寒假作业2/2
| 这个作业属于哪个课程 | 2021春软件工程实践|W班 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 |
阅读《构建之法》并提问 附加题 WordCount编程 附录 |
| 参考文献 | 无 |
阅读《构建之法》并提问
- 《5.3.5老板驱动流程》中提到:“领导对许多技术细节是外行,领导未必懂的软件项目的管理,领导的权威影响了自由的交流和创造”,但并没有说当问题或者分歧出现时要怎么解决。我在知乎搜索关于福州某知名游戏公司的工作待遇时看到,多数回答都在抱怨该公司官僚主义盛行,而且有些领导都是靠资历混上来的,本身没什么技术,有些产品也没什么实际意义。那么作为快实习的大学生,以后工作如果遇到类似的公司,面对分歧时要怎么和领导交流?领导权力大,可以找各种理由克扣工资,这时候是为了钱附和领导,还是为了做一个好产品或者让自己学到更多而跟领导提意见?若二者都想兼得,要如何与老板沟通呢?有没有比较好的建议呢?
- 《6.3敏捷团队》中提到:“敏捷对团队的要求很简单:自主管理、自我组织、多功能型”。现在很多人都提倡敏捷开发,但是人都是有惰性的,就我本身与同学合作完成一个任务的情况来看,大家都喜欢做简单、轻松的部分。当轻松的活儿都被挑走时,剩下的不得不做较复杂工作的同学们心中都不乐意,容易引起团队矛盾。在敏捷开发的过程中,万一小组成员在认领任务时,只选择一些轻松的任务,把复杂的任务留给别人时,要如何处理呢?若有的成员认领任务前以为自己能完成,实际上手后发现有些知识或技术实在不擅长甚至无法处理,以至于工作落后需要别的成员帮助改进,那么别的成员难免有怨气,这时作为领导或者负责人要如何调节安抚成员呢?从前各有各的分工,如今一个人要全面负责:写规格说明书、与人沟通、开发、测试……,这些都需要另外花时间去学习对应的方法和技术,这对一个人来说是否负担较重,降低了开发效率?拿我自己举例,在本次程序设计中,我本人既要开发也要测试,还要写博客说明,而且在开发---->测试---->修改这一过程中经历了3次以上,感觉负担较重。若此时有人负责测试,有人负责写博客说明,那我觉得我的的开发效率会更高,因为这样我就能专注与问题的解决,而不用忙于写测试案例试图自己否定自己写的代码。
- 在上一篇博客中我提过一个问题,从《4.5 结对编程》中可以看出作者十分推崇结对编程,参与结对编程的双方应当只有水平差距,但编程过程中必然有主(驾驶员)次(领航员)之分,若在双方水平一样的情况下,要如何合理安排任务分配(即主次顺序)呢?现在我有了自己的看法,在任务开始前就要列个List来分清双方自己负责的任务,当双方都觉得这个List上的方案可行时,才能开始工作。在工作过程中绝对不在任务以外的范围干涉对方的行动,有任务以外的问题都等到“驾驶员”完成这部分的内容后再讨论。那么现在我又有了新的问题:若双方在编程时出现分歧,而且各自的说法都有道理,这是该如何协调呢?举个例子,假设我和WY同学结对编程做这次的程序设计,要处理一个有关在内存中以什么形式保存文本内容的问题。WY同学坚持将文本内容读取后全部存放在一个字符串中,然后直接用正则表达式提取文本内的单词;而我坚持每次只保存一个字符,然后马上跟上一系列较为复杂的分支逻辑判断来统计单词。WY同学的代码的运行时间比我短许多,但是面对400MB的样本就会出现爆内存无法运行的问题;我的代码运行时间比WY同学长许多,但是同样的400MB的样本用我的代码仍然能跑。可以说我们俩的做法都有各自的道理,那么此时,应该选择什么方法呢?或者如何协调这种分歧?
- 《8.1软件需求》中详细介绍了获取用户需求的步骤:获取和引导需求---->分析和定义需求---->验证需求---->在软件产品的生命周期中管理需求。但我认为再科学的步骤都抵不过甲方爸爸自己推翻了以前确认过的需求。若此时项目已经进展到后期,该怎么处理这个问题呢?要推翻重做吗?若是推翻重做会耗费人力、物力、财力,损失谁来承担;若不重做,该软件已经不再符合用户的需求,这个软件就没有意义了。在初期和甲方沟通的时候,若甲方是个想到什么就一定要做什么的人,思维天马行空,常常在项目已经有一些进展的时候就变更需求,而且要求开发人员一定要满足否则不付钱,这时项目负责人要如何决策呢?
- 《13.2各种测试方法》中介绍了很多测试方法,其中开发人员使用最多的应该是单元测试。那么开发人员应当耗费多少时间在单元测试上比较合理呢?是只要正确运行一个具有普遍性的样例,不出错误就可以继续开发下一个部分,剩下的测试全部交给测试人员来做?还是要自己编写各种特殊的样例来定位bug,确保所有结果都正确才开始进行下一步的开发呢?如果是前者,有可能会面临多次返工的情况;如果是后者,开发人员的负担就变得很大,岂不是影响开发效率?如果是自己一个人独立完成一个project,那自然是后者,但程序猿一般都是团队工作,这时候如何把控自己花在单元测试上的时间?
