结对作业二
结对作业二
| 这个作业属于哪个课程 | 2021春软件工程实践|W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对第二次 |
| 结对学号 | 221801308 221801315 |
| 这个作业的目标 | 实现顶会热词统计的相关功能 |
| 其他参考文献 |
目录
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 300 | 350 |
| Design Spec | 生成设计文档 | 20 | 15 |
| Design Review | 设计复审 | 20 | 45 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 90 |
| Design | 具体设计 | 60 | 80 |
| Coding | 具体编码 | 3000 | 3660 |
| Code Review | 代码复审 | 60 | 45 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | ||
| Test Repor | 测试报告 | 20 | 15 |
| Size Measurement | 计算工作量 | 20 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 3730 | 4545 |
Github仓库地址
代码规范
项目访问地址
项目地址
(远程服务器可能会自动关闭,如遇不能访问情况。请联系学号为221801315的同学
成果展示
1.首页
2.注册
3.登录

4.联系我们
5.论文检索+收藏夹+回收站
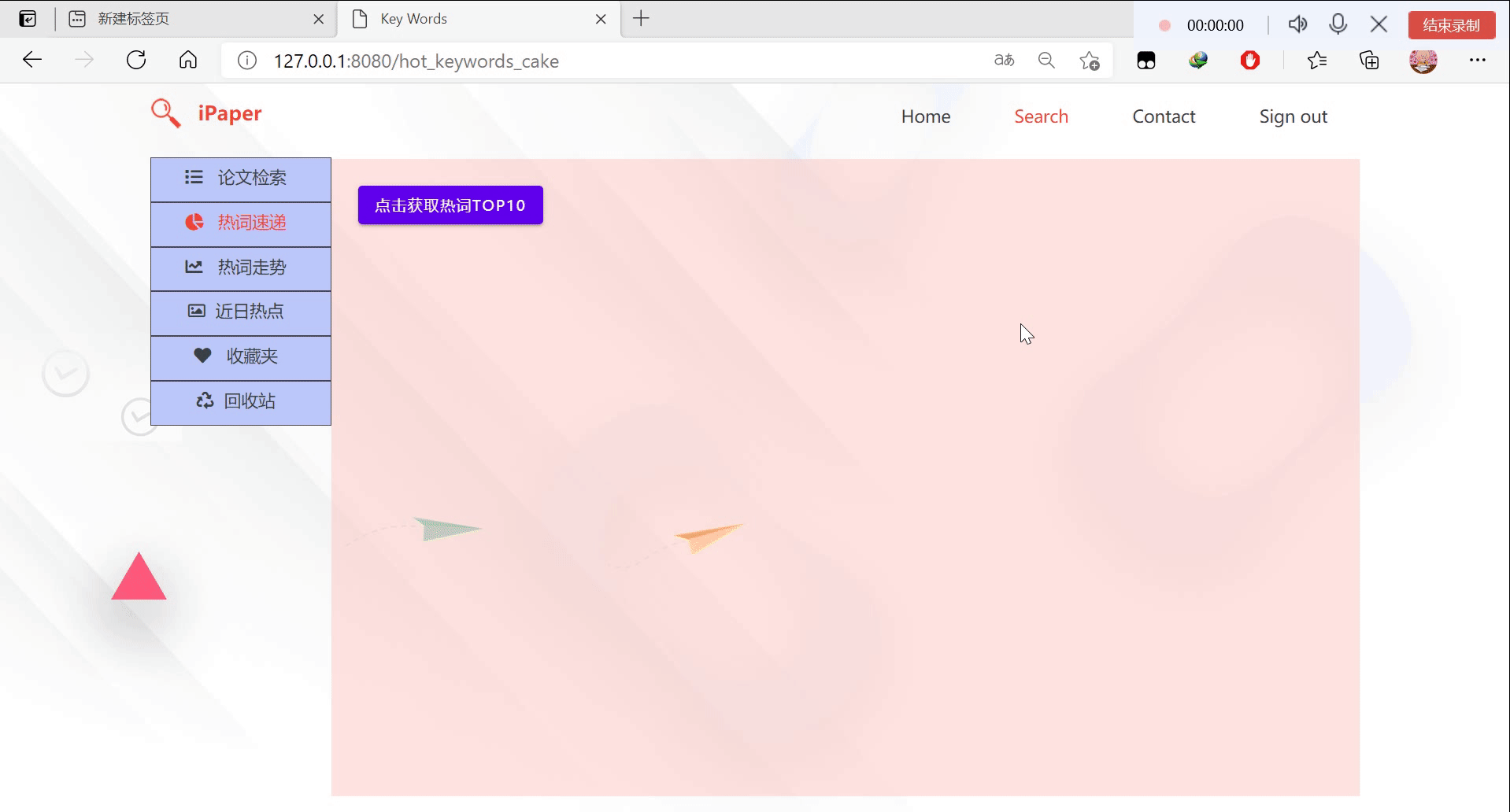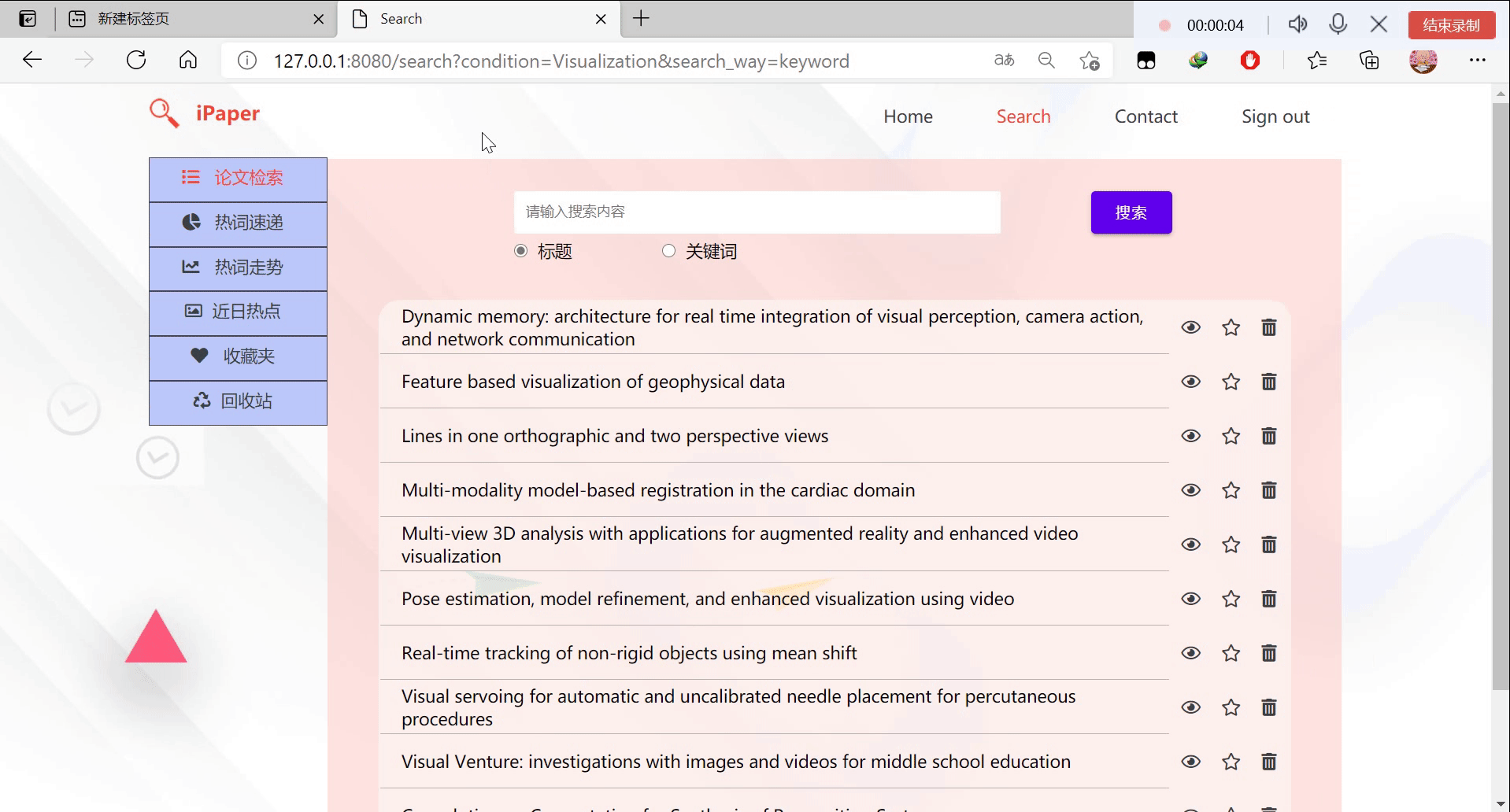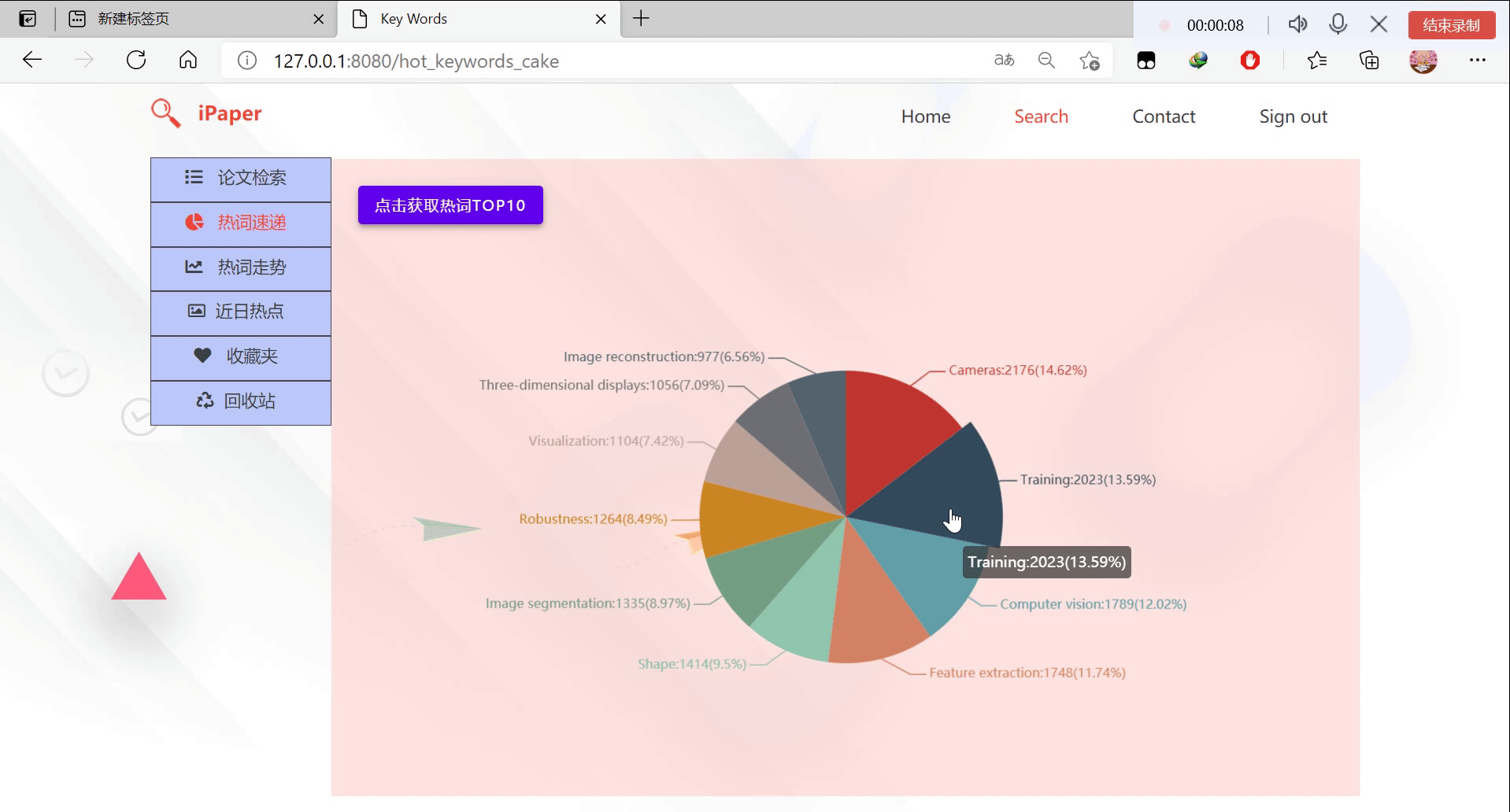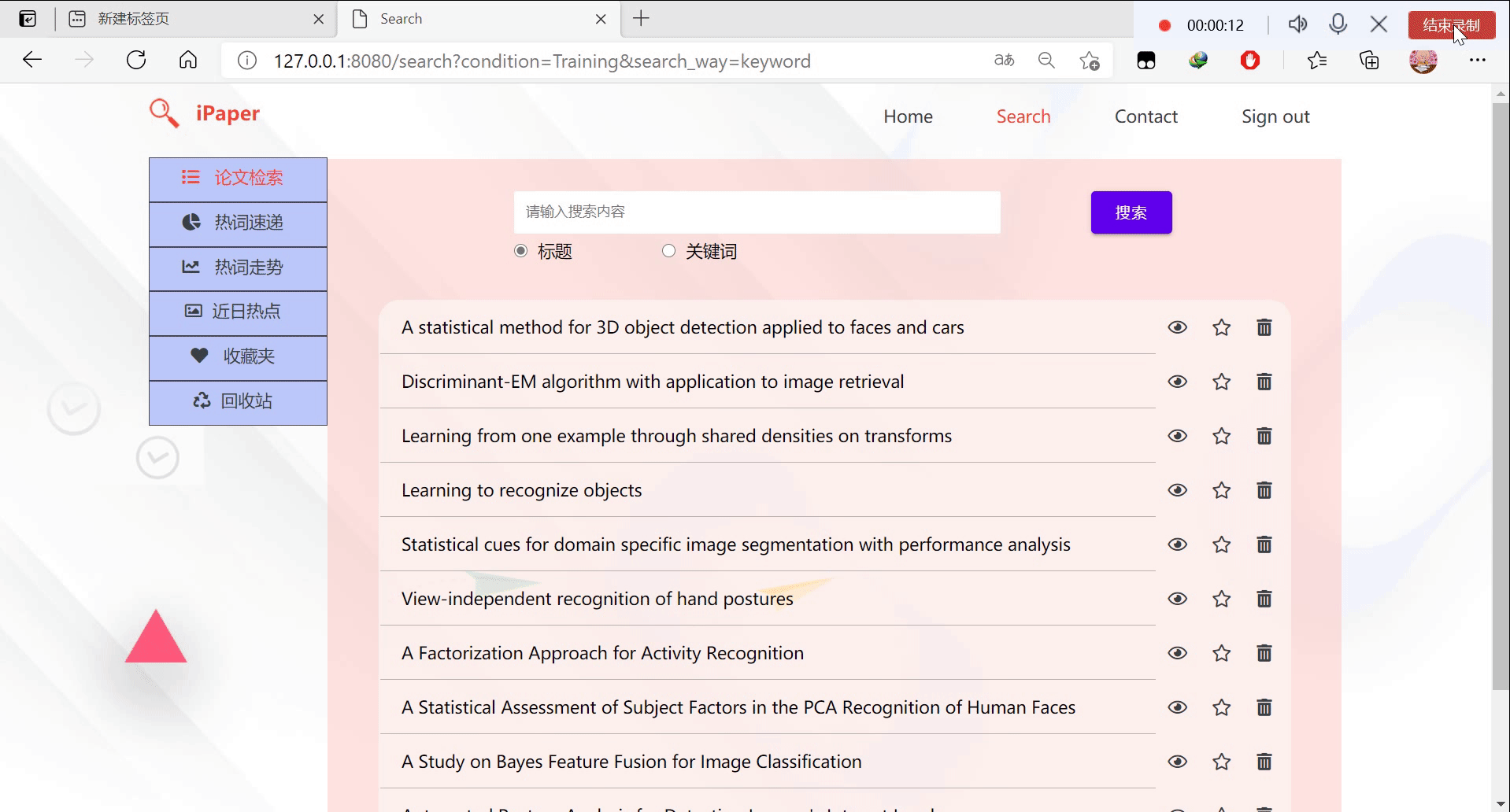
6.热词速递
7.热度走势
8.近日热点(轮播图展示或手动切换)
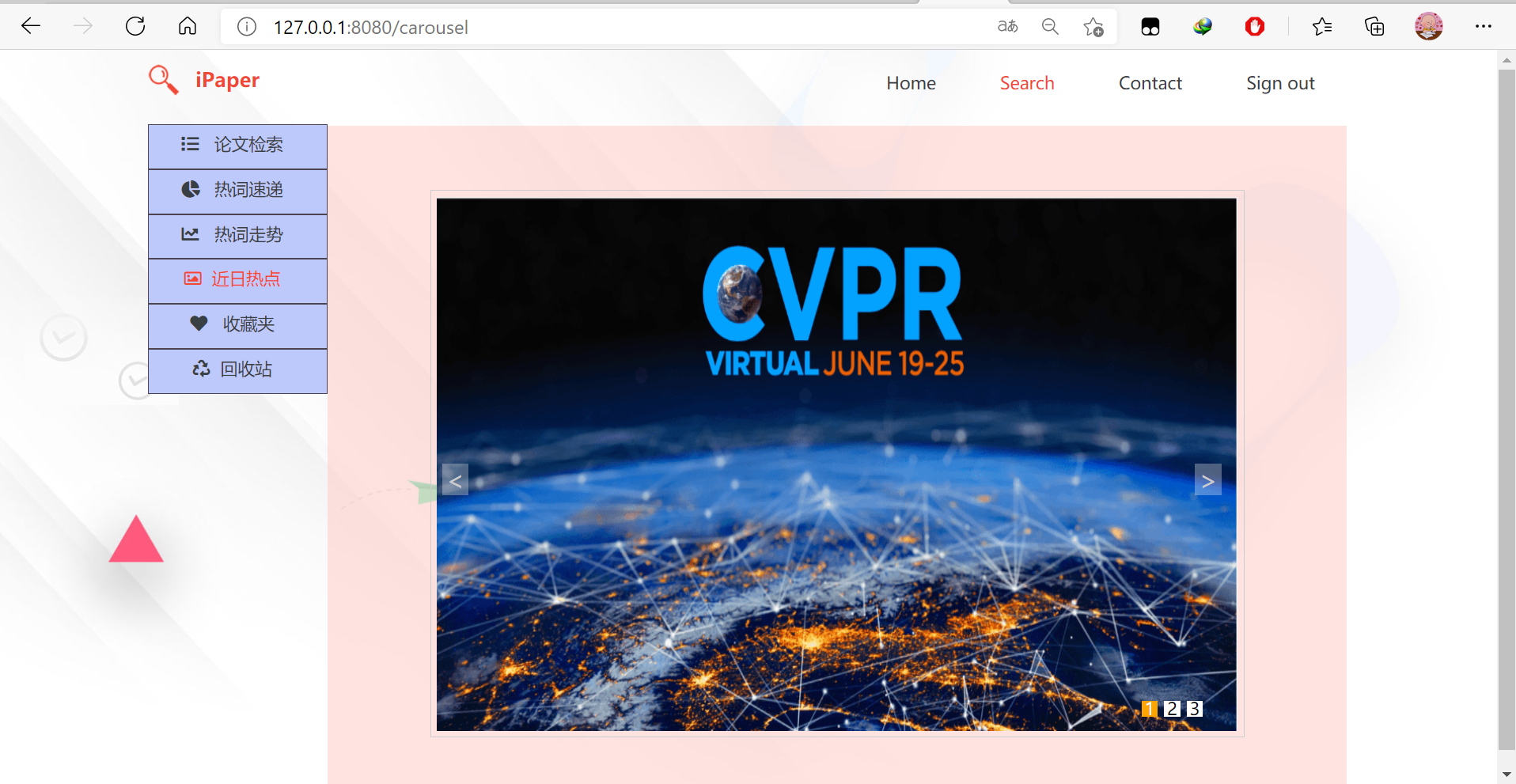
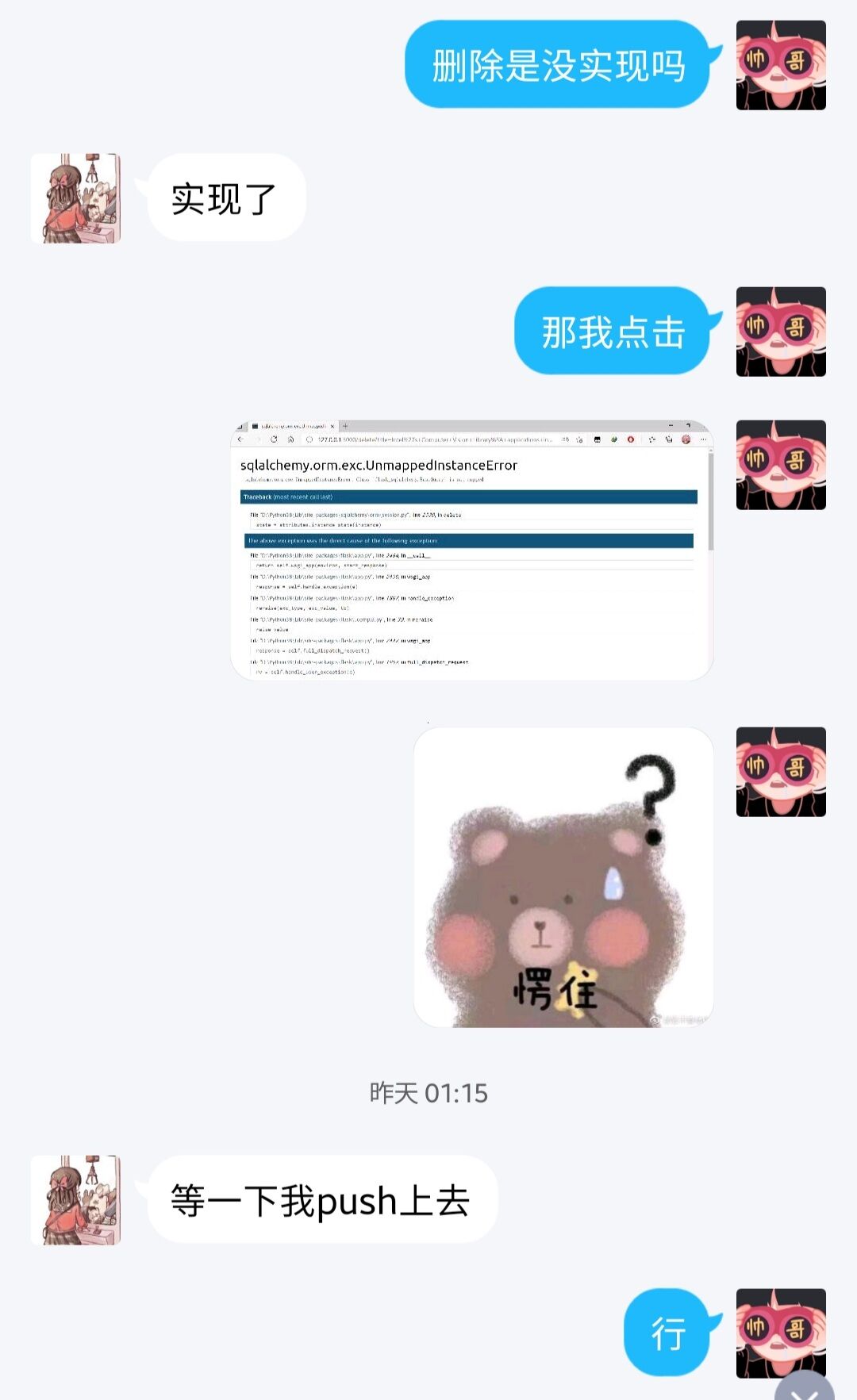
结对过程
- 发现BUG
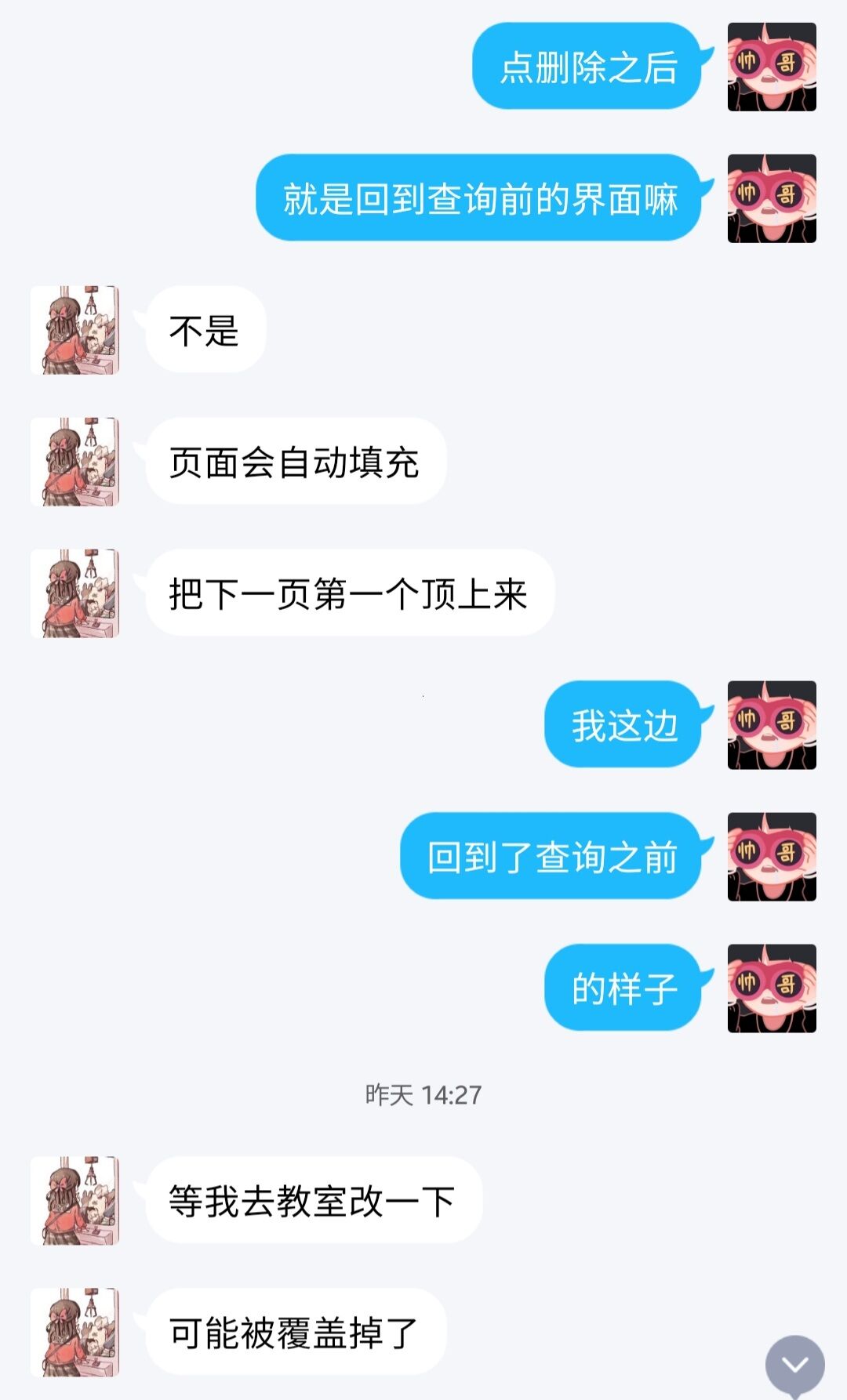
2.Json分割
3.实现关键词跳转查询界面并显示查询结果
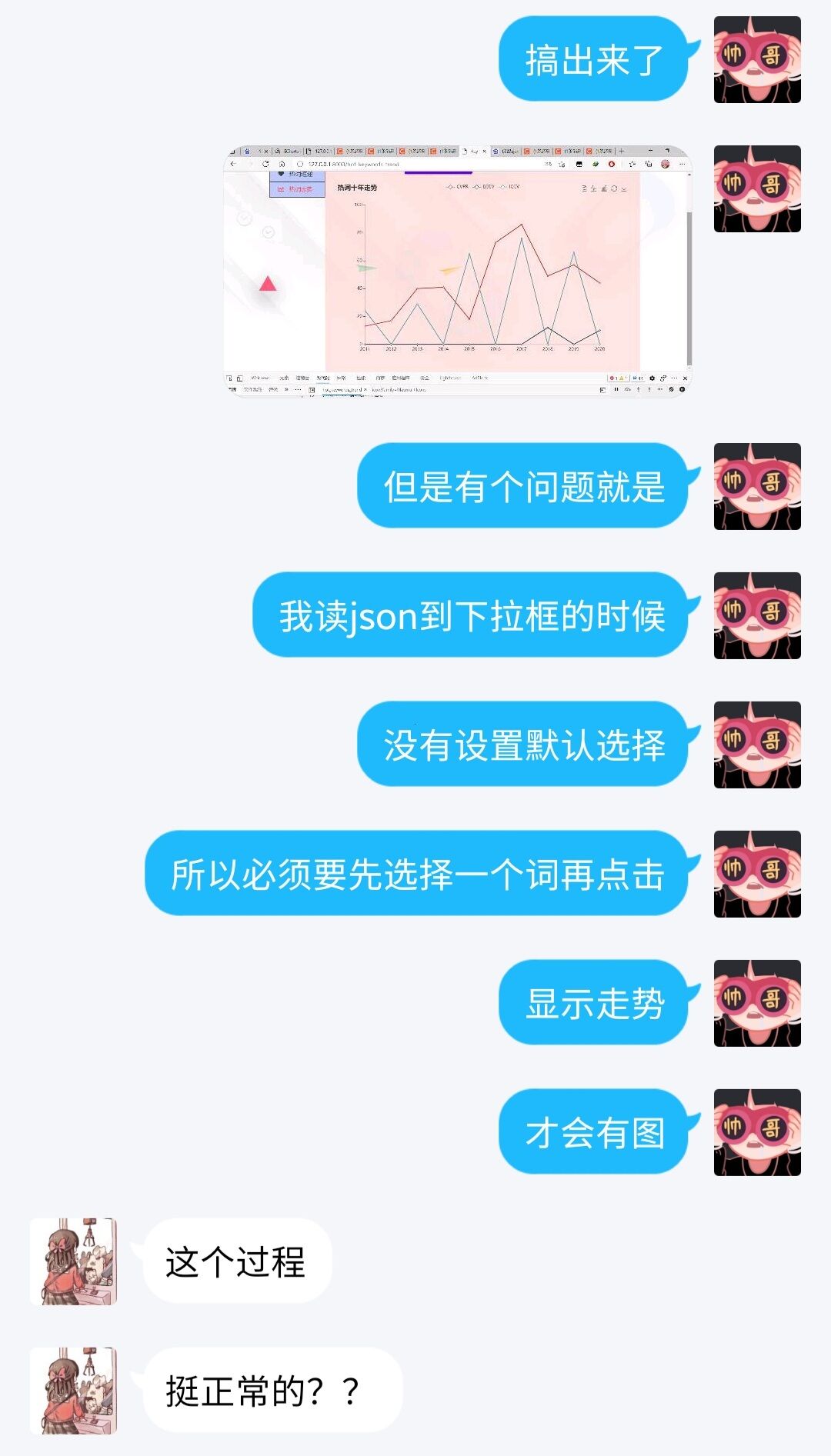
4.实现折线图
5.云服务器搭建完毕
实现过程
前端
采用HTML+CSS+JavaScript+JQuery+Ajax
1.采用三件套完成基本页面。
2.采用ajax和jquery进行交互
3.采用Echart和ajax进行图的绘制
后端
使用Python+Flask+Mysql。
- 整体框架:使用flask完成整个后端的编写。flask是一个具有上手快、轻量级特点的框架。个人感觉跟SpringBoot相似,不需要安装如Apache、Tomcat之类的应用服务器,只要实例化Flask就可以跑起来。flask与前端交互非常容易,前端同学很容易找到要链接的路由,而后端也可以直接返回html的模板渲染。
