第四次作业结对编程
| GIthub GIt地址 | 传送门 |
|---|---|
| 伙伴作业地址 | 传送门 |
| 我的博客地址 | 传送门 |
| 伙伴学号 | 201731062408 |
| 作业连接 | 传送门 |
| 作业目的 | 了解结对编程 |
1.PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| · Planning | · 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 25 | 25 |
| · Development | · 开发 | 890 | 1290 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 90 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 30 | 60 |
| · Coding | · 具体编码 | 600 | 900 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| · Reporting | · 报告 | 30 | 30 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 1025 | 1415 |
2.解题思路
2.1 思路
题目划分了三个阶段,我们就分三次入手分析各个要求的做法
-
基础功能
基础功能是统计有效单词的种类数,频数,按指定顺序输出频数前十的单词。难点和重点是如何统计有效的单词,从文本中剥离出一个个单词。为此我们的方法是使用正则表达式,在正则表达式中限定了条件,可以筛选出以英文字母开头,长度大于等于4,但不可以是数字开头的字符串,对于筛选出来的字符串,再进行统计,计数就不困难了。 -
扩展功能,命令行解析
扩展功能中要求实现一个命令行程序,像Linux的Shell命令一样有着一些参数选项。这一功能的难点在于命令行参数解析。为此,我们原打算通过判断Main··的入口args参数顺序以此比较来判断是否要进行某些功能。但是在实现过程中,发现题目要求命令行的参数有必填参数还有选填参数,参数的顺序还可以不固定。对此我们的方法就不再适用。通过请教同学,查阅资料,我们使用了NuGet包CommandLineParse工具来帮助我们实现命令行参数的解析工作。 -
扩展功能,窗体程序
在实现窗体程序前,我们把第二版的扩展功能的计算核心封装成DLL类库,在窗体程序中引用DLL服务,方便了程序的编写。
2.2 流程图
类图展示
词频统计的方法模块展示
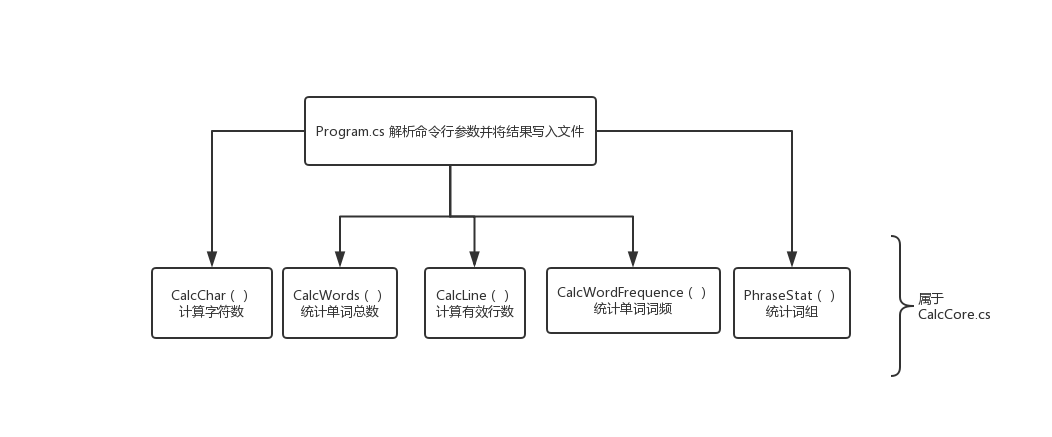
命令行程序的算法流程图
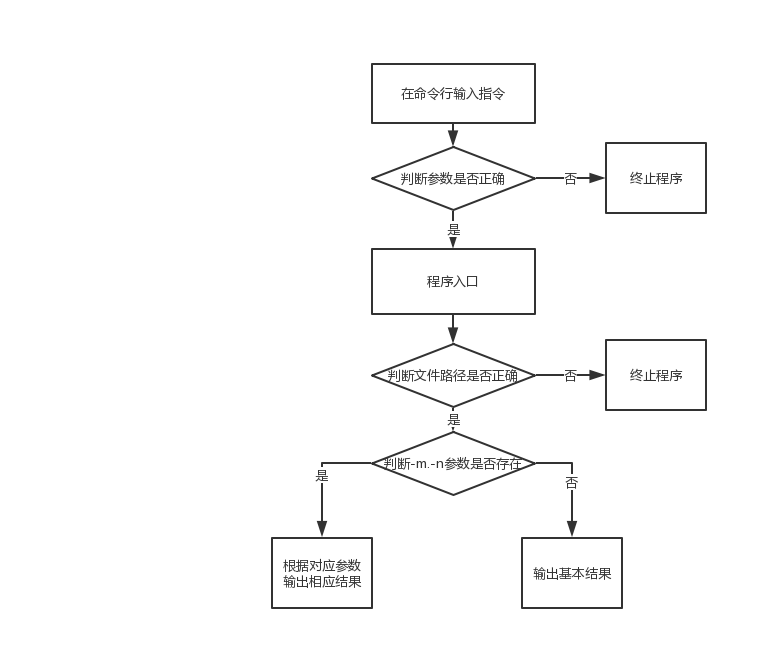
2.3 设计原则的体现
2.3.1 Information Hiding
信息隐藏,在设计计算核心模块的时候,计算行数的方法计算频数的方法等等,都是将所需要用到的变量隐藏,对于不相干的方法无权访问他们。
2.3.2 Loose Coupling
设计中,把计算核心抽离出来,计算方法都写进了计算核心中,与Program类分离开
3.代码规范
- Pascal——所有单词的第一个字母都大写;
- 一个通用的做法是:所有的类型/类/函数名都用Pascal形式,所有的变量都用。
类/类型/变量:名词或组合名词,如Member、ProductInfo等。例如单词数量取名CountOfWord - 函数则用动词或动宾组合词来表示例如计算行数方法取名
CalcLine - 缩进设置
Tab为4空格 - 在复杂条件表达式中使用括号表达优先级
- 花括号采用
{}各占一行的风格 - 在初始化变量时一定赋初值为默认
- 下划线在窗体程序中命名中采用
- 注释,对于计算核心的每个方法都注明方法的目的,参数,为什么这样做
- 错误处理,对于没有包含的操作,都要有配套的异常处理
[参考]
现代软件工程讲义 3 代码规范与代码复审
4.代码互审