附加题
一个电脑工程师,一个系统分析师,一个程序员,他们开车下山,突然刹车失灵。只听着他们尖叫着冲下山,速度越来越快,但最终还是停了下来,纯属运气,再过几寸就掉进万丈悬崖。他们都爬下车。电脑工程师:”我想我能修好它。” 系统分析师:“不,我认为我们应该把它运下山,找个专家看看是什么问题。” 程序员:“我认为我们应该把它推回山顶,看看这种问题是否能够重现。” ——来源:知乎
感觉故事中的程序员就是我的日常,写完一个程序,用一个测试案例测试。出现问题时,就会动动我的小手,点点绿色的小三角'Run',再跑一遍,看看这个异常出现是不是偶然。
WordCount编程
Github项目地址
PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| • Estimate | • 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 370 | 715 |
| • Analysis | • 需求分析 (包括学习新技术) | 30 | 60 |
| • Design Spec | • 生成设计文档 | 30 | 45 |
| • Design Review | • 设计复审 | 30 | 60 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 60 | 90 |
| • Design | • 具体设计 | 40 | 70 |
| • Coding | • 具体编码 | 40 | 40 |
| • Code Review | • 代码复审 | 40 | 50 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 100 | 300 |
| Reporting | 报告 | 40 | 45 |
| • Test Repor | • 测试报告 | 20 | 30 |
