笔试错题记录
一、Linux相关
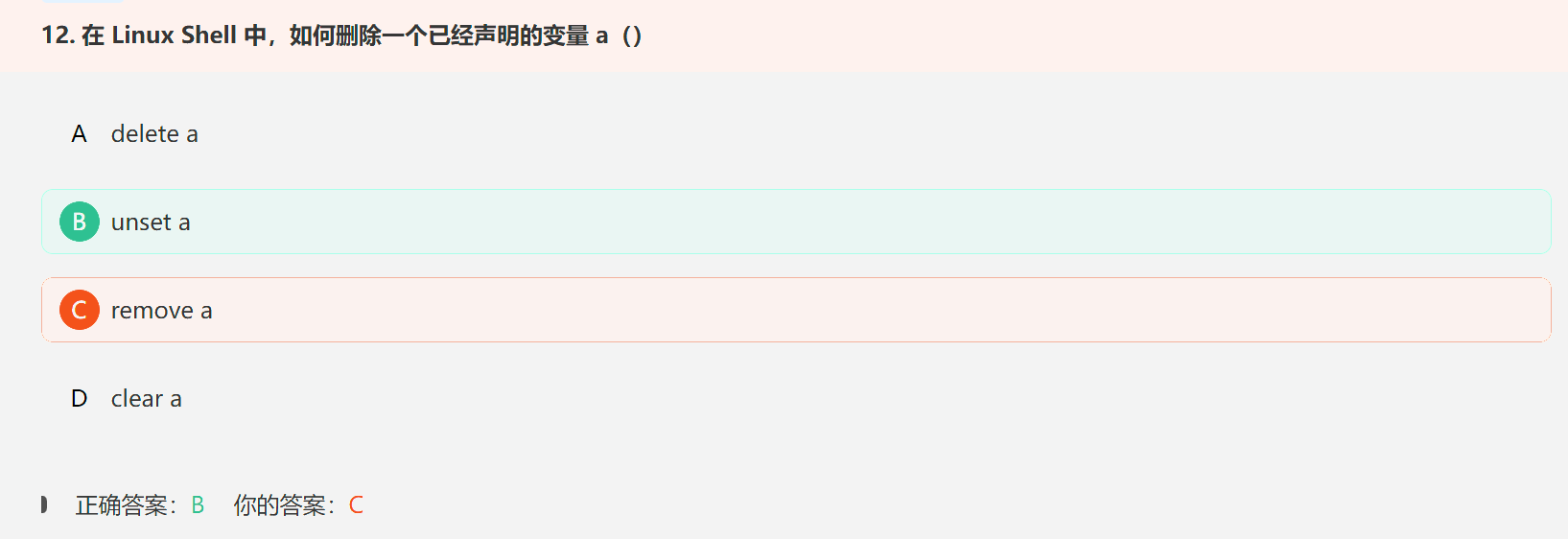
1. Linux删除变量的命令——unset
2. Linux进程地址空间中的代码段和数据段
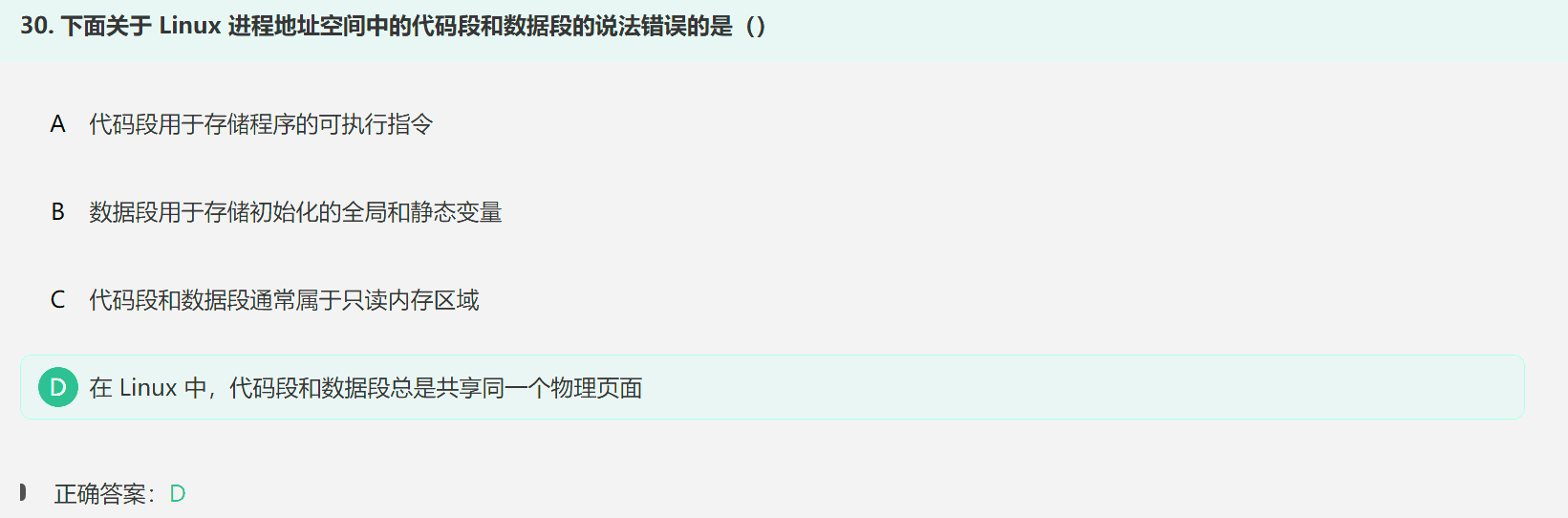
代码段:称为代码区或只读段,用来存储程序的机器指令,包括可执行代码和只读数据,代码段通常是只读的,程序在运行时无法修改这部分内容,
同时这一段通常又是共享的,即多个进程可以将相同的可执行文件映射到它们各自的地址空间中,从而节省内存;
数据段 :用来存储程序中已初始化的全局变量和静态变量,以及动态分配的内存空间(堆),数据段中的变量在程序运行过程中可以被修改,
数据段通常是每个进程私有的,每个进程都有自己独立的数据段副本;
本题CD都是错的,代码段只读,数据段是可写的;
除了代码段和数据段以外,Linux进程地址空间还包括:
堆:用于动态内存分配,比如使用malloc()和free()函数分配和释放内存;
栈:用于函数调用和局部变量存储;
内核空间:用于操作系统内核执行和管理;
内存映射段:包括了共享库、映射文件等,允许将文件内容映射到进程的地址空间,以便直接访问文件内容;
3. Linux目录和文件

在Linux中,有许多重要的目录,每个目录都有其特定的用途。以下是一些在Linux系统中常见的重要目录:
-
/bin:binary
- 存放系统的基本命令(binary),如ls、cp、mv等。
-
/boot:启动
- 包含启动Linux时所需的文件,包括内核文件和引导加载程序(boot loader)的配置文件。
-
/dev:device设备
- 包含设备文件(device files),用于与系统中的设备进行交互。
-
/etc:et cetera配置文件
- 存放系统的配置文件,包括各种软件的配置文件以及系统全局配置文件。
-
/home:
- 存放用户的主目录,每个用户通常拥有一个子目录,用于存储个人文件和设置。
-
/lib:library
- 存放系统所需的共享库文件(libraries)。
-
/media:媒体
- 用于挂载可移动媒体设备,如USB闪存驱动器、光盘等。
-
/mnt:mount挂载
- 用于临时挂载其他文件系统,通常用于管理员手动挂载其他设备。
-
/opt:optional可选
- 用于存放可选的附加软件包。
-
/proc:process进程
- 这是一个虚拟文件系统,提供有关系统内核和运行中进程的信息。
-
/root:
- root用户的主目录。
-