- 数据库:使用flask_sqlalchemy结合pymysql实现对数据库的操作。flask_sqlalchemy可以根据自定义的实体类轻松实现表的创建,而且还能完成多对多关系的双向查找功能。如根据论文article就能查到其对应的关键词组keywords,而根据关键词keyword也能查到包含这个关键词的所有文章articles。正是由于flask_sqlalchemy的强大,后端才能实现收藏夹、回收站等功能。flask_sqlalchemy还可以提供分页器pagination功能,将大量的数据分页返回,提高前端的显示速度。前端还可根据后端返回的pagination的某些属性,实现分页跳转。
- 权限控制:使用flask_login来实现登录才能访问某些页面的功能。flask_login将用户ID,Session ID等信息存入Session,可以识别整个应用运行期间用户是否登录,控制某些页面只有登陆的用户才可以访问。同时flask_login还提供logout功能,可以让已登录的用户登出。使用flask_login可以节省大量编写权限控制的时间。
- 部署:选择阿里云ESC服务器Centos8.0操作系统部署。Centos自带python3,不需要另外配置,对第一次部署python项目的新手友好
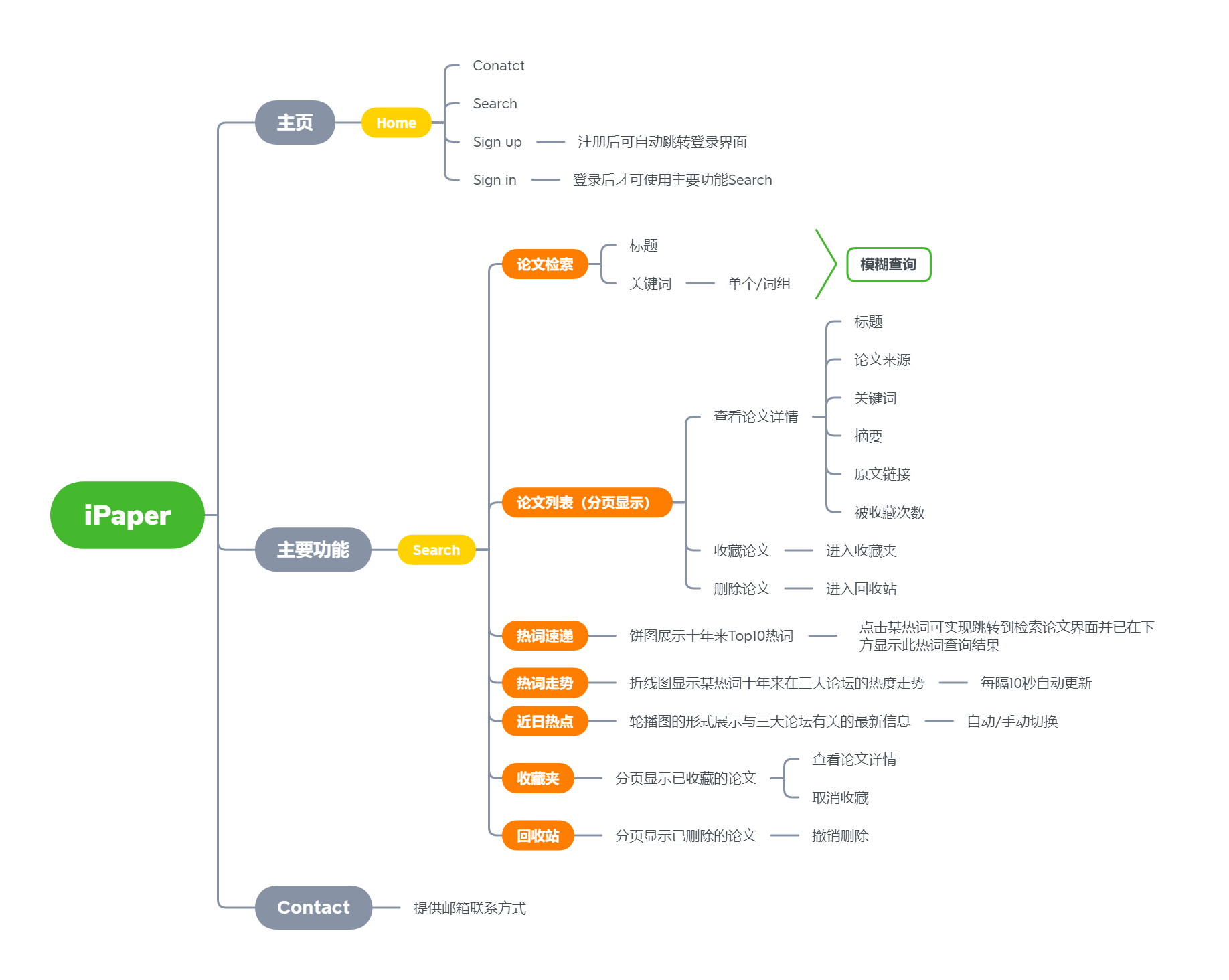
功能结构图
代码说明
前端
取json数据到
$.ajax({
url: '/get_trend',
type: 'get',
cache: false,
dataType: 'json',
success: function (data) {
//console.log(data.data);
var myselect = $("#myselect");
var mydata = data.data
var str = '';
$.each(mydata, function (index, item) {
console.log(item.keyword);
console.log(index);
str += '<option value="' + index + '">' + item.keyword + '</option>';
//console.log(str);
})
myselect.append(str);
$("#myselect").change(function () {
var options = $("#myselect option:selected");
console.log(options.val());
console.log(options.text());
key = options.text();
//console.log(key);
});
}
});
Echarts绘制
$("#key").click(function () {
var myChart = echarts.init(document.getElementById('main'));
// 显示标题,图例和空的坐标轴
function ajaxCake() {
myChart.setOption({
tooltip: {
trigger: 'item',
formatter: "{b}:{c}({d}%)"
},
series: [{
name: '次数',
type: 'pie',
radius: '55%',
label: {
normal: {
show: true,
formatter: "{b}:{c}({d}%)"
}
},
data: []
}]
});
// 异步加载数据
$.get('/get_cake').done(function (data) {
// 填入数据
var words = [];
var times = [];