| • Size Measurement | • 计算工作量 | 10 | 5 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 420 | 770 |
解题思路描述
一共要实现4个功能,且这4个功能都可以变成4个独立的函数,那么我就按“编写一个功能(函数)---->写一个对应的单元测试---->多样例测试一个功能(函数)”的路线来解决。
这4个功能都涉及到文件流的知识,其中统计有效行数和查找单词的部分可能涉及到正则表达式。
编写对文件路径、文件类型的异常处理,避免出现与文件本身有关的异常没有被处理的情况。
完成所有功能的编写后,再次用多案例检查是否有出错,有错就马上修改代码。
确认结果没问题后,编写将结果写入输出文件的函数,并且检查结果是否以正确格式被写入文件。
跑一遍所有函数的单元测试,没问题即可用JProfiler查看时间消耗和内存消耗。
若消耗过大,则要改进性能,减少I/O和排序的消耗,修改后的代码若通过正确性检查,就可用JProfiler再次查看性能。
代码规范制定链接
设计与实现过程
一共12个函数、2个类:WordCount和Lib。附录部分有各功能解题路线图,以及commit路线。
WordCount类
只有一个main函数,检查命令行传入的参数是否有两个:输入文件路径、输出文件路径,调用文件有效性检查函数checkFileValid(),以及将结果写入文本函数writeToOutFile()。
Lib类
所有功能实现的函数都在该类中,每个功能都被一个函数封装
模块接口
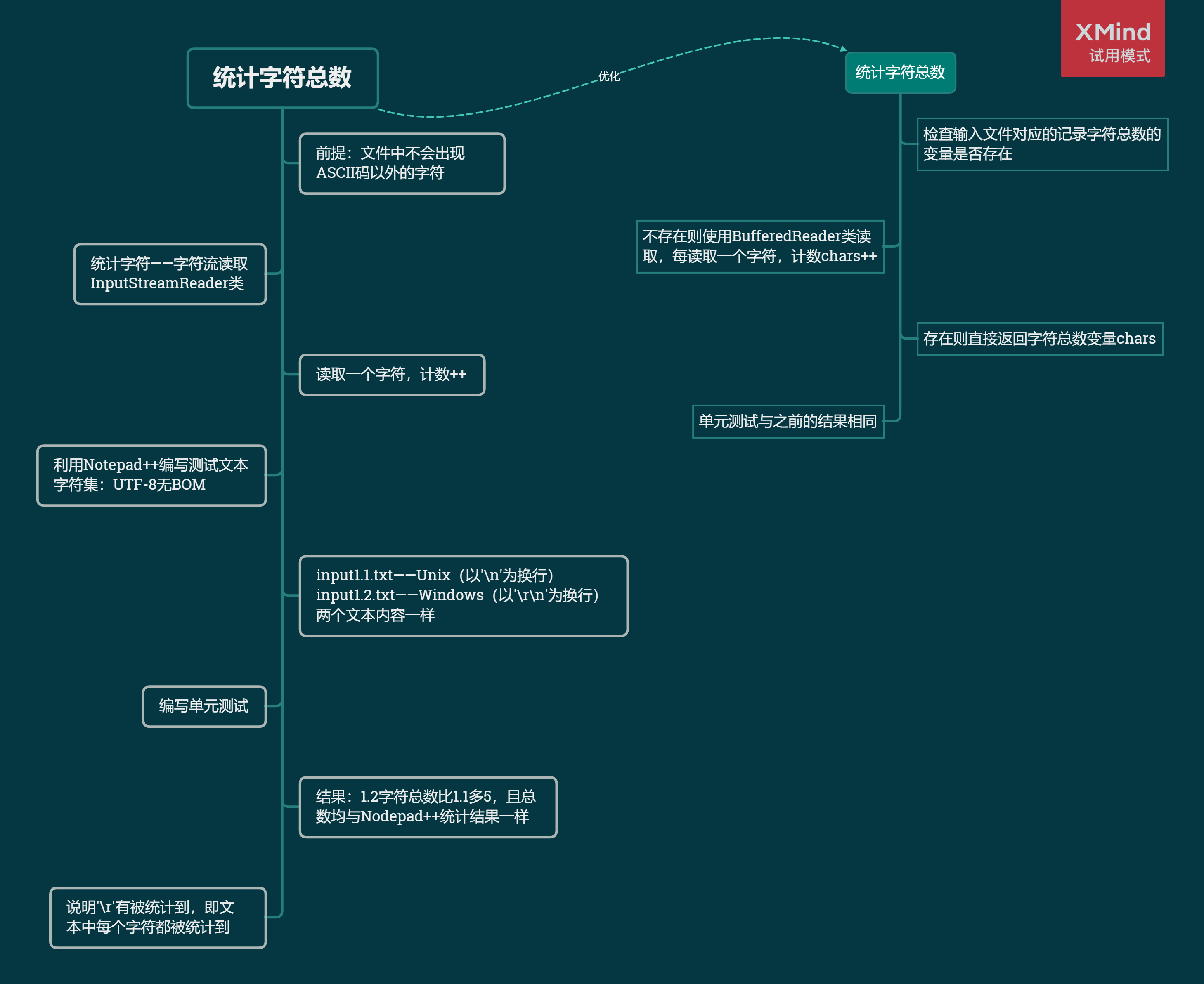
/* 统计输入文件中的字符总数
输入参数:输入文件路径inFilePath
返回值:字符总数chars */
public static int countTotalChar(String inFilePath);
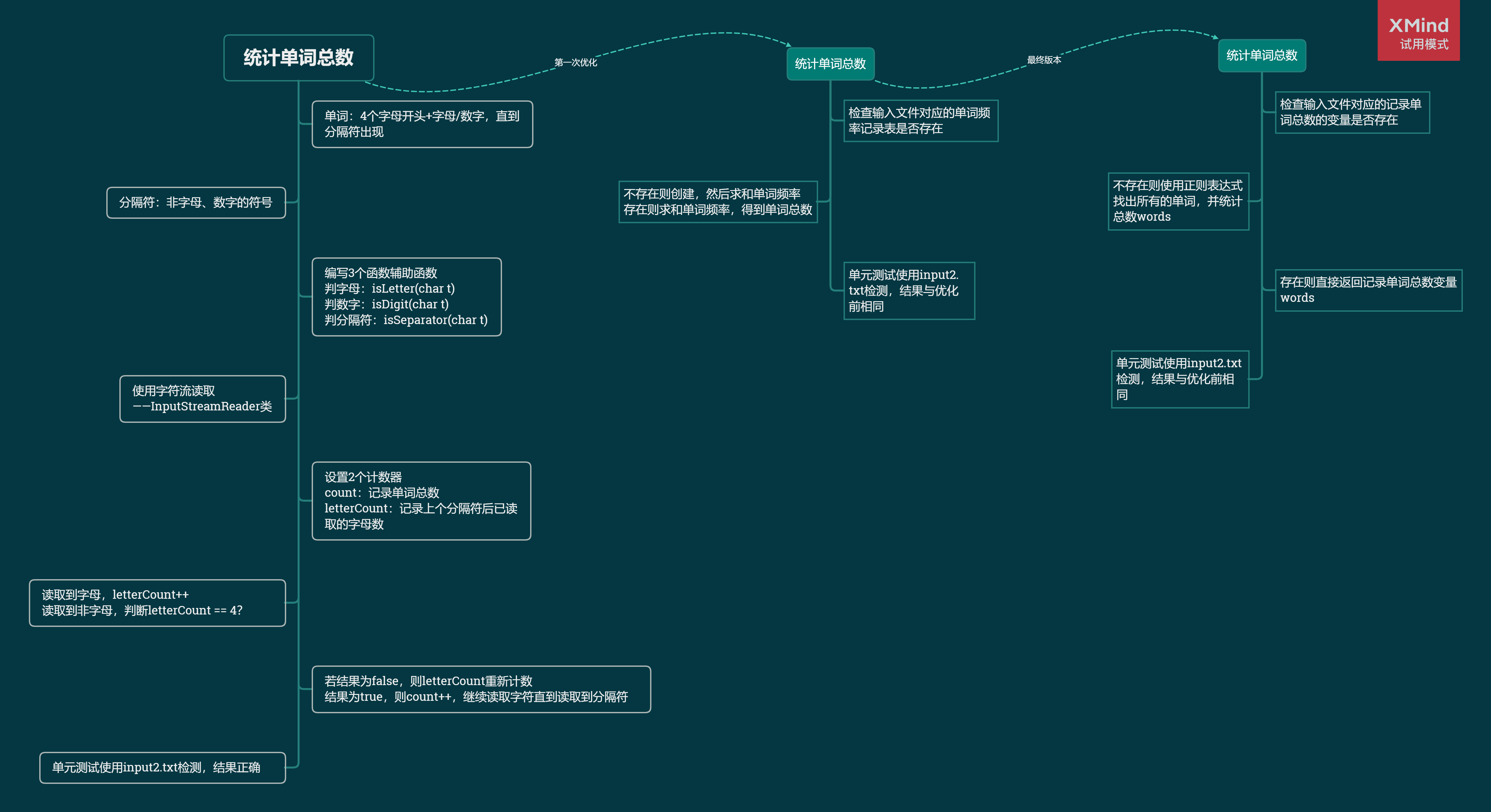
