文章内容的爬取.如果没有记错的话,未登录情况下,只能翻10页,想要更多,则需要基于selenium利用cookies实现模拟登录.

声明:本程序仅用于学习交流,请勿恶意使用!!!
完整程序
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 7 13:21:00 2019
@author: Administrator
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver import ActionChains
from bs4 import BeautifulSoup
import json
import time
import requests
import os.path
import random
class WXspider:
def __init__(self):
pass
def SearchKeywords(self,driver,searchName,dateStart,dateEnd):
"""
利用Cokies实现免密登陆
"""
url="https://weixin.sogou.com"
#Cookies0=json.load(open(r'C:\Users\Administrator\Desktop\spider_data\0.json','r'))
Cookies1 = json.load(open(r'C:\Users\Administrator\Desktop\spider_data\cookies\1.json', 'r'))
#Cookies2 = json.load(open(r'C:\Users\Administrator\Desktop\spider_data\2.json', 'r'))
driver.get(url)
time.sleep(3)
WebDriverWait(driver,20).until(
EC.presence_of_element_located((By.CSS_SELECTOR,"div[class='searchbox'] a[class='logo']")))
#Cookies=random.choice([Cookies0,Cookies1,Cookies2])
driver.delete_all_cookies()
time.sleep(5)
for cookie in Cookies1:
driver.add_cookie(cookie)
driver.get(url)
if driver.find_element_by_css_selector('div[class="login-info"] a[class="yh"]'):
print("登陆成功".center(100,'*'))
else:
print("利用Cookies免密登陆失败")
#开始输入关键字
input=driver.find_element_by_css_selector("div[class='qborder2'] input[class='query']")
input.clear()
input.send_keys(searchName)
input.send_keys(Keys.ENTER)
time.sleep(10)
##按照时间进行筛选
searchBtn=driver.find_element_by_css_selector("div[id='tool_show']").click()
time.sleep(1)
driver.find_element_by_class_name('btn-time').click()#输入时间
input2=driver.find_element_by_id('date_start')
input2.clear()
input2.send_keys(dateStart)
input3=driver.find_element_by_id('date_end')
input3.clear()
input3.send_keys(dateEnd)
#确认
driver.find_element_by_class_name('enter')
for i in range(5):
driver.execute_script('window.scrollTo(0,"document.body.scrollHeight")')
ActionChains(driver).key_down(Keys.DOWN).perform()
time.sleep(3)
return driver.page_source
def NextPage(self,driver):
"""
开始翻页
"""
nextPage=driver.find_element_by_link_text("下一页")
nextPageText=nextPage.text
#nextPage=driver.find_element_by_css_selector("div[class='p-fy'] a[last()]")
curPage=driver.find_element_by_css_selector('div[id="pagebar_container"] span').text
#print("当前是第{:-^30.0f}页,正在尝试翻页!".format(int(curPage)+1))
try:
if nextPageText:
nextPage.click()
driver.refresh()
time.sleep(10)
for i in range(8):
driver.execute_script('window.scrollTo(0,"document.body.scrollHeight")')
ActionChains(driver).key_down(Keys.DOWN).perform()
time.sleep(3)
except:
pass
print("翻页出现异常")
finally:
return nextPageText,driver.page_source,curPage
def GetParseHtml(self,link):
user_agent="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3650.400 QQBrowser/10.4.3341.400"
headers={"User-agent":user_agent}
r=requests.get(link,headers=headers,timeout=30)
if r.status_code==200:
r.encoding='utf-8'
soup=BeautifulSoup(r.text,'lxml')
content=""
for i in soup.select('div[id="js_content"]'):
content+=i.text.strip()
print('链接采集完成'.center(50,'*'))
return content
else:
print('该链接有问题,当前采集失败,暂时跳过')
pass
def GetContent(self,pageSource):
soup=BeautifulSoup(pageSource,'lxml')
filename=soup.title.string.split(" – ")[0]
domain=os.path.abspath(r"C:\Users\Administrator\Desktop\长春长生")#存放路径
filepath=os.path.join(domain,(filename+".json"))
for i in soup.select("div[class='news-box'] ul[class='news-list'] li"):
try:
newsInfo={}
newsInfo['title']=i.find('h3').text.strip()
newsInfo['time']=i.select("span[class='s2']")[0].text.split(')')[-1]
if i.select('div[class="txt-box"] h3 a'):
tempLink=i.select('div[class="txt-box"] h3 a')[0].attrs['data-share']
#开始解析网页
content=self.GetParseHtml(tempLink)
time.sleep(3)
if content:
#print(content)
newsInfo['Content']=content
with open(filepath,'a',encoding='utf-8') as f:
json.dump(newsInfo,fp=f,ensure_ascii=False)
f.close()
except:
pass
return print("当前页采集完成".center(25,'*'))
def WeiXinSpider(self,searchname):
driver=webdriver.Firefox()
driver.set_page_load_timeout(100)
driver.maximize_window()
driver.implicitly_wait(30)
print("开始微信文章的爬取!!!".center(50,'*'))
self.SearchKeywords(driver,searchname)
self.GetContent(driver.page_source)
page=0
try:
while page<100:
nextPage_sign,pageSource,curPage = self.NextPage(driver) # 判断"下一页"标志是否存在
print("开始当前页--->>>{}<<<---采集".format(int(curPage) + 1))
time.sleep(3)
self.GetContent(pageSource)
page+=1
if nextPage_sign:
pass
else:
break
except:
print('已经是最后一页'.center(50,'*'))
pass
finally:
driver.close()
print('本次爬取任务完成'.center(50,'*'))
if __name__=="__main__":
spider=WXspider()
spider.WeiXinSpider("长春长生疫苗",dateStart='2018-07-14',dateEnd='2018-07-16')
爬虫(类)的详细介绍
程序是我在未完整学习类时所写,感觉写的太罗嗦.这一点请忽略,重在理解爬虫过程:
1. 利用Cookies实现免密登录
def SearchKeywords(self,driver,searchName,dateStart,dateEnd):
其中:searchName为检索的目标关键词,dateStart,dateEnd表示目标时间区段.
