
oracle学习笔记(六):oracle中排序函数及其应用
初学oracle时,关于排序问题经常使用order by或者使用rownum进行分页,但是在TopN(N>2)时上述方法使用不是特别方便。在刷题过程中了解并学习了row_number,dense_rank,rank等函数,以下是对这几个问题的简单整理。
基础介绍
1. 基本用法
row_number() over (partition by col1 order by col2)
-- 表示根据col1分组,在分组内部根据col2排序,而此函数计算的值就表示每组内部排序后的顺序编号
(组内连续唯一)
rank,dense_rank,row_number,以及分组排名partition,lag(前向(首)),lead(向后(末))
| 函数 | 描述 |
|---|---|
| rank | 排名会出现并列第n名,它之后的会跳过空出的名次,例如:1,2,2,4 |
| dense_rank | 排名会出现并列第n名,它之后的名次为n+1,例如:1,2,2,3 |
| row_number: | :排名采用唯一序号连续值,例如1,2,3,4 |
| partition | 将排名限制到某一分组 |
| lag | arg1是检索列,arg2是偏移量(可以理解为滑动平均的长度),arg3表示超出当前范围的处理 |
2. 基本格式
- 基本格式
row_number() over(partition by x order by y) ...
row_number() over(order by x) ...
dense_rank() over(order by x) ...
rank() over(order by x)...
3.常见查询组合
- 常见的查询引用:
--按id进行排序
select id,val,row_number() over (order by id) x from a;
--//按val分组,分组内按id排序
select id,val,row_number() over (partition by val order by id) x from a;
-- id排序值 减去 val分组内id排序值 = 连续相同值的排序值
select id,val,row_number() over (order by id) - row_number() over (partition by val order by id) x from a;
应用案例
1.连续值查询问题
- 1编写一个 SQL 查询,查找所有至少连续出现三次的数字。
表数据样例:
create table Logs(
id number primary key,
num number
);
insert into Logs values(1,1);
insert into Logs values(2,1);
insert into Logs values(3,1);
insert into Logs values(4,2);
insert into Logs values(5,1);
insert into Logs values(6,2);
insert into Logs values(7,2);
对应的查询语句:
/* Write your PL/SQL query statement below */
select distinct(num) "ConsecutiveNums"
from (
select num,(row_number() over(order by id )-row_number() over(partition by num order by id)) rank_
from Logs
) tmp
group by rank_,num
having count(rank_)>=3;
类似的案例:603. 连续空余座位 - 力扣(LeetCode)
| seat_id | free |
|---|---|
| 1 | 1 |
| 2 | 0 |
| 3 | 1 |
| 4 | 1 |
| 5 | 1 |
其中,free中0表示已占位,1表示空缺
写一个查询语句,获取连续出现两次的空位,并返回seat_id !
