Caffeine本地缓存
一、Caffeine系统介绍
1.Caffeine本地缓存的两个缺点以及解决办法

解决1:可以为每个key设置单独的过期时间——expireAfter+cache.policy().expireVariably().ifPresent
查看代码
package com.tzc;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.Expiry;
import com.github.benmanes.caffeine.cache.Policy;
import com.github.benmanes.caffeine.cache.stats.StatsCounter;
import org.checkerframework.checker.index.qual.NonNegative;
import org.checkerframework.checker.nullness.qual.NonNull;
import org.junit.jupiter.api.Test;
import java.util.concurrent.TimeUnit;
import java.util.function.Consumer;
import java.util.function.Supplier;
public class CaffeineApiTest {
@Test
public void test1() throws InterruptedException {
Cache<String, Integer> cache = Caffeine.newBuilder()
.maximumSize(1000)
.recordStats()
// .expireAfterAccess(10, TimeUnit.SECONDS)
.expireAfter(new Expiry<String, Integer>() {
@Override
public long expireAfterCreate(@NonNull String s, @NonNull Integer integer, long l) {
return l;
}
@Override
public long expireAfterUpdate(@NonNull String s, @NonNull Integer integer, long l, @NonNegative long l1) {
return l1;
}
@Override
public long expireAfterRead(@NonNull String s, @NonNull Integer integer, long l, @NonNegative long l1) {
return l1;
}
})
.build();
// 一般将键值对放入缓存的方法(不单独为每个键值对提供过期时间配置)
cache.put("k", 5);
System.out.println("k: " + cache.getIfPresent("k"));
System.out.println("cache hit rate: " + cache.stats().hitRate());
// 为每一组键值对设置相应的过期时间的方法(需要在创建缓存时使用expireAfter自定义过期策略,不能使用expireAfter等过期策略)
cache.policy().expireVariably().ifPresent(stringIntegerVarExpiration -> {
stringIntegerVarExpiration.put("k1", 10, 5, TimeUnit.SECONDS);
stringIntegerVarExpiration.put("k2", 20, 10, TimeUnit.SECONDS);
});
Thread.sleep(6000);
System.out.println("k1: " + cache.getIfPresent("k1"));
System.out.println("cache hit rate: " + cache.stats().hitRate());
System.out.println("k2: " + cache.getIfPresent("k2"));
System.out.println("cache hit rate: " + cache.stats().hitRate());
}
}
解决2:可以设置内存上限的淘汰方式——maximumWeight+weigher
查看代码
@Test
public void test2() throws InterruptedException {
Cache<String, Integer> cache = Caffeine.newBuilder()
// .maximumSize(1000)
.recordStats()
// 规定内存上限,超过内存则进行淘汰(①不可与maximumSize同时使用; ②必须再加上weigher, 配置value占用内存大小的计算方式)
// 单位应该是B,一个Integer占16B
.maximumWeight(20L)
.weigher(new Weigher<String, Integer>() {
@Override
public @NonNegative int weigh(@NonNull String key, @NonNull Integer value) {
return Math.toIntExact(RamUsageEstimator.sizeOf(value));
}
})
.evictionListener(new RemovalListener<String, Integer>() {
@Override
public void onRemoval(@Nullable String key, @Nullable Integer value, @NonNull RemovalCause cause) {
System.out.println("移除了" + key + ",value: " + value + ",cause: " + cause + ",estimate size: " + Math.toIntExact(RamUsageEstimator.sizeOf(value)));
}
})
// .expireAfterAccess(10, TimeUnit.SECONDS)
.build();
cache.put("k", 5);
cache.put("k1", 5);
cache.put("k2", 5);
cache.put("k3", 5);
// System.out.println("k: " + cache.getIfPresent("k"));
}
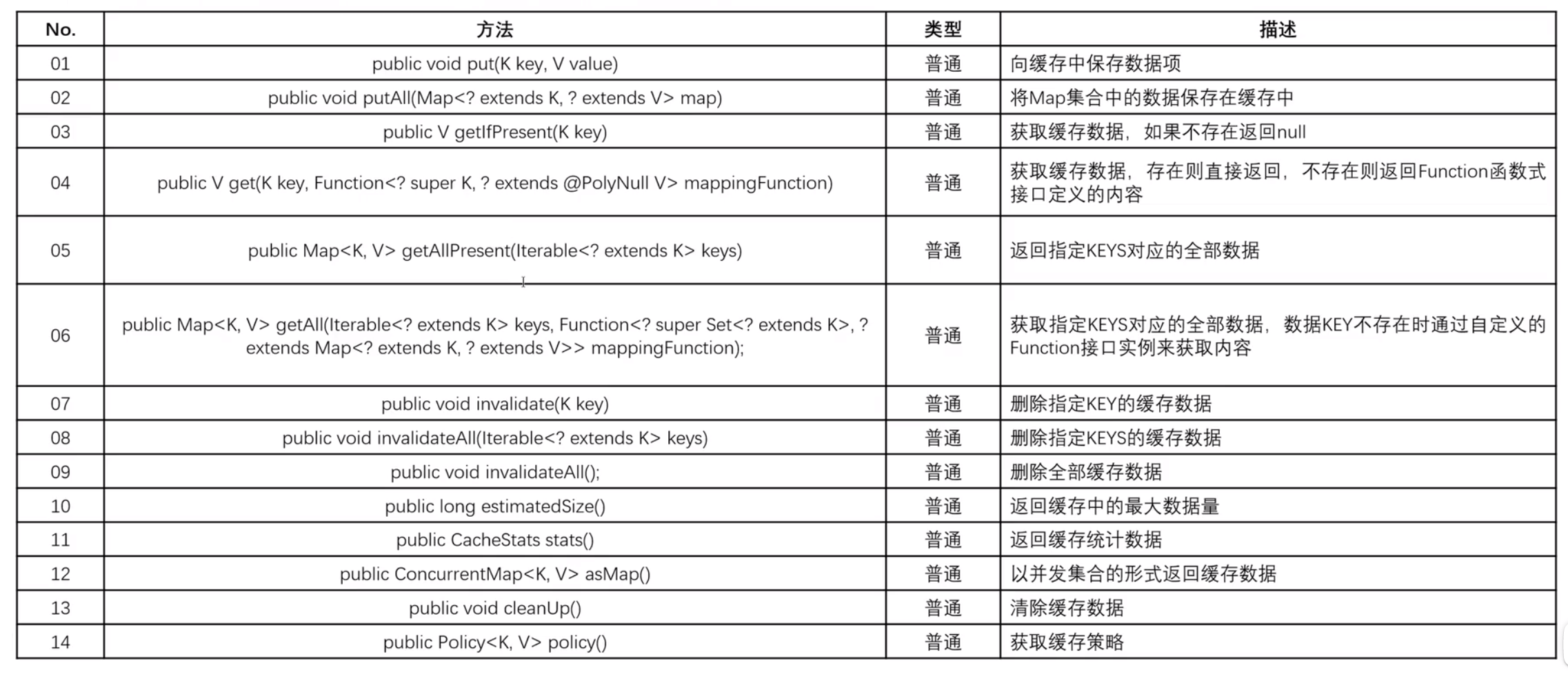
2.com.github.benmanes.caffeine.cache.Cache接口
①com.github.benmanes.caffeine.cache.Cache接口全部方法
所有与缓存相关的处理方法都是在这个接口中定义的
②Caffeine工具类中用于构造Cache的方法(1中已经展示了大部分方法)
Caffeine 类使用了建造者模式,有如下配置参数:
- expireAfterWrite:写入间隔多久淘汰;
- expireAfterAccess:最后访问后间隔多久淘汰;
- refreshAfterWrite:写入后间隔多久刷新,支持异步刷新和同步刷新,如果和 expireAfterWrite 组合使用,能够保证即使该缓存访问不到、也能在固定时间间隔后被淘汰,否则如果单独使用容易造成OOM,使用refreshAfterWrite时必须指定一个CacheLoader;
- expireAfter:自定义淘汰策略,该策略下 Caffeine 通过时间轮算法来实现不同key 的不同过期时间;
- maximumSize:缓存 key 的最大个数;