在编写完代码后,我和小伙伴一起进行了代码互审。互审工作,分为两步。第一步单独互审,第二步一起复审。起初,我先互审伙伴的代码,他负责把代码做最后的整合,使得代码更加符合要求,符合规范。在互审过程中,我发现他的代码有存在些小问题,提示代码不是很清楚明了,该删除的代码没有删除。大问题倒是没有什么了。接着是两个人一起的代码复审,两个人的眼睛总比一个的尖,在我互审伙伴的代码时还是有一些错误没有发现,两个人的效果确实要比一个人的好。代码互审并不是互相嘲讽对方的错误,而是为了优化代码,就好比对于一个问题有争端,大家进行的讨论应该是如何解决问题而不是谁更具有优越性。
5.性能分析
5.1 代码质量分析
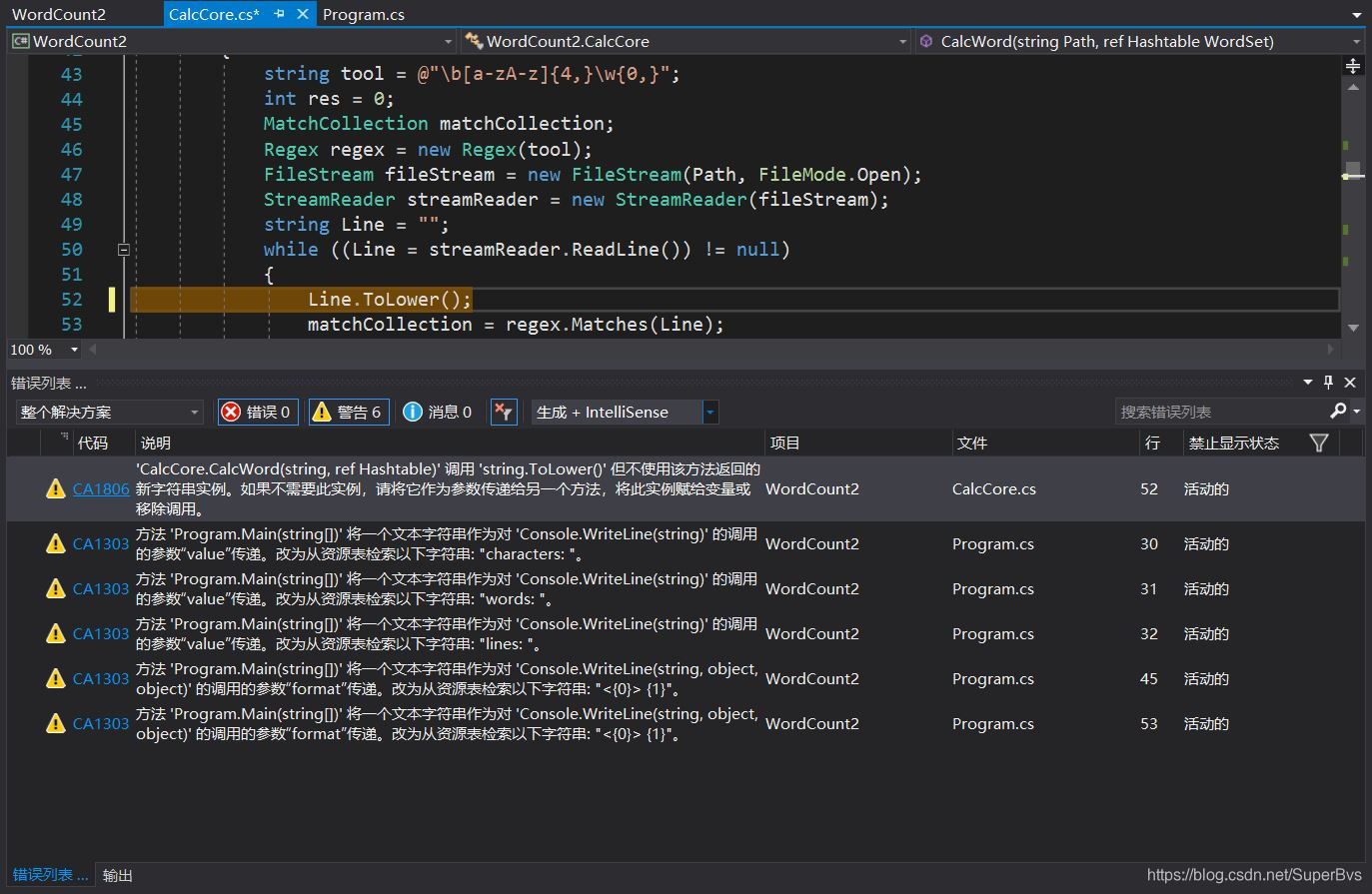
下方两图中第一张图在执行代码质量分析时出现了一些警告级的提示。把Console.WriteLine()语句删除后,警告消除,VS会认为向屏幕输出固定字符串更加规范的方式是通过资源表。
5.2 效能分析
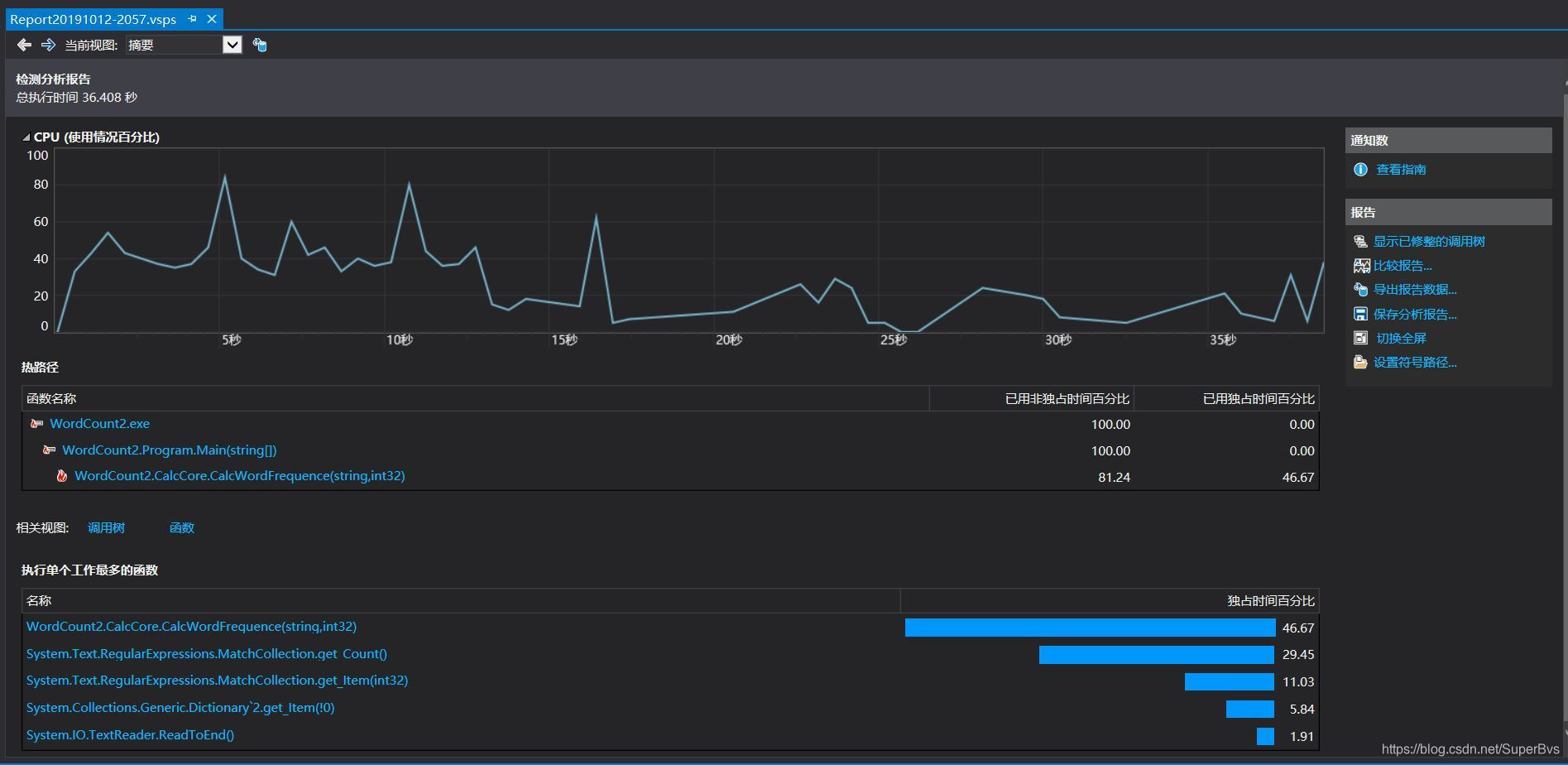
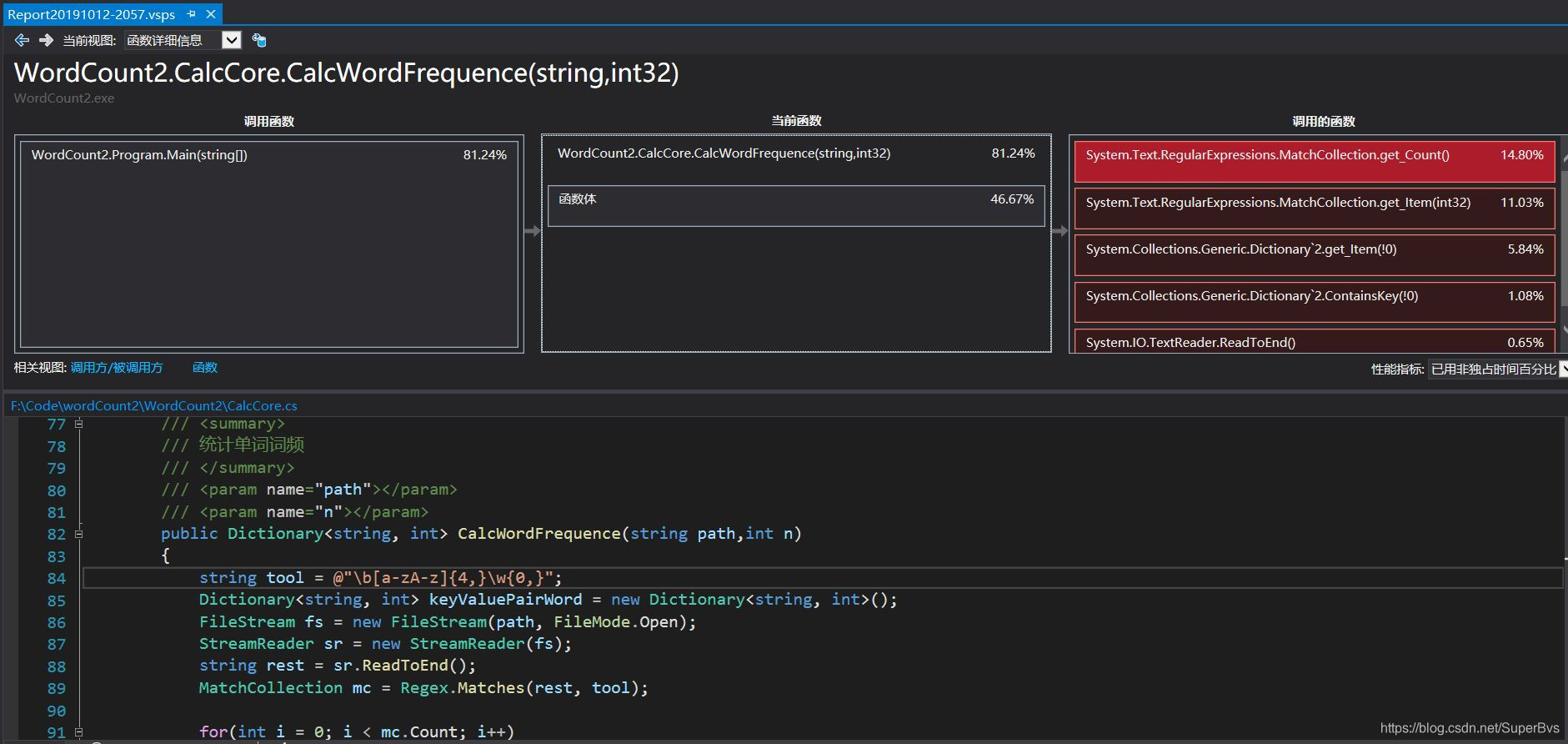
在图中可以很明显的看到,程序中耗时最长In的是词频的统计功能方法。这也是我们的程序瓶颈所在。
而其中比较耗时的是一个正则表达式的操作。占到方法的占用14%
下面是我们改进后的效能,改进的代码会在代码展示中体现。
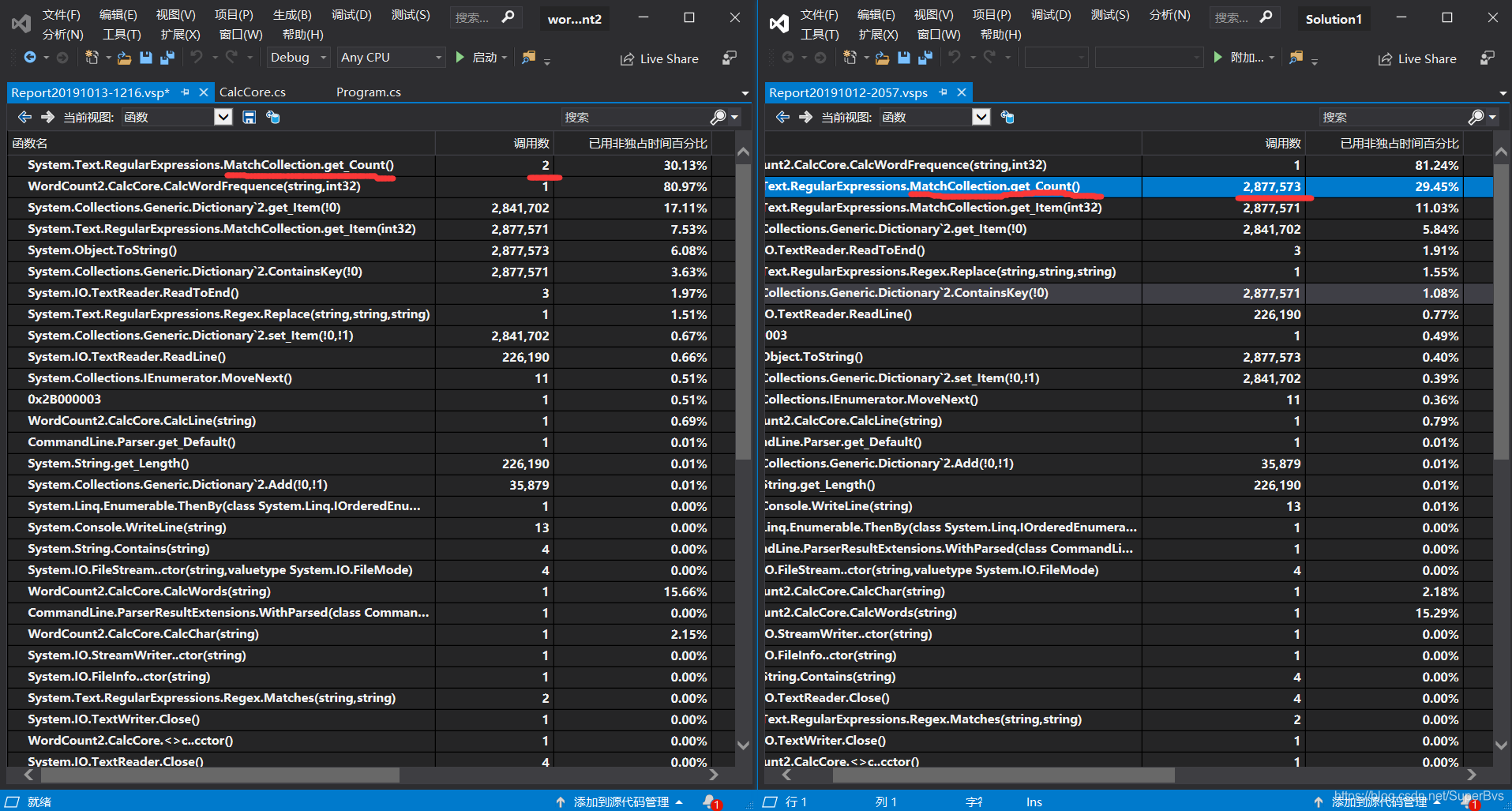
可以看到两次调用次数相差非常大,但占比却一样。
6.单元测试
所编写的测试,单元测试都通过了。
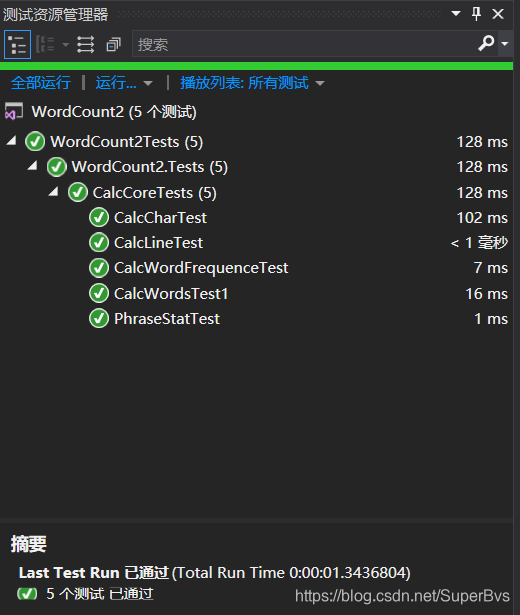
单元测试代码的编写展示
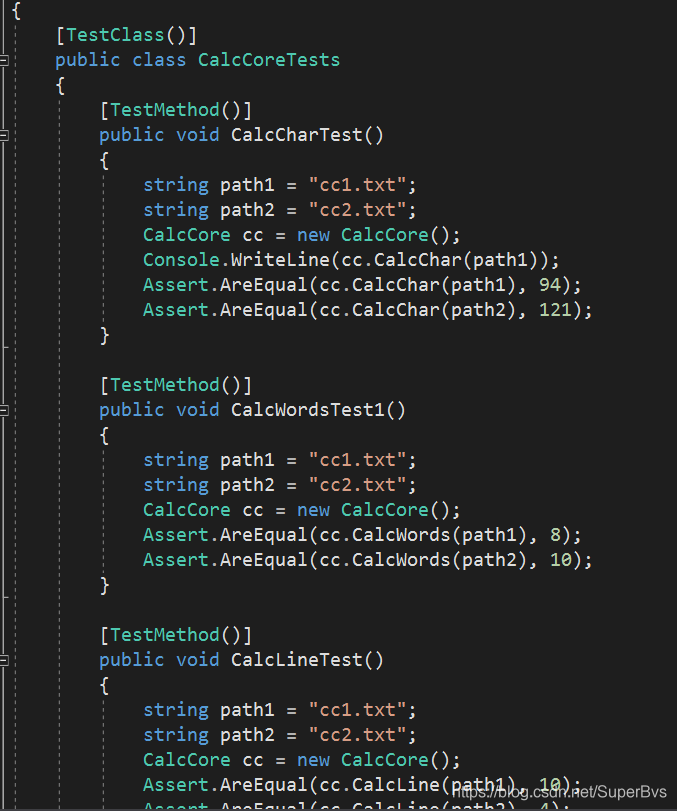
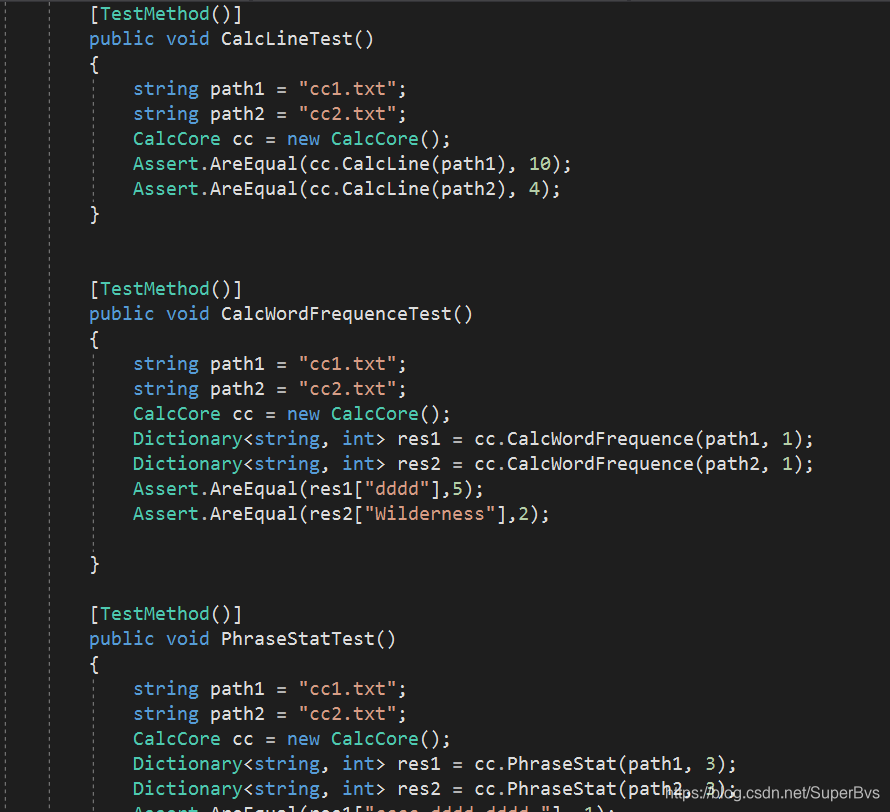
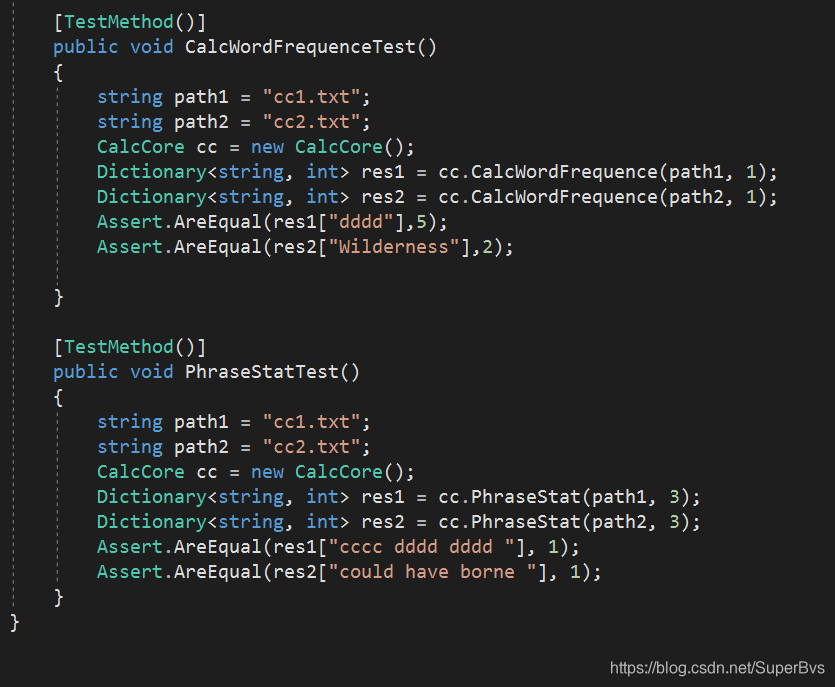
其中用到的测试数据文件

7.结对过程

8.部分代码展示
CalcLine方法
/// <summary>
/// 计算文件中的行数