/sbin:system bin
- 存放系统管理员使用的系统管理工具,如ifconfig、fdisk等。
-
/tmp:temporary
- 用于存放临时文件的目录。
-
/usr:user
- 包含了系统中的大部分用户应用程序和文件,类似于Windows中的Program Files目录。
-
/var:
- 包含经常变化的文件,如日志文件、临时文件、邮件等。
D错,因为在Linux系统中,文件的类型并不是通过文件扩展名(文件名中的后缀)来确定的,而是通过文件的权限和内容来确定的。Linux系统并不像Windows系统那样依赖于文件扩展名来识别文件类型。
在Linux中,文件类型主要通过以下几种方式来确定:
-
文件权限:文件的权限标志(如读、写、执行)可以确定文件的类型,比如普通文件、目录、链接文件等。
-
文件头部信息:有些文件包含特定的头部信息,可以通过这些信息确定文件的类型,比如二进制可执行文件、脚本文件等。
-
文件命令:使用
file命令可以查看文件的类型信息,该命令会根据文件内容进行检测并给出文件类型的推测结果。
虽然在Linux系统中并不要求为不同类型的文件使用特定的文件扩展名,但在实践中,一些应用程序和用户习惯仍然会根据文件类型使用一些约定俗成的文件扩展名。例如,用 .txt 表示文本文件,.sh 表示Shell脚本等。但这些文件扩展名在Linux系统中并不是必须的,系统并不依赖于它们来确定文件类型。
4. cron命令
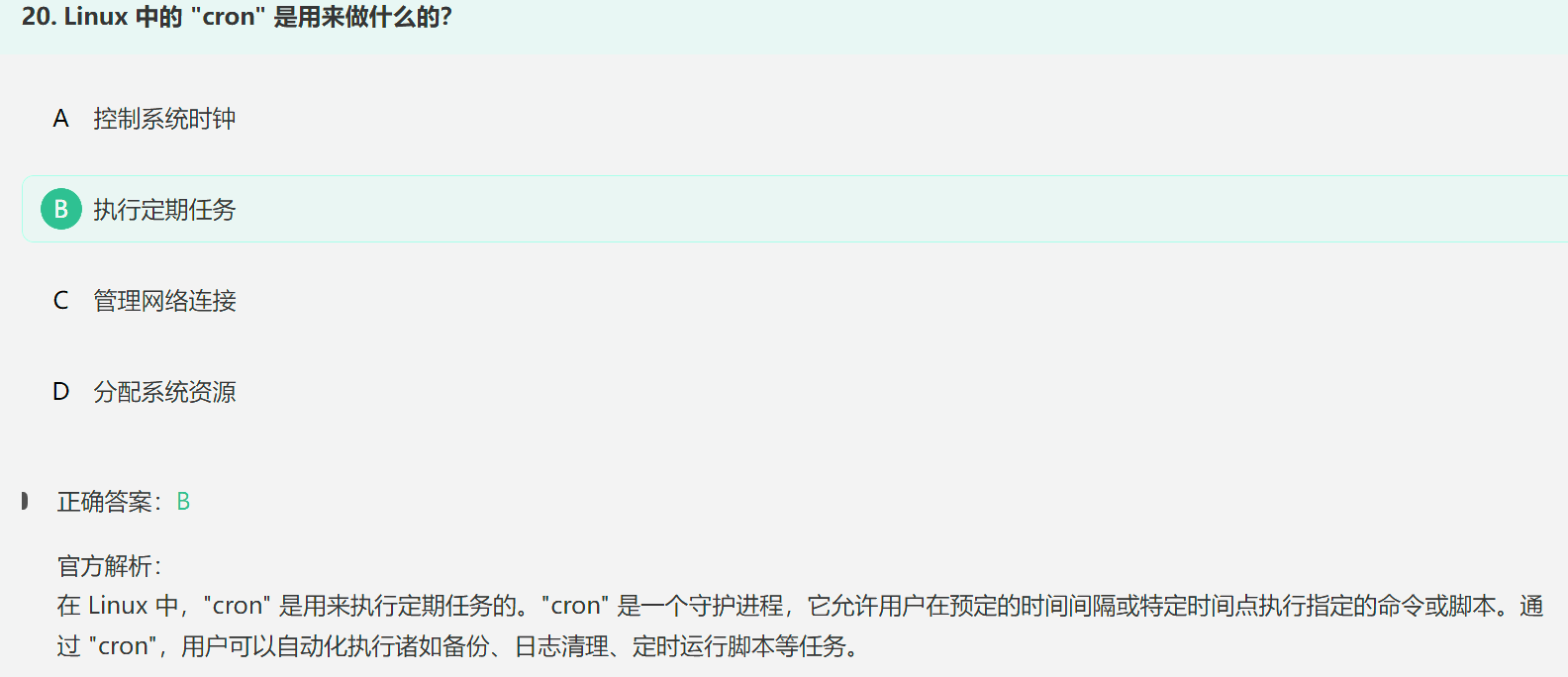
cron是chronograph(时间图表)的简写,
控制系统时钟:date;
管理网络连接:在 Linux 中,管理网络连接的命令有很多,以下是一些常用的命令:
-
ifconfig:显示和配置网络接口的命令。可以用来查看当前网络接口的配置信息,以及配置 IP 地址、子网掩码等。
-
ip:iproute2 工具集中的命令,提供了更多功能,包括查看和配置路由表、网络设备等。
- route:用于显示和设置路由表信息,可以查看当前系统的路由表,并且添加或删除路由条目。
分配系统资源:在 Linux 中,可以使用以下命令来分配系统资源:
-
nice 和 renice:这两个命令用于设置进程的优先级。
nice命令用于启动新进程并设置其优先级,renice用于修改正在运行进程的优先级。 -
ulimit:这个命令用于限制用户对系统资源的访问,包括 CPU 时间、文件大小、打开文件数等。通过
ulimit可以限制用户进程的资源使用。 -
chrt:这个命令用于设置进程的调度策略和优先级,可以将进程设置为实时进程或其他调度策略