var content = [];
console.log(data)
console.log(data.data)
$.each(data.data, function (index, item) {
console.log(item.keyword);
console.log(item.total);
content.push({
value: item.total,
name: item.keyword
})
// words.push(item.keyword);
// times.push(item.total);
})
myChart.setOption({
series: [{
// 根据名字对应到相应的系列
name: '次数',
data: content
}]
});
myChart.on('click', function (param) {
//这个params可以获取你要的图中的当前点击的项的参数
var keyword = param.name;
console.log(keyword);
$.ajax({
data: { 'keyword': keyword },
url: '/get_cake',
type: 'get',
cache: false,
dataType: 'json',
success: function (data) {
console.log(data);
console.log(data.data.url);
$.each(data.data, function (index, item) {
console.log(item.keyword);
console.log(item.url);
if (item.keyword == keyword) {
location.href = item.url;
}
})
//location.href="URL"
}
});
});
});
}
ajaxCake();
setInterval(() => {
ajaxCake();
}, 10000);
});
后端
登录login
@app.route("/login", methods=["POST"])
def login():
"""登录
获取前端通过POST方式提交的email、password,判断是否登陆成功
Args:
email: 邮箱账号
password: 密码
remember: 是否记住我,勾选则cookie的保存时间变长
Returns:
flash提示信息
登录成功时返回登陆后的首页视图
"""
email = request.form.get("email")
password = request.form.get("password")
remember = bool(request.form.get("remember"))
next_url = request.form.get("next")
if email == "":
flash("未输入邮箱账号")
return render_template("login.html")
if password == "":
flash("未输入密码")
return render_template("login.html")
user = Users.query.filter(Users.email == email).first()
if user is None:
flash("该账号不存在")
return render_template("login.html")
if user.password == password:
login_user(user, remember=remember)
flash("登陆成功")
if (next_url is None) or (not next_url.startswith("%2F")):
return redirect("/index_logined")
else:
next_url = next_url.replace("%2F", "/")
return redirect(next_url)
else:
flash("密码错误")
return render_template("login.html")
登出logout
@app.route("/logout", methods=["GET"])
def logout():
"""登出"""
logout_user()
flash("已登出")
return redirect("/")
注册register
@app.route("/register", methods=["POST"])
def register():
"""注册
获取前端通过POST方式提交的email、password、repetition,判断是否注册成功
Returns:
flash消息提示
注册成功时返回登录视图
"""
email = request.form.get("email")
password = request.form.get("password")
repetition = request.form.get("repetition")
if email == "":
flash("未输入邮箱账号")
return render_template("register.html")
user = Users.query.filter(Users.email == email).first()
if user is not None:
flash("该账号已注册")
return render_template("register.html")
if password == "":
flash("请输入密码")
return render_template("register.html")
if password != repetition:
flash("密码不一致")
return render_template("register.html")
try:
user = Users(email=email, password=password)
db.session.add(user)
db.session.commit()
flash("注册成功")
return redirect("/login_view")
except Exception as e:
db.session.rollback()
print(e)
flash("未知错误")
return render_template("register.html")
查询search
@app.route("arch", methods=["GET"])
def search():
"""查询
根据前端输入的条件和选择的查询方式查询论文
Returns:
返回查询界面模板
pagination_func: 查找函数名
pagination: 分页器
condition: 查询条件(前端传来的数据)
search_way: 查询方式(前端传来的数据)
无结果:返回模板文本
example:
见接口文档
"""
condition = request.args.get("condition")