/* 统计输入文件中的单词总数
输入参数:输入文件路径inFilePath
返回值:单词总数words */
public static int countTotalWord(String inFilePath);
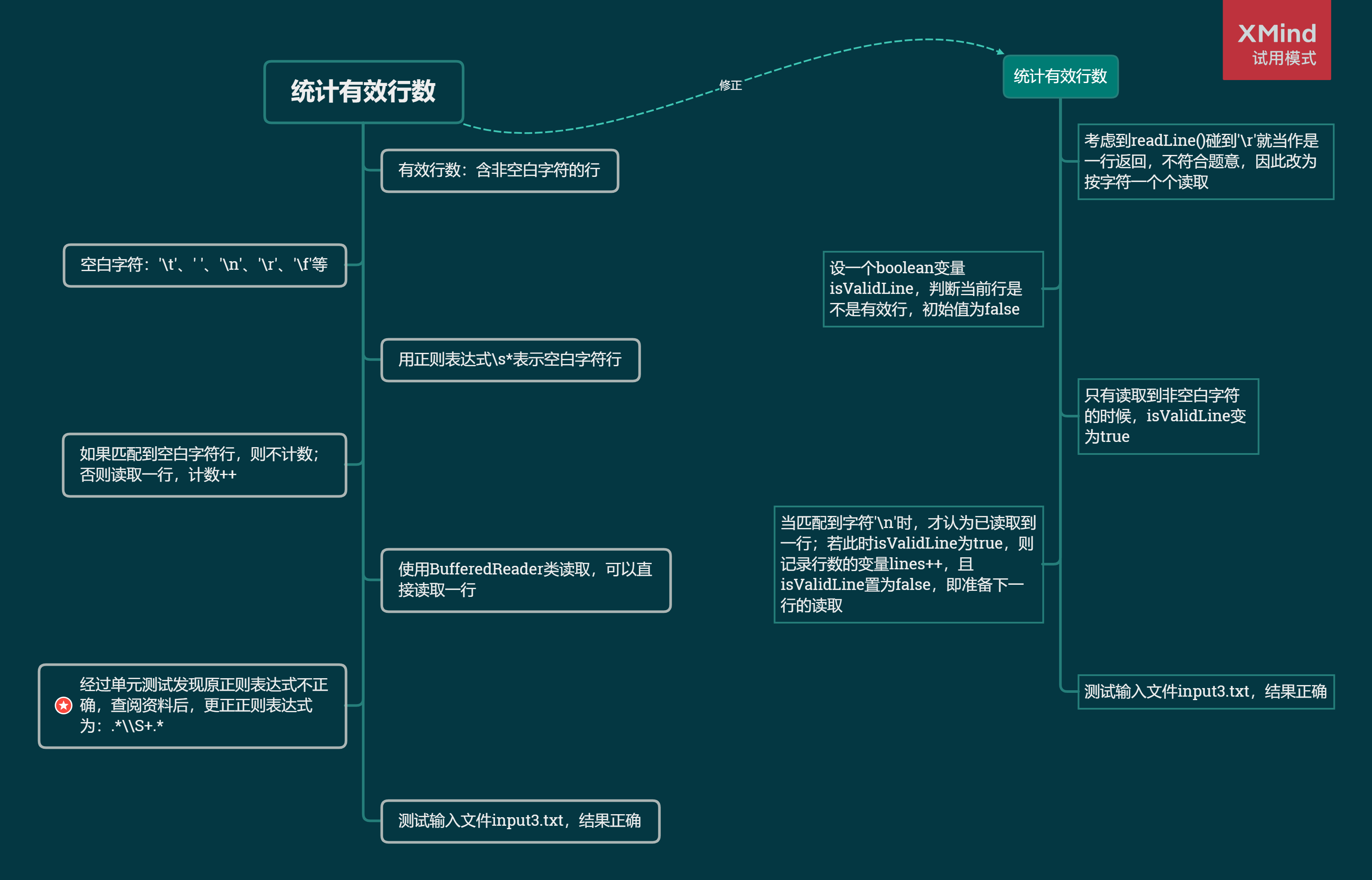
/* 统计输入文件中的有效行数
输入参数:输入文件路径inFilePath
返回值:行数lines */
public static int countValidLine(String inFilePath);
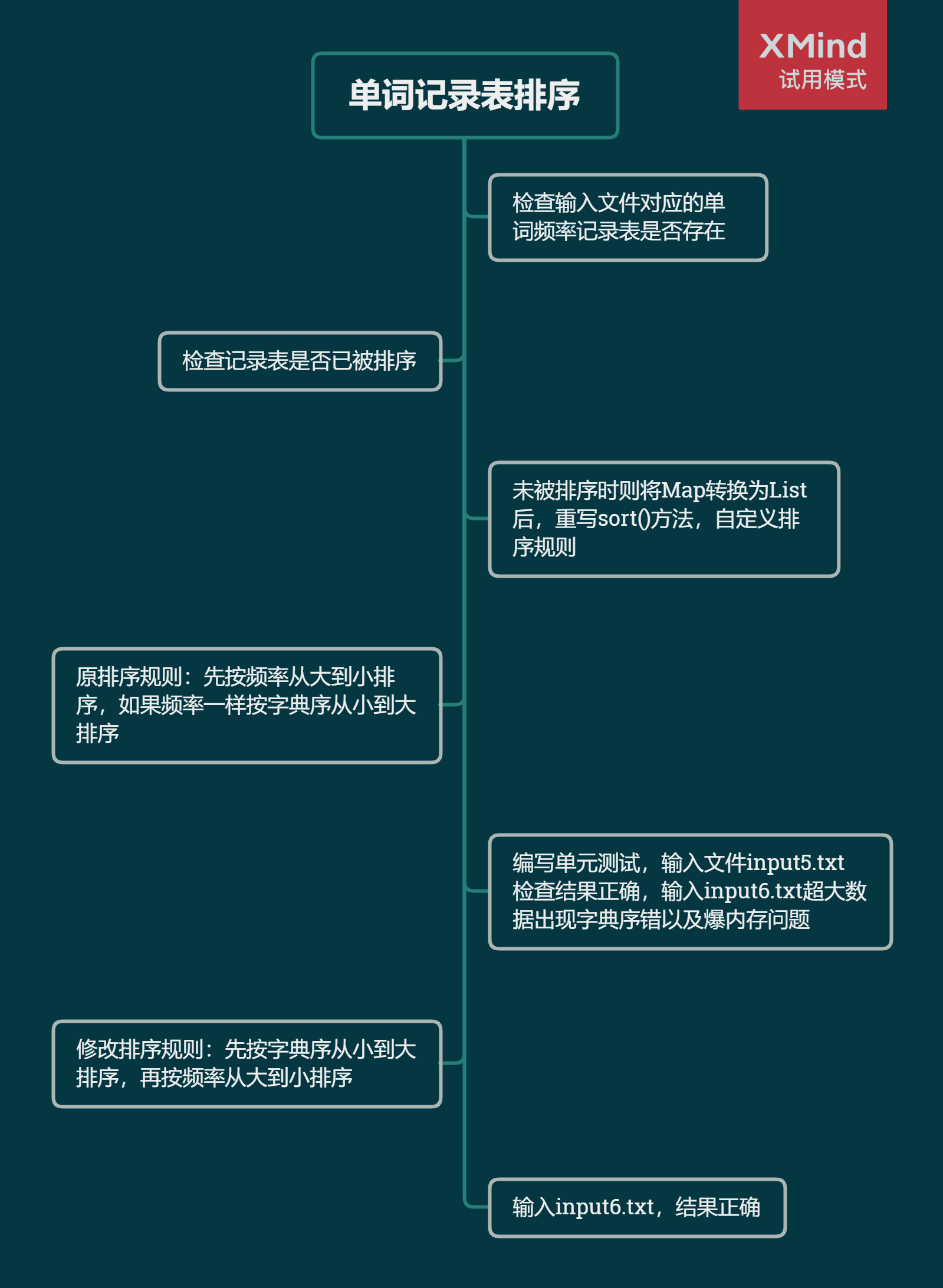
/* 先按频率后按字典序给单词记录表排序
输入参数:输入文件路径inFilePath
返回值:记录最高的10个频率的单词的列表list */
public static List<Map.Entry<String, Integer>> getSortWordFrequencyRecords(String inFilePath);
/* 将统计结果写入输出文件
输入参数:输入文件路径inFilePath,输出文件路径outFilePath
返回值:空 */
public static void writeToOutFile(String inFilePath, String outFilePath);
- 这些函数都可以单独使用。
- 如只需要统计单词总数,而不需统计别数据时,调用
countTotalWord()函数就能得到结果。同理,countTotalChar()、countValidLine()、getSortWordFrequencyRecords()也是如此。这4个函数相互独立,没有互相调用,便于使用者按自己的意愿组合统计结果,自由度更高。 writeToOutFile()函数依赖于getSortWordFrequencyRecords()和createWordFrequencyRecords(),调用该函数可以一次性得到需求中要求的结果,并将结果写入文件。