5. Linux /etc目录下常见文件及其作用
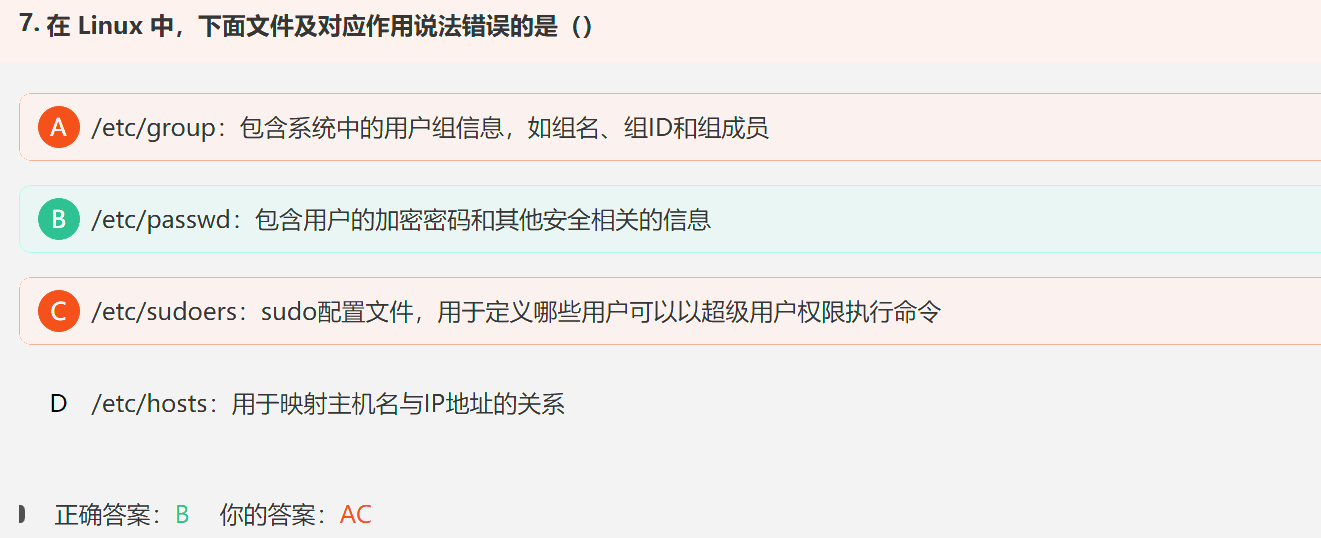
在 Linux 系统中,/etc 目录包含了许多系统的配置文件和目录。以下是一些 /etc 目录下常见文件及其作用:
-
/etc/passwd:包含了系统所有用户的基本信息,如用户名、用户 ID、主目录、默认 shell 等。
-
/etc/group:包含了用户组的信息,包括组名、组 ID、组内成员等。
-
/etc/shadow:存储加密后的用户密码以及密码过期信息,只有 root 用户可读。
-
/etc/hosts:用于配置主机名与 IP 地址的对应关系,可以手动添加主机名和 IP 地址的映射关系。
-
/etc/resolv.conf:包含了 DNS 解析配置信息,指定了域名服务器的 IP 地址以及搜索域等。
-
/etc/fstab:描述了文件系统的挂载信息,包括哪些文件系统应该在启动时挂载、挂载的位置、挂载选项等。
-
/etc/hostname:存储了计算机的主机名。
-
/etc/ssh/sshd_config:SSH 服务器的配置文件,可以设置 SSH 服务的参数、安全策略等。
-
/etc/sudoers:包含了 sudo 命令的配置信息,定义了哪些用户可以以超级用户的权限执行特定命令。
-
/etc/crontab:用于配置定时任务,包括指定定时运行的命令或脚本。
B错,因为/passwd存储的是所有用户的基本信息,/shadow存储的才是加密后的密码;
6. Linux页面交换——即页面置换
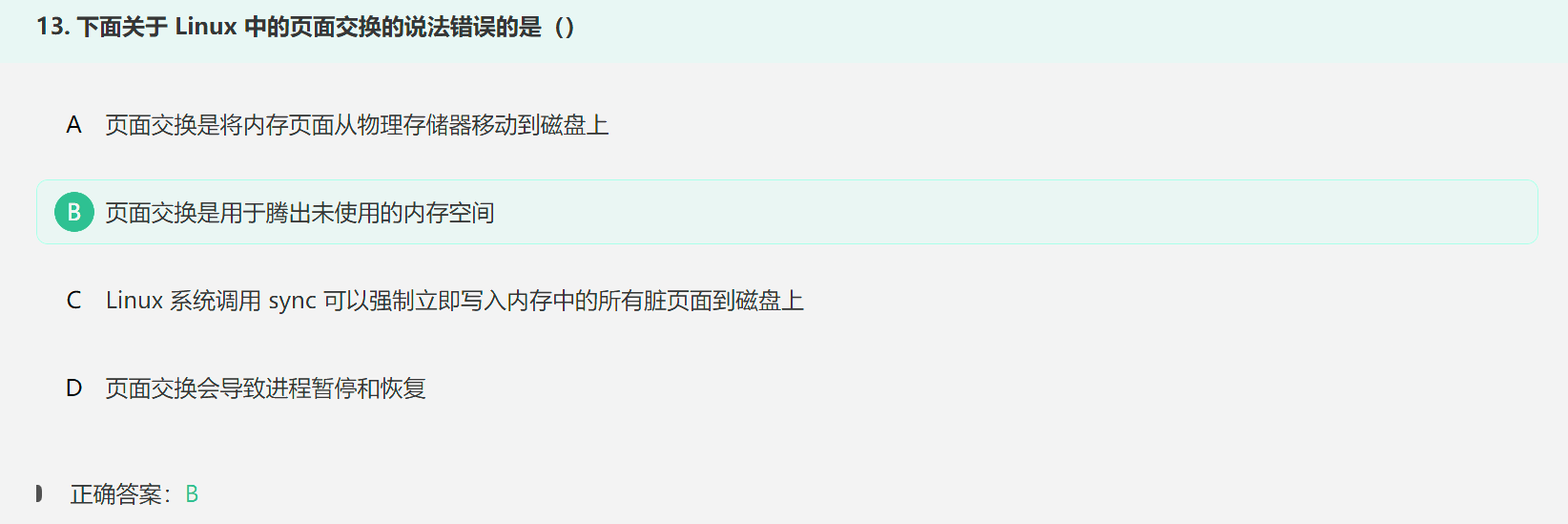
在 Linux 系统中,页面交换(Page Swapping)是指将内存中暂时不活跃或不频繁使用的页面(页)移动到磁盘上的交换空间(Swap Space)中,以释放内存供其他程序使用。当系统内存不足时,Linux 内核会通过页面交换机制来管理内存,并确保系统的正常运行。
sync 命令在 Linux 系统中用于强制将所有未写入的缓冲区数据(也就是脏页面)立即写入磁盘,确保文件系统的一致性;
二、MySQL
1. 各种类型的索引
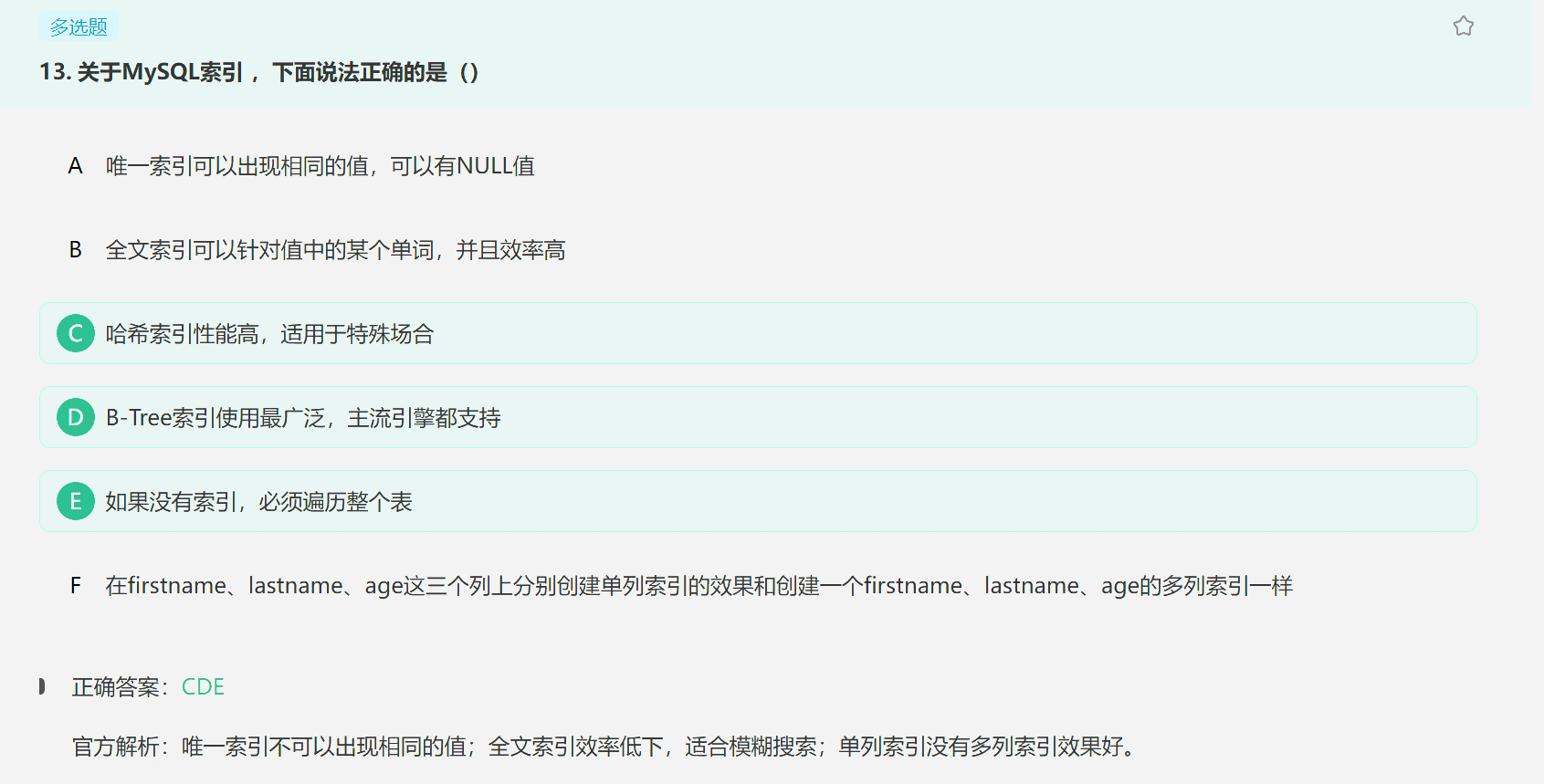
全文索引效率低下,只适合模糊搜索;
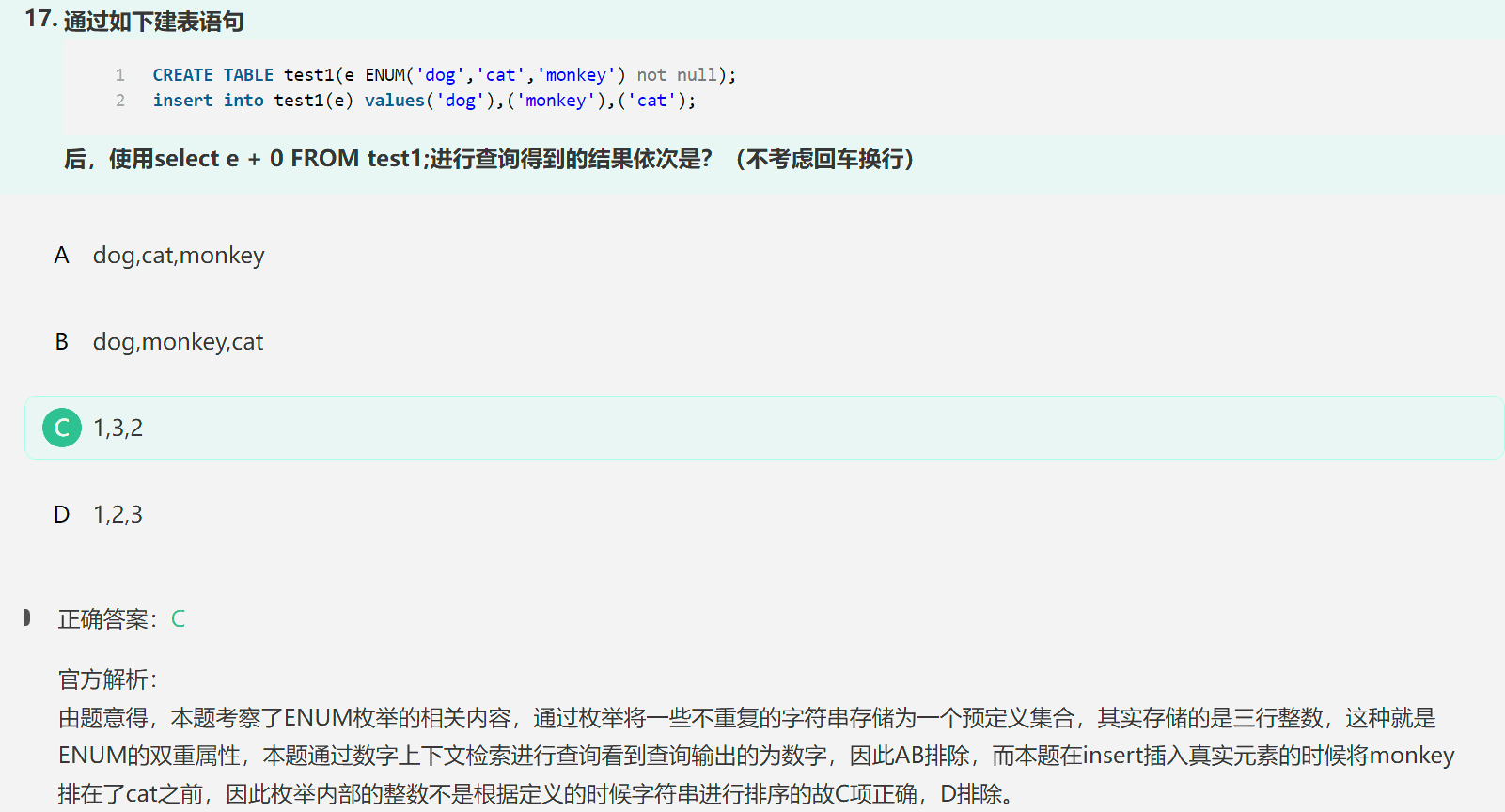
2. MySQL中的枚举类型
3. MySQL的存储过程

官方解析:在MySQL存储过程中,可以在存储过程名后使用括号来声明参数,例如:
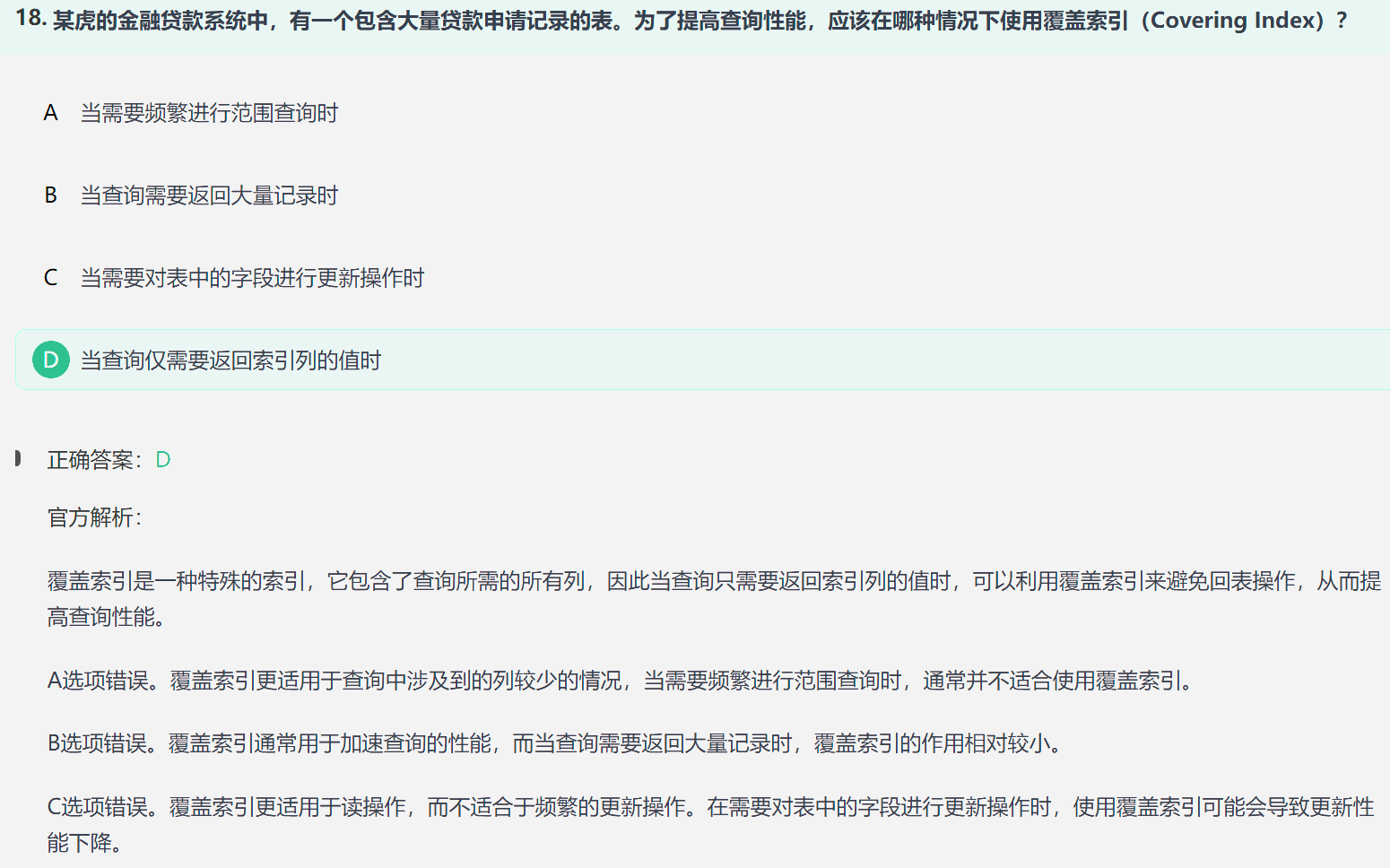
4. 覆盖索引
5. 正则表达式
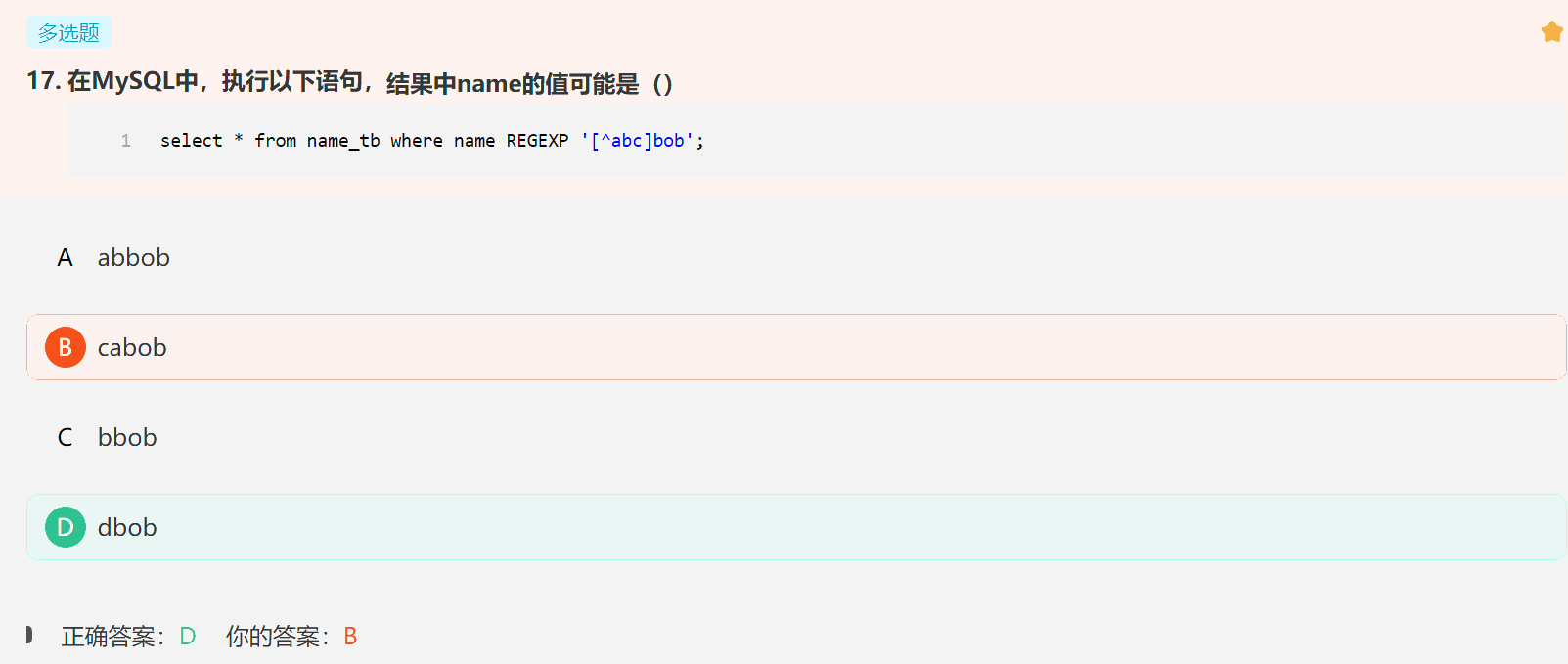
正则表达式 [^abc]bob 的含义是:
[^abc]:匹配除了 a、b、c 之外的任意一个字符。bob:紧跟着上面定义的字符之后是 "bob"。
因此,这个查询的意思是选择 name 列的值中,第一个字符不是 a、b、c,而紧随其后的三个字符是 "bob" 的所有记录。
6. 散列索引
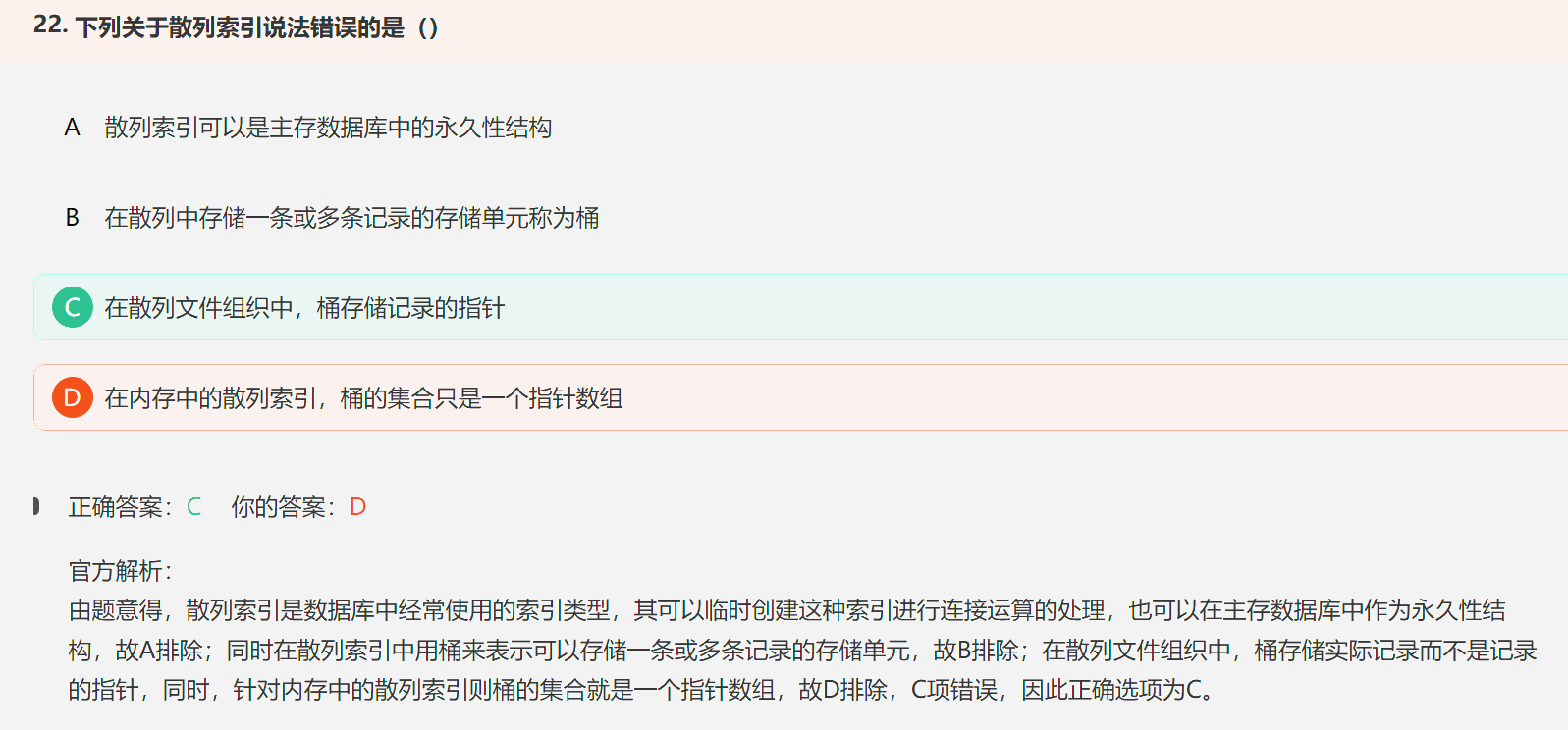
散列索引(Hash Index)是数据库中一种特殊的索引类型,用于加快对特定列的查找速度。与传统的 B 树索引不同,散列索引将列值通过哈希函数映射为索引键,然后在哈希表中存储索引键与数据位置的对应关系,以实现快速的数据检索。
以下是散列索引的一些特点和注意事项:
-
快速查找速度: 散列索引在理想情况下可以实现 O(1) 的查找时间复杂度,即不论数据量大小,查询操作都可以在常量时间内完成。
-
适合等值查询: 散列索引主要适用于等值查询(例如
=),对于范围查询或排序操作并不适合。 -
哈希冲突: 由于哈希函数的映射范围有限,可能会出现不同列值经过哈希函数得到相同的散列值,这种情况称为哈希冲突。散列索引的实现需要解决哈希冲突的问题,常见的解决方法包括链地址法和开放寻址法等。
-
不支持前缀查找: 与 B 树索引不同,散列索引不支持前缀查找,即不能通过索引查找列值的前缀部分。
-
内存消耗: 散列索引通常需要较大的内存空间来存储哈希表,因此在内存资源受限或数据量较大时,需要谨慎使用散列索引。
在实际应用中,散列索引通常用于对数据进行快速的唯一性检查或快速等值查询,而对于范围查询或排序等操作,则更适合使用 B 树索引等其他类型的索引。数据库管理系统(DBMS)会根据实际情况和索引设计原则来选择合适的索引类型以提高查询效率。
在散列文件组织中,桶存储实际记录而不是记录的指针,同时,针对内存中的散列索引则桶的集合就是一个指针数组,故C错D对;
三、设计模式
1. 浏览器的事件模型使用了哪种设计模式——发布者/订阅者模式
浏览器的事件模型通常使用了观察者模式(Observer Pattern),也被称为发布-订阅模式(Publish-Subscribe Pattern)。
在浏览器中,各种事件(如鼠标点击、键盘输入、页面加载完成等)都可以被看作是事件源,而注册在这些事件上的事件处理程序则可以看作是观察者。当事件发生时,事件源会通知所有注册在其上的事件处理程序,从而触发相应的操作。