page = int(request.args.get("page", 1))
search_way = request.values.get("search_way")
if condition == "":
return render_template("search.html")
if search_way == "title":
pagination = search_by_title(title=condition, page=page)
return render_template("search.html", pagination_func="search", pagination=pagination, condition=condition,
search_way=search_way)
else:
pagination = search_by_keyword(keyword=condition, page=page)
return render_template("search.html", pagination_func="search", pagination=pagination, condition=condition,
search_way=search_way)
查看论文详情view
@app.route("/view", methods=["GET"])
def view():
"""查看论文
在查询列表,每篇论有一个查看按钮,点击查看后看到论文详细内容
Args:
title: 在列表视图中点击查看按钮时会自动获取title
Return:
返回模板渲染
"""
title = request.args.get("title")
condition = request.args.get("condition")
page = request.args.get("page")
search_way = request.args.get("search_way")
pagination_func = request.args.get("pagination_func")
article = Articles.query.filter(Articles.title == title).first()
user_count=article.users.count()
return render_template("view.html", article=article, pagination_func=pagination_func, page=page,
condition=condition, search_way=search_way, user_count=user_count)
删除论文delete(进入回收站)
@app.route("/delete", methods=["GET"])
def delete():
"""删除论文
在查询列表,每篇论有一个删除按钮,点击删除后数据库将删除该文章,同时更新当前的查询列表视图
被删除的文章加入回收站
Args:
title: 在列表视图中点击删除按钮时会自动获取title
Return:
返回模板渲染
"""
title = request.args.get("title")
condition = request.args.get("condition")
page = request.args.get("page")
search_way = request.args.get("search_way")
pagination_func = request.args.get("pagination_func")
