leetcode刷题笔记
一、数组
1.二分查找法
①应用场景
有序数组的查询都可以考虑使用二分查找;
标准写法:——#704
public int search(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while(left <= right){
int mid = (right - left) / 2 + left;
if(nums[mid] == target){
return mid;
}else if(nums[mid] > target){
right = mid - 1;;
}else{
left = mid + 1;
}
}
return -1;
}
②注意点
Ⅰ. 若当前元素不存在于数组中,则二分查找的left指针最终位置即为当前元素按序应当插入数组的下标;——#35
Ⅱ. 拓展为用二分法求一个整型的算术平方根(向下取整),若其算数平方根不为整型,则其向下取整的结果即为left-1(left为二分查找的left指针最终位置);——#69
Ⅲ. 如果当nums[mid] == target时仍令right = mid - 1并记录最新的mid,则可以找到第一个等于target的值,
如果当nums[mid] == target时仍令left = mid + 1并记录最新的mid,则可以找到最后一个等于target的值;——#34
Ⅳ. #74:搜索一个递增的二维矩阵——一次二分查找即可,用mid / col、mid % col作为行号、列号;
Ⅴ. #33:对旋转排序数组进行二分查找——旋转排序数组的特性:取mid之后,其左右两侧至少有一边是保持增序的,判断target是否存在于有序的那一侧即可,不在则必在另一侧;
Ⅵ. #153:寻找旋转排序数组的最小值——继续使用旋转排序数组的特性,每次取有序一侧的最小值即可;
Ⅶ. #300:二分法查找一个有序数组中小于target的最大元素的下标pos,这样pos + 1就是大于等于target的最小元素,再配合贪心算法让上升速度尽可能慢,维护一个最长递增子序列;
int left = 1, right = index, temp = 0;
while (left <= right) {
int mid = (right - left) / 2 + left;
if (dp[mid] < nums[i]) {
temp = mid;
left = mid + 1;
} else {
right = mid - 1;
}
}
dp[temp + 1] = nums[i];换一种写法,直接找出大于等于target的最小元素:
int left = 1, right = index, temp = 0;
while (left <= right) {
int mid = (right - left) / 2 + left;
if (dp[mid] < nums[i]) {
left = mid + 1;
} else {
temp = mid;
right = mid - 1;
}
}
dp[temp] = nums[i];Ⅷ. #4(hard):二分法寻找两个正序数组的中位数——二分法:每次从两个数组中各找出第k/2个数,将较小的那一组的前k/2个数截断舍弃,时间复杂度为O(log(m+n));
——注意:①三个边界条件,如果len1 == 0、len2 == 0、或是k == 1;
②找第k/2个数时,注意k/2可能大于len1/len2,因此要取两者的最小值;
③递归时更新截断的数组的起始下标,以及k即可;
④中位数对于奇数、偶数是不一样的,因此分别找出第(m+n+1)/2、(m+n+2)/2个数再取平均值,注意结果要强转为double以保留小数;
2.双指针法
①应用场景
双指针法可用于以O(n)的时间复杂度实现对数组的元素替换、移动等操作;
②解题思路
Ⅰ. left、right分别用于指向什么元素,如何初始化,如何移动;
Ⅱ. 退出循环的条件,退出循环后是否还要进行判断;
③例题
Ⅰ. #283:将数组中的非零元素移动到0元素之前,并保持非零元素的相对顺序——right遍历数组,并对每个非零元素进行交换操作,left和right指针间若有0元素则全为0元素,若没有0元素则为空;
Ⅱ. #844:比较两个含退格的字符串是否相等——使用left、right指针分别对两个字符串从后往前遍历(因为退格键是删除其左侧的元素),使用两个变量分别记录当前退格符的数量,分情况讨论;
Ⅲ. #977:对一个含负数的非递减数组的平方进行排序——因为含负数且非递减,所以其越靠外的元素平方越大,故使用left、right指针从最外侧向内侧遍历,即可以O(n)时间复杂度实现;
Ⅳ. #15:给定一个数组,求三数之和等于target的所有不重复的组合——在有序的情况下,使用双指针可以用O(n)的时间复杂度求出所有两数之和等于指定值的组合,本题还要求去重,还可以剪枝;
Ⅴ. #18:给定一个数组,求四数之和等于target的所有不重复的组合——和#15基本完全一样,只不过多了一个外层循环,以及相应的去重、剪枝操作(没必要再做一遍);
②注意
Ⅰ.如何使用双指针遍历所有组合(双指针相比暴力解法可以降低一阶时间复杂度);
Ⅱ.如何去除重复的组合;——双指针内部的去重操作应当在找到满足条件的组合之后、指针发生变动之前进行
Ⅲ.如何剪枝以减少循环次数;
3.滑动窗口法
①应用场景
可用于元素全为正数(保证right右移变大left右移变小,这一点很有必要,例如#560数组有正有负就用不了滑动窗口)、
求满足大于某值的连续子数组的最小长度、或是小于某值的连续子数组的最大长度;
②解题思路
Ⅰ. 推荐初始令left=0,right=0,right指向待插入窗口的元素;
Ⅱ. 循环退出条件一般为right < len,但需要考虑到right == len这个边界条件下,是否还需要进入循环继续判断,
很多时候都是需要的,此时一般将循环退出条件改为right <= len,再在循环体内添加一个退出的情况;
③例题
Ⅰ. #209:求和不小于target的连续子数组的最小长度;——求大于某值的连续子数组的最小长度
Ⅱ. #904:求元素值不超过两种的连续子数组的最大长度;——求小于某值的连续子数组的最大长度
Ⅲ. P5700:区间取数,可转换为与#209一样的滑动窗口题;——求大于某值的连续子数组的最小长度
Ⅳ. #3:求无重复子串的最长子串——因为字串中不可能存在两个相同字符,所以没必要使用哈希表,用HashSet即可;——求小于某值的连续子数组的最大长度
Ⅴ. #76(hard):求一个字符串 s 中能够覆盖另一个字符串 t 的最短子串——用一个哈希表存放当前仍需多少个该字符才能完成覆盖,用一个变量flag记录总共还需要多少个字符,多余的字符不计入flag内;
(这一方法还可以用于找字母异位词#438)
④注意:
Ⅰ. 先判断sum > target、sum < target时,是左边界右移还是右边界右移,再根据求最大/最小长度决定sum == target时,是左边界右移(求最小长度)还是右边界右移(求最大长度);
Ⅱ. 注意边界条件是否符合:数组为空、数组长度为1、当right遍历到数组最后一位时;
4. 矩阵
①应用场景
Ⅰ. #54:螺旋矩阵:通过利用四条边界实现以螺旋的方式遍历矩阵,并根据要求对路径上的矩阵元素做操作;
Ⅱ. #73:矩阵原地置0,要求空间复杂度为O(1)——用两个变量记录第0行第0列是否应当全为0,再用第0行和第0列记录剩下的行和列是否应当全为0并原地修改,最后根据两个变量决定是否修改第0行第0列;
Ⅲ. #48:方阵原地旋转90°,要求空间复杂度为O(1)——原地将方阵旋转90°,相当于先沿水平中线翻转,再沿主对轴线翻转;
Ⅳ. #240:搜索二维矩阵,要求时间复杂度为O(m+n)——从矩阵右上角开始遍历,大于target就列--,小于target就行++;
②注意
Ⅰ. 螺旋矩阵注意退出循环的时机:大循环while(true),内部每遍历一条边之后,例如left++,就通过if (left > right) break; 来控制循环退出的时机;
5. 前后缀子串问题
①例题
Ⅰ. #560:求一个数组中和为k的所有连续子数组的数量
——本题数组中存在负数,滑动窗口失效(left右移或是right右移都有可能让窗口和增加或减小,无法判断),
——由于相同开头的大前缀-小前缀=后缀,用一个变量leftStrSum记录以 i 为尾的前缀的数组和,用一个哈希表记录此前的所有前缀和的个数,当leftStrSum - k在哈希表中存在时,就说明以 i 为尾和为k的后缀存在,哈希表中为几就存在几个;
Ⅱ. #437:求二叉树中和为targetSum的向下队列的路径的数量(不要求以根节点开始,也不要求叶子节点结束,只要求向下连续即可)
——本题虽然是二叉树的题,但其用到的大前缀-小前缀=后缀的思想和#560如出一辙,通过前缀和思想可以从递归解法的O(n²)优化为O(n);
——注意:①前缀和可能超过int范围,所以用long;
②prefix应当在初始化时存入(0, 1)键值对;
③为了保证求的都是向下队列,当本节点所在子树遍历完时,应令和为sum的前缀和数量-1;
6. 后缀子数组问题
①例题
Ⅰ. #53:求一个数组中连续子数组的最大和——用一个变量max表示当前最大后缀和,如果max + nums[i]比 nums[i]更大就令max = max + nums[i],反之令max = nums[i];
Ⅱ. #152:求一个数组中连续子数组的最大乘积(数组元素有正有负)——相比#53,因为乘积遇到负数会最大、最小逆转,因此增加一个变量min原来保存当前最大后缀乘积,遇到负数令max、min互换;
7. 归并思想
①例题
Ⅰ. #88:合并两个有序数组,要求将结果放入其中一个数组——要求原地完成,由于nums1数组中有空位,因此分别对两个数组逆序遍历,逆序放入nums1中;
Ⅱ. #LCR170:hard但面试常客;
Ⅲ. #315:hard但面试常客;
Ⅳ. #912:归并排序;
8. 快排的分治思想
①例题
Ⅰ. #215:要求用O(n)的时间复杂度求数组中第k个最大的元素——利用了快排partition()方法一次确定一个元素的最终位置,并且左侧都是小于等于它的元素,右侧都是大于它的元素;
Ⅱ. #912;快速排序,两次优化;
Ⅲ. #75:对仅包含0、1、2三种元素的数组进行升序排序,要求只进行一趟遍历,且空间复杂度为O(1)——计数排序需要两趟遍历,要想一趟遍历,
这里可以用三个指针:zero指向应当为0的下标,初始化为0,index用来遍历数组,初始化为0,two指向应当为2的下标,初始化为nums.ength - 1;
循环条件为index <= two,
当nums[index]为0时,交换index、zero下标的元素,并令zero++、index++,
当nums[index]为1时,不进行交换,index++;
当nums[index]为2时,交换index、two下标的元素,并令two--;
——为什么交换index、zero时令index++,而交换index、two时index不变?