原型模式是一种创建型设计模式,其主要思想是通过复制现有对象来生成新对象,而不是通过实例化类来创建新对象。通过这种方式可以避免使用构造函数来创建新对象,从而提高性能并减少不必要的资源消耗。
在原型模式中,通常会定义一个抽象的原型接口,包含一个用于复制自身的方法。具体的对象类将实现这个原型接口,并实现复制自身的方法,从而使得可以基于现有对象来创建新的对象实例。
应用场景:
- 当创建新对象的成本较大,而且新对象与现有对象相似度很高时,可以考虑使用原型模式。例如,在某些场景下,从数据库或文件系统中读取数据来创建对象的开销较大,这时可以利用已有对象进行复制来创建新对象。
- 在需要动态生成对象的场景下,原型模式也很有用。例如,在一些图形编辑软件中,用户可以通过复制现有图形对象来创建新的图形对象,这就是原型模式的应用之一。
- 原型模式还可以用于对象的克隆,当需要生成一系列相似对象时,可以通过原型模式来快速生成这些对象的副本。
总的来说,原型模式适用于对象的创建成本较大,而且新对象与现有对象相似度高的情况下,可以通过复制现有对象来创建新对象,从而提高效率和降低资源消耗。
中介者模式是一种行为型设计模式,旨在减少对象之间的直接通信,通过引入一个中介者对象来协调各对象之间的交互。这种模式有助于降低对象之间的耦合度,使系统更易于维护和扩展。
在中介者模式中,对象之间不再直接相互调用,而是通过一个中介者对象来进行通信。当一个对象发生改变时,它不需要知道其他对象的存在,只需将这个改变通知给中介者对象,由中介者对象负责处理后续的交互逻辑。这样可以避免对象之间的紧耦合关系,提高系统的灵活性和可维护性。
应用场景:
- 当系统中对象之间存在复杂的交互关系,导致对象之间相互依赖过多、耦合度较高时,可以考虑使用中介者模式。通过引入中介者对象,可以有效地管理对象之间的通信,减少彼此之间的直接依赖。
- 在图形用户界面(GUI)开发中,中介者模式也经常被应用。例如,在一个包含多个组件的窗体中,各组件之间的交互可能较为复杂,这时可以引入一个中介者对象来统一管理组件之间的通信。
- 在多人协作系统中,如聊天室或在线游戏中,中介者模式可以用来管理用户之间的消息传递和交互,确保各用户之间的通信能够顺畅进行。
- 在分布式系统中,中介者模式也可以用于解耦不同节点之间的通信,通过中介者节点来协调各节点之间的消息传递。
总的来说,中介者模式适用于需要减少对象之间直接耦合、集中管理对象之间交互的场景,可以提高系统的灵活性和可维护性。
2. E-R图