getSortWordFrequencyRecords()函数会检查内存中是否已有单词频率记录表wordFrequencyRecords的存在,不存在则调用createWordFrequencyRecords()创建一个单词频率记录表,否则直接对其进行排序,返回频率最高的10个单词的列表。- 其他函数都是辅助函数,如判断是否是数字、字母、空白符等等。
核心
createWordFrequencyRecords()函数是本程序的核心,该函数用于创建单词频率记录表wordFrequencyRecords- 利用hashMap结构储存单词频率记录表
wordFrequencyRecords,降低了频繁插入单词的时间消耗。 - 该函数使用缓冲流读取文本,不需要频繁访问文件,减少I/O消耗。
- 【⭐】只遍历一次完整的文本内容,就能得到所有需要的统计的信息,极大降低了I/O消耗。
- 该输入流每次读取一个字符
temp,同时使字符总数chars++。 - 若
temp为非空白字符,则当后续读取到一个'\n'时,有效行数lines++。 - 当
temp为字母时,字母计数letterCount++,单词word += temp。 - 当
temp为数字时,若字母计数letterCount >= 4,则单词word += temp,否则单词word清空,letterCount重新计数。 - 当
temp为分隔符时,若字母计数letterCount >= 4,就把word加入自定义的单词频率记录表wordFrequencyRecords,然后清空word,letterCount重新计数。 createWordFrequencyRecords()的关键代码如下所示,无关部分用......省略【我真的真的真的没有可省略的代码惹】:
public static void createWordFrequencyRecords(String inFilePath) {
......
