[PE结构]导入表与IAT表
导入表的结构导入表的结构
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date\time stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name;
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;
typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;
- Name
导入函数所在dll的名称 - OriginalFirstThunk FirstThunk
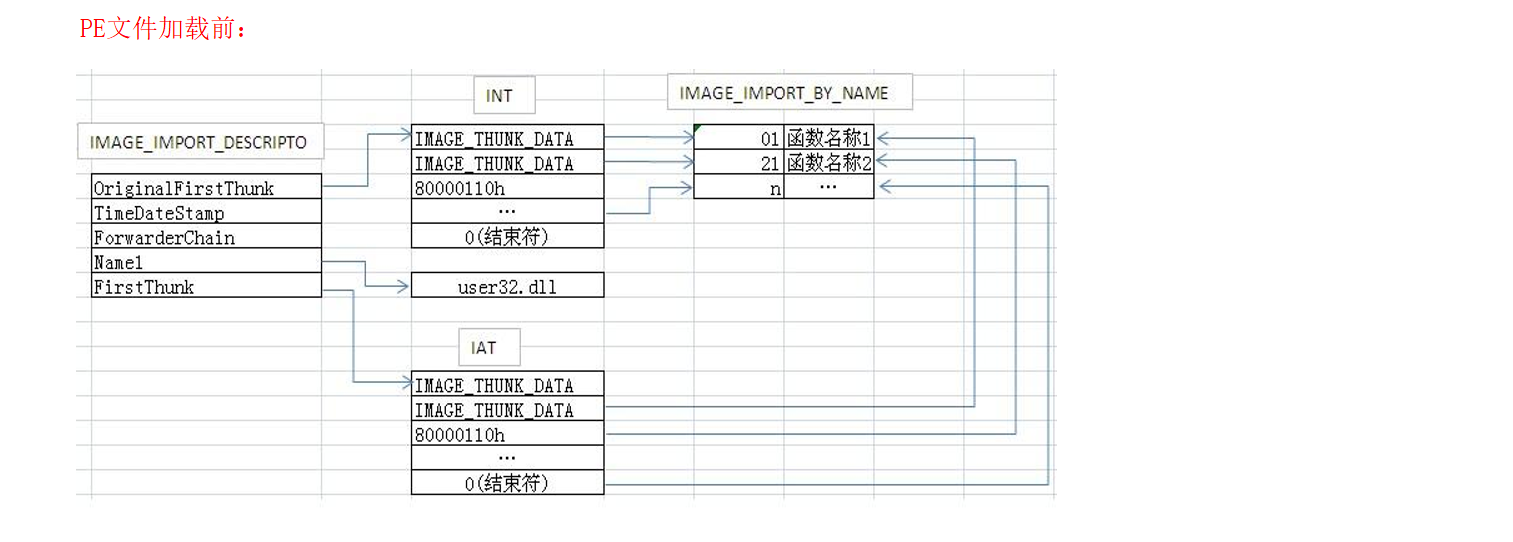
可以看到两个分别指向INT(Import Name Table)和IAT(Import Name Table)。
表中的每一项数据存放的需要的函数名或函数序号
那么怎么区分存放的是函数序号还是函数名呢?
如果最高位为1,则表示是存储的序号,序号的值为去掉最高位后其余位数的值
如果为0,则表示是函数名,它指向一个IMAGE_IMPORT_BY_NAME,其中存放着函数名
搞这么多表,看着头晕,设计者当时是嫌不够乱?
其实东西在那儿自然有在的意义,我们要做的就是找出有什么作用。
- 为什么要有IAT表或者INT表?
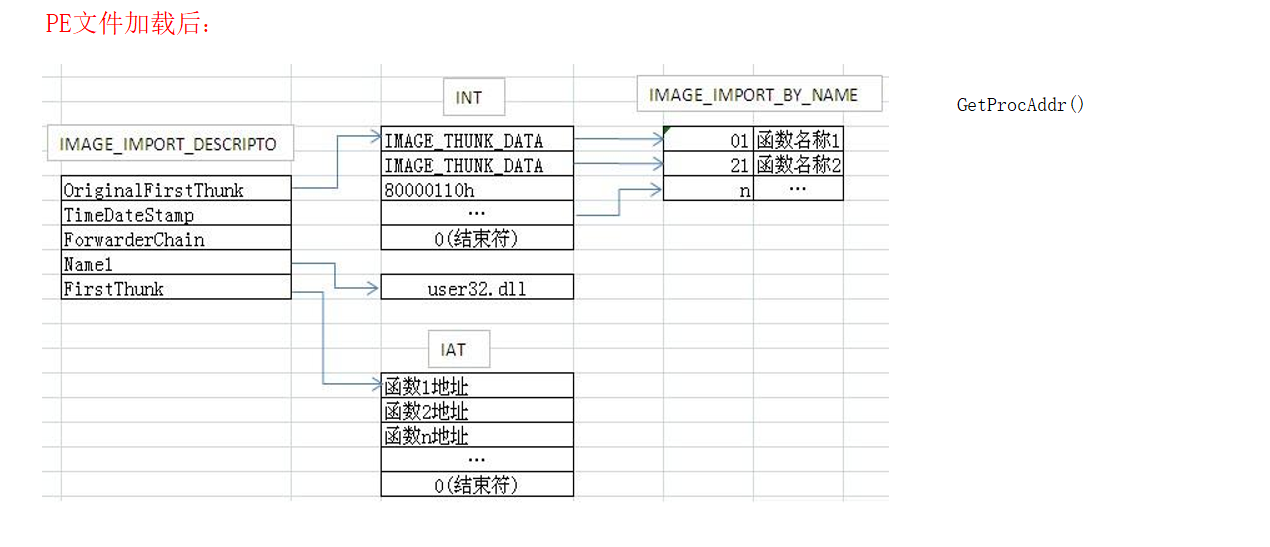
有人会想,导入表不就是告诉利用的外部函数地址吗?那为什么不可以将函数地址直接写入呢?其实是因为程序在编译链接时,最终都需要硬编码,并存盘。硬编码就会将函数地址固定了,而dll在加载时的地址可能会变化,如果此时函数名被硬编码,那么在调用时就可能失败,所以才会有张表,而调用一般是采用 call [0x111111]这种方式,最终函数地址可以动态化。 - 为什么同时要有IAT表和INT表?
是因为如果在程序加载后,IAT表中的就会变成函数地址,那么我们怎么区分哪个是哪个的函数地址呢?这时就可以通过INT表来确定了。可是编译后已经被硬编码了啊,完成函数调用已经没问题了,所以INT表应该是提供给需要知道函数名的需求者。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号