- weakKeys:key设置为弱引用,在 GC 时可以直接淘汰;
- weakValues:value设置为弱引用,在 GC 时可以直接淘汰;
- softValues:value设置为软引用,在内存溢出前可以直接淘汰;
- executor:选择自定义的线程池,默认的线程池实现是 ForkJoinPool.commonPool();
- maximumWeight:设置缓存最大权重;
- weigher:设置具体key权重;
- recordStats:缓存的统计数据,比如命中率等;
- removalListener:缓存淘汰监听器(可以自定义当移除缓存项时进行哪些操作,比如输出日志);
3. Caffeine中Cache的四种类型
①Cache(上面的例子中使用的都是Cache)
最普通的一种缓存,无需指定加载方式,需要手动调用put()进行加载。需要注意的是,put()方法对于已存在的key将进行覆盖。
在获取缓存值时,如果想要在缓存值不存在时,原子地将值写入缓存,则可以调用get(key, k -> value)方法,该方法将避免写入竞争——这种情况更推荐使用LoadingCache。
调用invalidate()方法,将手动移除缓存。
多线程情况下,当使用get(key, k -> value)时,如果有另一个线程同时调用本方法进行竞争,则后一线程会被阻塞,直到前一线程更新缓存完成;而若另一线程调用getIfPresent()方法,则会立即返回null,不会被阻塞。
示例
Cache<String, String> cache = Caffeine.newBuilder().build();
cache.getIfPresent("1"); // null
cache.get("1", k -> 1); // 1
cache.getIfPresent("1"); //1
cache.set("1", "2");
cache.getIfPresent("1"); //2
②LoadingCache(LoadingCache是Cache的子接口)
LoadingCache是一种自动加载的缓存。
其和普通缓存不同的地方在于,当缓存不存在/缓存已过期时,若调用get()方法,则会自动调用CacheLoader.load()方法加载最新值。调用getAll()方法将遍历所有的key调用get(),除非实现了CacheLoader.loadAll()方法。
——调用get()或getAll()方法才会触发对CacheLoader.load()方法的调用,如果使用getIfPresent()则会直接返回null
使用LoadingCache时,需要在build()中传入CacheLoader接口,并实现其中的load()方法供缓存缺失时自动加载。
多线程情况下,当两个线程同时调用get(),则后一线程将被阻塞,直至前一线程更新缓存完成。
示例
@Test
public void test3() throws InterruptedException {
LoadingCache<String, Integer> loadingCache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterAccess(3, TimeUnit.SECONDS)
.build(new CacheLoader<String, Integer>() {
@Override
public @Nullable Integer load(@NonNull String key) throws Exception {
TimeUnit.SECONDS.sleep(2);
System.out.println("正在加载数据");
return 114514;
}
});
loadingCache.put("k1", 1);
// 1
System.out.println("读取未过期数据,key:k1,value:" + loadingCache.getIfPresent("k1"));
TimeUnit.SECONDS.sleep(5);
// null
System.out.println("读取已过期数据,key:k1,value:" + loadingCache.getIfPresent("k1"));
// 114514
System.out.println("读取已过期数据,key:k1,value:" + loadingCache.get("k1"));
}
LoadingCache特别实用,我们可以在load方法里配置逻辑,缓存不存在的时候去我们的数据库加载,可以实现多级缓存。
③Async Cache(Async Cache是Cache的同级接口)
AsyncCache是Cache的一个变体,其响应结果均为CompletableFuture,通过这种方式,AsyncCache对异步编程模式进行了适配。默认情况下,缓存计算使用ForkJoinPool.commonPool()作为线程池,如果想要指定线程池,则可以覆盖并实现Caffeine.executor(Executor)方法。
多线程情况下,当两个线程同时调用get(key, k -> value),则会返回同一个CompletableFuture对象。由于返回结果本身不进行阻塞,可以根据业务设计自行选择阻塞等待或者非阻塞。
查看代码
AsyncCache<String, String> cache = Caffeine.newBuilder().buildAsync();
CompletableFuture<String> completableFuture = cache.get(key, k -> "1");
completableFuture.get(); // 阻塞,直至缓存更新完成
④Async Loading Cache(是Async Cache的子接口)
显然这是Loading Cache和Async Cache的功能组合。AsyncLoadingCache支持以异步的方式,对缓存进行自动加载。
类似LoadingCache,同样需要指定CacheLoader,并实现其中的load()方法供缓存缺失时自动加载,该方法将自动在ForkJoinPool.commonPool()线程池中提交。
如果想要指定Executor,则可以实现AsyncCacheLoader().asyncLoad()方法。
查看代码
AsyncLoadingCache<String, String> cache = Caffeine.newBuilder()
.buildAsync(new AsyncCacheLoader<String, String>() {
@Override
// 自定义线程池加载
public @NonNull CompletableFuture<String> asyncLoad(@NonNull String key, @NonNull Executor executor) {
return null;
}
})
//或者使用默认线程池加载(和上面方式二者选其一)
.buildAsync(new CacheLoader<String, String>() {
@Override
public String load(@NonNull String key) throws Exception {
return "456";
}
});
CompletableFuture<String> completableFuture = cache.get(key); // CompletableFuture<String>
completableFuture.get(); // 阻塞,直至缓存更新完成Async Loading Cache也特别实用,有些业务场景我们Load数据的时间会比较长,这时候就可以使用Async Loading Cache,避免Load数据阻塞。
异步加载案例(4_1是非异步的LoadingCahe,4_2是异步加载的AsyncLoadingCache)——必须用getAll()同时查询多组数据才会触发异步
@Test