//读取文件,直到文件结束
while ((temp = in.read()) != -1) {
++chars;
if (!isBlankChar((char) temp)) //说明读入非空白字符
isValidLine = true;
if ((char) temp == '\n' && isValidLine) {
isValidLine = false;
++lines;
}
if (isDigit((char) temp)) { //避免44aaaa这种形式的字符串被认作单词
if (word.equals(""))
beforeIsDigit = true;
else {
if (letterCount >= 4)
word += (char) temp;
else {
word = "";
letterCount = 0;
beforeIsDigit = true;
}
}
} else if (isLetter((char) temp)) {
if (!beforeIsDigit) {
++letterCount;
word += (char) temp;
}
} else {
if (letterCount >= 4)
addRecord(word.toLowerCase(Locale.ROOT));
word = "";
letterCount = 0;
beforeIsDigit = false;
}
}
......
}
性能改进
总耗费时间3h。
初始版本
统计一个142MB的文本文档约需要55s,在JProfiler中检测性能约花费56s,JProfiler截图如下:
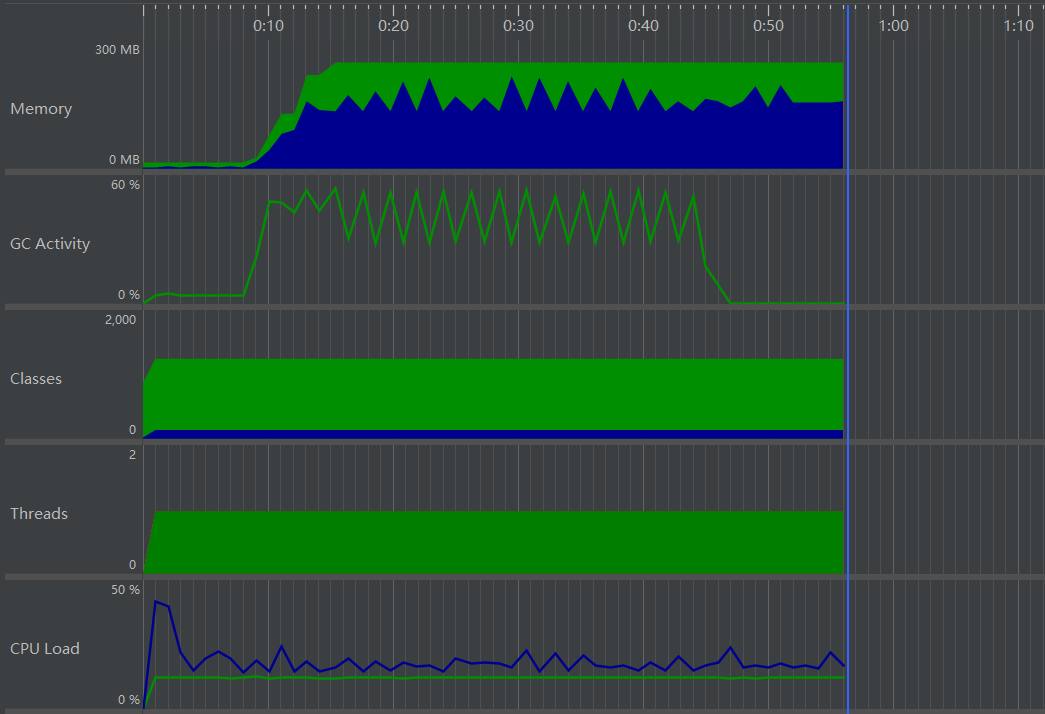
修改I/O
- I/O消耗原因:初始版本中的
writeToOutFile()函数调用了4个功能的计算函数,每个函数都用文件流访问一次文件,造成了不必要的I/O消耗。 - 改进步骤:
- 在Lib类中新增了3个静态成员变量:字符总数
chars、有效行数lines、单词总数words。 - 修改
createWordFrequencyRecords()函数,使其运行一次,即访问一次文件就计算出上述3个变量的值,同时得到单词频率记录表wordFrequencyRecords。 - 去掉
writeToOutFile()中调用计算字符数、行数、单词数3个功能的语句,加入创建单词记录表的语句。 - 运行完
createWordFrequencyRecords()后,内存中已存在单词记录表,sortWordFrequencyRecords()只需对其排序,不需要访问文件建立单词表。
- 结果:统计一个142MB的文本文档约需要28s,在JProfiler中检测性能约花费30.5s,JProfiler截图如下:
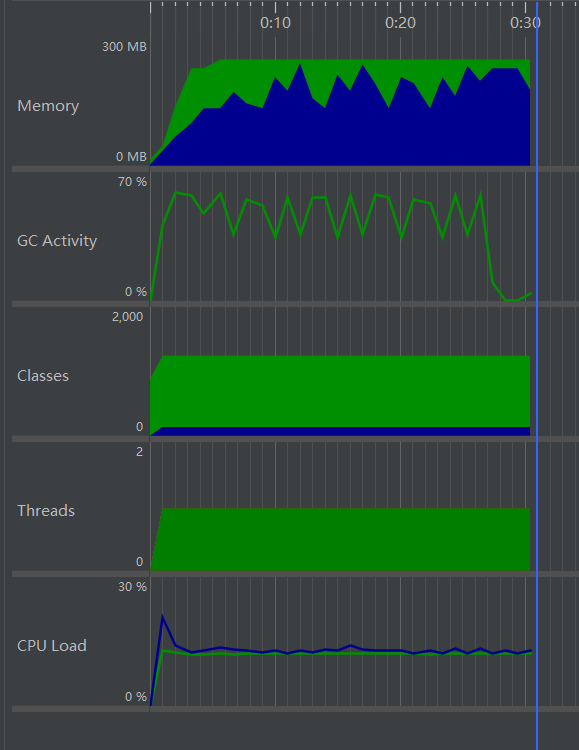
修改sort方法
Befor
先按字典序排序一次,再按频率从大到小排序一次,共排序2次。
After
修改自定义比较器,若两个单词频率相同,返回单词的字典序比较结果,否则返回单词频率差值。只排序1次。
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if (o1.getValue() == o2.getValue())
return o1.getKey().compareTo(o2.getKey());
else