article = Articles.query.filter(Articles.title == title).first()
recycle = Recycles(article)
try:
db.session.add(recycle)
db.session.delete(article)
db.session.commit()
flash("删除成功")
except Exception as e:
print(e)
flash("数据库错误")
return redirect(url_for(pagination_func, page=page, condition=condition, search_way=search_way))
回收论文recycle(撤销删除)
@app.route("/recycle", methods=["GET"])
def recycle():
"""回收论文
在回收站,每篇论有一个回收按钮,点击回收后该论文重新加入文章列表
Args:
title: 在列表视图中点击回收按钮时会自动获取title
Return:
返回模板渲染
"""
title = request.args.get("title")
page = int(request.args.get("page", 1))
pagination_func = request.args.get("pagination_func")
recycle = Recycles.query.filter(Recycles.title == title).first()
article = Articles(id=recycle.id, meeting=recycle.meeting, title=recycle.title,
publicationYear=recycle.publicationYear, abstract=recycle.abstract, doiLink=recycle.doiLink,
keywords=recycle.keywords)
try:
db.session.add(article)
db.session.delete(recycle)
db.session.commit()
flash("已还原")
except Exception as e:
print(e)
flash("数据库错误")
return redirect(url_for(pagination_func, page=page))
收藏favorite(加入收藏夹)
@app.route("/favorite", methods=["GET"])
def favorite():
"""收藏论文
在论文列表,每篇论文有一个收藏按钮,点击后该论文加入当前登陆用户的收藏夹
Args:
title: 在列表视图中点击收藏按钮时会自动获取title
Return:
返回模板渲染
"""
title = request.args.get("title")
condition = request.args.get("condition")
page = request.args.get("page")
search_way = request.args.get("search_way")
pagination_func = request.args.get("pagination_func")
article = Articles.query.filter(Articles.title == title).first()
current_user.articles.append(article)