public void test4_1() throws InterruptedException {
LoadingCache<String, Integer> loadingCache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterAccess(3, TimeUnit.SECONDS)
.build(new CacheLoader<String, Integer>() {
@Override
public @Nullable Integer load(@NonNull String key) throws Exception {
System.out.println("正在加载数据");
TimeUnit.SECONDS.sleep(20);
return 114514;
}
});
loadingCache.put("k1", 1);
loadingCache.put("k2", 2);
loadingCache.put("k3", 3);
TimeUnit.SECONDS.sleep(5);
// LoadingCache没有异步加载能力,三组数据是一个一个加载出来的
for(Map.Entry<String, Integer> entry : loadingCache.getAll(List.of("k1", "k2", "k3")).entrySet()){
System.out.println("读取已过期数据,key:" + entry.getKey() + ",value:" + entry.getValue());
}
}
@Test
public void test4_2() throws InterruptedException, ExecutionException {
AsyncLoadingCache<String, Integer> asyncLoadingCache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterAccess(3, TimeUnit.SECONDS)
.buildAsync((key, executor) ->
CompletableFuture.supplyAsync(() -> {
System.out.println("正在异步加载数据");
try {
TimeUnit.SECONDS.sleep(20);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return 1998;
}));
asyncLoadingCache.put("k1", CompletableFuture.completedFuture(1));
asyncLoadingCache.put("k2", CompletableFuture.completedFuture(2));
asyncLoadingCache.put("k3", CompletableFuture.completedFuture(3));
TimeUnit.SECONDS.sleep(5);
// System.out.println("读取已过期数据,key:k1,value:" + asyncLoadingCache.get("k1").get());
// System.out.println("读取已过期数据,key:k2,value:" + asyncLoadingCache.get("k2").get());
// System.out.println("读取已过期数据,key:k3,value:" + asyncLoadingCache.get("k3").get());
// 使用getAll()来触发异步加载,一个一个使用get()只会按代码顺序一个一个先后执行
// 这里触发了异步加载,三组数据同时加载出来
for(Map.Entry<String, Integer> entry : asyncLoadingCache.getAll(List.of("k1", "k2", "k3")).get().entrySet()){
System.out.println("读取已过期数据,key:" + entry.getKey() + ",value:" + entry.getValue());
}
}
⑤总结
Cache和LoadingCache都属于同步加载的缓存,在多线程的情况下,当两个线程同时调用get()方法时,后一个线程将被阻塞,直至前一个线程完成任务;
AsynCache和AsyncLoadingCache都属于异步加载的缓存,在多线程的情况下,当多个线程同时调用get()方法时,会通过异步加载的方式同时为这些线程返回结果;
——推荐使用LoadingCache或AsyncLoadingCache,功能更完善
——异步加载的性能更优秀,在设备允许的情况下推荐使用异步加载
4.Caffeine的3种回收策略
①基于大小的过期方式
基于大小的回收策略有两种方式:一种是基于缓存数量,一种是基于权重。
查看代码
// 根据缓存的计数进行驱逐
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(10000)
.build(new CacheLoader<String, Object>() {
@Override
public @Nullable Object load(@NonNull String s) {
return "从数据库读取";
}
@Override
public @NonNull Map<@NonNull String, @NonNull Object> loadAll(@NonNull Iterable<? extends @NonNull String> keys) {
return null;
}
});
// 根据缓存的权重来进行驱逐,权重低的会被优先驱逐
LoadingCache<String, Object> cache1 = Caffeine.newBuilder()
.maximumWeight(10000)
.weigher(new Weigher<String, Object>() {
@Override
public @NonNegative int weigh(@NonNull String s, @NonNull Object o) {
return 0;
}
})
.build(new CacheLoader<String, Object>() {
@Override
public @Nullable Object load(@NonNull String s) {
return "从数据库读取";
}
@Override
public @NonNull Map<@NonNull String, @NonNull Object> loadAll(@NonNull Iterable<? extends @NonNull String> keys) {
return null;
}
});maximumWeight与maximumSize不可以同时使用。
②基于时间的过期方式
Caffeine提供了三种定时驱逐策略:
expireAfterAccess(long, TimeUnit):在最后一次访问或者写入后开始计时,在指定的时间后过期。假如一直有请求访问该key,那么这个缓存将一直不会过期。
expireAfterWrite(long, TimeUnit):在最后一次写入缓存后开始计时,在指定的时间后过期。
expireAfter(Expiry):自定义策略,过期时间由Expiry实现独自计算。
查看代码
// 基于不同的到期策略进行退出
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.expireAfter(new Expiry<String, Object>() {
@Override
public long expireAfterCreate(String key, Object value, long currentTime) {
