pod控制器之Horizontal Pod Autoscaler
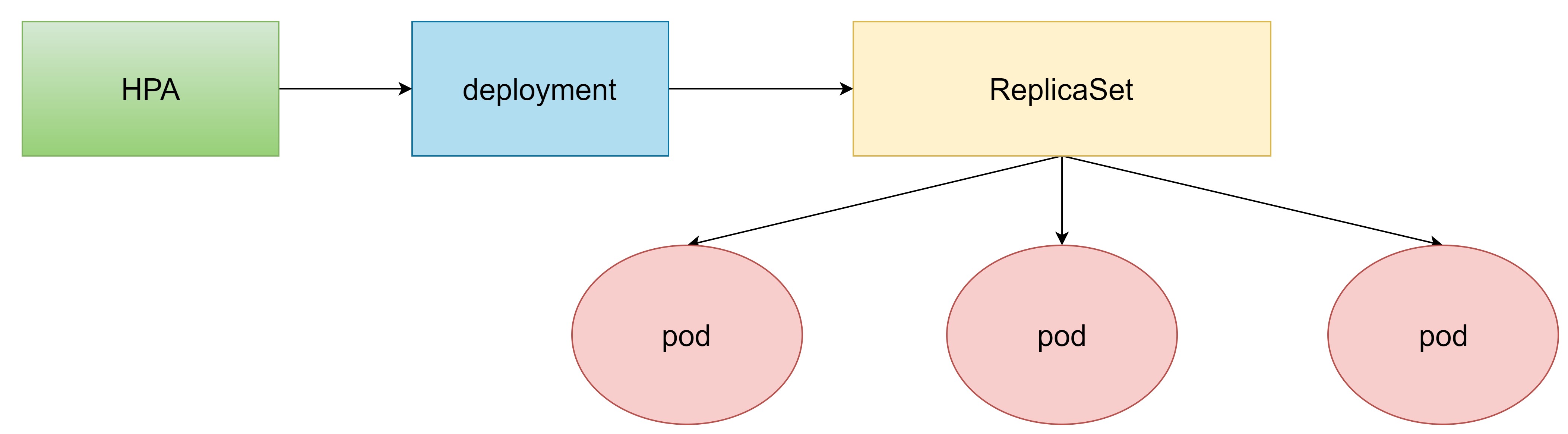
HPA(pod水平自动伸缩)介绍
在前面的学习中,我们可以通过手工执行kubectl scale命令实现pod扩容,但是这显然不符合k8s的定位目标:自动化、智能化。
k8s期望可以通过监测pod的使用情况,实现pod数量的自动调整,于是就产生了HPA这种控制器
HPA可以获取每个pod利用率,然后和HPA中定义的指标进行对比,同时计算出需要伸缩的具体值,最后实现pod数量的调整。
其实HPA与之前的Deployment一样,也属于一种k8s资源对象,它通过追踪分析目标pod的负载变化情况,来确定是否需要针对性地调整目标pod的副本数。
说白了,就相当于你有10个pod在运行,但是pod利用率只有10%,那么HPA会根据指标自动给你删除其他不需要的pod。
安装metrics-server
metrics-server可以用来收集集群中的资源使用情况#安装git[root@master ~]# yum install git -y
#获取metrics-server,注意使用的版本 #注意,由于国内访问github较慢的原因,从github上下载文件可能会失败,建议多试几次或者使用代理 [root@master ~]# git clone -b v0.3.6 https://github.com/kubernetes-incubator/metrics-server
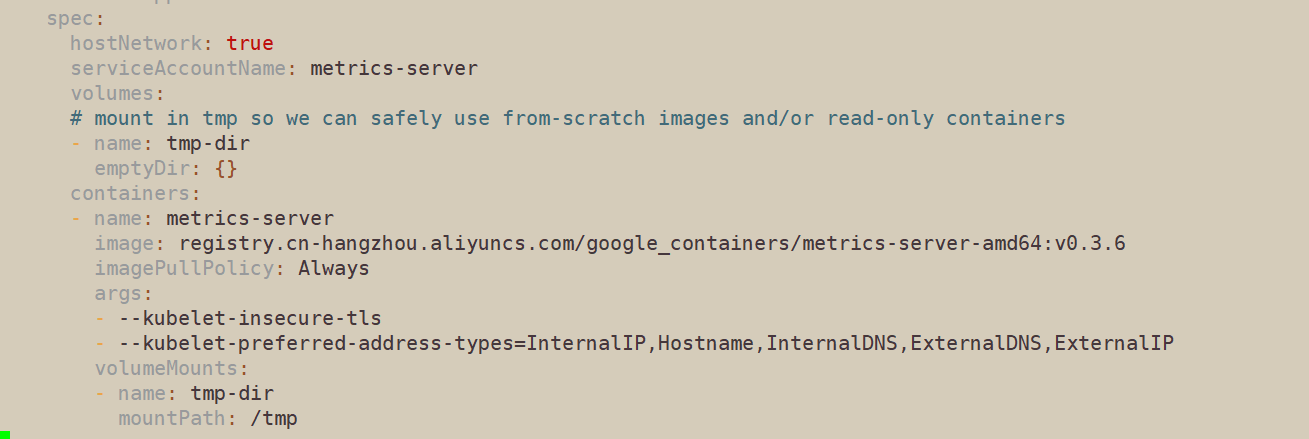
#修改deployment,注意修改的是镜像和初始化参数 [root@master ~]# cd metrics-server/deploy/1.8+/ [root@master 1.8+]# vim metrics-server-deployment.yaml
#添加如下选项 hostNetwork: true registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.6
args:
- --kubelet-insecure-tls - --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
效果如下:
查看安装情况