return o2.getValue() - o1.getValue();
}
结果
统计一个142MB的文本文档约需要26s,在JProfiler中检测性能约花费30s,JProfiler截图如下:
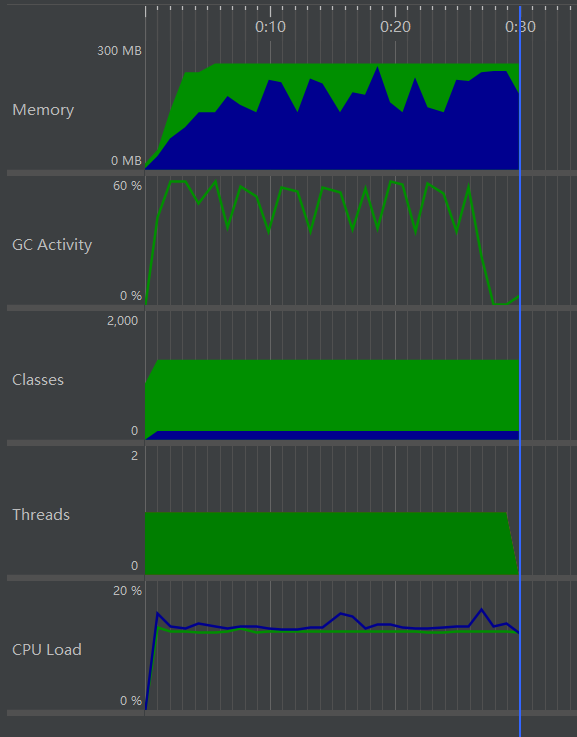
功能独立
修改统计字符、行数、单词数3个功能的代码,使其均可以作为一个独立的函数按使用者的需求被调用。
- 统计字符的函数
countTotalChar(),若检测到内存中chars != 0且数据源recordSource变量为当前输入的文件时,直接返回chars,不必再访问文件。否则访问文件统计字符数。 - 统计有效行数的函数
countValidLine(),若检测到内存中lines != 0且数据源recordSource变量为当前输入的文件时,直接返回lines,不必再访问文件。否则访问文件统计有效行数。 - 统计单词总数的函数
countTotalWord(),若检测到内存中words != 0且数据源recordSource变量为当前输入的文件时,直接返回words,不必再访问文件。否则访问文件利用正则表达式(^|[^a-z0-9])([a-z]{4}[a-z\d]*)统计单词总数。
部分单元测试
我认为优化代码覆盖率最好的方法就是所有编写的函数,都尽量在单元测试中涉及到。测试数据主要来源于我的胡乱敲键盘,文章提到的140多MB和400多MB的文件都来源于WY同学的分享。
测试Lib.countTotalChar()
利用两个文本内容一样的文件进行测试'\r'是否被正确检测,若被正确检测到,则以'\r\n'换行的文件的字符数会比以'\n'换行的文件多行数的个数。input1.1.txt是以'\n'换行,input1.2.txt是以'\r\n'换行。
@Test
public void countTotalChar() {
System.out.println("同样的内容在Unix下的总字符数:" + Lib.countTotalChar("./src/input1.1.txt"));
System.out.println("同样的内容在Windows下的总字符数:" + Lib.countTotalChar("./src/input1.2.txt"));
}
测试Lib.countTotalWord()
传入一个输入文件路径参数,人工计算输入文件的单词数,使用断言比对结果。
@Test
public void countTotalWord() {
Assert.assertEquals(Lib.countTotalWord("./src/input2.txt"), 9);
}
代码覆盖率截图:
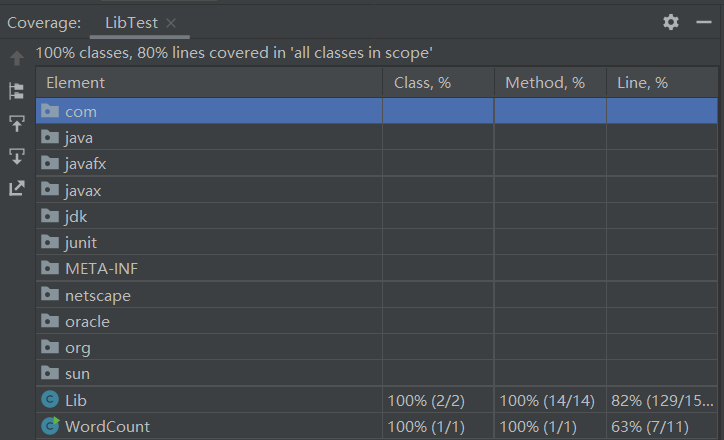
异常处理说明
我认为该程序涉及到的异常只会是命令行参数异常和文件异常,归纳了以下几种情况,并针对每种情况单元测试。
- 传入参数的个数不足2个,即没有同时给出输入文件路径和输出文件路径---->打印提示,并要求使用者输入两个文件路径
@Test
public void test1() {
String[] args = new String[1]; //没有传入2个参数
args[0] = "./src/input8.txt";
WordCount.main(args);
}
- 传入参数个数有2个,但是输入文件不存在---->打印提示,并要求使用者输入存在的文件路径
@Test