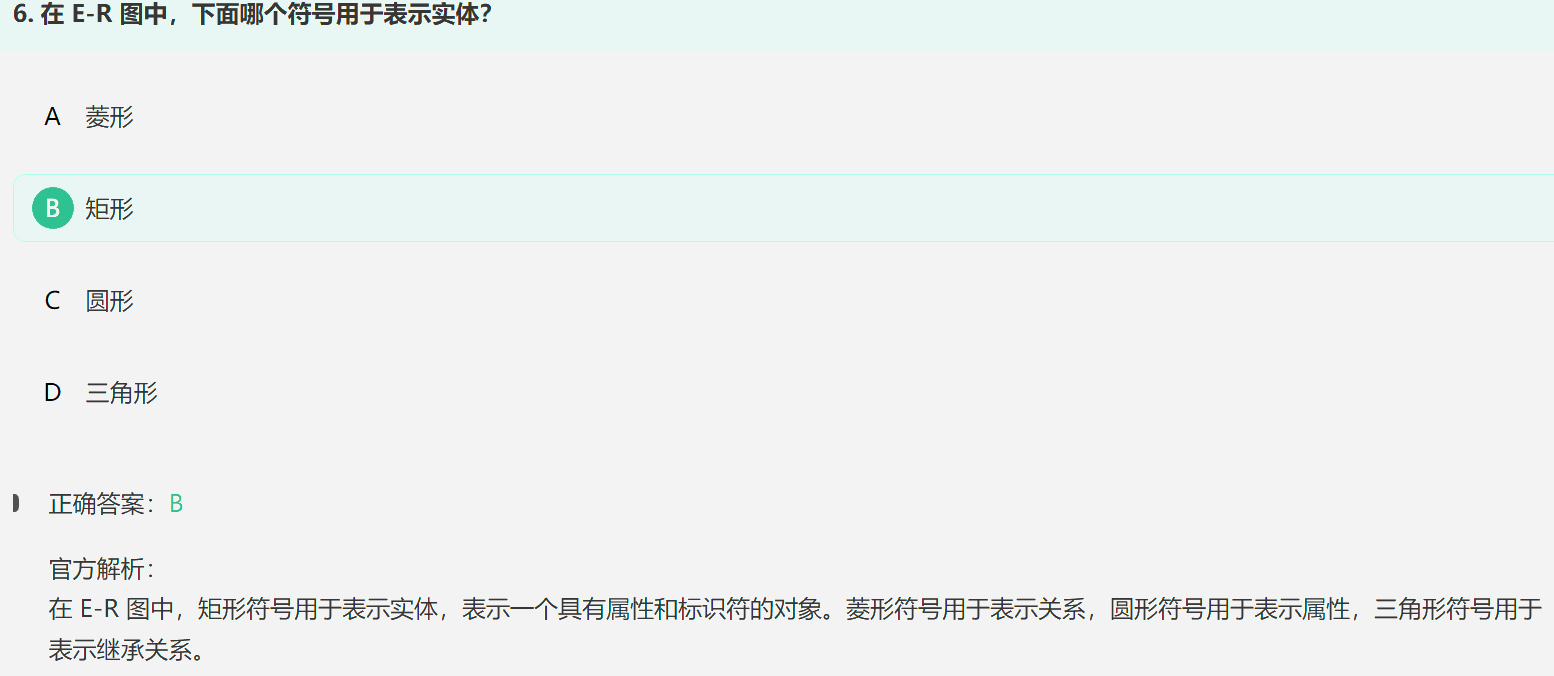
E-R图(Entity-Relationship Diagram)是一种用于描述实体之间关系的数据模型图。它是一种抽象的、高层次的数据模型工具,用于可视化和描述现实世界中各种实体之间的关系;
四、计算机网络
1. TCP/UDP报文格式

2. HTTP请求报文&响应报文
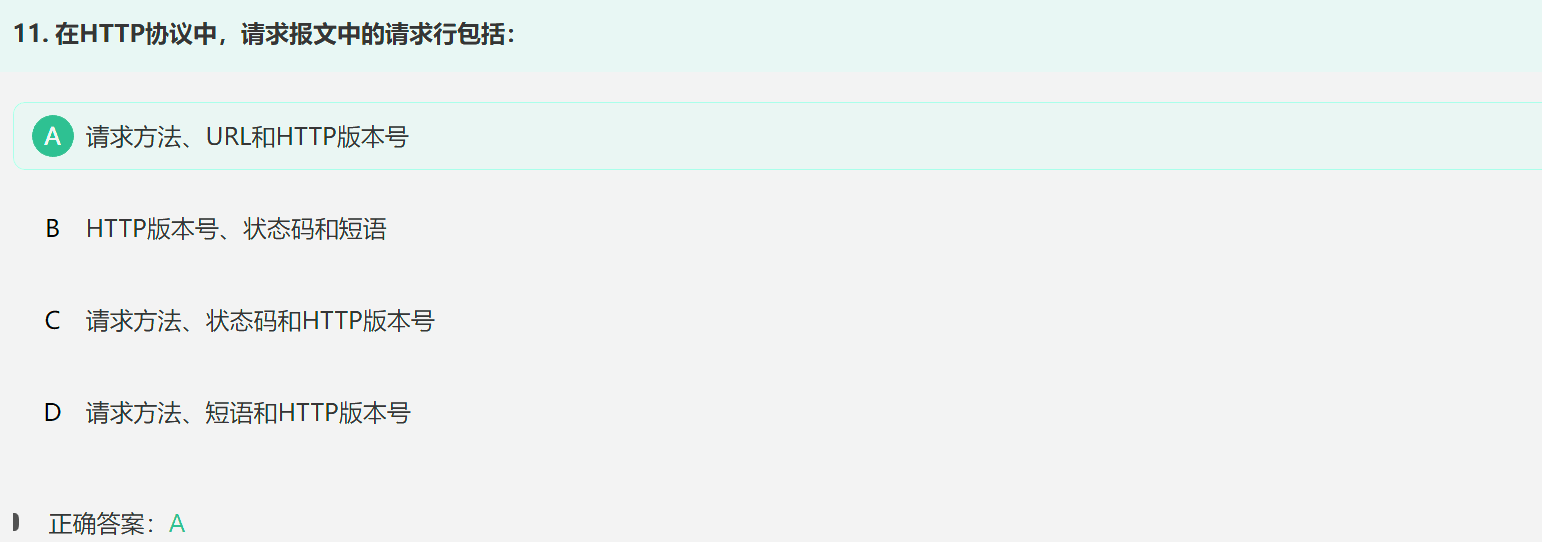
HTTP请求报文的首部行由方法+URL+版本组成,
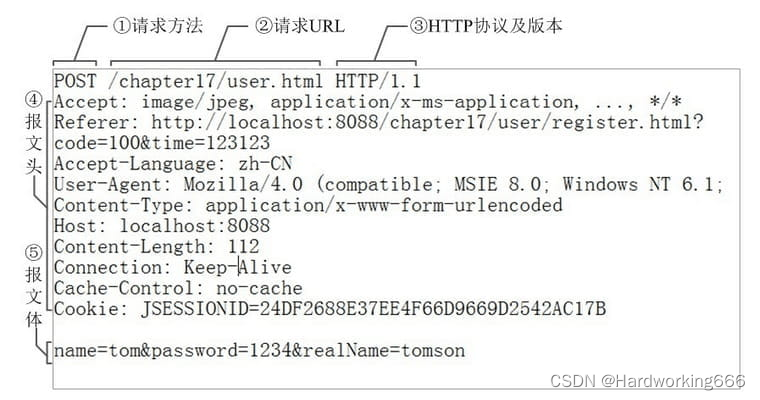
请求报文常用的方法:
①GET:请求读取由URL标识的信息;
②HEAD:请求读取由URL标识的信息的首部,使用HEAD方法时,服务器可对HTTP报文进行响应,但不会返回请求对象,其作用主要是调试;
③POST:给服务器添加信息(如注释);
④CONNECT:用于代理服务器;
Host表示服务器域名,即URL标识的信息存放在哪个服务器;
Connection表示HTTP的连接方式,keep-Alive表示持久连接,Close表示非持久连接;
Cookie表示这个用户曾经访问过这个网页,且其表示号为*****;
而HTTP响应报文的开始行由版本+状态码+短语组成;

3. HTTP状态码
HTTP常见状态码
1XX:信息性状态码,表示请求正在处理;
2XX:成功状态码,表示请求正常处理完毕,例如200 OK一切正常;
3XX:重定向状态码,表示资源位置发生变动,需要客户端重新发送请求,例如304 NOT MODIFIED 资源未修改,客户端可继续使用缓存;
4XX:客户端错误状态码,表示请求报文有误,服务器无法处理,例如404 NOT FOUND 资源未找到,403 Forbidden禁止访问;
5XX:服务器错误状态码,表示服务器在处理请求时内部发生错误,例如500 服务器错误;
4. 发送和接收邮件的协议
①发送方用户代理将邮件发送到发送端邮件服务器:使用SMTP、HTTP、MIME协议;
②发送方邮件服务器将邮件发送到接收端邮件服务器:只能使用SMTP协议;
③接收端邮件服务器将邮件读取到接收方用户代理:使用POP3、HTTP、MIME协议;
5. IO调度

请求队列是以设备为单位的;
五、操作系统
1. 进程管理

临界资源:多个进程可以共享系统中的资源,一次仅允许一个进程使用的资源称为临界资源,如共享的数据、代码或硬件设备等;
临界区:指访问临界资源的那段代码程序,如P/V操作、加减锁等;
2. 死锁解除的方法