/// path为文件路径
/// </summary>
/// <param name="path"></param>
/// <returns></returns>
public int CalcLine(string path)
{
int res = 0;
FileStream fileStream = new FileStream(path, FileMode.Open);
StreamReader streamReader = new StreamReader(fileStream);
string Line = "";
while ((Line = streamReader.ReadLine()) != null)
{
if (Line.Length > 0)
res += 1;
}
streamReader.Close();
fileStream.Close();
Console.WriteLine("有效行数:" + res);
return res;
}
向方法传入文件路径,通过创建文件流,读取每一行,如果每行的长度大于0则算是一个有效的行。
CalcWords方法
/// <summary>
/// 统计单词总数
/// </summary>
/// <param name="path"></param>
/// <returns></returns>
public int CalcWords(string path)
{
FileStream fileStream = new FileStream(path, FileMode.Open);
StreamReader streamReader = new StreamReader(fileStream);
string tool = @"\b[a-zA-z]{4,}\w{0,}";
string rest = streamReader.ReadToEnd();
MatchCollection mc = Regex.Matches(rest, tool);
int res = mc.Count;
Console.WriteLine("单词总数:" + res);
streamReader.Close();
fileStream.Close();
return res;
}
设置好正则表达式后,读取文件的每一行,并将其转换为小写。在使用正则表达式与每行字符串匹配,返回正则表达式匹配到的总数就是单词的总数
CalcChar方法
/// <summary>
/// 统计字符数
/// </summary>
/// <param name="path"></param>
/// <returns></returns>
public int CalcChar(string path)
{
int charNum;
string rest, str;
FileStream fs = new FileStream(path, FileMode.Open);
StreamReader sr = new StreamReader(fs);
str = sr.ReadToEnd();
string pattern = @"[\u4e00-\u9fa5]";
rest = Regex.Replace(str, pattern, "");
charNum = rest.Length;
sr.Close();
fs.Close();
Console.WriteLine("字符总数:" + charNum);
return charNum;
}
传入文件路径,设置好正则表达式,匹配除中文外的字符。同样返回匹配的的字符串的长度总和。
CalcWordFrequence方法
/// <summary>
/// 统计单词词频
/// </summary>
/// <param name="path"></param>
/// <param name="n"></param>
public Dictionary<string, int> CalcWordFrequence(string path,int n)
{
string tool = @"\b[a-zA-z]{4,}\w{0,}";