因为第一种情况下,zero指向的一定是1或是和index相同位置的0,对于第二种情况,必须令index++,否则就会出错;
而在第二种情况下,two指向的可能是0、1、2,如果是2或0的话都需要进一步处理;
Ⅳ. #395:找出一个字符串中至少有k个重复字符的最大字串长度——使用分治法进行递归,
对于出现次数小于k的字符,其必不可能出现在结果中,因此可以直接以此字符对字符串进行分割,对每个子串递归地进行进一步判断;
如果所有字符出现次数均大于等于k,则直接返回字符串的长度;
——时间复杂度约为O(n * 26 * 26)
9. 八大排序——#912
①直接插入排序
Ⅰ. 算法分析
不断将未排序的节点加入到已排序的部分中,
时空复杂度:时间复杂度最低O(n),最高O(n²);
稳定性:稳定,因为大循环是自左向右遍历,只要确保小循环中在为元素temp在已排序数组中寻找插入位置时,当nums[j - 1]等于temp时,不要让nums[j-1]右移,只有当nums[j - 1]大于temp时才右移;
——直接插入排序在基本有序的数组上表现良好(还有一种数组叫做短数组,指每个元素离其最终位置都很近,这种也很适合直接插入排序);
Ⅱ. 算法实现注意点
一句话总结算法实现:大循环从i = 1开始顺序遍历数组,小循环从j = i -1开始逆序遍历已排序的数组,若大于当前元素则令其右移,直至为当前元素找到插入位置;
和单链表中的实现的区别在于:因为数组可以自后向前遍历,所以就不需要尾指针还分两种情况了,在为当前元素寻找插入位置时,直接从已排序数组的最后一个元素开始遍历,
若大于当前元素则右移一位(这样刚好将寻找插入位置和后续元素右移操作合并了);
②希尔排序
Ⅰ. 算法分析
本质上是以gap为间隔来将数组切分为子数组,再分别对子数组进行直接插入排序;
(gap是希尔排序的一个超参数,其如何初始化及后续如何变化会直接影响算法的效率,这里我们直接取最简单的len/2,后面也是不断折半)
时空复杂度:时间复杂度很难计算,不作要求,空间复杂度为O(1)
稳定性:不稳定,因为在切分子数组时可能会将数值相等的元素切分到不同子数组,分别进行排序之后,其相对顺序可能会发生改变,例如对[1,2左,2右,1]进行gap=2、1的希尔排序,gap=2排序得[1,1,2右,2左],gap=1排序顺序不变,很明显,两个2的相对顺序发生了改变;
Ⅱ. 算法实现注意点
对每个gap,都可以在数组中找出gap个间隔为gap的子数组,分别对其进行一次直接插入排序,
单次插入排序:对数组nums中从start开始,间隔为gap的子数组进行直接插入排序,写法就是把直接插入排序里的1都改成gap;
③冒泡排序
Ⅰ. 算法分析
遍历序列,通过对不满足排序规则的相邻元素进行两两交换,实现一次遍历确定一个待排序序列中最大/最小元素的最终位置,当某次遍历一次交换都没有进行时,说明此时序列已经有序;
冒泡排序和简单选择排序比较接近,都是一次遍历确定一个当前最大/最小元素的最终位置,不过冒泡排序是可以中途停止的,不一定非要遍历n-1次;
时空复杂度:时间复杂度为O(n²),空间复杂度为O(1)
稳定性:稳定,因为只有当nums[i] > nums[i + 1]时才会发生元素交换,而冒泡排序又是通过逐个遍历的方式进行的,因此值相等的元素在任何情况下都不会交换位置;
Ⅱ. 算法实现注意点
一句话总结算法实现:大循环递减控制本次需要排序的数组的长度,小循环遍历待排序数组,对于满足条件的两个数组元素进行交换,设置一个boolean flag来判断本次小循环有无元素交换,如没有直接break;
④快速排序
Ⅰ. 算法分析
一次划分:为元素pivot确定其在数组中的最终位置,同时将小于pivot的元素移动到其左侧,大于pivot的元素移动到其右侧;
递归地对pivot左、右侧的子数组进行划分,直至子数组只包含单个元素;
时空复杂度:平均情况下,基本每遍历一次数组都可以确定两个元素的最终位置,只需要遍历logn次即可,因此平均时间复杂度为O(nlogn),空间复杂度为O(longn),主要是递归时的栈空间;
稳定性:快速排序中不是按顺序对数组进行遍历的,交换元素时有可能让同值元素的相对位置发生改变,故不稳定;
Ⅱ. 算法实现注意点——快速排序算法的优化
参考文章:快速排序的几个优化
a. 优化方向1:当初始数组基本有序时
因为通常取pivot=nums[left],故当数组基本有序时,每次确定的元素的最终位置都在数组边缘,
导致大部分情况下遍历一次数组只能确定一个元素的最终位置(因为另一个子数组为空),遍历次数趋近n,算法时间复杂度趋近O(n²);
解决办法:
可以是取随机枢轴,也可以用三数取中法设置枢轴;
b. 优化方向2:当数组中存在大量相同元素时
因为在快排的基本写法中,通常将等于pivot的元素全部放在pivot的一侧,故当大部分元素都相同时,每次确定的元素的最终位置都在数组边缘,
导致大部分情况下遍历一次数组只能确定一个元素的最终位置(因为另一个子数组为空),遍历次数趋近n,算法时间复杂度趋近O(n²);
解决办法:
等于pivot的元素应当均匀地分布在pivot两侧,避免两个子数组长度差距过大,具体实现方法就是当元素等于pivot时也参与交换;
——算法实现:在新边界[i = low + 1, j = high]内交换,分别令i在元素小于pivot时++、j在元素大于pivot时--,当i >= j直接break,否则交换i、j元素并令i++、j--,
最后退出循环后,交换low、j元素;
⑤ 选择排序
Ⅰ. 算法分析
每遍历一次未排序的序列,就确定一个最大/最小元素,并将其与其应在的位置上的原来的元素交换,遍历n-1次后确定所有元素的最终位置;
时空复杂度:无论输入是否基本有序,其完成排序的时间复杂度都为O(n²),空间复杂度为O(1);
稳定性:交换元素就无法保证稳定性,例如对[3左,3右,2,1]进行选择排序,第一轮变成[1,3右,2,3左],第二轮变成[1,2,3右,3左],第三四轮不变,可以看到两个3的相对位置发生改变,故不稳定;
——选择排序的优点在于其是交换次数最少的排序算法,在交换成本较高的排序任务中可以考虑优先使用;
⑥堆排序
Ⅰ. 算法分析
下沉操作:若当前节点存在左孩子,且其左、右孩子节点值中的最大者大于当前节点,则令当前节点与最大者交换节点值,直至当前节点不存在左孩子、或最大者也不大于当前节点;
建堆:对所有的分支节点(非叶子结点)自后向前依次进行下沉操作;
堆排序:用i控制待排序序列的长度,每次将当前堆顶元素和最后一个元素交换,确定一个最大元素的最终位置,序列缩短一位,再对新的堆顶元素进行下沉操作,i==0时停止排序(最后一个元素不用排序了);
——在已建成大根堆中进行一次siftDown()操作的作用:重新选出一个最大值作为根节点;
在无序序列中逆序对每个分支节点进行siftDown()操作的作用:将无序序列变成大根堆;
时空复杂度:时间复杂度为O(nlogn),空间复杂度为O(1);
稳定性:存在元素交换操作,无法保证稳定性;
——堆排序的优点在于其在平均时间复杂度达到O(nlogn)的同时,空间复杂度只有O(1),适用于一些可用空间有限,又需要较高效率的排序算法的场景;
⑦归并排序
Ⅰ. 算法分析
从长度为1的有序子序列开始,不断两两合并,直至整体有序,因为合并有序序列的时间复杂度为O(n),总共只需要合并logn次,故整体时间复杂度为O(nlogn);
时空复杂度:归并排序是一种最坏情况下时间复杂度也只有O(nlogn)的高效排序算法,空间复杂度为O(n),因为数组的合并需要一个辅助数组用于暂存合并后的数组;
——归并排序的优点在于它是唯一一个平均时间复杂度达到O(nlogn)的情况下,还能保证稳定性的排序算法;
Ⅱ. 算法实现注意点
个人更习惯使用自底向上的非递归写法,注意控制好两个有序子数组的边界即可;
——merge()方法中创建的中间数组长度应为待归并的两个子数组长度之和,而不是整个nums数组的长度,后者会浪费过多的内存空间;
⑧三种非比较的排序算法
Ⅰ. 计数排序:建立一个长度等于序列数值范围的数组,用这个数组记录序列中每个数出现的次数,最后基于这个数组按顺序写回原数组即可;
Ⅱ. 基数排序:将计数排序中的辅助数组细化到分别对个位、十位、百位进行统计,可以缩短辅助数组的长度;
(值的范围小、数量大用计数排序,值的范围大、数量小用基数排序)
Ⅲ. 桶排序:先将原序列按值的范围分成若干个桶,再分别对每个桶进行排序,最后依次将桶中的数据取回原数组即可;
⑨Arrays.sort()排序算法原理
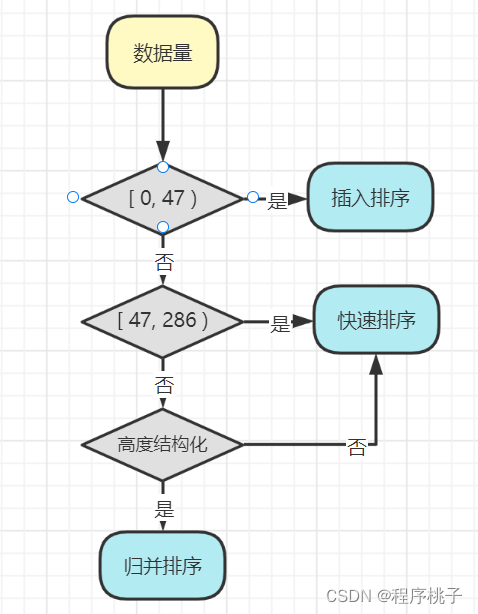
根据数据量大小和数据是否高度结构化(高度结构化:指序列是否基本有序),分情况采用直接插入排序、快速排序和归并排序;
10. 数组普通题
①例题
Ⅰ. #56:合并区间——将待合并的子数组放在list的尾部,可以避免对数组最后一个元素的讨论;
Ⅱ. #189:将数组元素整体右移k位,要求原地完成不使用额外空间——三次逆置数组实现原地反转;
Ⅲ. #238:令数组中每个元素等于除其自身以外全部元素的乘积,但不允许用除法,且要求时间复杂度O(n),空间复杂度O(1)——依次从左向右乘、从右向左乘,分别用一个变量记录中间乘积,结果数组应全部初始化为1;
Ⅳ. #41:找到一个数组中从1到n缺失的第一个正数,要求时间复杂度为O(n),空间复杂度为O(1)——如果一个不缺失,则该数组各位置元素应为1到n,
遍历数组,若该元素在[1, n]范围内,则将其交换到其应在的位置,一直置换到该元素不在范围内,或是其与其应在的位置的元素相同;
再遍历数组,如果nums[i]不等于i + 1,则返回i + 1,全部都等于则返回n + 1;
Ⅴ. #169:寻找数组中出现次数超过n / 2的多数元素,要求空间复杂度为O(1)——同归于尽消杀法/摩尔投票法;
Ⅵ. #31:寻找数组的下一个排列——用left指针找到自右向左不满足递增的第一个数,再用right指针在left右侧自右向左找到第一个大于nums[left]的元素,交换left、right,并逆置left右侧元素即可;
(第一次left自右向左找不满足递增的第一个元素,这里不要求严格递增,第二次right自右向左找第一个大于left的元素,这里要求严格大于;)
Ⅶ. #628:寻找数组中三个数的最大乘积——用五个变量分别记录最大的三个数和最小的两个数,当数组元素全为正或全为负,最大乘积必为最大的三个数的乘积,当数组元素有正有负,最大乘积可能是最大三个数的乘积,也可能是最大的一个数和最小的两个数的乘积;
11. 位运算相关
①例题
Ⅰ. #136:找出只出现过一次的数字,要求空间复杂度为O(1)——利用了异或运算“同0异1”,以及0和任意二级制数做异或运算结果都为该数本身的特性;
二、链表
1.链表的基础增删改查操作
①应用场景
Ⅰ. 经典高频面试题#146——使用哈希表+双向链表实现一个简单的LRU缓存;
哈希表存储Integer类型的key和双向链表节点类型的value,这样做的好处在于不管是put操作还是get操作都需要的将访问节点移动到链表头这一操作,由于可以通过哈希表直接获取该节点,因此删除该节点的操作不需要再遍历链表,直接删除即可,只需O(1)的时间复杂度;
——双向链表节点本身既存储key又存储value,
存储key是因为deleteTail()操作需要返回删除节点对应的key值,之后根据key值再去哈希表中删除对应的键值对;
存储value是因为哈希表的value已经是DListNode了,要查value只能去节点内部查了;
Ⅱ. 使用LinkedHashMap实现一个带ttl的LRU缓存
实现思路:
首先带ttl分两种情况,是LinkedHashMap本身带一个ttl,所有键值对共用相同的ttl,
还是每个键值对都可以自定义各自的ttl;
其次,带上ttl之和,对于过期的键值对,采用怎样的淘汰策略?是惰性删除?还是定期删除?