public void test2() {
String[] args = new String[2];
args[1] = "./src/output.txt"; //输出文件存在
args[0] = "./src/input1.1.cs"; //该输入文件不存在
WordCount.main(args);
}

- 传入参数个数有2个,输入文件存在,但输入文件的扩展名不为.txt---->打印提示,表示仍然可以读取该文件
@Test
public void test3() {
String[] args = new String[2];
args[1] = "./src/output.txt"; //输出文件存在
args[0] = "./src/input8.cs"; //输入文件存在,但格式不为.txt
WordCount.main(args);
}

- 传入参数个数有2个,输入文件存在,输入文件的扩展名为.txt,但输出文件不存在---->打印提示,程序自动创建同名.txt文件,如:不存在out.cs,但程序会创建out.txt
@Test
public void test4() {
String[] args = new String[2];
args[1] = "./src/out.txt"; //输出文件不存在
args[0] = "./src/input8.txt"; //该输入文件存在,且格式为.txt文件
WordCount.main(args);
}

- 传入参数个数有2个,输入文件存在,输入文件的扩展名为.txt,输出文件存在,但输出文件的扩展名不为.txt---->打印提示,程序自动创建同名.txt文件,如:存在out.cs,但程序会创建out.txt
@Test
public void test5() {
String[] args = new String[2];
args[1] = "./src/out.cs"; //输出文件存在
args[0] = "./src/input8.txt"; //该输入文件存在,且格式为.txt文件
WordCount.main(args);
}

心路历程与收获
在程序的设计中,与班上同学进行交流后发现,每个人思考问题的方式和解题方式真的不一样,各有各的侧重点。我主要的交流对象是WY同学,她的程序跑142MB的那个测试样本只需要15s,而我需要28s。但是她的程序在跑400+MB的样本时会发生爆内存的情况,而我的程序依然可以跑,耗时在1m22s左右。经过交流发现她是用空间换时间,将整个文本的内容存在一个字符串中,因此逻辑方面就少了很多判断分支,节省时间。而我的程序主要是一个一个读字符,只保存一个字符的内容,因此我的逻辑方面判断就比较复杂,增加了时间的开销。但是在统计超大文本的情况出现时,她的程序就会因为内存不足崩溃,而我的不会。只能说各有所长,提供的文本内容不多的时候,用她的程序显然更快速,但是一旦出现大几百MB的文件时,显然我的程序更占优势。
在博客开头,我也提出了有关上述事情的问题,当面对老师提供的需求时,究竟该选择哪一种方案更好呢?希望老师能给个解答。
经过这次开发过程。我体会到遇到问题就要立刻查资料、互相交流,吸收别人的方法,更要学会分析自己的性能与别人的性能相差很大时的原因是什么。当然,就算性能有时候不够好,也要肯定自己写的程序的优点,这样才能保证对编程一直充满热情和不断进取的心。
再次感谢WY同学对我的帮助!
附录
各功能解题路线

commit路线