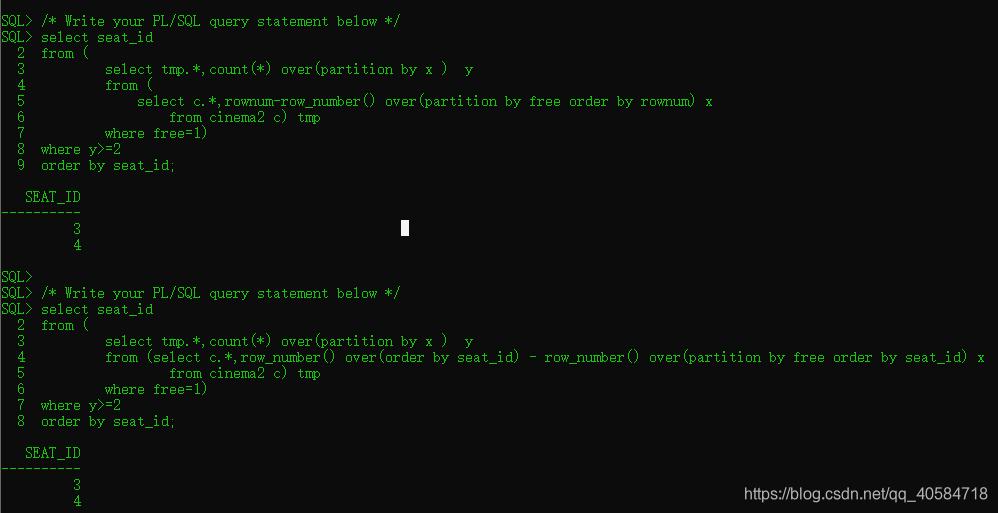
/* Write your PL/SQL query statement below */
select seat_id
from (
select tmp.*,count(*) over(partition by x ) y
from (
select c.*,rownum-row_number() over(partition by free order by rownum) x
from cinema c) tmp
where free=1)
where y>=2
order by seat_id;
或者:
/* Write your PL/SQL query statement below */
select seat_id
from (
select tmp.*,count(*) over(partition by x ) y
from (select c.*,row_number() over(order by seat_id)-row_number() over(partition by free order by seat_id) x
from cinema c) tmp
where free=1)
where y>=2
order by seat_id;
603问题的核心,在于检测到连续序列,下述查询语句是解决该问题的关键.
-- 第一种
-- id排序值 减去 val分组内id排序值 = 连续相同值的排序值
select c.*,row_number() over(order by seat_id)-row_number() over(partition by free order by seat_id) x from cinema c;
-- 第二种:
select c.*,rownum-row_number() over(partition by free order by rownum) x from cinema c;
这条语句的查询语句各变量的统计结果如下图所示:

其中,A表示行号;B表示free变量分组排序;X表示A和B的差值.
- 两种写法有何区别?
以该例子为例,当seat_id有序排列时,两者没有任何差异.
以下是乱序的结果验证,对cinema选择部分,然后乱序排列,组成表cinema2.结果显示两者结果相同
表cinema2:
| seat_id | free |
|---|---|
| 1 | 1 |
| 2 | 0 |
| 4 | 1 |
| 3 | 1 |
create table cinema2(
seat_id number(3),
free number(3));
insert into cinema2 values(1,1);
insert into cinema2 values(2,0);
insert into cinema2 values(4,1);
insert into cinema2 values(3,1);
以下是两组语句检测的连续序列相同,最终得结果也相同.
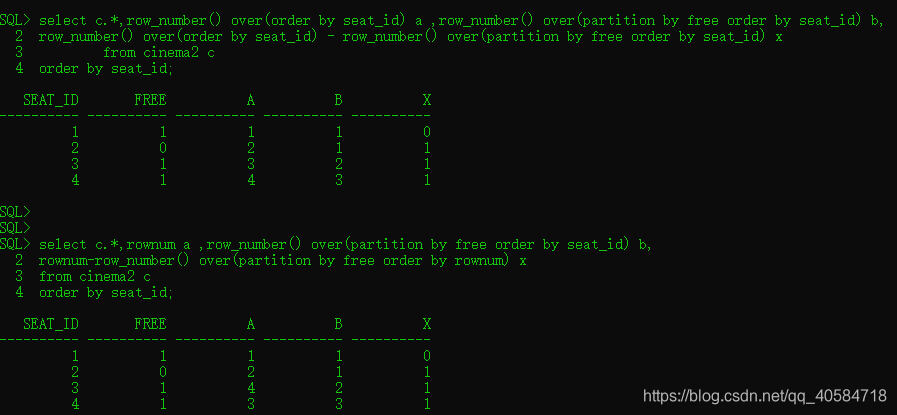
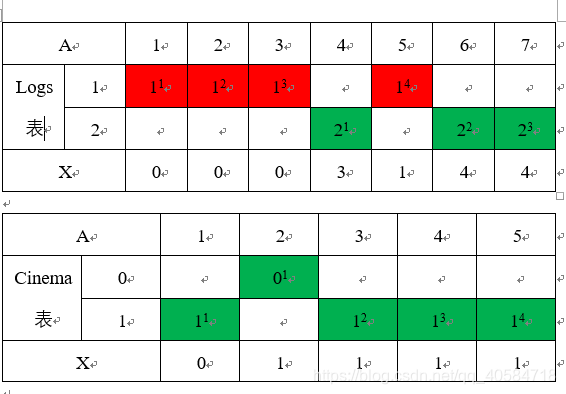
所以接下来选其一解释,为何上述X可以表示连续值呢?