下面是采用了每个键值对都可以自定义各自的ttl、过期数据淘汰策略选择惰性删除(每次进行get、put操作时检查当前key对应的键值对是否过期,删除过期的键值对)的LRUCache:
(这里采用了最简单的键值对类型均为int,实际应用可使用泛型)
public class LRUCache {
int capacity;
Map<Integer, ValueHolder> cache;
public LRUCache(int capacity) {
this.capacity = capacity;
cache = new LinkedHashMap<Integer, ValueHolder>(capacity, 0.75f, true) {
@Override
public boolean removeEldestEntry(Map.Entry eldest) {
return size() > capacity;
}
};
}
public int get(int key) {
if (!cache.containsKey(key) || removeExpiredEntry(key)) {
return -1;
}
return cache.get(key).value;
}
public void put(int key, int value, long ttl) {
if (!cache.containsKey(key) || removeExpiredEntry(key)) {
ValueHolder vh = new ValueHolder(value, System.currentTimeMillis(), ttl);
cache.put(key, vh);
} else {
cache.get(key).value = value;
}
}
private boolean removeExpiredEntry(int key) {
if (!cache.containsKey(key)) {
return false;
}
ValueHolder vh = cache.get(key);
if (System.currentTimeMillis() - vh.timestamp > vh.ttl) {
cache.remove(key);
return true;
}
return false;
}
public class ValueHolder {
int value;
long timestamp;
long ttl;
public ValueHolder(int value, long timestamp, long ttl) {
this.value = value;
this.timestamp = timestamp;
this.ttl = ttl;
}
}
}
2.使用两个指针对单链表进行增删改查操作
①注意:
Ⅰ.在单链表上原地使用两个指针进行删除、插入这样的修改节点操作,容易出现一个指针在进行操作时修改了另一个指针的内容的情况,出现难以预测的错误,
建议一个链表同一时间只使用一个指针进行增删这样的修改操作;——#86
Ⅱ. 一次遍历找出两个链表的相交节点——#160
——是a==null而非a.next==null,后者因为不会遍历空节点,会导致当两个链表不存在相交节点时,a和b就永远不会相等,进而无限循环;
3.三指针对链表节点的顺序进行改变
①应用场景
Ⅰ. 部分链表翻转——#92
首先利用left找到待翻转链表的起始节点、和它前面的一个节点,记录这两个节点,
然后令pre指向待翻转链表的起始节点,cur指向下一个节点,开始进行翻转,利用right控制翻转次数,最终pre落在待翻转链表的最后一个节点,cur落在其后一个节点;
最后将三个子链表连接起来;
经典翻转链表代码:
ListNode tmp = cur.next;
cur.next = pre;
pre = cur;
cur = tmp;
Ⅱ. 两两交换链表节点的顺序——#24
本题和Ⅰ的不一样,首先pre、cur、tmp三个节点指向的位置就不一样,
本题中初始pre指向dummy节点,cur指向pre.next,也就是待交换节点中的第一个节点,
之后只要cur和cur.next都不为null,就进入循环交换节点,
在循环内取tmp = cur.next,即指向待交换节点中的第二个节点,然后依次对pre.next、cur.next、tmp.next进行修改,最后调整pre、cur的位置:(都是按照pre、cur、tmp的顺序进行修改)
pre.next = tmp;
cur.next = tmp.next;
tmp.next = cur;
pre = cur;
cur = cur.next;
Ⅲ. #25(hard):K个一组翻转链表——多指针截断子链表实现翻转:用node遍历链表,用needle连接翻转后的子链表,用left、right分别指向待翻转子链表的第一个、最后一个节点;
4.快慢指针法
①应用场景——尤其适合解决是否会出现循环的问题
Ⅰ.找出单链表的中间结点;——#234
标准写法:
将快慢指针初始化为dummy(与判断是否有环不同,不能初始化为head),循环退出条件是fast != null && fast.next != null,slow进一步fast进两步;
// 快慢指针确定单链表中间结点:链表个数n为偶数时,slow指向第n/2个节点,
// 链表个数为奇数时,slow指向第n/2+1个节点
public ListNode findMidNode(ListNode head){
ListNode dummy = new ListNode(-1, head);
ListNode fast = dummy, slow = dummy;
while(fast != null && fast.next != null){
slow = slow.next;
fast = fast.next.next;
}
return slow;
}
Ⅱ.找出存在成环的单链表的开始入环的第一个节点;——#142
快慢指针在存在环形的链表中必定会相遇,推荐将快慢指针初始化为dummy(head其实也可以),循环退出条件仍是fast != null && fast.next != null,
但相比寻找中间结点,还需要增加一个循环退出条件if (slow == fast) break;,并在退出循环后对链表不存在环形的情况进行讨论:if (fast == null || fast.next == null) return null;
Ⅲ.判断一个数是不是“快乐数”:一个数不断等于自身各位上的数的平方和,最终会变成1还是无限循环且不等于1——#202
本质上也是判断序列中是否存在环形,用快慢指针即可:这里没有dummy,直接将快慢指针初始化为n即可;
Ⅳ. #143:链表综合题,要求寻找链表中间结点+链表逆置+合并链表;
Ⅴ. #287:在一个长度为n、元素大小为1到n的数组中,有一个数出现次数超过1次,其它元素均只出现一次,找出这个重复出现的数;
——数组中如果有重复的数,那么数组下标到数组元素的映射就一定会有环路了,且入环点一定是重复元素(因为重复元素被多个下标指向);
因此,找到数组中的重复整数就等价于找到链表的环入口,将问题转换为使用快慢指针找出环入口;
——注意这里slow、fast只能初始化为0,因此需要在进入循环前先进行一次slow = nums[slow]、fast = nums[nums[fast]];
5.链表排序
①应用场景
Ⅰ.直接插入排序;——#147
直接插入排序的核心思想:
不断将未排序的节点加入到已排序的部分中,
特点是在部分有序的情况下能有效降低时间复杂度,最低O(n),最高O(n²);
算法注意点:
用一个虚拟头节点dummy和一个真实尾节点tail来标识已排序的链表部分,对尚未排序的节点先判断其是否大于tail.val,
若是则直接令tail后移一位,若不是再从头遍历已排序链表寻找插入位置;
Ⅱ.归并排序;——#148
归并排序的核心思想:
从长度为1的有序子序列开始,不断两两合并,直至整体有序,因为合并有序序列的时间复杂度为O(n),总共只需要合并logn次,故整体时间复杂度为O(nlogn);
归并排序是一种最坏情况下时间复杂度也只有O(nlogn)的高效排序算法;
算法注意点:
用一个虚拟头节点dummy总览整个链表,并将dummy.next作为最终返回值,
用size表示每轮合并中子序列的长度,大循环的条件为size<len:
用一个指针temp=dummy.next指向每轮合并时的头节点(因为排序的原因头节点是会变的,所以和head是不等价的),并用其遍历整个链表,
再用一个指针needle=dummy指向每次合并后的链表的尾节点,用于将每次合并后的链表与前面的链表连接起来;
小循环的条件是temp!=null,即用temp指针对整个链表进行一次遍历:
用指针head1指向待合并的第一个子链表头节点,令temp = cut(temp, size),用指针head2指向待合并的第二个子链表头节点,令temp = cut(temp, size),
合并两个子链表,并用needle指针连接上,再将needle指针移动到尾节点;
每次小循环结束后,还要令size *= 2;
结束全部循环之后,返回dummy.next即可;
自定义方法:
ListNode cut(ListNode temp, int size):令temp指针后移size-1次(或长度不够到了空节点)至当前子链表尾节点,将尾节点next指针置空,再令temp移动到下一个子链表的头节点。返回最终的temp指针;
ListNode merge(ListNode head1, head2):合并两个链表head1、head2,返回新的头节点;
Ⅲ. 冒泡排序——不推荐
冒泡排序的核心思想:
遍历序列,通过对不满足排序规则的相邻元素进行两两交换,实现一次遍历确定一个待排序序列中最大/最小元素的最终位置,当某次遍历一次交换都没有进行时,说明此时序列已经有序;
冒泡排序和简单选择排序比较接近,都是一次遍历确定一个当前最大/最小元素的最终位置,不过冒泡排序是可以中途停止的,不一定非要遍历n-1次;
算法注意点(这里以默认的递增排序为例):
交换节点需要三个指针,先定义前两个指针pre、cur,算法结束条件需要一个记录本次遍历中交换元素次数的变量times,并初始化为非零值;
大循环是控制是否要再对链表进行一次遍历,条件是times != 0:
每次对链表进行遍历前都需要对pre、cur、times进行初始化:pre = dummy,cur = dummy.next,times = 0;
小循环是完成一次对链表从头到尾的遍历,条件是cur != null && cur.next != null:
定义第三个指针tmp = cur.next,若cur.val <= tmp.val,无需交换元素,令pre、cur右移一位即可;
若cur.val >= tmp.val,则需要交换节点:cur.next = tmp.next; tmp.next = cur; pre.next = tmp; 最后再令pre = tmp; times++;(这里和两两交换节点不同)
结束全部循环之后,返回dummy.next即可;
Ⅳ. 简单选择排序——不推荐
简单选择排序的核心思想:
每遍历一次未排序的序列,就确定一个最大/最小元素,并将其与其应在的位置上的原来的元素交换,遍历n-1次后确定所有元素的最终位置;
简单选择排序的特点在于无论输入是否基本有序,其完成排序的时间复杂度都为O(n²);
算法注意点:
用单链表实现的话,因为交换节点需要其上一个节点的指针,而在单链表中很难在确定链表中值最大/最小的节点的同时还记录其上一个节点的指针,所以不太好实现;
不过如果降低要求,只交换节点的值的话,那还是很好实现的:
一个指针pre用于控制遍历链表的起始节点,大循环条件为:pre != null:
一个指针cur用于本次对链表的遍历初始化为pre,一个指针min记录本次遍历中值最小的节点,也初始化为pre,
小循环的条件为:cur != null && cur.next != null:
若cur.next的值小于min的值,则更新min,cur右移一位;
退出小循环后,对pre节点和min节点的值进行交换,令pre右移一位;
结束全部循环之后,返回dummy.next即可;
Ⅴ. 希尔排序——不适用于单链表,因为单链表只能通过遍历的方式获取当前节点往后第d个节点,这会让算法的时间复杂度高一个量级
Ⅵ. 快速排序——不适用于单链表,因为快速排序的一次划分需要low、high指针自外向内遍历,而单链表只能从头向尾遍历,不能反向遍历(其实交换节点在这里也非常不方便,最多只能交换节点值);
Ⅶ. 堆排序——单链表不适合用节点建立大/小根堆,如果只用节点值的话,那算法本身其实和数组排序也没什么区别了;
Ⅷ. 基数排序——同Ⅶ,只用到了节点值,和数组排序无异;
6. 两数相加链表版
#2:两数相加链表版——和合并链表相似,但需要注意的是即使只剩一个链表,仍需考虑进位而不能直接拼接,包括拼接完所有链表之后,如果进位仍为1,则还要再新建一个节点;
三、哈希表
1.求两个数组的交集
①应用场景
求两个数组的交集部分,先用哈希表统计一个数组元素出现的次数,再遍历另一个数组,判断每个元素是否属于交集,若属于则令哈希表中的value--;——#350
2.字母异位词
①定义
若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词;
这一问题可以通过用哈希表统计字符串中每个字符出现的次数来解决,
若限定字符在一个较小范围内,比如只能是小写字母,则用int[26]数组来统计每个字符出现的次数更方便,字符 - 'a' 对应数组下标;——如#49
②注意
找出一个字符串中和另一个字符串是字母异位词的全部子串,则还可以结合滑动窗口来避免重复遍历——#438
3.两数之和
①应用场景
在一个数组中寻找唯一一个两数之和等于target的组合的下标,数组中的同一个数不能重复使用——#1
②注意
因为要求两个数的下标,所以Map的key需要是数组的元素值,value需要是数组的元素下标,这样一来就没法体现每个元素的出现次数了,
为了保证同一元素不会在答案中出现两次,不能先将数组全部存入哈希表再查找,只能每遍历一个数组元素nums[i],就查找target-nums[i]是否存在,若存在直接返回下标组合,不存在则将当前元素放入哈希表;
4. 几数之和总结
题目内容通常为:给定一个数组(一般来说数组都是无序的,因为有序直接用双指针就行了),求其中的几个元素之和等于target的组合;
根据结果是否允许有重复解,这类题通常可以分成两类:
①允许有重复解:既然不用考虑去重操作,那直接使用哈希表就行了,例如#1两数之和、#454四数相加Ⅱ;
②不允许有重复解:需要去重,那只能用双指针法了(要先对数组排序),例如#15三数之和、#18四数之和;
5. 最长连续序列
#128. 最长连续序列——通过!set.contains(nums[i] - 1)确保当前元素是连续序列中的最小值,避免对连续序列从中间开始遍历;
6. 划分字母区间
① 案例
Ⅰ. #763:将字符串划分为同一字母最多出现在一个片段中的子串,求每个子串的长度
——用一个Map记录字符串中每个字符最后出现的下标,用一个Set记录当前子串中有哪些字符不是在字符串中最后一次出现,
当当前子串所有字符均是最后一次出现时(Set为空时),就找到一个满足条件的子串了
四、字符串
1.翻转字符串
①应用场景
#541:在一个字符串中每隔2k个字符就翻转前k个字符,不足k个也全部翻转——用left,right指针控制每次做翻转的区间,不断对left,right进行更新即可;
2.分割字符串
①应用场景
②注意
如何解决开头和结尾的空格,以及中间的多个连续空格,还有注意不要将空字符串存入list中;
3.KMP算法及其应用
①应用场景
Ⅰ.#28:一个字符串与另一个字符串做匹配,求满足条件的最小下标——标准字符串匹配,用KPM算法;
Ⅱ. #459:判断一个字符串能否由其一个子串重复多次拼接而成——见下面的结论;
②注意
Ⅰ. 生成next[]数组:
next[]数组中next[i]表示当前字符串的下标0到i的子串,其最大公共前后缀长度为next[i],
Ⅱ. 在字符串匹配时,当第i个字符不匹配时,
若i == 0,则i仍等于0不变,
若i > 0,则令needle字符串指针由 i 不断回退到next[i - 1],直至该字符匹配,或是i == 0;
(例如"ababaa"和"ababababaa"进行匹配,"ababaa"的next数组为[0, 0, 1, 2, 3, 1],用i指向ababaa",j指向"ababababaa",
当i = 5, j = 5时,'a'和'b'不匹配,此时令i = next[4] = 3,'b'和'b'匹配,继续进行下一步)
Ⅱ.#459涉及一个结论,即当一个字符串可以由其一个子串重复多次拼接而成时,如果将两个 s连在一起,并移除第一个和最后一个字符,那么得到的字符串一定包含 s,即 s 是它的一个子串,
分析:假设字符串s是由s1+s2组成的,s+s后,str就变成了s1+s2+s1+s2,去掉首尾,破环了首尾的s1和s2,变成了s3+s2+s1+s4,此时str中间就是s2+s1,如果s是循环字串,也就是s1=N*s2,所以str中间的s2+s1就和原字符串
相等如果s不是循环字串,s1!=N*s2,那么s1+s2是不等于s2+s1的,也就是str中间不包含s;
4. 最长特殊序列
#522:
5. 字符串转整数
①应用场景
Ⅰ. #8:字符串转整数——字符串由空格+符号位+数字字符+其它字符组成,还要防止溢出;
五、栈与队列
1. 设计栈or队列
①应用场景
Ⅰ.用两个栈实现队列的先进先出功能;——#232
一个in栈,一个out栈
入队时元素压入in栈,
出队或访问队头元素时,
若out栈为空,则将in栈元素依次压入out栈,再对out栈执行出栈操作;
若out栈不为空,则直接对out栈执行出栈;
Ⅱ.用一个队列实现栈的后进先出功能;——#225
插入元素后,将队列中原本的元素依次弹出再压入队列,时间复杂度为O(n);
Ⅲ. 设计一个可以用O(1)时间复杂度获取当前栈内最小值的最小栈——#155
②注意
Ⅰ.栈和队列都推荐使用Deque的ArrayDeque,Deque提供了push()、pop()和peek()方法来模拟栈,也可以用offerLast()、pollFirst()、peekFirst()方法来模拟队列;
——LinkedList同时实现了List和Deque两个接口
2. 后缀表达式(逆波兰表达式)求值
①应用场景
Ⅰ. 后缀表达式求值——#150
初始化一个操作数栈;
从左到右依次扫描后缀表达式的各个元素,并做以下处理:
若遇到操作数,就将其压入栈中;
若遇到运算符,则依次从栈中弹出两个操作数,以先出栈的元素为右操作数,后出栈的元素为左操作数,执行相应运算再将结果压入栈中;
重复步骤2直至扫描完后缀表达式中的全部元素;
Ⅱ. 中缀表达式求值——暂未看到例题
初始化两个栈:一个操作数栈,一个运算符栈;
从左到右逐个扫描中缀表达式中的元素,并进行以下操作:
遇到操作数,直接压入操作数栈;
遇到界限符,若是左括号"("则直接入栈,若是右括号")"则依次弹出栈中的元素直到遇到一个左括号,则停止弹出并删去栈中的左括号;
遇到运算符,依次弹出栈中优先级高于或等于当前运算符的所有运算符,直到遇到左括号或是优先级低于当前运算符的运算符,则停止弹出并将当前运算符压入栈中;
每弹出一个运算符,就从操作数栈中弹出两个操作数,以先出栈的元素作为右操作数,后出栈的作为左操作数,执行相应计算并将结果压入栈中;
重复上述操作直至全部元素扫描完毕,则栈中最后一个数即为计算结果;
Ⅲ. 字符串解码——#394
需要两个栈分别存储每个字符串及其出现的次数,需要两个变量分别记录当前遍历到的数字和字符串,
遇到左括号就将这两个变量分别入栈,
遇到右括号就从两个栈中分别弹出str和k,将str和res重复k次拼接起来,变为新的res;
②注意
String转int,注意对负数的处理;
3. 优先队列PriorityQueue
①应用场景
Ⅰ. 求数组中出现频率最高的前k个元素——#347
Ⅱ. 求滑动窗口内的全部最大值;——#239
Ⅲ. #23(hard):合并K个升序链表——用一个优先队列存储每个子链表的第一个节点,每次从优先队列中取出堆顶节点,如果堆顶节点之后还有节点,则将那个节点加入到优先队列中;
②注意
Ⅰ. 先用哈希表统计每种数出现的次数,再使用优先队列PriorityQueue,把key和value以数组形式存入递减优先队列中,最后从优先队列队头取出k组数,其key即为所求的数;
Ⅱ. 优先队列PriorityQueue自定义比较器lambda表达式写法:
PriorityQueue<ListNode> queue2 = new PriorityQueue<>((o1, o2) -> o2.val - o1.val);Ⅲ. PriorityQueue的使用:
——初始化时,添加参数Comparator,自定义比较方法,默认o1-o2,即最小值为最优先,如果改为o2 - o1就是最大值最优先;
——入队offer出队poll,查看队头peek,和普通队列一样;
4. 其它栈&队列题
①应用场景
Ⅰ. #32(hard):最长有效括号——栈底存储最近的不满足匹配条件的右括号的下标(初始填入一个-1),遍历字符串,对于左括号,直接将其下标入栈,
对于右括号,首先弹出一个栈顶元素,
如果此时栈为空说明弹出的是不符合条件的右括号,没有和当前右括号匹配的左括号,则将此右括号压入栈中,
如果此时栈不为空,说明有和当前右括号匹配的左括号,更新res即可;
六、二叉树
1. 前、后序遍历
①迭代解法2的实现
Ⅰ. 前序遍历:使用一个辅助栈,首先将非空root压入栈中,退出循环的条件是栈为空,
循环中:从栈中弹出一个节点作为root,直接将root.val加入到res中,之后依次将root的孩子节点从右到左压入栈中;
——无条件将栈顶元素加到res中体现了“中”在最前,孩子节点从右到左依次压入栈中体现了“先左后右”的顺序;
Ⅱ. 后序遍历:使用一个辅助栈,首先将非空root压入栈中,再创建一个节点prev用来存放上一个遍历到的节点,退出循环的条件仍是栈为空,
循环中:使用peek()查看栈顶元素,若其孩子节点为空,或最右侧的孩子节点已经遍历到(对于二叉树,分为右孩子存在和右孩子不存在两种情况,对于n叉树,可以直接获取最右侧孩子节点),
则从弹出栈顶元素作为root并将其值放入res中,并更新prev,否则依次将root的孩子节点从右到左压入栈中(不同于前序遍历不管是否将root添加到res中都会对其孩子节点做判断,后序遍历中,如果成功将root添加到res中,说明其所有孩子节点必然都已经加入到res中,这两个操作是互斥的,是if-else的关系);
——有条件将栈顶元素加到res中体现了“中”在最后,孩子节点从右到左依次压入栈中体现了“先左后右”的顺序;
②应用场景
Ⅰ. 二叉树/多叉树的前、后序遍历——#144、#145、#589、#590;
Ⅱ. #114:二叉树按照前序遍历顺序原地展开为单链表——既然是要按照前序遍历的顺序,也就是中、左、右,