return TimeUnit.SECONDS.toNanos(seconds);
}
@Override
public long expireAfterUpdate(@Nonnull String s, @Nonnull Object o, long l, long l1) {
return 0;
}
@Override
public long expireAfterRead(@Nonnull String s, @Nonnull Object o, long l, long l1) {
return 0;
}
}).build(key -> function(key));
③基于引用的过期方式

注意:AsyncLoadingCache不支持弱引用和软引用。
Caffeine.weakKeys(): 使用弱引用存储key。如果没有其他地方对该key有强引用,那么该缓存就会被垃圾回收器回收。
Caffeine.weakValues() :使用弱引用存储value。如果没有其他地方对该value有强引用,那么该缓存就会被垃圾回收器回收。
Caffeine.softValues() :使用软引用存储value。当内存满了过后,软引用的对象以将使用最近最少使用(least-recently-used ) 的方式进行垃圾回收。由于使用软引用是需要等到内存满了才进行回收,所以我们通常建议给缓存配置一个使用内存的最大值。
Caffeine.weakValues()和Caffeine.softValues()不可以一起使用。
查看代码
// 当key和value都没有引用时驱逐缓存
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.build(key -> function(key));
// 当垃圾收集器需要释放内存时驱逐
LoadingCache<String, Object> cache1 = Caffeine.newBuilder()
.softValues()
.build(key -> function(key));
5.被动刷新机制refreshAfterWrite()
试想这样一种情况:当缓存运行过程中,有些缓存值我们需要定期进行刷新变更。
使用刷新机制refreshAfterWrite(),刷新机制只支持LoadingCache和AsyncLoadingCache。
refreshAfterWrite()方法是一种被动更新,它必须设置CacheLoader,key过期后并不立即刷新value:
1、当过期后第一次调用get()方法时,得到的仍然是过期值,同时异步地对缓存值进行刷新;
2、当过期后第二次调用get()方法时,才会得到更新后的值。
通过覆写CacheLoader.reload()方法,将在刷新时使得旧缓存值参与其中。
查看代码
Caffeine.newBuilder()
.refreshAfterWrite(1,TimeUnit.MINUTES)
.build(new CacheLoader<String, Object>() {
@Override
public @Nullable Object load(@NonNull String s) throws Exception {
return null;
}
@Override
public @Nullable Object reload(@NonNull String key, @NonNull Object oldValue) throws Exception {
return null;
}
});
6.统计recordStats()
Caffeine内置了数据收集功能,通过Caffeine.recordStats()方法,可以打开数据收集。这样Cache.stats()方法将会返回当前缓存的一些统计指标,例如:
- hitRate():查询缓存的命中率
- evictionCount():被驱逐的缓存数量
- averageLoadPenalty():新值被载入的平均耗时
查看代码
Cache<String, String> cache = Caffeine.newBuilder().recordStats().build();
cache.stats(); // 获取统计指标
二、Caffeine缓存核心原理——W-TinyLFU缓存淘汰算法
1.常见缓存淘汰算法的优缺点
考虑因素:实现是否简单、性能开销大不大、缓存命中率如何、能否处理稀疏流量的场景(还分少量和大量)
①FIFO算法
先进先出,实现简单,但命中率非常低,基本不会使用;
②LRU算法——最近最久未使用
保存最近使用过的缓存项,淘汰最久未使用的缓存项;
优点:实现较为简单,性能开销也不大,缓存命中率较高,且可以很好地处理少量稀疏流量的场景(sparse burst,即短时间内使用几次后面就不被使用了);
缺点:未考虑使用频率,当出现大量稀疏流量时,由于缓存空间有限,可能会将使用频率很高的缓存项淘汰掉;
③LFU算法——最不经常使用
保存最近使用频率高的缓存项,淘汰使用频率低的缓存项;
优点:考虑了使用频率,可以处理突发流量的场景;
缺点:统计每个缓存项的使用频率导致性能开销较大,对稀疏流量的场景响应迟钝(因为历史的数据已经积累了很多次计数,新来的数据肯定是排在后续的);
2.Count-Min Sketch(CMS)频率统计算法
为了解决上面介绍的LFU的第一个缺点,caffeine缓存的LFU频率统计方法采用的是Count-Min Sketch算法。该算法借鉴了boomfilter的思想,只不过hash key对应的value不是表示存在的true或false标志,而是一个计数器。它采用了四个hash函数,四个hash函数同时对缓存项key计算hash值,将hash值对应的计数器加一。计数器只有4bit,所以计数器最大只能计数到15,超过15时则保持15不变,不再往上增加计数了。计数器最大只能计数到15,容量超乎预调的小,但是从实际测试来看,效果却超乎预调的好。因为bloomfilter存在positive false的问题(其实就是存在hash冲突),缓存项的频率值取四个计数器的最小值(这就是Count-Min的含义)。当所有计数器值的和超过设定的阈值(默认是缓存项最大数量的10倍)时,所有的计数器值都减到原来的一半。
Count-Min Sketch算法详细实现方案如下:
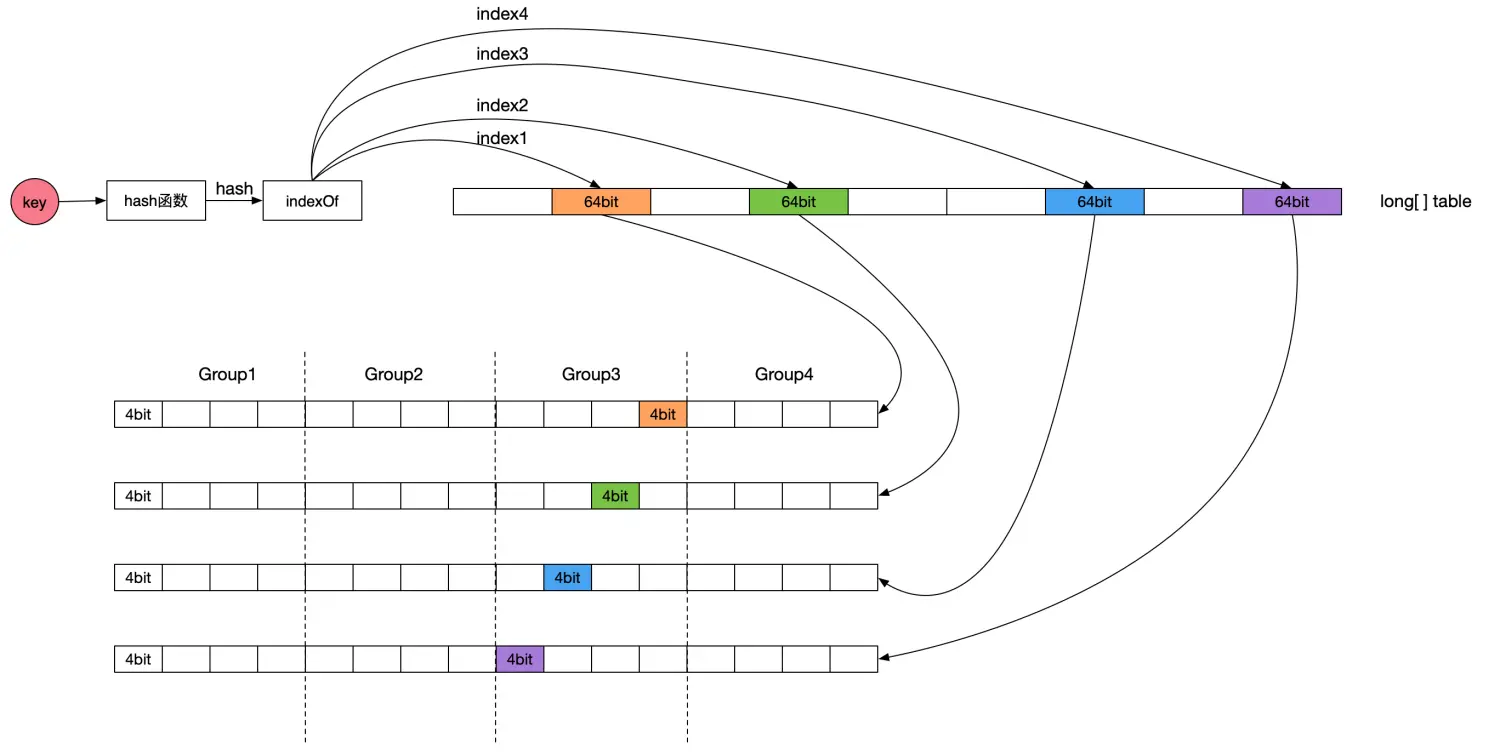
Count-Min Sketch维护了一个long[] table数组,数组的大小为缓存空间容量(缓存项最大数量)向上取整为2的n次方。Count-Min Sketch的计数器是4bit,table数组的每个元素大小是64bit,相当于table元素包含了16个计数器,这16个计数器进一步分为4个group,那么每个group包含4个计数器,正好等于bloom hash函数的个数,同一个key的四个计数器分别使用group内相应位置的计数器。每个table元素包含16个计数器,4个hash计数器在相应table元素内计数器的偏移不一样,可以有效降低hash冲突。
缓存项计数统计过程为:先计算缓存项key的hash值,然后使用4个不同的种子值分别计算得到table数组四个元素的下标。然后根据hash值的低2bit确定table数组元素中的group,那么第一个计数器位置为第一个table数组元素相应group中的第一个计数器,第二个计数器位置为第二个table数组元素相应group中的第二个计数器,第三个计数器位置为第三个table数组元素相应group中的第三个计数器,第四个计数器位置为第四个table数组元素相应group中的第四个计数器。
从Count-Min Sketch频率统计算法描述可知,由于计数器大小只有4bit,极大地降低了LFU频率统计对存储空间的要求。同时,计数器统计上限是15,并在计数总和达到阈值时所有计数器值减半,相当于引入了计数饱和和衰减机制,可以有效解决短时间内突发大流量不能有效淘汰的问题。比如出现了一个突发热点事件,它的访问量是其他事件的成百上千倍,但是该热点事件很快冷却下去,传统的LFU淘汰机制会让该事件的缓存长时间地保留在缓存中而无法淘汰掉,虽然该类型事件已经访问量非常小或无人问津了。