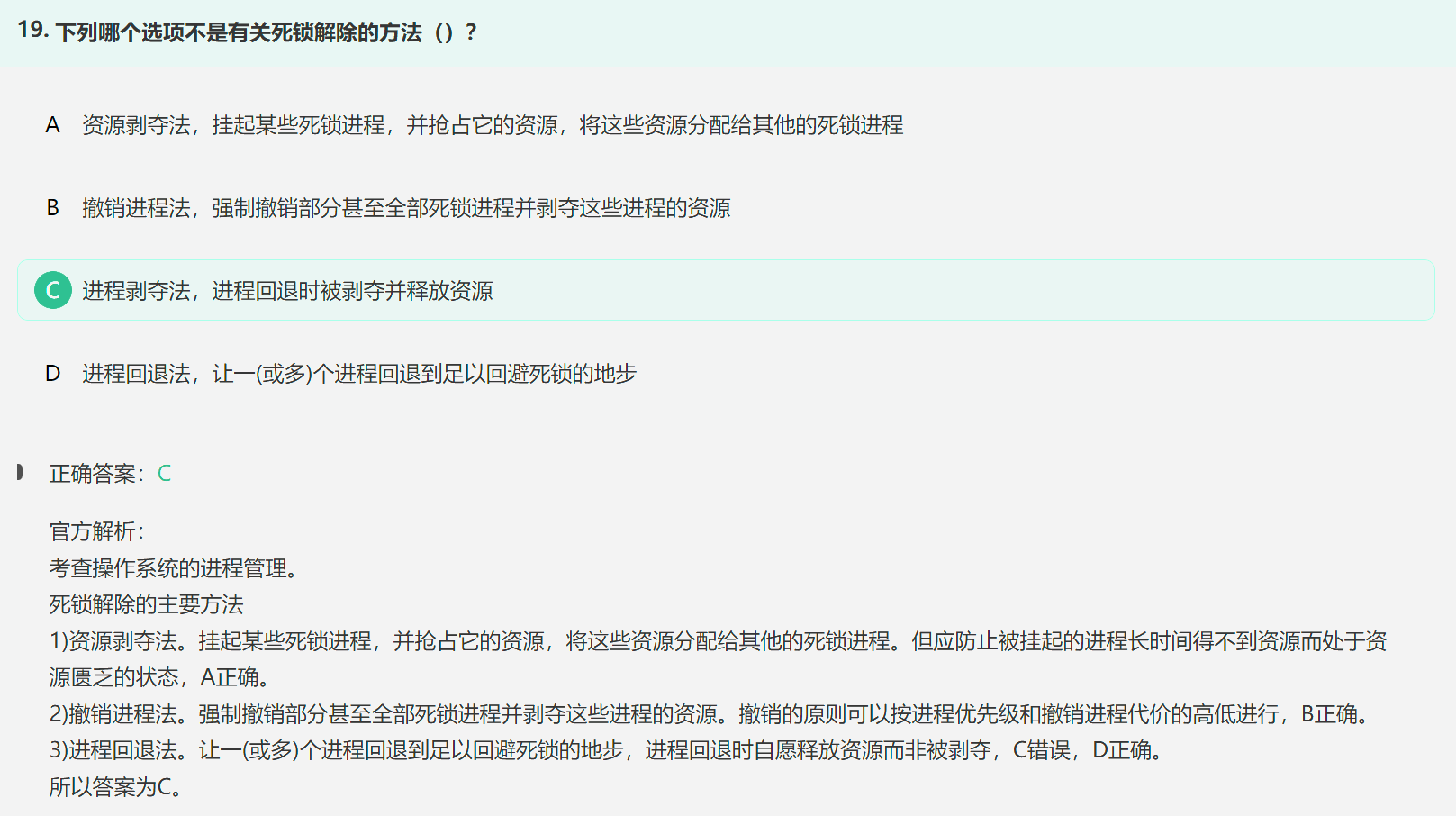
进程回退时自愿释放资源而非被剥夺,故C错误;
3. 进程控制块PCB
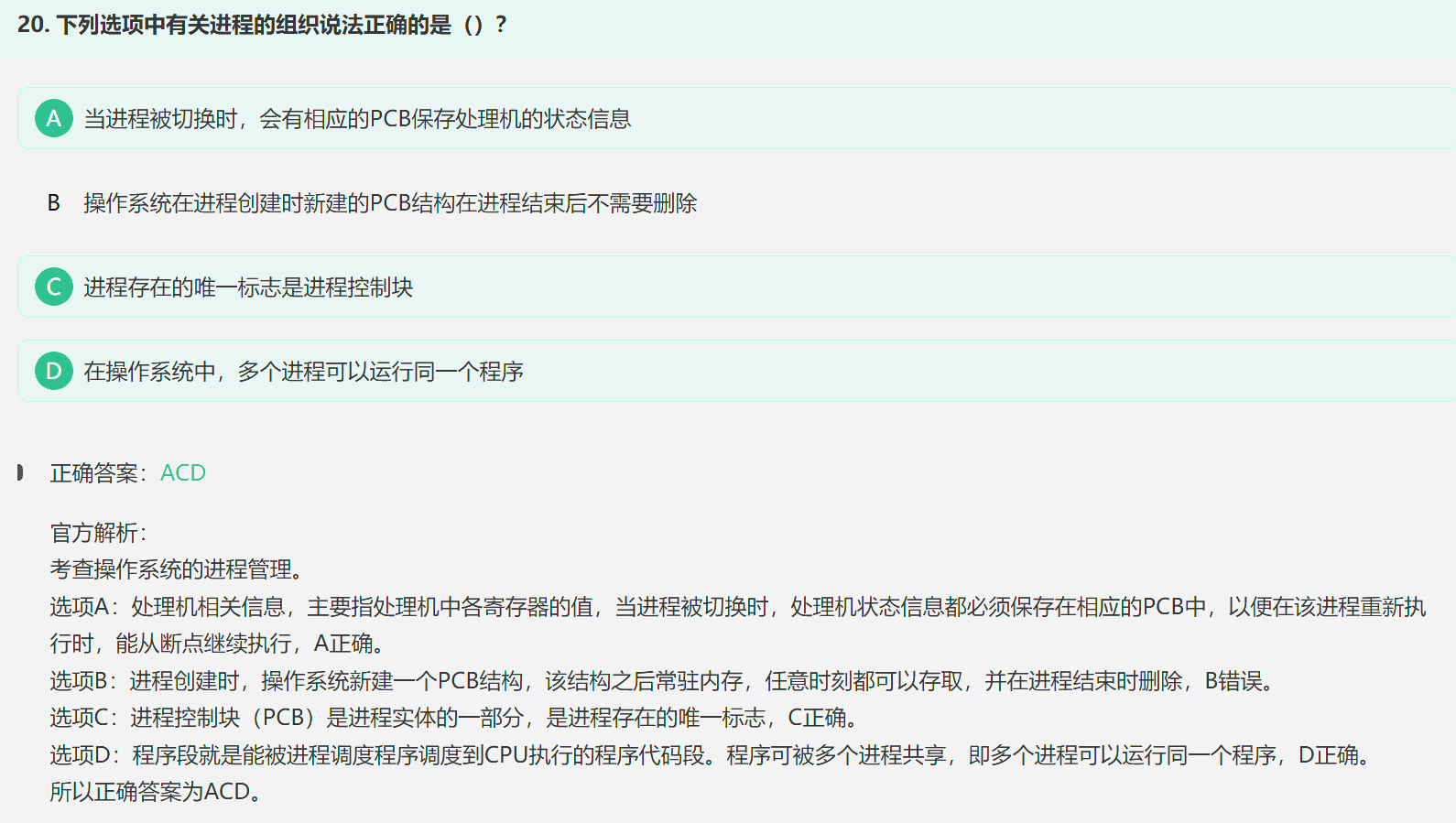
进程创建时,操作系统新建一个PCB结构,该结构之后常驻内存,任意时刻都可以存取,并在进程结束时删除,故B错误;
六、Spring&SpringBoot
1. Spring框架中用到了哪些设计模式

Spring 框架中使用了多种设计模式来实现其功能,其中一些常用的设计模式包括:
-
单例模式(Singleton Pattern):Spring 中大量使用了单例模式,确保容器中的 bean 默认是单例的,这样可以节省资源并提高性能。
-
工厂模式(Factory Pattern):Spring 使用工厂模式通过 BeanFactory 和 ApplicationContext 来创建和管理 bean 实例,将对象的创建和获取解耦,使得应用更加灵活。
-
代理模式(Proxy Pattern):Spring AOP(面向切面编程)基于代理模式实现,通过动态代理机制为目标对象织入横切关注点,实现对业务逻辑的增强。
-
观察者模式(Observer Pattern):Spring 事件机制就是基于观察者模式实现的,允许对象在事件发生时注册监听器,并在事件发生时得到通知。
-
模板方法模式(Template Method Pattern):Spring 的 JdbcTemplate 使用了模板方法模式,定义了数据库操作的算法框架,具体的 SQL 查询和更新由用户实现。
-
装饰器模式(Decorator Pattern):Spring 的装饰器模式体现在 AOP 中,通过切面(Aspect)为 bean 动态添加额外的功能,而不改变原有类的结构。
-
适配器模式(Adapter Pattern):Spring MVC 中的 HandlerAdapter 就是适配器模式的应用,用于将不同类型的处理器适配到框架中统一的处理器接口。
-
建造者模式(Builder Pattern):Spring 中的 RestTemplate 使用了建造者模式来构建 HTTP 请求,使得客户端能够方便地创建复杂的请求。
命令模式(Command Pattern)是一种行为型设计模式,旨在将请求封装成一个对象,从而使调用操作的对象与执行操作的对象解耦。在命令模式中,命令被封装成一个对象,包含了执行该命令所需的所有信息,如方法调用、参数等。命令模式广泛应用于各种应用场景,如 GUI 操作的撤销重做、多线程任务处理、网络请求处理等。通过命令模式,可以将请求封装成独立的对象,提高系统的灵活性、可扩展性和可维护性。