具体来说,如果root.left不为空,则将root.right接到左子树先序遍历的最后一个节点的right指针,也就是沿着root.left的右指针一直遍历到最后一个节点;
之后将root.right改为root.left,将root.left置空,最后让root往右遍历一个节点;
(如果root.left为空则直接让root往右遍历一个节点)
2. 中序遍历&层序遍历
①中序遍历
迭代解法1的实现——#94
中序遍历:使用一个辅助栈,退出循环的条件是root为空且栈为空,
循环中:首先不断遍历左孩子节点并压入栈中,直至root为空,然后从栈中弹出一个节点作为root,将其值加入res中,然后令root指向右孩子节点;
——遍历左孩子并只将栈顶元素加入到res中,体现了左在前、中在后,之后将root指向右孩子,体现了右最后;
②层序遍历
Ⅰ. 基本题型——#102. 二叉树的层序遍历;
Ⅱ. 扩展题型——#199. 二叉树的右视图;
Ⅲ. 求二叉树的最小深度——#111,DFS递归法和求最大深度的区别在于:除了Math.max变为Math.min外,当求最小深度时,对于左、右子树中之只有一个为空的情况,其最小深度不应等于0+1,而是那个不为空的子树的最小深度+1(因为深度指的是根节点到叶子节点的节点数)
还有,求最小深度DFS递归不是最好的解法,因为DFS需要遍历所有节点,但实际使用BFS层序遍历只要找到第一个叶子节点返回其深度即为最小深度;
Ⅳ. 求二叉树的最大宽度——#662:为了避免层数较大时栈溢出,不能存入空节点,而要使用Pair存入非空节点及其下标,最大宽度即为最右侧下标-最左侧下标+1;
也可以用两个Deque,一个存非空节点,一个存对应的节点下标,每一层的宽度就是其最外侧两个节点下标的差值+1;
3. 填充每个节点的右指针——迭代法完成
①应用场景
Ⅰ.完全二叉树的情况;——#116,大循环中node指针(初始化为root)沿着左子树遍历;小循环中temp指针(初始化为node)沿着next指针向右遍历,利用本题完全二叉树的特点,每遍历一个节点都可以将其左右孩子节点连接起来,若temp.next不为空,则还可以将其右孩子与右孩子的右侧一个节点连接起来;大循环的退出条件为node.left == null,小循环的退出条件为temp == null;
Ⅱ.普通二叉树的情况;——#117,大循环是使用node指针(初始化为root)遍历每一层的第一个非空节点;小循环是使用temp指针(初始化为dummy头节点)遍历node节点下一层的全部节点并连接起来;
大循环跳转至每层的第一个节点的方法是令node = dummy.next,小循环通过使用头节点解决了只有左孩子或只有右孩子的特殊情况,通过node = node.next向右遍历;
大小循环的退出条件均为node == null;
②注意
难点在于O(1)空间复杂度的解法
4. 对两个二叉树进行处理
①应用场景
Ⅰ.判断一个二叉树是否是对称二叉树——#101,DFS自顶向下递归,可以转化为判断左、右子树是否对称,关键代码:return dfs(left.left,right.right) && dfs(left.right,right.left);
Ⅱ. 合并两个二叉树——#617,DFS根据root1、root2是否为null分情况讨论,均为null直接返回null,一个为null则直接令root等于不为null的节点,均不为null则令root.val等于二者之和,并对左右子树进行递归;
②总结
对两个二叉树进行处理的题目,通常可以分成下列几种情况进行讨论:
若二者均为空,则。。。
若其中一个为空,则。。。
若二者均不为空,则。。。
5. 二叉树的路径
①应用场景
Ⅰ. 求一个二叉树的所有根节点到叶子节点的路径——#257,DFS自顶向下递归,若节点为空直接返回,若是叶子节点则添加val值并将path加到结果集中,其他情况则添加val值和"->",继续递归,
为确保return时路径参数仍是之前的参数:用String path作为传参(当前函数范围内的变量,所有递归栈均可见,不能在函数内对传参进行修改),在修改时应当创建一个局部变量StringBuilder sb,若成功进入递归则传入参数sb.toString(),失败return则path并未发生改变;
Ⅱ. 求二叉树中所有 从根节点到叶子节点 路径总和等于给定目标和的路径——#113,DFS自顶向下递归,若节点为空直接返回,若节点为叶子节点且val等于targetSum,则将当前list加入到结果集中,最后对左、右孩子递归;
为确保回溯时使用的list不会被后续递归操作修改,需要在每个递归方法中创建一个局部变量List,所有修改都是对这个局部变量进行;
Ⅲ. #437:求二叉树中和为targetSum的向下队列的路径的数量(不要求以根节点开始,也不要求叶子节点结束,只要求向下连续即可)
——本题虽然是二叉树的题,但其用到的大前缀-小前缀=后缀的思想和#560如出一辙,通过前缀和思想可以从递归解法的O(n²)优化为O(n);
——注意:①前缀和可能超过int范围,所以用long;
②prefix应当在初始化时存入(0, 1)键值对;
③为了保证求的都是向下队列,当本节点所在子树遍历完时,应令和为sum的前缀和数量-1;
②注意
Ⅰ. 对于前两道题,可以用一个参数记录整个递归过程中的路径,为了避免前一条路径被后面的节点复用,应当在递归遍历完之后,去掉路径中当前节点产生的痕迹,
具体方法可以是每次都重新创建一个新的路径,如下:
if (root == null) {
return;
}
List<Integer> list = new ArrayList<>(path);
list.add(root.val);
if (root.left == null && root.right == null) {
if (targetSum == root.val) {
res.add(new ArrayList<Integer>(list));
}
return;
}
dfs(root.left, targetSum - root.val, list);
dfs(root.right, targetSum - root.val, list);也可以是每次递归完之后,从路径中去掉当前节点产生的痕迹,如下:(#257难以判断root.val的字符串长度是多少所以不好去掉,只能用上面的方法)
if (root == null) {
return;
}
targetSum -= root.val;
path.add(root.val);
if (root.left == null && root.right == null) {
if (targetSum == 0) {
res.add(new ArrayList<>(path));
}
}
dfs(root.left, targetSum, path);
dfs(root.right, targetSum, path);
path.remove(path.size() - 1);
Ⅱ. 第三道题#437的路径不需要在叶子节点结束,且不求路径本身,而是求满足条件的路径和的数量,
所以这里使用Map来记录路径前缀和,Map也需要像上面的路径一样避免被后面的路径复用,因为Map没有提供对应的构造器,所以还是在递归完直接令对应key的value减一比较方便;
6. 求二叉树的各种参数
①应用场景
Ⅰ.判断一个二叉树是否是另一个二叉树的子树——#572,掌握迭代法带空节点前序遍历+KMP算法;
Ⅱ.求一个完全二叉树的节点个数——#222,O(log²n)解法:根据二进制节点序号判断节点是否存在+通过二分法判断完全二叉树的叶子节点是否存在来确定节点数量;
Ⅲ. 求二叉树的左叶子之和——#404,左叶子:是左孩子(不是右孩子也不能是根节点),且是叶子节点,除此之外就没有其他要求了,DFS自顶向下递归,本题的特点在于还要延伸对左、右孩子进行判断;
Ⅳ. 对二叉树进行翻转——#226,DFS自顶向下递归,因为java的参数传递只支持值传递,因此要实现翻转必须以root.left = 、root.right = 的方式对节点指针进行交换;
7. 构造二叉树
①应用场景
Ⅰ. 用中序遍历序列和前序遍历序列构造唯一二叉树——#106,DFS自顶向下递归,根据前序遍历序列的首个节点即为根节点,一次递归确定一个当前范围内的根节点,然后递归地确定左右孩子节点(要给出左右子树在后、中序遍历中的范围);
——注意后续遍历是“左右中”,所以递归先确定右子树root.right范围,再确定左子树root.left范围
Ⅱ. 用一个序列,按照最大的元素作为根节点的原则,保持序列原有的左右顺序构造唯一的最大二叉树——#654,可以使用#105的递归法,时间复杂度为O(n²),还有复杂度更低的单调栈法,时间复杂度为O(n):
——单调栈:即单调递减栈,while(栈不为空)
若新元素小于栈顶元素,直接入栈,退出循环;
若新元素不小于栈顶元素,则弹出栈顶元素,继续循环;
若栈为空,新元素直接入栈;
——本题的单调栈法在上面的基础上,添加步骤:若新节点小于栈顶节点,则令栈顶节点.right = 新节点,反之令新节点.left = 栈顶元素,最后返回栈底的节点即为根节点;
Ⅲ. 用一个有序数组构造一棵平衡的BST——#108,DFS自顶向下递归,需要同时保证平衡和BST两个要求(每次从中间选取节点构造头节点可保证平衡,左右两侧分别构造左右子树保证BST的左小右大);
②总结
构造各种二叉树的算法都是通过DFS自顶向下递归实现的;
8. BST二叉搜索树
①应用场景
Ⅰ. 判断一棵树是否为BST——#98,迭代法中序遍历序列递增,用一个遍历pre记录上一次遍历到的节点值,为保证没有相等元素,将pre初始化为Long.MIN_VALUE,
也可以用递归法,用参数max、min记录当前子树的最大、最小值,确保BST的根节点大于其左子树的全部节点值,右子树同理,;
Ⅱ. 求BST中的众数——#501,对BST进行中序遍历,将问题变为求有序序列中的众数,要求不能使用哈希表和递归栈、结果集以外的辅助空间:
用pre记录上一个遍历的元素,count记录当前元素出现的次数,maxCount记录当前最大出现次数,
若当前元素与pre相同,count++即可,反之令pre = 当前元素、count重置为1,
若count > maxCount,清空结果集,将当前元素加入到结果集,更新maxCount,若count == maxCount,将当前元素加入到结果集即可;
Ⅲ. 求BST中两个节点的最近公共祖先——#235,根据BST左小右大的特性,根节点值比p、q更大说明都在根节点左子树中,反之都在右子树中,由此自上而下地遍历,找到第一个满足根节点值介于二者之间的根节点,即为最近公共祖先;
Ⅳ. 删除BST中指定节点——#450,如果当前节点root即为待删除节点,则分下列三种情况:若左子树为空,则返回root.right即可;若右子树为空,则返回root.left即可,
若均不为空,则找出root左子树中值最接近的节点pre,令pre.right=root.right,再返回root.left;
如果待删除节点在当前节点的左子树中,则令root.left=递归调用当前函数在左子树中删除该节点,在右子树中同理,最后返回root;
Ⅴ. 删除BST中超出指定范围的所有节点——#669,利用BST左小右大的特性进行DFS递归,若root节点值小于左边界,则直接返回对root.right的递归结果(删除包括根节点在内的整个左子树),大于右边界同理,
若root节点值在边界范围内,则对其左右孩子递归地进行修剪操作,最后返回root;