3.W-TinyLFU算法
W-TinyLFU算法的框架如下所示:
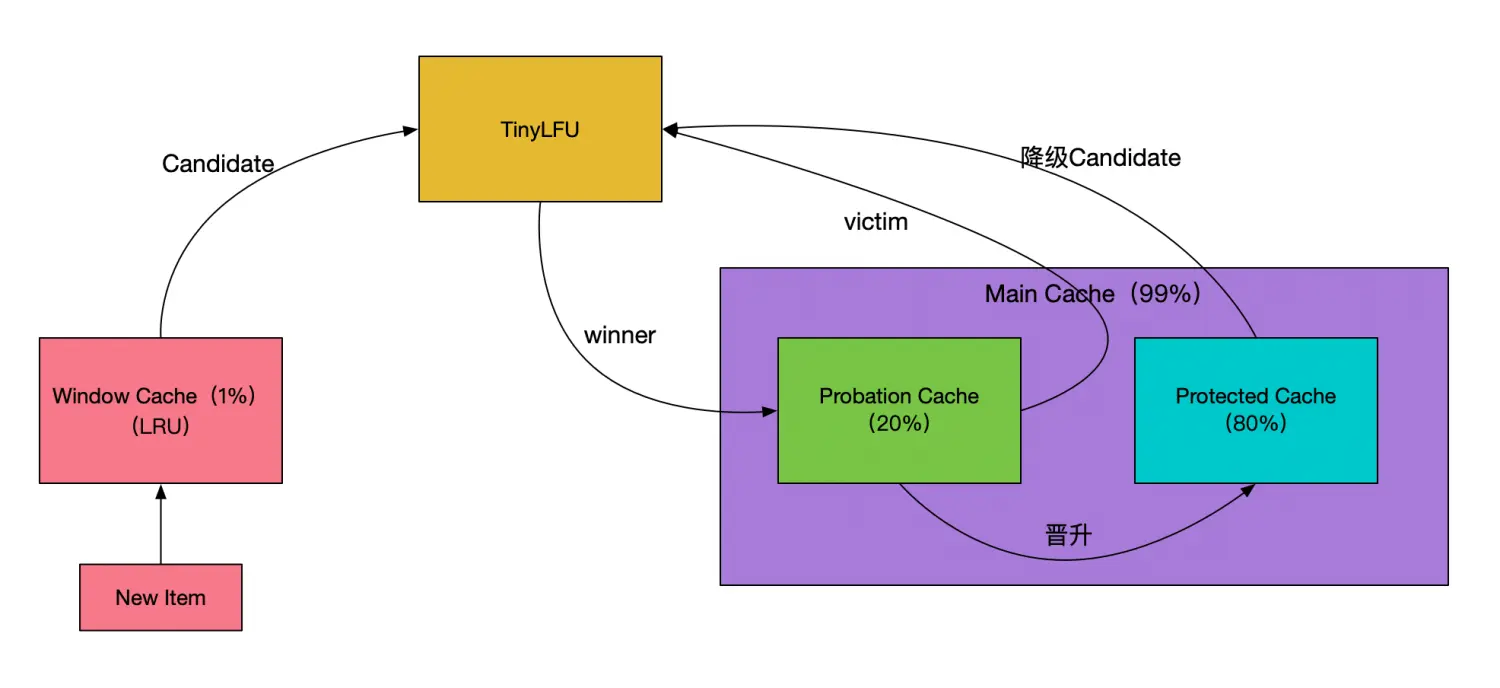



总结:
W-TinyLFU算法集成了LRU和LFU的优点,既有着较低的性能消耗,又有着非常高的缓存命中率,而且能够妥善处理各种稀疏流量的场景,堪称完美;
三、Caffeine缓存中用到的其它优化手段
1.读缓冲和写缓冲
缓存中数据的读写会伴随缓存状态的变更,比如需要更新缓存数据访问的频率、判断数据是否需要淘汰,
一般情况下会将这些状态变更的操作与读写操作放在一起,在一个同步加锁的原子操作中一起完成,但是这样会造成锁竞争,降低了缓存的读写性能;
Caffeine则是使用了缓冲区(Read Buffer & Write Buffer)来记录由于数据读写而产生的状态变更的日志,
在执行读写操作时,先把状态变更信息记录在缓冲区,如何在合适的时机异步、批量地执行缓冲区中的内容(异步数据处理是有可能导致缓存的实际大小超过缓存最大容量的限制的,但多余的数据会很快被清除,影响不大);
其中,读操作产生的状态变更信息存储在环形缓冲区(Ring Buffer)中,Ring Buffer的容量有限,当异步处理的速度跟不上存入数据的时候,后面的状态变更信息就会被忽略,不过对于读操作来说这是可以接受的;
而写操作产生的状态变更信息存储在阻塞队列(MpscGrowableArrayQueue)中,这是一个安全队列,因为写操作是不允许数据丢失的;
——读、写缓冲区的具体实现不太清楚
2.Caffeine的过期策略——时间轮
详见这篇文章:https://www.yuque.com/snailclimb/mf2z3k/oson7u6g1fxzxkt4#8ab79a62
四、SpringBoot集成Caffeine/Redis缓存的流程
1.导入缓存相关依赖、给主启动类加上@EnableCaching注解
<!-- SpringBoot的cache组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<!-- 使用redis缓存所需依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 使用caffeine缓存所需依赖 -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
@SpringBootApplication
@MapperScan("com.tzc.mapper")
@EnableCaching
public class ZCnovelApplication {
public static void main(String[] args) {
SpringApplication.run(ZCnovelApplication.class, args);
}
}
2. 将项目中所以用到的缓存的相关属性都以常量和枚举类的格式存入缓存常量类中
——包括缓存名称、缓存类型(redis 还是 caffeine,如果只用了一种那就没必要了)、ttl、缓存大小等;
CacheConsts
package io.github.xxyopen.novel.core.constant;
/**
* 缓存相关常量
*
* @author xiongxiaoyang
* @date 2022/5/12
*/
public class CacheConsts {
/**
* 本项目 Redis 缓存前缀
*/
public static final String REDIS_CACHE_PREFIX = "Cache::Novel::";
/**
* Caffeine 缓存管理器
*/
public static final String CAFFEINE_CACHE_MANAGER = "caffeineCacheManager";
/**
* Redis 缓存管理器
*/
public static final String REDIS_CACHE_MANAGER = "redisCacheManager";
/**
* 首页小说推荐缓存
*/
public static final String HOME_BOOK_CACHE_NAME = "homeBookCache";
/**
* 最新新闻缓存
*/
public static final String LATEST_NEWS_CACHE_NAME = "latestNewsCache";
/**
* 小说点击榜缓存
*/
public static final String BOOK_VISIT_RANK_CACHE_NAME = "bookVisitRankCache";
/**
* 小说新书榜缓存
*/
public static final String BOOK_NEWEST_RANK_CACHE_NAME = "bookNewestRankCache";
/**
* 小说更新榜缓存
*/
public static final String BOOK_UPDATE_RANK_CACHE_NAME = "bookUpdateRankCache";
/**
* 首页友情链接缓存
*/
public static final String HOME_FRIEND_LINK_CACHE_NAME = "homeFriendLinkCache";
/**
* 小说分类列表缓存
*/
public static final String BOOK_CATEGORY_LIST_CACHE_NAME = "bookCategoryListCache";
/**
* 小说信息缓存
*/
public static final String BOOK_INFO_CACHE_NAME = "bookInfoCache";
/**
* 小说章节缓存
*/
public static final String BOOK_CHAPTER_CACHE_NAME = "bookChapterCache";
/**
* 小说内容缓存
*/
public static final String BOOK_CONTENT_CACHE_NAME = "bookContentCache";
/**
* 最近更新小说ID列表缓存
*/
public static final String LAST_UPDATE_BOOK_ID_LIST_CACHE_NAME = "lastUpdateBookIdListCache";
/**
* 图片验证码缓存 KEY
*/
public static final String IMG_VERIFY_CODE_CACHE_KEY =
REDIS_CACHE_PREFIX + "imgVerifyCodeCache::";
/**
* 用户信息缓存
*/
public static final String USER_INFO_CACHE_NAME = "userInfoCache";
/**
* 作家信息缓存
*/
public static final String AUTHOR_INFO_CACHE_NAME = "authorInfoCache";
/**
* 缓存配置常量
*/
public enum CacheEnum {
HOME_BOOK_CACHE(0, HOME_BOOK_CACHE_NAME, 60 * 60 * 24, 1),
LATEST_NEWS_CACHE(0, LATEST_NEWS_CACHE_NAME, 60 * 10, 1),
BOOK_VISIT_RANK_CACHE(2, BOOK_VISIT_RANK_CACHE_NAME, 60 * 60 * 6, 1),
BOOK_NEWEST_RANK_CACHE(0, BOOK_NEWEST_RANK_CACHE_NAME, 60 * 30, 1),