#安装metrics-server [root@master 1.8+]# kubectl apply -f ./ clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created serviceaccount/metrics-server created deployment.apps/metrics-server created service/metrics-server created clusterrole.rbac.authorization.k8s.io/system:metrics-server created clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created #查看pod [root@master 1.8+]# kubectl get pods -n kube-system metrics-server-6b976979db-mrng6 1/1 Running 0 39s #使用kubectl top node查看资源使用情况 [root@master 1.8+]# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% master 83m 4% 803Mi 46% node1 37m 1% 330Mi 19% node2 <unknown> <unknown> <unknown> <unknown> [root@master 1.8+]# kubectl top pod -n kube-system NAME CPU(cores) MEMORY(bytes) coredns-6955765f44-pxnqm 2m 11Mi coredns-6955765f44-stjjf 2m 12Mi etcd-master 12m 44Mi kube-apiserver-master 28m 356Mi kube-controller-manager-master 13m 39Mi kube-flannel-ds-m8pv6 3m 32Mi kube-flannel-ds-rszpm 2m 31Mi kube-proxy-dz88s 1m 14Mi kube-proxy-smj5t 1m 14Mi kube-scheduler-master 3m 16Mi metrics-server-6b976979db-mrng6 2m 11Mi
至此,metrics-server安装完成
准备deployment和service
使用命令行工具
#创建deployment [root@master 1.8+]# kubectl run nginx --image=nginx:1.17.1 --requests=cpu=100m -n dev #创建service [root@master ~]# kubectl expose deploy nginx --type=NodePort --port=80 -n dev service/nginx exposed #查看 [root@master ~]# kubectl get deploy,pod,svc -n dev NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx 1/1 1 1 5m4s NAME READY STATUS RESTARTS AGE pod/nginx-778cb5fb7b-58jrz 1/1 Running 0 5m4s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/nginx NodePort 10.101.205.0 <none> 80:31313/TCP 28s
部署HPA
创建pc-hpa.yaml
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: pc-hpa namespace: dev spec: minReplicas: 1 #最小pod数量 maxReplicas: 10 #最大pod数量 targetCPUUtilizationPercentage: 3 #cpu使用率指标,意思是当pod使用率达到3%之后就增加新的pod scaleTargetRef: #指定要控制的nginx信息 apiVersion: apps/v1 kind: Deployment name: nginx
使用yaml文件