(1) 利用Cookies模拟登录.
面向的是搜狗微信,所以需要利用Cookies实现模拟登录.虽然这个获取途经有点猥琐,但是对于新手,绝对实用.就是一步一步模拟登录,然后用driver.get_cookies()保存当前登录用户的Cookies.基于selenium一步模拟操作到位获取Cookies,对我来说困难啊,关键时刻还得
"扫一扫,然后手动!手动!手动!!!"(自己体会)
程序中使用Cookies1 = json.load()用来加载本地(保存)的Cookies.这里建议多收集几组.网站好像识别能力提高了,容易被封IP.
(2) 输入检索关键词,以及时间区段
(有点尴尬,时间段输入框好像不见了)
浏览器的基本设置参数
driver=webdriver.Firefox()
driver.set_page_load_timeout(100)
driver.maximize_window()
driver.implicitly_wait(30)
2. 页面解析,及信息提取
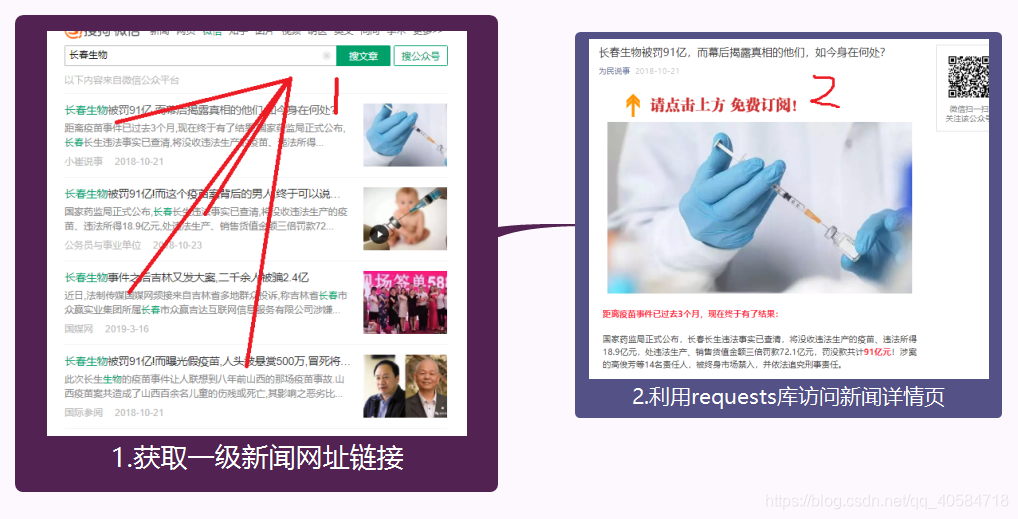
def GetParseHtml(self,link):
先获取一级新闻网址链接,然后使用requests.get访问详情页.然后使用BeautifulSoup .
相关信息提取技术可以参考爬虫:网页信息提取_Python_qq_40584718的博客-CSDN博客
3. 实现翻页
def NextPage(self,driver)用来实现翻页
常用的方式有以下几种:
(1)有明显的翻页标志,如下一页,则可以通过:
nextPage=driver.find_element_by_link_text("下一页")
或者:
nextPage=driver.find_element_by_id("下一页所对应的"id标签)
上述两种,适用范围不如通过xpath和css逐级定位.xpath,css使用语法
对应在selenium中的语法格式为:
driver.find_element_by_css_selector()
driver.find_element_by_xpath()
翻页终止条件:
(1) 在一定范围内抓取固定页,这种比较简单;
(2) 有的网页遍历到最后一页时,下一页这个标签在源码中会找不到,可以通过定位翻页标注(常与while搭配使用)确定是否是最后一页!
4. 数据的存储问题
两种策略:
1.按照特定单位进行抓取与存储;
本文是一次翻页中作为基本单位.这种需要将抓取的文件保存在统一文件夹,然后使用os库来批量导入,合并数据.这种方法对异常情况的响应友好性要好于第二种策略.
2.者全部抓完一次存储
这种情况对程序的完整性要求较高,需要注意异常情况捕获,和处理.一次性存储可以使用json.dump或者pandas和numpy的数据存储功能.
5. 页面响应以及睡眠问题
在抓取的过程中,要注意适当的睡眠,保证页面及时完整加载.
下面的程序用来实现常见的页面滚动操作,导入文件from selenium.webdriver import ActionChains.
for i in range(8):
driver.execute_script('window.scrollTo(0,"document.body.scrollHeight")')
ActionChains(driver).key_down(Keys.DOWN).perform()
time.sleep(3)
通过一级链接访问详情页时需要注意详情页是打开了新窗口,还是覆盖了本地窗口,这将会
涉及到网页的重定向问题.这两个细节需要谨慎处理.
6.建议
静态网页,用requests或urllib库完全够用;要是动态网页,再考虑使用selenium.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号