BOOK_UPDATE_RANK_CACHE(0, BOOK_UPDATE_RANK_CACHE_NAME, 60, 1),
HOME_FRIEND_LINK_CACHE(2, HOME_FRIEND_LINK_CACHE_NAME, 0, 1),
BOOK_CATEGORY_LIST_CACHE(0, BOOK_CATEGORY_LIST_CACHE_NAME, 0, 2),
BOOK_INFO_CACHE(0, BOOK_INFO_CACHE_NAME, 60 * 60 * 18, 500),
BOOK_CHAPTER_CACHE(0, BOOK_CHAPTER_CACHE_NAME, 60 * 60 * 6, 5000),
BOOK_CONTENT_CACHE(2, BOOK_CONTENT_CACHE_NAME, 60 * 60 * 12, 3000),
LAST_UPDATE_BOOK_ID_LIST_CACHE(0, LAST_UPDATE_BOOK_ID_LIST_CACHE_NAME, 60 * 60, 10),
USER_INFO_CACHE(2, USER_INFO_CACHE_NAME, 60 * 60 * 24, 10000),
AUTHOR_INFO_CACHE(2, AUTHOR_INFO_CACHE_NAME, 60 * 60 * 48, 1000);
/**
* 缓存类型 0-本地 1-本地和远程 2-远程
*/
private int type;
/**
* 缓存的名字
*/
private String name;
/**
* 失效时间(秒) 0-永不失效
*/
private int ttl;
/**
* 最大容量
*/
private int maxSize;
CacheEnum(int type, String name, int ttl, int maxSize) {
this.type = type;
this.name = name;
this.ttl = ttl;
this.maxSize = maxSize;
}
public boolean isLocal() {
return type <= 1;
}
public boolean isRemote() {
return type >= 1;
}
public String getName() {
return name;
}
public int getTtl() {
return ttl;
}
public int getMaxSize() {
return maxSize;
}
}
}
Caffeine 类使用了建造者模式,有如下配置参数:
- expireAfterWrite:写入间隔多久淘汰;
- expireAfterAccess:最后访问后间隔多久淘汰;
- refreshAfterWrite:写入后间隔多久刷新,支持异步刷新和同步刷新,如果和 expireAfterWrite 组合使用,能够保证即使该缓存访问不到、也能在固定时间间隔后被淘汰,否则如果单独使用容易造成OOM,使用refreshAfterWrite时必须指定一个CacheLoader;
- expireAfter:自定义淘汰策略,该策略下 Caffeine 通过时间轮算法来实现不同key 的不同过期时间;
- maximumSize:缓存 key 的最大个数;
- weakKeys:key设置为弱引用,在 GC 时可以直接淘汰;
- weakValues:value设置为弱引用,在 GC 时可以直接淘汰;
- softValues:value设置为软引用,在内存溢出前可以直接淘汰;
- executor:选择自定义的线程池,默认的线程池实现是 ForkJoinPool.commonPool();
- maximumWeight:设置缓存最大权重;
- weigher:设置具体key权重;
- recordStats:缓存的统计数据,比如命中率等;
- removalListener:缓存淘汰监听器(可以自定义当移除缓存项时进行哪些操作,比如输出日志);
上面这些属性都可以先以常量的形式存放在此类中,之后在CacheConfig中创建缓存对象时使用这些属性进行初始化;
(也可以在配置文件application.yml中进行配置,但如果缓存数量较多的话,一个个配置就会比较低效,推荐使用上面的方式)
3.在CacheConfig配置类中创建要用的缓存对应的CacheManager
CaffeineCacheManager:依据CacheConsts对每个Cache进行各自的配置;
RedisCacheManager:连接redis服务器、设置Redis缓存默认设置、依据CacheConsts对每个Cache进行各自的配置;
CacheConfig(包含CaffeineCacheManager和RedisCacheManager)
package com.tzc.core.config;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.tzc.core.constant.CacheConsts;
import org.springframework.boot.autoconfigure.cache.CacheProperties;
import org.springframework.cache.CacheManager;
import org.springframework.cache.caffeine.CaffeineCache;
import org.springframework.cache.support.SimpleCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.cache.RedisCacheWriter;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import java.time.Duration;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
/**
*
* 缓存配置类
* @author tzc
* @date 2023/11/21
*/
@Configuration
public class CacheConfig {
/**
* Caffeine 缓存管理器
* 依据CacheConsts对每个Cache进行各自的配置
*/
@Bean
/**
* 由于类中有两个同类型的Bean,因此在通过@Autowired注入时可能会抛出异常,@Primary表示这个类优先
* */
@Primary
public CacheManager caffeineCacheManager(){
SimpleCacheManager simpleCacheManager = new SimpleCacheManager();
List<CaffeineCache> caches = new ArrayList<>(CacheConsts.CacheEnum.values().length);
// 类型推断 var 非常适合 for 循环,JDK 10 引入,JDK 11 改进
// 遍历缓存枚举常量,为其中的本地缓存设置TTL和MaxSize
for(var c : CacheConsts.CacheEnum.values()){
// 对于其中的本地缓存
if(c.isLocal()){
// 通过创建Caffeine对象来对缓存的各项属性进行配置
// 首先设置缓存大小maxSize(值为缓存枚举常量的对应属性)
Caffeine<Object, Object> caffeine = Caffeine.newBuilder().recordStats().maximumSize(c.getMaxSize());
// 若该常量的ttl属性 > 0
if(c.getTtl() > 0){
// 则将缓存的写入后淘汰的时间设置该值(单位为秒)
caffeine.expireAfterAccess(Duration.ofSeconds(c.getTtl()));