个人理解:可以将free可以看作是列表,A为free中个元素出现的位置排序;X=A-B则表示元素距初始(0)位置的距离,若X出现连续等值说明该序列存在连续,如下图所示.
上述案例的变形
601. 体育馆的人流量 - 力扣(LeetCode)
请编写一个查询语句,找出人流量的高峰期。高峰期时,至少连续三行记录中的人流量不少于100。
/* Write your PL/SQL query statement below */
SELECT a.id, to_char(a.visit_date, 'yyyy-MM-dd') AS visit_date, a.people
FROM (
SELECT id, visit_date, people, COUNT(*) OVER (PARTITION BY a.id - a.rk ) AS allCount
FROM (
SELECT id, visit_date, people, rownum AS rk
FROM stadium
WHERE people >= 100
) a
) a
WHERE a.allCount >= 3
ORDER BY a.id
2.TopN问题
- 2.TopN问题
编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)。
样表:
| Id | Salary |
|---|---|
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
CREATE FUNCTION getNthHighestSalary(N IN NUMBER) RETURN NUMBER IS
result NUMBER;
BEGIN
/* Write your PL/SQL query statement below */
select distinct(salary) into result
from (select salary,dense_rank() over(order by salary desc) rank_ from employee) tmp
where tmp.rank_=N;
RETURN result;
END;
3.分组TopN问题
- 3Employee 表包含所有员工信息,每个员工有其对应的工号 Id,姓名 Name,工资 Salary 和部门编号 DepartmentId 。
样表:
| Id | Name | Salary | DepartmentId |
|---|---|---|---|
| 1 | Joe | 85000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
| 7 | Will | 70000 | 1 |
Department 表包含公司所有部门的信息。
| Id | Name |
|---|---|
| 1 | IT |
| 2 | Sales |
| 编写一个 SQL 查询,找出每个部门获得前三高工资的所有员工 |
--查询语句
/* Write your PL/SQL query statement below */
select de.name department,tmp1.name employee,salary
from (
select e.* ,
dense_rank() over(partition by departmentid order by salary desc) rank_
from employee e ) tmp1,
department de
where tmp1.departmentid=de.id and tmp1.rank_<=3;
4.累加,累减,累乘,累商问题
oracle 下实现累计求和_数据库_iechenyb专栏-CSDN博客
累加方法实现
select t.*,
sum(col) over(partition by target_col order by target_col) result_rename
from table t
当只需要每一组最终的统计结果时,可以加distinct即可.
完整代码:
select distinct t.*,
sum(col) over(partition by target_col order by target_col) result_rename
from table t
累减的实现:
减法通过加法实现.如a-b=a+(-b),所以累减问题,只需要将偶数列变为负值,然后再累加即可.
select distinct t.*,
sum(decode(mod(行号,2),1,col,-col)) over(partition by target_col order by target_col) result_rename
from table(使用子查询,并增加行号) t
累乘,累商问题与累加,累减类似,oracle 下实现累计求和_数据库_iechenyb专栏-CSDN博客 该博客中按照先取对数(ln),然后取指数exp,但是这种情况下容易出现对数真数为0的情况,所以将顺序调换以下可能会更好
上述应用案例及表数据均来自leetcode
参考:
oracle排序使用,很多中函数,不同的效果 - NewLife365 - 博客园
oracle中的排名函数用法 - 随风而行 - 博客园
oracle 下实现累计求和_数据库_iechenyb专栏-CSDN博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号