Ⅵ. 向BST中插入节点——#701,BST插入节点最方便的方法就是只生成叶子节点插入;
②总结
BST相关算法题总体来说通常从两个方面考察;
Ⅰ. BST的中序遍历序列递增,将问题转换为对递增数组的处理,例如判断BST、求BST序列中的众数集合;
Ⅱ. 利用BST节点左小右大的特性,使用DFS自顶向下递归解决问题,例如求BST中两个节点的最近公共祖先、删除BST中的某个指定节点、删除BST中指定范围外的节点、BST插入节点;
9. 自底向上的DFS递归法
①应用场景
Ⅰ. 判断一个二叉树是否是平衡二叉树——#110,getHeight():若root为空返回0,先递归求左右子树的高度,再分情况讨论:若当前节点不满足平衡条件(左、右子树中有一个不平衡或高度差大于1),返回-1,否则返回当前节点高度;
Ⅱ. 求二叉树的最大深度(最大深度也即是高度)——#104,就是#110的子题;
Ⅲ. 求二叉树中两个节点的最近公共祖先——#236,退出条件:如果root为null,或是p、q中的一个,立即返回root,否则递归地求p、q在root左右子树中的最近公共祖先,最后分情况讨论返回值;
Ⅳ. #124:求二叉树中最大路径和——注意root作为根节点和作为孩子节点时计算最大路径和是不一样的,所以单独用一个变量记录所有节点作为根节点时的最大路径和,递归时返回作为孩子节点的路径和;
Ⅴ. #543:求二叉树的直径,也就是最大路径长度——#124的简化版;
10. 特殊树题
①应用场景
Ⅰ. #208:构造一个只包含小写字母的前缀树,每个前缀树节点包含一个长度为26的数组记录当前字符是哪个、一个flag记录当前字符是否为字符串的最后一个字符;
——插入字符串和搜索字符串都是沿着node.children[c - 'a']遍历即可;
11. 总结
①二叉树题型分类
二叉树的算法题大致可以分为下面几种:
Ⅰ. 前、后序遍历+中序遍历+层序遍历,及其衍生题——#144、#145、#589、#590、#94、#102、#199、#111、#662;
Ⅱ. 填充二叉树节点的右指针(要求用O(1)空间复杂度完成)——#116完全二叉树、#117普通二叉树;——三指针+dummy节点,O(1)空间复杂度解决
Ⅲ. 对两个二叉树进行处理——#101判断一个二叉树是否是对称二叉树、#617合并两个二叉树;——分全为空、一个为空、均不为空几种情况讨论
Ⅳ. 求二叉树的路径——#257求一个二叉树的所有根节点到叶子节点的路径、#113求二叉树中所有路径总和等于给定目标和的路径、#437求二叉树中满足条件的路径和的数量(不要从根节点开始,也不要求叶子节点结束);
Ⅴ. 构造二叉树——#106用中序遍历序列和后序遍历序列构造唯一二叉树、#654用一个序列构造唯一的最大二叉树、#108用一个有序数组构造一棵平衡的BST;——每次创建一个当前范围的根节点,再分范围进行递归
Ⅵ. BST搜索二叉树相关——#98判断一棵树是否为BST、#501求BST中的众数、#235求BST中两个节点的最近公共祖先、#450删除BST中指定节点、#669删除BST中超出指定范围的所有节点、#701向BST中插入节点;
——一类是根据BST中序遍历序列为升序的特性,将问题转换为对升序序列的处理,一类是根据BST左小右大的特性,使用DFS自顶向下递归;
Ⅶ. DFS自底向上递归——#110判断一个二叉树是否是平衡二叉树、#104求二叉树的最大深度(最大深度也即是高度)、#236求二叉树中两个节点的最近公共祖先、#124求二叉树最大路径和hard、#543二叉树的直径、#114二叉树展开为链表;——先递归,再分情况讨论
Ⅷ. 求二叉树的一些参数——#572判断一个二叉树是否是另一个二叉树的子树、#222求一个完全二叉树的节点个数、#404求二叉树的左叶子之和、#226对二叉树进行翻转;
②解题思路
Ⅰ. 是否属于前、中、后、层序遍历或是衍生题;——#144、#145、#589、#590、#114二叉树先序展开为单链表、#94、#102、#199、#111、#662;
Ⅱ. 是否属于特殊题型:填充右指针——#116完全二叉树、#117普通二叉树;
对两个二叉树进行处理——#101判断一个二叉树是否是对称二叉树、#617合并两个二叉树;
求二叉树的路径——#257求一个二叉树的所有根节点到叶子节点的路径、#113求二叉树中所有 从根节点到叶子节点 路径总和等于给定目标和的路径;
构造二叉树——#106用中序遍历序列和后序遍历序列构造唯一二叉树、#654用一个序列构造唯一的最大二叉树、#108用一个有序数组构造一棵平衡的BST;
BST根据中序遍历序列为升序的特性,将问题转换为对升序序列的处理——#98判断一棵树是否为BST、#501求BST中的众数;
DFS自底向上递归——#110判断一个二叉树是否是平衡二叉树、#104求二叉树的最大深度(最大深度也即是高度)、#236求二叉树中两个节点的最近公共祖先、#124求二叉树最大路径和hard、#543二叉树的直径、;
Ⅲ. 剩下的基本都是通过DFS自顶向下递归完成——#235求BST中两个节点的最近公共祖先、#450删除BST中指定节点、#669删除BST中超出指定范围的所有节点、#701向BST中插入节点、#572判断一个二叉树是否是另一个二叉树的子树、#222求一个完全二叉树的节点个数、#404求二叉树的左叶子之和、#226对二叉树进行翻转;
Ⅳ. 特殊树题——#208构造前缀树;
③DFS自顶向下递归、自底向上递归
Ⅰ. DFS向下递归
关键思路:当前递归函数的作用是什么?——输入什么参数,返回什么结果,或是产生什么效果
DFS自顶向下递归的通用写法:
若root为空,则返回,有可能还有其他操作;——确定退出条件
若root满足条件,则对root进行对应处理;——对root分情况讨论确定返回值
若root既不为空,也不满足条件,则对其左、右子树进行递归;——递归到左右子树
Ⅱ. DFS自底向上递归
适用于那些只有在遍历到叶子节点才能确定状态/数值的情况,例如求树的深度/高度、是否平衡(几乎等价于求高度,多了一个不平衡返回-1)、求两个节点在二叉树中的最近公共祖先;
DFS自底向上递归的通用写法:首先确定退出条件;
然后递归调用当前方法(一般都是对左、右子树进行递归),得到中间结果;
最后根据中间结果分情况确定返回值;
七、回溯算法
对12道经典回溯算法题的总结分析见excel“回溯递归法”

总结
无任何条件的求全部子集(元素不可重复使用)
class Solution {
List<List<Integer>> res = new ArrayList<>();
List<Integer> path = new ArrayList<>();
public List<List<Integer>> subsets(int[] nums) {
backtrack(nums, 0);
return res;
}
private void backtrack(int[] nums, int start) {
res.add(new ArrayList<Integer>(path));
for (int i = start; i < nums.length; i++) {
path.add(nums[i]);
backtrack(nums, i + 1);
path.remove(path.size() - 1);
}
}
}①组合&子集问题——#77、#39、#40、#216、#78、#90、#491
Ⅰ. 需要一个start参数保证不向前回溯,for循环中令i = start,递归时若元素不可重复使用则传入i + 1,反之传入 i ;
Ⅱ. 若有长度限制,则加入res的条件为path.size() == nums.length,for循环内以if (path.size()+集合剩余元素数量<len) break;进行剪枝;
若有组合总和限制,则添加一个sum参数记录当前path元素和,加入res的条件为sum == target,for循环内以if (sum + nums[i] > target) break;进行剪枝(先对nums进行排序确保升序),递归时传入sum + nums[i];
Ⅲ. 若数组中存在重复元素需要去重,则先对nums进行排序确保升序,然后在for循环内以if (i > start && nums[i] == nums[i - 1]) continue;进行去重;
Ⅳ. #491非递减子序列属于比较特殊的子集问题:其除了需要子集问题的Ⅰstart参数、Ⅱ长度限制外;
还需要保证序列递增,这个通过在for循环内使用if (!path.isEmpty() && nums[i] < path.get(path.size() - 1)) continue;来剪枝即可;
除此之外,因为本题不允许对原数组进行排序,又需要进行去重,故需要在for循环外添加一个HashSet,在for循环内通过if (set.contains(nums[i])) continue;进行去重,递归时添加元素也需要set.add(nums[i]),去除元素时则不需要从set中剔除;
②全排列问题——#46、#47、#17
Ⅰ. 不需要start参数了,for循环中令i = 0,加入res的条件为path.size() == nums.length,不过此时不需要根据长度进行剪枝了;
Ⅱ. 添加一个used[]数组,记录数组中每个元素是否被使用过,for循环内要用if(used[i]) continue;进行剪枝,除此之外,在向path中添加和删除元素时,也需要分别令used[i] = true、used[i] = false;
Ⅲ. 若数组中存在重复元素需要去重,则先对nums进行排序确保升序,然后在for循环内以if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1] continue;进行去重;
Ⅳ. #17电话号码组合属于加了一层中间变量的排列问题:本题只有长度要求,其它什么要求都没有,
对于中间变量,我们可以采取使用参数index遍历字符串digits,使用for循环遍历digits.get(index)对应的字符串(用一个Map记录映射关系),不需要剪枝,正常添加元素、递归、剔除元素即可;
③分割字符串问题——#131、#93
Ⅰ. 需要一个index参数来控制分割字符串的起点:加入res的基础条件变为index == str.length(),当然根据题目条件可能还有其他条件,例如IP地址的数量;
Ⅱ. for循环现在用于控制对字符串取子串的长度,起始i = 1,终止条件为index + i <= str.length(),
需要判断的对象变为当前子串str.substring(index, index + i),可在for循环内根据题目条件(回文、IP地址等)进行剪枝,向path中添加、剔除的对象也是子串;
④其它回溯递归题
Ⅰ. #22:生成所有有效的括号组合——分别用两个参数left、right记录左、右括号的数量,在left < n的情况下先对左括号进行回溯递归,然后在right < left的情况下,对右括号进行回溯递归,这样就能保证生成的括号组合都是有效的,最后当path的长度等于2n时终止本次递归,将path放入res中;
Ⅱ. #79:单词搜索——递归参数:x, y表示当前递归的数组位置,index表示当前递归到字符串的第几位,退出条件:如果index == word.length(),说明已经完全匹配,直接返回true;
如果(x, y)超出范围,或是该位置的字符不等于word.charAt(index),直接结束递归返回false;剩下的情况就是没有完全匹配完,但当前字符是匹配的,接下来开始回溯递归:
首先为了避免重复遍历,先令board[x][y] = '0',然后分别对(x, y)四周的字符进行递归,用 || 连接,得到最终结果res,最后回溯将board[x][y]再置为原来的字符word.charAt(index),最终返回res;
Ⅲ. #51( hard ):N皇后——用一个数组queens记录每个皇后的位置,数组下标表示行号,数组元素值表示列号,用三个Set分别记录当前已被其它皇后占用的列号、正斜号(等于行号-列号)、反斜号(等于行号+列号);
递归参数为行号,递归退出条件为行号等于皇后数,此时用queens生成对应的字符串列表加入到结果中,否则对所有列进行遍历:
首先剪枝:判断当前列号、正斜号、反斜号是否已被占用,如果是则continue;
然后回溯递归:在queens中添加一个新皇后,在三个Set中添加被占用的列号、正斜号、反斜号,递归时令行号+1,回溯则是删除刚才的新皇后,同时从三个Set中删除被占用的列号、正斜号、反斜号;
Ⅳ. #797:从起点到终点所有可能的路径——用一个参数node表示当前遍历到二维数组的哪一行进行回溯递归,退出条件为node == graph.length,无需剪枝去重,for循环遍历数组的第node行的每个数,递归时令node=num;
八、贪心算法
1.根据序列有序的特性,使用贪心思想先处理最大/最小的数据
①应用场景
Ⅰ.求数组k次取反后最大的数组和——#1005,注意在遍历数组时记下绝对值最小的数,后续若剩余取反次数为奇数则对此数取反;
Ⅱ.求小于一个数的最大的单调递增数——#738,找到第一个不满足递增条件(包括等于)的数的下标,将在其之前递减(不包括等于)的数依次减一,在减到不满足条件后,再进一位,将之后的数均改为9;
Ⅲ.根据身高重建队列——#406,个高的不受个矮的影响,所以个高的先排,前面人少的在前,前面人多的在后,后者不会影响到前者的位置,所以前面人少的先排;
Ⅳ.对多个区间取交集——#452,按左端点升序排序,然后依次对相邻区间取交集,左端点递增的两个存在重叠的区间取交集的原则:交集左端点等于较大者,也即第二个区间的左端点,右端点等于两个区间右端点中的较小者;
Ⅴ.对多个区间进行合并——#56,合并区间相当于对存在交集的两个区间取并集,思路和#452很像,按左端点升序排序,不过对两个存在重叠的区间进行合并(取并集)的原则和取交集恰好相反:
并集左端点等于较小者,也即第一个区间的左端点,右端点等于两个区间右端点中的较大者;
Ⅵ.求要使多个区间之间互相不存在交集,需要去除的最少区间数量——#435,这里为了保证去除的区间数最少,应当按右端点升序排序,然后依次比较两个区间是否存在交集(方法和上面是一样的),若存在就去掉第二个区间
(直接用第一个区间的右端点覆盖第二个区间的右端点即可),同时令结果+1;
②注意
Ⅰ.Arrays.sort()排序方法默认递增排序,若需自定义,需重写new Comparator()中的compare()方法;
二维数组自定义排序:
Arrays.sort(people, new Comparator<int[]>(){
public int compare(int[] nums1, int[] nums2){
if(nums1[0] != nums2[0]){
return nums2[0] - nums1[0];
}else{
return nums1[1] - nums2[1];
}
}
});
Ⅱ.compare()方法注意o1-o2可能会溢出,可以换一种写法:
Arrays.sort(points, new Comparator<int[]>(){
public int compare(int[] nums1, int[] nums2){
//这里为了避免极端例子[[-2147483646,-2147483645],[2147483646,2147483647]]溢出,不能这么写
// return nums1[0] - nums2[0];
if(nums1[0] > nums2[0]){
return 1;
}else{
return -1;
}
}
});
2.统计一个数组中摆动序列的最长长度——#376
①注意
难点在于如何处理下列情况:比如1,1,2,2,3,如何做到既要保证遍历到第一个2时会count++,又要保证遍历到3时不会count++
3.跳跃游戏
①应用场景
数组元素表示当前位置可跳跃的长度,求跳跃到数组末尾的最小步数——#45
②注意
在每一步能走范围内的每一格计算下一步最远走多远,每次在当前步数走到最后一格时,更新下一步最远能走多远,若下一步可以走到终点则直接返回步数;
如此便可以在O(n)的时间复杂度内计算出最小步数;
4.加油站——#134
①注意
Ⅰ.首先是特殊情况的判断:若gas之和小于cost之和,则必然不存在走完一圈的路径,直接返回-1;
Ⅱ.然后是必然不可能走完一圈的点:remains[i]小于0,或者在i > 0的情况下,remains[i]虽然大于0,但remains[i - 1]也大于零(remains[i - 1]>0都走不通,储备更少的remains[i]必然不可能走通);
Ⅲ.最后从可能走完的点出发后,当发现走不完时,i可以直接跳到发现已经走不下去的点(因为前面能走完说明都是有储备的,突然走不完说明走不下去的那个点消耗非常大,应该直接跳到那个点的下个点重新开始判断);
5.最长递增子序列——#300
①注意
给定应该数组,求其中递增子序列的最大长度——#300,推荐使用贪心算法+二分法查找,用一个List暂存递增序列,遍历数组,若数组元素大于List尾元素,则直接加入List,否则就二分法查找List中第一个大于它的元素并替换掉(若有相等元素则无需进行任何操作),最后List的长度就是最大递增子序列长度;
九.动态规划
1.一些基础题
①应用场景
Ⅰ. 求带障碍物的情况下在一个二维数组中从(0,0)到(n,n)的不同路径——#63,注意对障碍物在边界条件和动态转移方程中的处理;
Ⅱ. 将一个整数拆分为若干整数,如何使其乘积最大——#343,要想乘积最大,每次拆分要么拆出2、要么拆出3,对剩余部分要么直接算乘积、要么继续拆分;
2.0-1背包
①应用场景
Ⅰ.给定0-1背包,求和为target的组合是否存在——#416、#1049,f[i][j]表示在nums的0到i-1下标内,能否以0-1背包的形式凑齐和为j的组合;
Ⅱ.给定0-1背包,求和为target的组合的数量——#494,f[i][j]表示在数组下标为0到i-1范围内的元素,凑成和为j的组合的数量;
Ⅲ.给定0-1背包,求和小于target的组合最大元素数量——#474,f[i][j][k]表示数组在0到i-1下标内的元素,在最多有j个0和k个1的条件下,子集的最大长度;
②特殊情况
Ⅰ. sum % 2 != 0;
Ⅱ. sum < target || (sum - target) % 2 != 0;
Ⅲ. 无;
③边界条件
Ⅰ. 无;
Ⅱ. dp[0] = 1;
Ⅲ. 无;
④动态转移方程
Ⅰ. 根据 j 和nums[i ]之间的大小关系,分为==、>两种情况,==时直接令dp[j]=true,>时令dp[j] = dp[j] || dp[j - nums[i]],<时dp[j]不变;
Ⅱ. 根据 j 和nums[i ]之间的大小关系,,若满足j >= nums[i],则令dp[j] += dp[j - nums[i]],不满足则dp[j]不变;
Ⅲ. 根据 j 与temp[0]之间、 k 与temp[1]之间的大小关系,若满足j >= temp[0] && k >= temp[1],则令dp[j][k] = Math.max(dp[j][k], dp[j - temp[0]][k - temp[1]] + 1),不满足则dp[j]不变;
3.完全背包
①应用场景
Ⅰ. 给定完全背包,求和为amount的组合数量——#518,相当于0-1背包同类型题如#494中,不对j进行逆序遍历;
Ⅱ. 给定完全背包,求和为target的排列数量——#377,和#518的区别在于,本题的组合对序列顺序有要求,解决办法为交换两层循环的先后顺序;
Ⅲ. 给定完全背包,求和为amount的组合的最小元素数量——#322,相当于0-1背包同类型题如#474中,不对j进行逆序遍历;
(注意这里是最小长度,所以对f[]数组初始化时需要做一些特殊处理:dp[0]=0,其余均初始化为Integer.MAX_VALUE-1,返回值也需要进行判断)
Ⅳ. 自行构建完全背包,求和为n的组合的最小元素数量——#279,和#322的区别在于,①要自行构建背包,②返回值不需要进行判断了;
Ⅴ. 给定完全背包,求能否凑成指定排列——#139,相当于0-1背包同类型题如#416中,不对j进行逆序遍历,同时这里的组合有序,需要将两个for循环交换顺序;
(区别在于这里是比较字符串是否相等,动态转移方程的条件变为子串是否相等)
②背包问题总结(0-1背包和完全背包)
#518,给定完全背包求和为target的组合的数量
class Solution {
public int change(int amount, int[] coins) {
int[] dp = new int[amount + 1];
dp[0] = 1;
for (int i = 0; i < coins.length; i++) {
for (int j = 0; j <= amount; j++) {
if (j >= coins[i]) {
dp[j] += dp[j - coins[i]];
}
}
}
return dp[amount];
}
}
首先,目前见过的背包问题主要分为三类:
Ⅰ. 给定背包和目标target,求和为target的组合的最大数量——#494、#518、#377;
Ⅱ. 给定背包和目标target,求和为target的组合是否存在——#416、#1049、#139;
Ⅲ. 给定背包和目标target,求和为target的组合的最大/最小元素数量——#474、#322、#279;
其中背包又可以分为0-1背包和完全背包;
dp[]数组:一律设为dp[n + 1];
边界条件:
第一类问题需要注意的是初始化边界条件dp[0] = 1,
第二类问题没有边界条件,
第三类问题对于最大元素数量,不需要边界条件,对于最小元素数量,则需要dp[0]=0,其余均初始化为Integer.MAX_VALUE-1,返回值也需要进行判断;
for循环:(这里我们默认用 i 对背包进行遍历,用 j 对target进行遍历)
这三类问题for循环完全一样,其中,
对于0-1背包需要将对 j 逆序遍历,对于完全背包则是对 j 顺序遍历;
若结果无顺序之分,则对 i 的遍历在外,j 在内,若结果有顺序之分则反过来;
动态转移方程:(动态转移方程要会随机应变,如果不是求数字之和就要变换成同等的表达式,例如#139就是用子串内容是否相等 替代 数字大小是否相等)
第一类问题:if(j >= nums[i]) dp[j] += dp[j - nums[i]];
第二类问题:if (nums[i] == j) dp[j] = true; else if (nums[i] < j) dp[j] = dp[j] || dp[j - nums[i]];
if (j >= coins[i]) dp[j] = Math.min(dp[j], dp[j - coins[i]] + 1);(这里列举的是最小的情况,最大将min换成max即可)
4.打家劫舍系列
①应用场景
Ⅰ.给定一个数组,不可连续两个都抢,求可抢的最大值——#198,简单题,要求用O(1)空间复杂度完成;