}
// 最后用该常量的name属性为缓存命名,并创建CaffeineCache加入到缓存集合caches中
Cache<Object, Object> cache = caffeine.build();
caches.add(new CaffeineCache(c.getName(), cache));
}
}
simpleCacheManager.setCaches(caches);
return simpleCacheManager;
}
/**
* Redis 缓存管理器
* 连接redis服务器、设置Redis缓存默认设置、依据CacheConsts对每个Cache进行各自的配置
*/
@Bean
public CacheManager redisCacheManager(RedisConnectionFactory redisConnectionFactory){
// 用connectionFactory为参数创建一个RedisCacheWriter
RedisCacheWriter redisCacheWriter = RedisCacheWriter.nonLockingRedisCacheWriter(redisConnectionFactory);
// 创建一个RedisCacheConfiguration(redis配置类),配置了禁止value为空、缓存名称前缀为Cache::Novel::
RedisCacheConfiguration defaultCacheConfig = RedisCacheConfiguration.defaultCacheConfig()
.disableCachingNullValues().prefixCacheNameWith(CacheConsts.REDIS_CACHE_PREFIX);
//创建一个容量为缓存常量类中枚举类个数的LinkedHashMap,用来存放接下来要创建的缓存对象
Map<String, RedisCacheConfiguration> cacheMap = new LinkedHashMap<>(CacheConsts.CacheEnum.values().length);
// 类型推断 var 非常适合 for 循环,JDK 10 引入,JDK 11 改进
// 遍历缓存枚举常量,为其中的Redis缓存设置TTL和MaxSize
for(var c : CacheConsts.CacheEnum.values()){
// 对于其中的远程缓存
if(c.isRemote()){
// 若该常量的ttl属性 > 0
if(c.getTtl() > 0){
// 以该常量的name属性为key,配置了缓存前缀、禁止空value缓存项、ttl的redis配置类为value存入LinkedHashMap中
cacheMap.put(c.getName(),
RedisCacheConfiguration.defaultCacheConfig().disableCachingNullValues()
.prefixCacheNameWith(CacheConsts.REDIS_CACHE_PREFIX)
.entryTtl(Duration.ofSeconds(c.getTtl())));
// 若该常量的ttl属性 <= 0
}else{
// 同上,区别是不配置tll(也即无过期时间,不会过期)
cacheMap.put(c.getName(),
RedisCacheConfiguration.defaultCacheConfig().disableCachingNullValues()
.prefixCacheNameWith(CacheConsts.REDIS_CACHE_PREFIX));
}
}
}
// 以RedisCacheWriter、redis配置类RedisCacheConfiguration、LinkedHashMap为参数创建RedisCacheManager
RedisCacheManager redisCacheManager = new RedisCacheManager(redisCacheWriter, defaultCacheConfig, cacheMap);
// 开启redis事务
redisCacheManager.setTransactionAware(true);
// 初始化redisCacheManager
redisCacheManager.initializeCaches();
return redisCacheManager;
}
}
4.在需要使用缓存的类或方法处以@Cacheable注解的形式配置缓存
BookRankCacheManager——使用了Caffeine缓存和Redis缓存(都是以注解形式使用的)
package io.github.xxyopen.novel.manager.cache;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import io.github.xxyopen.novel.core.constant.CacheConsts;
import io.github.xxyopen.novel.core.constant.DatabaseConsts;
import io.github.xxyopen.novel.dao.entity.BookInfo;
import io.github.xxyopen.novel.dao.mapper.BookInfoMapper;
import io.github.xxyopen.novel.dto.resp.BookRankRespDto;
import java.util.List;
import lombok.RequiredArgsConstructor;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Component;
/**
* 小说排行榜 缓存管理类
*
* @author xiongxiaoyang
* @date 2022/5/12
*/
@Component
@RequiredArgsConstructor
public class BookRankCacheManager {
private final BookInfoMapper bookInfoMapper;
/**
* 查询小说点击榜列表,并放入缓存中
*/
@Cacheable(cacheManager = CacheConsts.REDIS_CACHE_MANAGER,
value = CacheConsts.BOOK_VISIT_RANK_CACHE_NAME)
public List<BookRankRespDto> listVisitRankBooks() {
QueryWrapper<BookInfo> bookInfoQueryWrapper = new QueryWrapper<>();
bookInfoQueryWrapper.orderByDesc(DatabaseConsts.BookTable.COLUMN_VISIT_COUNT);
return listRankBooks(bookInfoQueryWrapper);
}
/**
* 查询小说新书榜列表,并放入缓存中
*/
@Cacheable(cacheManager = CacheConsts.CAFFEINE_CACHE_MANAGER,
value = CacheConsts.BOOK_NEWEST_RANK_CACHE_NAME)
public List<BookRankRespDto> listNewestRankBooks() {
QueryWrapper<BookInfo> bookInfoQueryWrapper = new QueryWrapper<>();
bookInfoQueryWrapper
.gt(DatabaseConsts.BookTable.COLUMN_WORD_COUNT, 0)