Dictionary<string, int> keyValuePairWord = new Dictionary<string, int>();
FileStream fs = new FileStream(path, FileMode.Open);
StreamReader sr = new StreamReader(fs);
string rest = sr.ReadToEnd();
MatchCollection mc = Regex.Matches(rest, tool);
for(int i = 0; i < mc.Count; i++)
{
string tmp = "";
tmp = mc[i].ToString();
if (!keyValuePairWord.ContainsKey(tmp))
{
keyValuePairWord.Add(tmp, 1);
}
else
{
keyValuePairWord[tmp]++;
}
}
//if (n > keyValuePairWord.Count)
//{
// Console.WriteLine("参数大于总词数");
// return null;
//}
var res = from pair in keyValuePairWord
orderby pair.Value descending, pair.Key ascending
select pair;
Dictionary<string, int> result = new Dictionary<string, int>();
int j = 0;
foreach (var i in res)
{
if (j == n)
{
break;
}
result.Add(i.Key, i.Value);
j++;
Console.WriteLine(i.Key + ":" + i.Value);
}
sr.Close();
fs.Close();
return result;
}
传入路径和输出的单词数n,同样的通过正则表达式匹配,将匹配得到的字符串保存,到字典中,若字符串在字典中首次出现则将其value设置为1,否则value++返回一个字典,其中保存了所有符合要求的单词。使用Linq语句可以使得字典中元素可以自定义排序保存,所以我们按照总数降序的同时字典序升序排序。
PhraseStat方法
/// <summary>
/// 统计词组
/// </summary>
/// <param name="path"></param>
/// <param name="m"></param>
public Dictionary<string, int> PhraseStat(string path, int m)
{
Dictionary<string, int> keyValuesPairPhrase = new Dictionary<string, int>();
string tool1 = @"\b[a-zA-z]\w{0,}";
string tool2 = @"\b[a-zA-z]{4,}\w{0,}";
FileStream fs = new FileStream(path, FileMode.Open);
StreamReader sr = new StreamReader(fs);
//string rest = sr.ReadToEnd();
string Line = "";
while ((Line = sr.ReadLine()) != null)
{
MatchCollection mc = Regex.Matches(Line, tool1);
for (int i = 0; i < mc.Count - m + 1; i++)
{
string tmp = "";
for (int j = i; j < i + m; j++)
{
if (mc[j].Length < 4)
{
goto tick;
}
tmp += mc[j].ToString() + " ";
}
if (!keyValuesPairPhrase.ContainsKey(tmp))
{
keyValuesPairPhrase.Add(tmp, 1);