[root@master ~]# vim pc-hpa.yaml [root@master ~]# kubectl create -f pc-hpa.yaml horizontalpodautoscaler.autoscaling/pc-hpa created [root@master ~]# kubectl get hpa -n dev NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE pc-hpa Deployment/nginx 0%/3% 1 10 1 61s
进行hpa压力测试
新建窗口
新建三个xshell窗口,第一个检测deploy,第二个检测pod,第三个检测hpa
在第二个窗口中输入
[root@master ~]# kubectl get deploy -n dev -w NAME READY UP-TO-DATE AVAILABLE AGE nginx 1/1 1 1 22m
在第三个窗口中输入
[root@master ~]# kubectl get pod -n dev -w NAME READY STATUS RESTARTS AGE nginx-778cb5fb7b-58jrz 1/1 Running 0 23m
在第四个窗口中输入
[root@master ~]# kubectl get hpa -n dev -w NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE pc-hpa Deployment/nginx 0%/3% 1 10 1 6m56s
使用postman进行压力测试
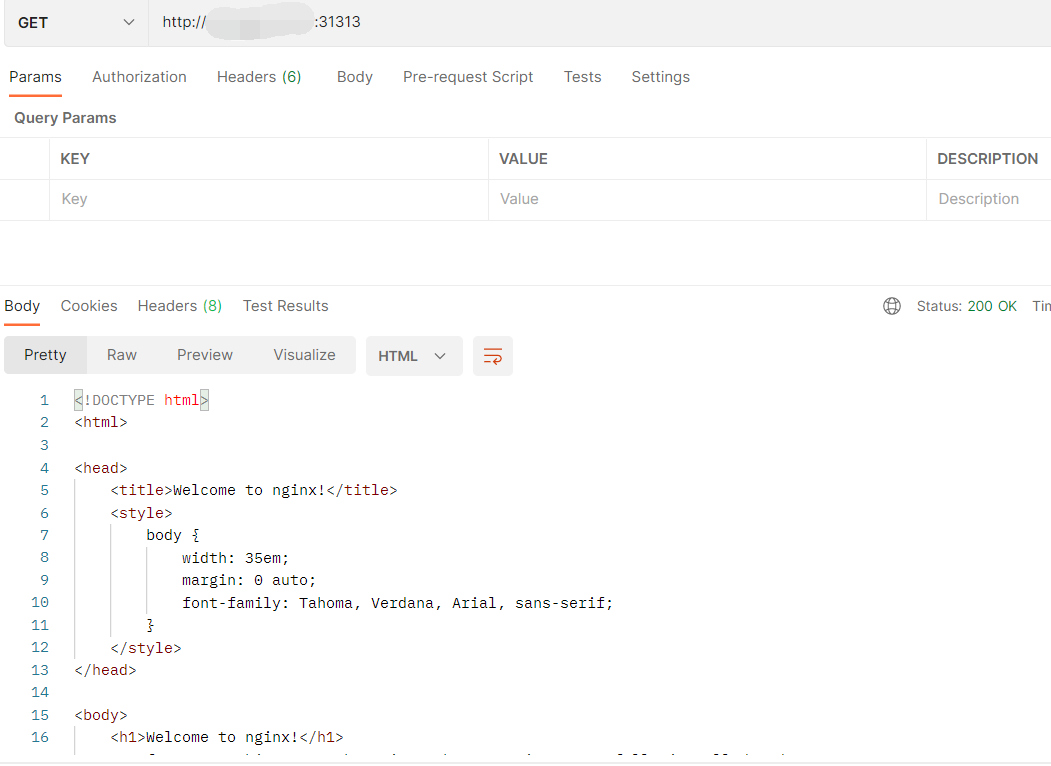
测试访问,使用postman进行访问,发现能够访问通
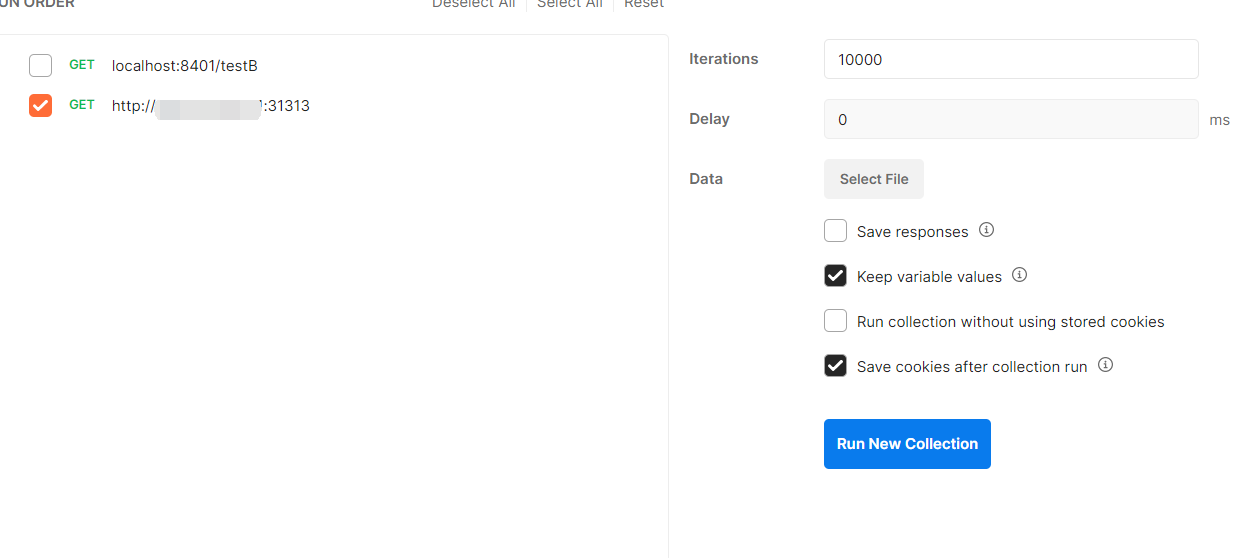
使用postman新建一个runner tab,将要测试的地址拖进去,设置压测的数量为10000,点击运行
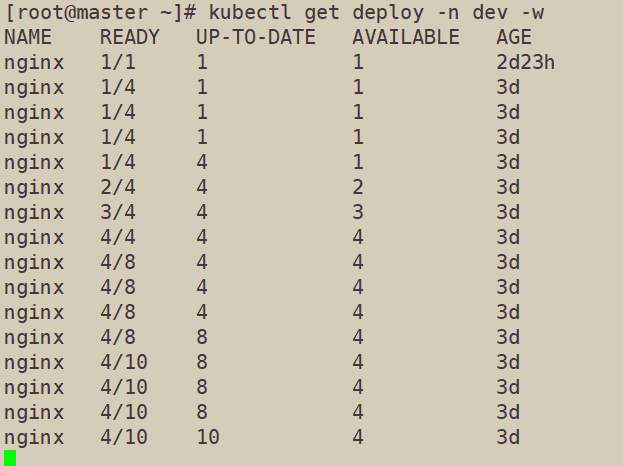
查看三个监控窗口
deploy监控窗口
pod监控窗口
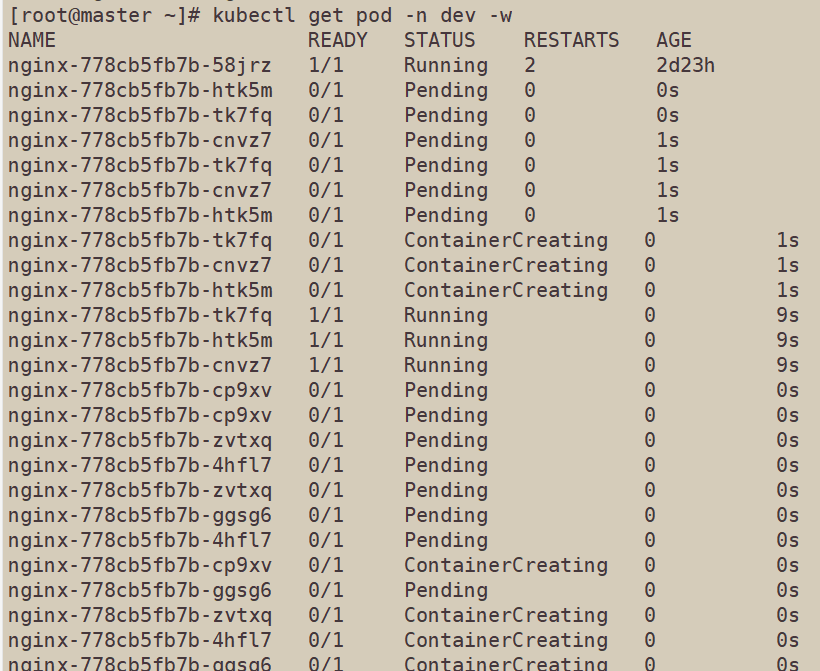
hpa监控窗口

可以发现由于pod使用率的增加,pod在不断地被创建,最后总共创建了10个pod,即我们设置的最大阈值

压力测试结束之后,在等几分钟,再次查看pod的情况,可以发现,大约10分钟之后,由于pod使用率降低,pod在不断地被删除,最后只剩一个pod