try:
db.session.commit()
flash("收藏成功")
except Exception as e:
print(e)
flash("数据库错误")
return redirect(url_for(pagination_func, page=page, condition=condition, search_way=search_way))
取消收藏cancel_favorite(从收藏夹中删除)
@app.route("/cancel_favorite", methods=["GET"])
def cancel_favorite():
"""取消收藏论文
在收藏夹,每篇论文有一个取消收藏按钮,点击后取消收藏该论文
Args:
title: 在列表视图中点击取消回收按钮时会自动获取title
Return:
返回模板渲染
"""
title = request.args.get("title")
page = int(request.args.get("page", 1))
pagination_func = request.args.get("pagination_func")
article = Articles.query.filter(Articles.title == title).first()
current_user.articles.remove(article)
try:
db.session.commit()
flash("已取消收藏")
except Exception as e:
print(e)
flash("数据库错误")
return redirect(url_for(pagination_func, page=page))
传递给前端热词饼图的数据get_cake
@app.route("/get_cake", methods=["GET"])
def get_cake():
"""热词饼图获取数据
获取频率最高的前10个关键词,返回json格式
Return:
json格式
code: 0正常
data: 含有10个关键词的list
keyword: 关键词
url: 查询跟该关键词相关的论文的路由
total: 每个词的总数
"""
keyword = Keywords.query.order_by(Keywords.count.desc()).limit(10).all()
data = []
for key in keyword:
per_key = {"keyword": key.keyword, "total": key.count,
"url": url_for("search", condition=key.keyword, search_way="keyword")}
data.append(per_key)
return jsonify(code=0, data=data)
传递给前端热词走势图的数据
@app.route("/get_trend", methods=["GET"])
def get_trend():
"""热词走势图获取数据
获取频率最高的前10个关键词,返回json格式
Return:
json格式
code: 0正常
data: 含有10个关键词的list
keyword: 关键词
CVPR: 近10年间在每年在该会议出现的次数
ECCV: 近10年间在每年在该会议出现的次数
ICCV: 近10年间在每年在该会议出现的次数
"""
keyword = Keywords.query.order_by(Keywords.count.desc()).limit(10).all()