——但Spring框架中没怎么用到
工程模式好像没有这个设计模式;
七、数据结构
1. 手动求KMP算法中的next[]数组
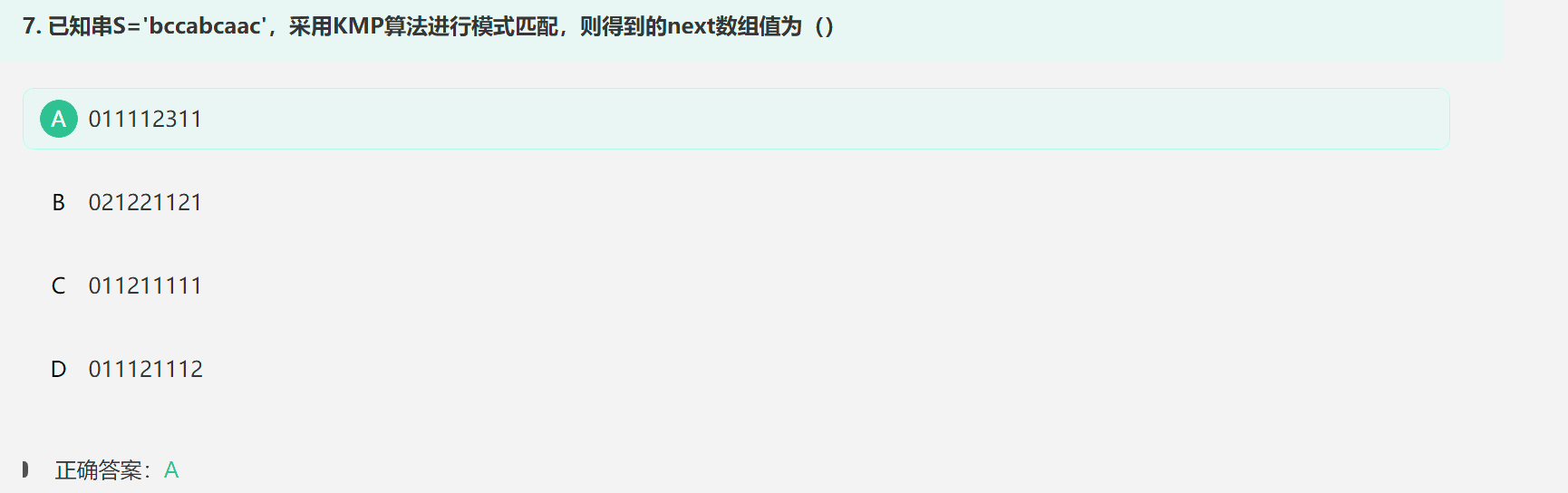

求完当前最长相同前后缀长度之后,还要右移一位(第一位补-1)再加一;
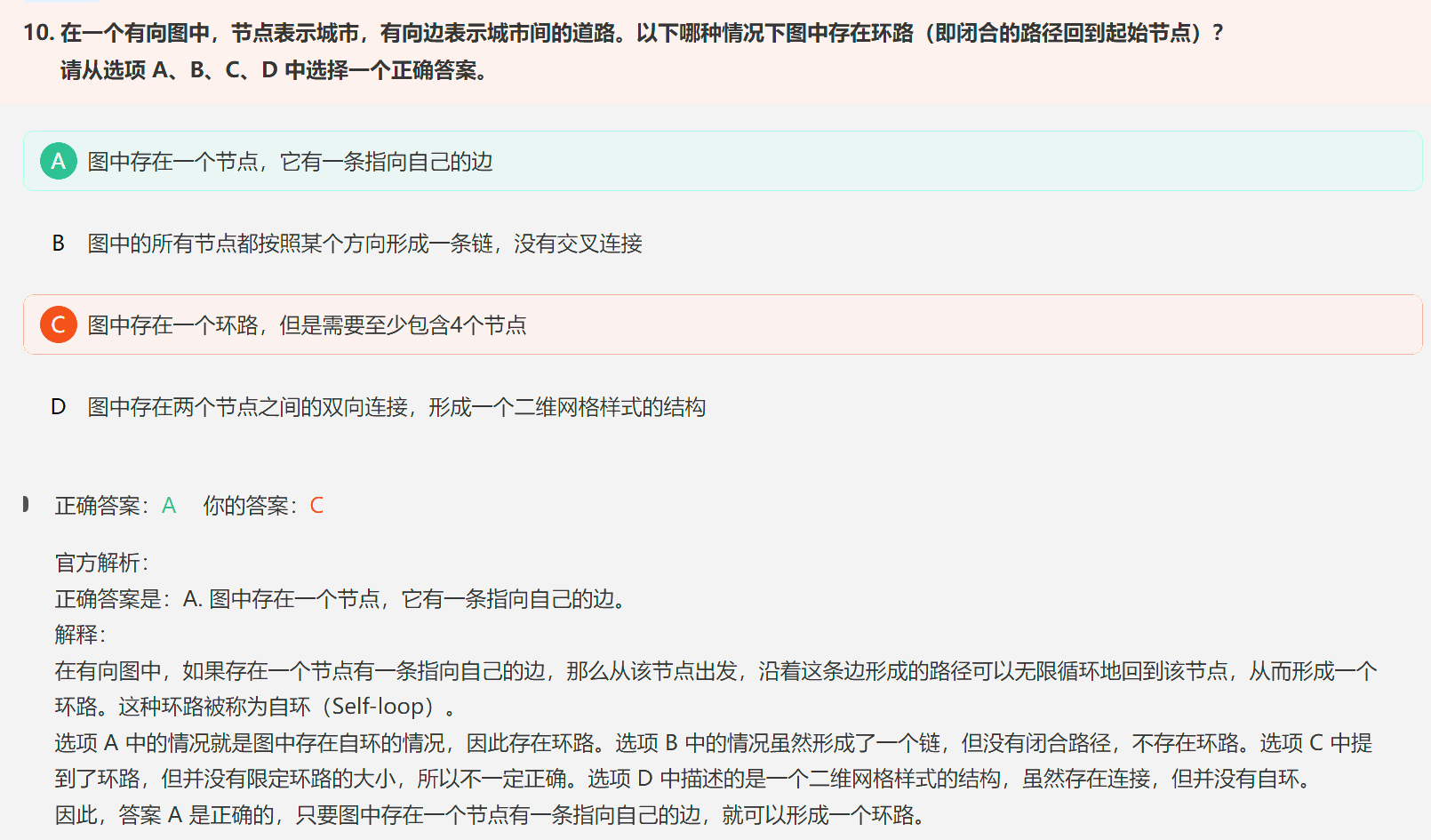
2. 有向图
八、Java基础&集合&并发
1. instanceof

a instanceof A:判断一个对象是否是一个类、或是其子类的实例,或是一个接口的实现类的实例,进而判断a能否被(强制)转换为对类A的引用;
2. 反射
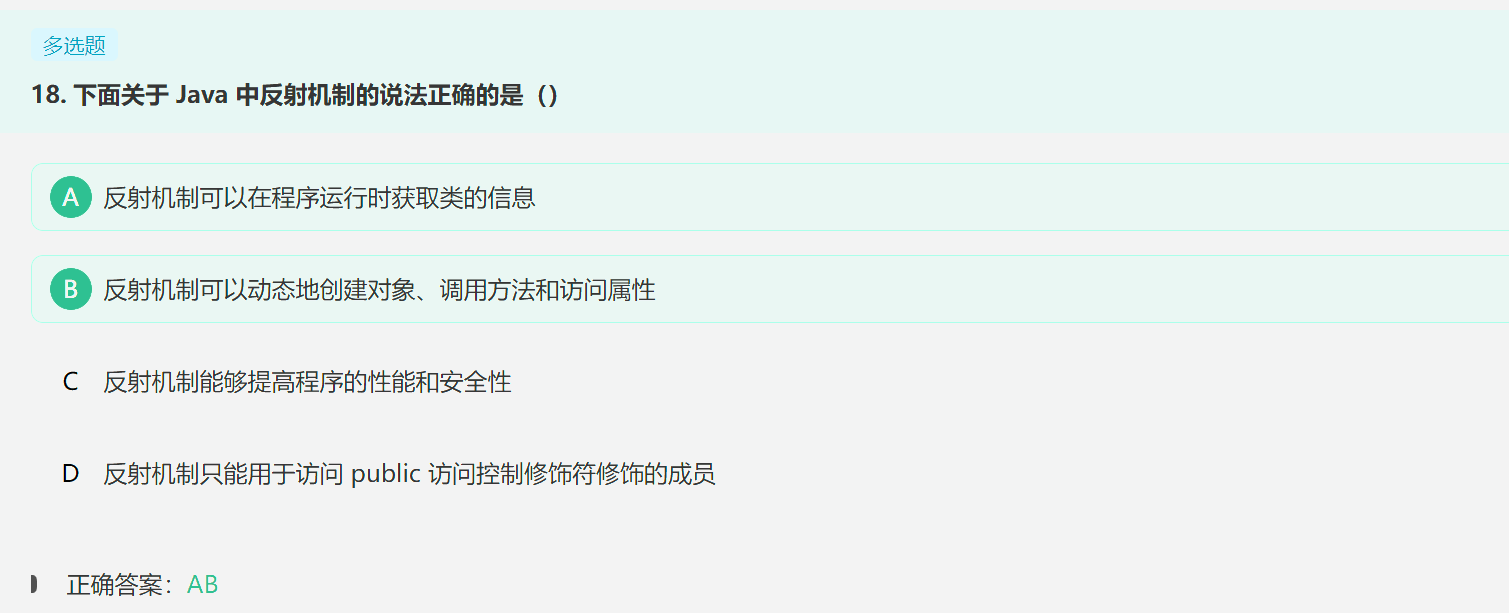
通过反射可以在运行时获取任意一个类的所有属性和方法,并进行调用;
反射的优点是让代码更加灵活,Spring、MyBatis 等框架中都大量使用了反射机制,jdk动态代理也是基于反射;缺点则是会增加安全问题;
常用的获取Class实例的三种方式:类.class、对象.getClass()、Class.forName(字符串类型的类路径,如"com.atguigu.java.Person");
反射中常用的方法:
getFields():获取当前运行时类及其父类中声明为public访问权限的属性;
getDeclaredFields():获取当前运行时类中声明的所有属性。(不包含父类中声明的属性);
getMethods():获取当前运行时类及其所有父类中声明为public权限的方法;
getConstructors():获取当前运行时类中声明为public的构造器;
对获取到的属性/方法/构造器对象调用.setAccessible(true)方法,即可保证其可访问;
3. 一个字节可以存多少英文字符/汉字?

一个字节可以存储一个ASCII字符,也就是一个西文字符,
在常见的 UTF-8 编码中,一个汉字通常需要3个字节来表示(UTF-16 编码需要2个字节,UTF-32 编码需要4个字节);
4. 内部类
①内部类可以访问外部类的私有成员;
②内部类可以隐藏外部类的实例化过程,使得外部类的实例化逻辑对外部代码不可见,例如单例模式的静态内部类实现;
③外部类中不能直接访问内部类的非静态属性,可以在外部类中创建内部类的实例,然后通过该实例来访问内部类的属性;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号