.orderByDesc(DatabaseConsts.CommonColumnEnum.CREATE_TIME.getName());
return listRankBooks(bookInfoQueryWrapper);
}
/**
* 查询小说更新榜列表,并放入缓存中
*/
@Cacheable(cacheManager = CacheConsts.CAFFEINE_CACHE_MANAGER,
value = CacheConsts.BOOK_UPDATE_RANK_CACHE_NAME)
public List<BookRankRespDto> listUpdateRankBooks() {
QueryWrapper<BookInfo> bookInfoQueryWrapper = new QueryWrapper<>();
bookInfoQueryWrapper
.gt(DatabaseConsts.BookTable.COLUMN_WORD_COUNT, 0)
.orderByDesc(DatabaseConsts.CommonColumnEnum.UPDATE_TIME.getName());
return listRankBooks(bookInfoQueryWrapper);
}
private List<BookRankRespDto>listRankBooks(QueryWrapper<BookInfo> bookInfoQueryWrapper) {
bookInfoQueryWrapper
.gt(DatabaseConsts.BookTable.COLUMN_WORD_COUNT, 0)
.last(DatabaseConsts.SqlEnum.LIMIT_30.getSql());
return bookInfoMapper.selectList(bookInfoQueryWrapper).stream().map(v -> {
BookRankRespDto respDto = new BookRankRespDto();
respDto.setId(v.getId());
respDto.setCategoryId(v.getCategoryId());
respDto.setCategoryName(v.getCategoryName());
respDto.setBookName(v.getBookName());
respDto.setAuthorName(v.getAuthorName());
respDto.setPicUrl(v.getPicUrl());
respDto.setBookDesc(v.getBookDesc());
respDto.setLastChapterName(v.getLastChapterName());
respDto.setLastChapterUpdateTime(v.getLastChapterUpdateTime());
respDto.setWordCount(v.getWordCount());
return respDto;
}).toList();
}
}
VerifyCodeManager——也可以通过RedisTemplate工具类来使用redis缓存,但代码侵入性高,不推荐(这里使用主要是因为要存入缓存的不是方法的返回值,其实也可以再创建一个方法将其返回值以注解的方式放入缓存)
package io.github.xxyopen.novel.manager.redis;
import io.github.xxyopen.novel.core.common.util.ImgVerifyCodeUtils;
import io.github.xxyopen.novel.core.constant.CacheConsts;
import java.io.IOException;
import java.time.Duration;
import java.util.Objects;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
/**
* 验证码 管理类
*
* @author xiongxiaoyang
* @date 2022/5/12
*/
@Component
@RequiredArgsConstructor
@Slf4j
public class VerifyCodeManager {
private final StringRedisTemplate stringRedisTemplate;
/**
* 生成图形验证码,并放入 Redis 中
*/
public String genImgVerifyCode(String sessionId) throws IOException {
//获取随机的校验码
String verifyCode = ImgVerifyCodeUtils.getRandomVerifyCode(4);
//生成校验码图片
String img = ImgVerifyCodeUtils.genVerifyCodeImg(verifyCode);
//将图形验证码放入 Redis 中(key值为CacheConsts中的IMG_VERIFY_CODE_CACHE_KEY+sessionId,只保留五分钟)
stringRedisTemplate.opsForValue().set(CacheConsts.IMG_VERIFY_CODE_CACHE_KEY + sessionId,
verifyCode, Duration.ofMinutes(5));
return img;
}
/**
* 校验图形验证码
*/
public boolean imgVerifyCodeOk(String sessionId, String verifyCode) {
return Objects.equals(stringRedisTemplate.opsForValue()
.get(CacheConsts.IMG_VERIFY_CODE_CACHE_KEY + sessionId), verifyCode);
}
/**
* 从 Redis 中删除验证码
*/
public void removeImgVerifyCode(String sessionId) {
stringRedisTemplate.delete(CacheConsts.IMG_VERIFY_CODE_CACHE_KEY + sessionId);
}
}
配置缓存的几个注解:

这里重点介绍@Cacheable注解,这也是最常用的注解
(参考文章:https://blog.csdn.net/zl1zl2zl3/article/details/110987968)
①@Cacheable注解的属性

cacheManager、cacheName/value这两个属性是必须配置的;
key可以不配置,默认是方法参数的值(空参则为0),配置的话可以用springEL表达式来写:

五、Caffeine缓存和Redis缓存
1.二者的异同
相同点:
①都是性能非常优秀的缓存;
不同点:
①Caffeine是本地缓存,且不支持持久化,而Redis是分布式缓存,且支持持久化;
②Caffeine相比于Redis没有网络IO的性能开销,且可以灵活配置缓存的过期策略,适合单台服务器、数据集不是太大的缓存;
③Redis适合在多台服务器间共享缓存数据,且数据集很大的情况;
——可以考虑将两种缓存结合起来,形成两级缓存:Caffeine本地缓存->Redis分布式缓存->数据库;
六、Caffeine的底层数据结构
参考文章:frank_cui Caffeine - Caffeine框架全介绍
接下来的学习方向:
1.如何针对不同场景对caffeine缓存进行配置:https://juejin.cn/post/6956148238399307813;
2.如何测试caffeine缓存带来的性能提升;
3.如何实现redis+caffeine二级缓存;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号