data = []
for key in keyword:
CVPR = [0 for i in range(10)]
ECCV = [0 for i in range(10)]
ICCV = [0 for i in range(10)]
for article in key.articles:
year = int(article.publicationYear)
if year in range(BEGIN_YEAR, CURRENT_YEAR):
if article.meeting == "CVPR":
CVPR[year - BEGIN_YEAR] += 1
elif article.meeting == "ECCV":
ECCV[year - BEGIN_YEAR] += 1
else:
ICCV[year - BEGIN_YEAR] += 1
per_key = {"keyword": key.keyword, "CVPR": CVPR, "ECCV": ECCV, "ICCV": ICCV}
data.append(per_key)
return jsonify(code=0, data=data)
心路历程和收获
前端
心路历程
- 开始的时候想用vue-cli来写,但发现因为有'&'运行会报错。
- 后来电脑出了问题,不停死机重启,直至github实训的的前一天才修好(心碎2021)。然后周一下午电脑又被牛奶滋润了(再次心碎2021)。好在当晚去检查电脑时发现电脑还活着。
- 然后时间紧迫放弃了使用Vue,因为后端同学已经有测试好接口的HTML文件,所以就在此基础上进行了前端页面的编写。
收获
- 无情的界面美化工具
- debug能力明显提高
- css+ajax+jquery更加熟练
- echarts作图真不错
- 希望接下来好运一点
后端
- 在项目开始前,我的web技术一直很烂,也不会什么框架,本来打算现学spring boot。但是和同学交流过程中得知python的flask框架也挺好用,加上我本身也会python,因此打算使用flask完成整个项目。
- 项目初期我使用pymysql来操作数据库,但是面临多对多关系时就犯了难。经过搜索资料了解到flask_sqlalchemy,发现这个库更好用,轻松解决多对多关系的查询,提高了开发效率。
- 前后端开始调试接口时真的很痛苦,经常报错。特别是登陆、注册在ajax里用alert显示后端传来的检查结果数据时经常出问题,因此我决定使用flask来控制检查结果的传递,效果喜人。
- 部署云服务器也是我的一大挑战,我之前从来没有部署过。团队实训的早上刚好抢到了阿里云服务器的体验资格,就试了一下,发现一窍不通。断断续续查了三天的资料,根据教程部署却一直出错。直到截止日期的中午才找到一篇靠谱的教程,用了10分钟就部署好了环境,并且能从外网访问到服务器上的项目了。
- 本来考虑加上爬虫功能,但是由于前端同学遭遇一些不可抗力事件的影响,时间不够,只补充了收藏夹、回收站两个功能。后期有时间的时候会考虑加入爬虫功能。
队友评价
221801315--->221801308
- 前端界面做的很好看,相互配合的很顺利。
- 希望你下次能幸运一点,不要再遭遇不可抗力事件,延迟前端开始时间。
- 虽然催你写代码的时候,我就化身为白雪公主的后妈,心狠手辣。但是别恨我,恨我没结果。
221801315--->221801308
- 学习小能手,Flask从入门到精通。
- 后端小公主,帮我做了很多交互的事情,减轻了我的工作量。
- 沟通没有障碍,合作很愉快。