}
else
{
keyValuesPairPhrase[tmp]++;
}
tick:;
}
}
Dictionary<string, int> result = new Dictionary<string, int>();
foreach (var i in keyValuesPairPhrase)
{
Console.WriteLine(i.Key + ":" + i.Value);
result.Add(i.Key, i.Value);
}
sr.Close();
fs.Close();
return result;
}
和词频统计大同小异,只不过,在此基础上,统计连续m个符合要求的单词字符串,并无本质上的区别。
8.异常处理
8.1命令行解析异常处理

在键入命令行参数时,如果键入的参数出现异常,会提示参数错误并结束程序
8.2 文件读入异常处理
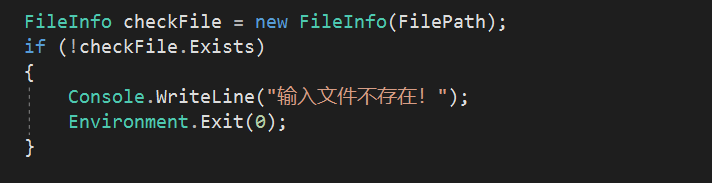
执行任何计算方法之前都会检查输入的路径是否正确,该文件是否存在。如果不存在该文件,会提示输入文件不存在并退出程序。
8.3 窗体参数检查

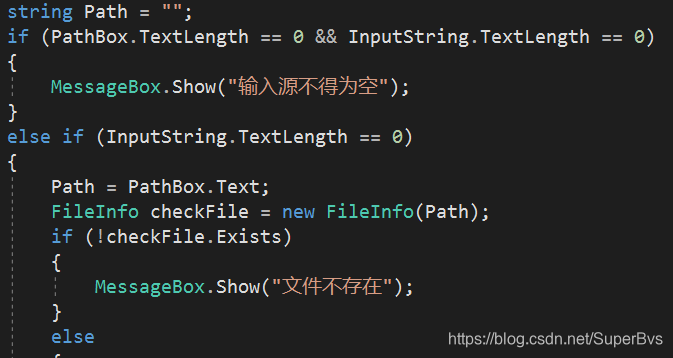
和命令行程序差不多,窗体程序也会检查路径是否正确,文件是否存在。在扩展计算中会检查扩展参数是否正确,是否是一个合法的参数。
9.总结
通过这次的结对编程,我更加熟悉了C#,作为编程工具的一些特性。学习了字典的使用,哈希表的使用,学习了LINQ语句。更重要的是体会到一种1+1>2的编程体验。一个人在编代码的时候可能无法高效率的发现一些错误,而当两个人在一起进行审查代码时,发现错误就相对很容易。其次就是相互学习,结对编程可以学习对方的优点,看到自己的缺点,更好的改进自己。
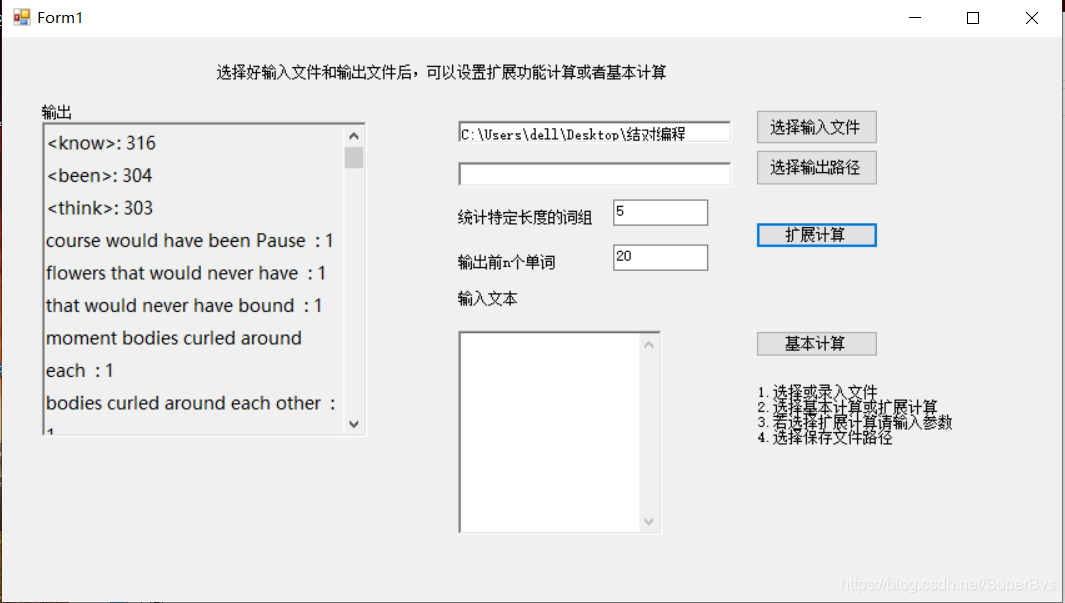
10. 窗体程序展示
[参考资料]
CommandLineParse

 浙公网安备 33010602011771号
浙公网安备 33010602011771号