Ⅱ.在Ⅰ的基础上,增加头尾不可同时抢的要求——#213,简单题,分别在[0,n-2]和[1,n-1]两个区间上去抢,取其中的较大者即可,注意对数组长度为1或2两种特殊情况的处理;
Ⅲ.给定一棵二叉树,要求任意相连的节点不可同时抢,求可抢的最大值——#337,抢root必不抢左右孩子,不抢root则左右孩子可抢可不抢,利用此特性,在后序遍历的同时,求每个子树在头节点抢与不抢两种情况下的
最大值,分别用两个HashMap记录,最后取root抢与不抢两种情况下的较大值(注意在postorder()中,若节点为空,查询哈希表应返回默认值0);
5.股票系列
①应用场景
Ⅰ.给定一个数组表示每天的股价,限制只允许买卖一次,求最大收益——#121,简单题,用一个变量记录当前遍历到的最低股价,再用一个变量记录当前最大收益;
Ⅱ.给定一个数组表示每天的股价,允许买卖无限次,求最大收益——#122,简单题,用一个变量buy记录当天进行买入时的最大收益,再用一个变量sell记录当天进行卖出时的最大收益,遍历整个数组,最后返回sell;
Ⅲ.给定一个数组表示每天的股价,限制只允许买卖两次,求最大收益——#123,用四个变量分别记录当天第一次买入、第一次卖出、第二次买入、第二次卖出时的最大收益,遍历整个数组,最后返回第一次卖出和第二次卖出最大收益中的较大者;
Ⅳ.给定一个数组表示每天的股价,限制最大买卖次数为k次,求最大收益——#188,用两个数组分别记录每次买入、卖出时的最大收益,遍历整个数组,注意第一次买卖和后续买卖的初始化与动态转移方程的区别;
Ⅴ.给定一个数组表示每天的股价,允许买卖无限次,但加了一个冷静期,求最大收益——#309,多用一个变量表示冷静期即可,注意动态转移全部完成前中各变量不应更新,所以需要中间变量暂存;
Ⅵ.给定一个数组表示每天的股价,允许买卖无限次,但每卖出一次需要交一次手续费,求最大收益——#714,简单题,每次卖出算上手续费即可;
②系列问题核心思路——以最能体现这一思路的#188、#309母题为例
题目限制几次买入卖出,就创建几个buy、sell变量,记录每天第i次买入、卖出时的最大收益,并在for循环中对它们进行更新:
初始化时,buy[i] = -prices[0], sell[i] = 0;
for循环中,对于第一次买入卖出:buy[i] = Math.max(buy[i], -price); sell[i] = Math.max(sell[i], buy[i] + price);
对于后续买入卖出:buy[i] = Math.max(buy[i], sell[i - 1] - price); sell[i] = Math.max(sell[i], buy[i] + price);
如果是无限次,如#122,则没有第一次和后续之分,一律按buy = Math.max(buy, sell - price); sell = Math.max(sell, buy + price);来处理;
最后取所有次卖出中收益最大者;
对于含冷静期的题,如#309,则应添加一个freeze变量表示当前为冷静期时的最大收益,buy-sell-buy-sell的流程变成buy-sell-freeze-buy-sell-freeze
初始化时,freeze = 0;
for循环中,buy = Math.max(buy, freeze - price); freeze = Math.max(freeze, sell);
最后取所有次卖出、冷静期中收益最大者;
6.子序列
①应用场景
Ⅰ.给定两个数组,求二者的最大公共子序列(不要求连续)的长度——#1143,依次对两个字符串的每个前缀子串的尾字符做判断,f[i][j]表示text1的0到i-1的子串,与text2的0到j-1的子串的最大公共子序列长度,若尾字符相同,则基于f[i-1][j-1]再加一,若尾字符不相同,则i与j任意一个回退一位的f值中的较大者即为f[i][j](因为这里子序列不要求连续,所以可以继承前面的最大值,如果要求连续则不可以);
Ⅱ.给定一个字符串,求其中最长回文子序列(不要求连续)的长度——#516,f[i][j]表示在下标i到j的子串中最长回文子序列的长度,因为在进行动态转移时要根据内部子串f[i+1][j-1]的长度确定f[i][j],为了保证f[i+1][j-1]在f[i][j]之前就已确定,这里对i要从len-1开始从右向左遍历,对j要从i+1开始从左向右遍历,当i和j处的字符相等时,f[i][j]=f[i+1][j-1]+2,不相等时,f[i][j]等于i右移一位或是j左移一位后的子串的最长回文长度中的较大者;
(注意#516有边界条件:dp[i][i] = 1)
Ⅲ. #NC323:要让区间内的括号匹配至少需要添加多少括号——边界条件、遍历方式都和求最大回文子序列非常相似,不过动态转移方程有所不同,
7.连续子序列
①应用场景
Ⅰ.给定两个数组,求二者的最大公共连续子序列的长度——#718,思路和#1143基本一致,区别在于这里要求是连续子序列;
——故在动态转移方程中,若i字符不等于j字符,则什么都不做(其实是令f[i][j]=0,不过初始值就为0所以可以省略),
——且最终的返回值不再是f[m][n],而应用一个变量res记录每次f[i][j]发生增加时的最大值;
Ⅱ.给定一个字符串,求其中最长回文子串(要求连续)——#5,思路和#516相近,区别在于这里要求是连续子串;
——当i字符等于j字符时,若i进一位j退一位之后的子串存在,且不为回文串,则f[i][j]仍等于0;if (i + 1 < j - 1 && f[i + 1][j - 1] == 0) f[i][j] = 0;
(例如"aacbaa",虽然1、4下标字符相同,但f[1][4]不应等于f[2][3]+2=2,这样会进一步导致f[0][5]=f[1][4]+2=4,而实际上根据f[i][j]的含义它俩都应等于0),其他情况下可以正常令f[i][j] = f[i + 1][j - 1] + 2;
——故在动态转移方程中,若i字符不等于j字符,则什么都不做(其实是令f[i][j]=0,不过初始值就为0所以可以省略)
——本题要求的返回值是最长的回文子串本身,故用一个引用res初始化为第一个字符,当f[i][j]大于res的长度时更新res if (f[i][j] > res.length()) res = s.substring(i, j+ 1);,最终返回res;
Ⅲ.求一个字符串中所有回文子串的总数——#647,使用中心拓展法分奇偶两种情况讨论,可以用O(n²)的时间复杂度找出全部回文子串;
8. 经典DP之编辑距离
①应用场景
Ⅰ. #72:求一个字符串通过增加、删除、替换字符变为另一个字符串所需的最少步数——dp[i][j]表示word1的0到i - 1的子串变换为word2的0到j - 1的子串最少需要多少步;
边界条件为i = 0、j = 0,此时dp[i][j]就等于字串长度;
动态转移方程:dp[i - 1][j - 1] + 1表示进行一次修改操作、dp[i - 1][j] + 1表示进行一次删除操作、dp[i][j - 1] + 1表示进行一次添加操作,
先取dp[i][j]为三种操作中的最小值,然后如果word1的i - 1字符==word2的j - 1字符,则令dp[i][j]取dpi][j]和dp[i - 1][j - 1]中的最小值,
最后返回dp[m][n],表示word1的0到m - 1的子串变换为word2的0到n - 1的子串最少需要多少步;
十、单调栈
①单调栈说明
单调递减栈的作用:可以找出序列中左侧和右侧第一个大于它的元素;
单调递增栈的作用:可以找出序列中左侧和右侧第一个小于它的元素;
②递减栈应用场景
Ⅰ.找出循环数组中每个数的第一个大于它的数——#503,不需要两次遍历,只需要一次从0遍历到2 * len - 2即可,下标取i % len;
Ⅱ.接雨水——#42(hard),i为右边界,第一个弹出的栈顶元素为底,剩下的栈顶元素为左边界,由这三者可进一步算出宽度、高度和接水面积;
③递增栈应用场景
Ⅰ. #84(hard):求柱状图中面积最大的矩形——left[]:左侧第一个高度比自己小的柱子的下标,如果都比自己大就是-1,right[]:右侧第一个高度比自己小的柱子的下标,如果都比自己大就是n,
( right[i]-left[i]-1 ) * height[i]即为 i 所在的矩形的最大面积;
——对每个柱形条来说,高度为heights[i]的最大矩形=heights[i]*(右侧第一个高度小于其的下标 - 左侧第一个高度小于其的下标 - 1);
而要求出这两个下标,可以使用递增栈,当当前元素高度>=栈顶元素高度时,可以确定当前元素左侧第一个高度小于其的下标为栈顶元素,之后将当前元素入栈,退出循环;
当当前元素高度<栈顶元素高度时,可以确定栈顶元素右侧第一个高度小于其的下标,此时令栈顶元素出栈,继续循环;
最后在所有高度的最大矩形中取最大值即可;
十一、图论
1. 岛屿问题
①题型分析
②应用场景
Ⅰ. #463:求所有岛屿的周长和——先计算单个值为1的格子的周长(看四周格子,如果四周格子超出范围、或是为0是海面,就令周长+1,为1或2都表示是陆地,周长不能+1);
然后递归计算每个格子所在独立岛屿的周长(如果超出范围、或是值不为1,说明该格子不存在岛屿或是已被其它岛屿占用,直接返回0,否则就令该格子等于2表示已被占用,接着令当前格子所在独立岛屿的周长,等于当前格子周长+所有相连的值为1的格子的周长之和);
最后遍历整个数组,计算所有独立岛屿的周长之和;
Ⅱ. #827(hard):求添加一个格子后的最大岛面积——首先遍历数组,计算每个独立岛的面积,为了区分不同岛,应当依次将其所在格子填为2、3、4 ... ,并将序号和岛面积存入一个哈希表中;
边界条件1:如果哈希表长度为0,说明没有岛屿,直接返回允许填的岛面积1;
然后再次遍历数组,开始填岛,对于值为0可以填的格子,依次判断其四周格子:如果没有超出范围,且不为0,就将其序号放入一个Set中(因为重复的序号代表是相同的岛,不能重复算面积),之后遍历Set,求其序号在哈希表中对应的岛面积,最后+1填岛面积,用res记录所有填岛情况下的最大面积;
边界条件2:如果res仍是初始值0,说明所有格子都不为0,全为陆地1,此时应当都被填为了2,故返回mp.get(2),否则直接返回res;
Ⅲ. #200:求岛屿数量——很简单,每遍历一个岛就将格子都改为2,找出为1的格子的数量即为岛屿数量;
Ⅳ #695:求最大岛屿面积——#827的简化版,直接求最大岛屿面积即可;
2. 图的层序遍历
①应用场景
Ⅰ. #994:腐烂的橘子——复杂版的二叉树层序遍历,即图的层序遍历,首先遍历整个网格,找出所有为0的节点,并将其唯一序号行数*col+列数存入dq和mp,
然后开始有条件的层序遍历(只遍历为2的节点),在每一层的遍历中,对于每个为2的节点,都应对其四周进行rot操作;
最后遍历网格,如果还有为1的元素,直接返回-1,否则取所有为2的元素中rot层数最大者;
3. 图的拓扑排序
①应用场景
Ⅰ. #207:课程表,标准的拓扑排序——用一个二维List来存储图,行号表示边的起点,内部List存储边的终点,
用一个数组indegree来存储每个节点的入度,数组下标表示节点号,
再用一个队列queue来存储入度为0的节点,用一个数visited记录队列中总共弹出节点的总数;
当queue不为空时,每次从队头弹出一个节点,visited++,同时遍历所有以这个节点为起点的边,令这些边的终点入度都减一,若减为0就加入到queue中;
最后看弹出节点数是否等于图的总节点数;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号