内存对齐详解
由底层深入内存对齐原理剖析
寻址花费的时间==》降低寻址次数,数据单元大>也就是内存和效率的互换
内存对齐前的内存分体技术
什么叫分体?分体是干嘛的?
硬件层都是01的天下,我们的数据也是位存储,我们存储数据时按道理是不是也应该这样一位位二进制进行存储。事实上,我们在日常操作中,常操作的是Byte,往往都是一个B一个B的进行存储。这实际上就是为了简化我们的日常操作,毕竟谁愿意存一个数据,需要自己一个bit一个bit得进行存储。于是这就形成了所谓的体,即8bit为一个(分)体。每个体在访问时,一次默认就读出一个体的数据长度,现如今的64位机,也就是说一个访问地址单元的数据为64位,即64条数据线,一次可读4K。
那如果在64位机中,我存有一个8位数据(16-31),该怎么访问呢。每次都要读出64位数据吗?
事实上,设计者们在最开始已经想好了。当需要时,可以通过控制电路,对数据线进行控制,也就是说,即使每个单元都链接有64根数据线,但可以只选中其中的16-31号地址线进行数据读取,从而达到逻辑上的8位位宽。
这也就解释了,为啥在固定64位机上,编译器等,可以调整对齐宽度,这些只是逻辑上的调整,最底层还是64位的对齐宽度。
接下来的内存对齐,都是基于逻辑上的内存对齐。
内存分配时,一个数据总是会尽量不被切开到多个地址单元中
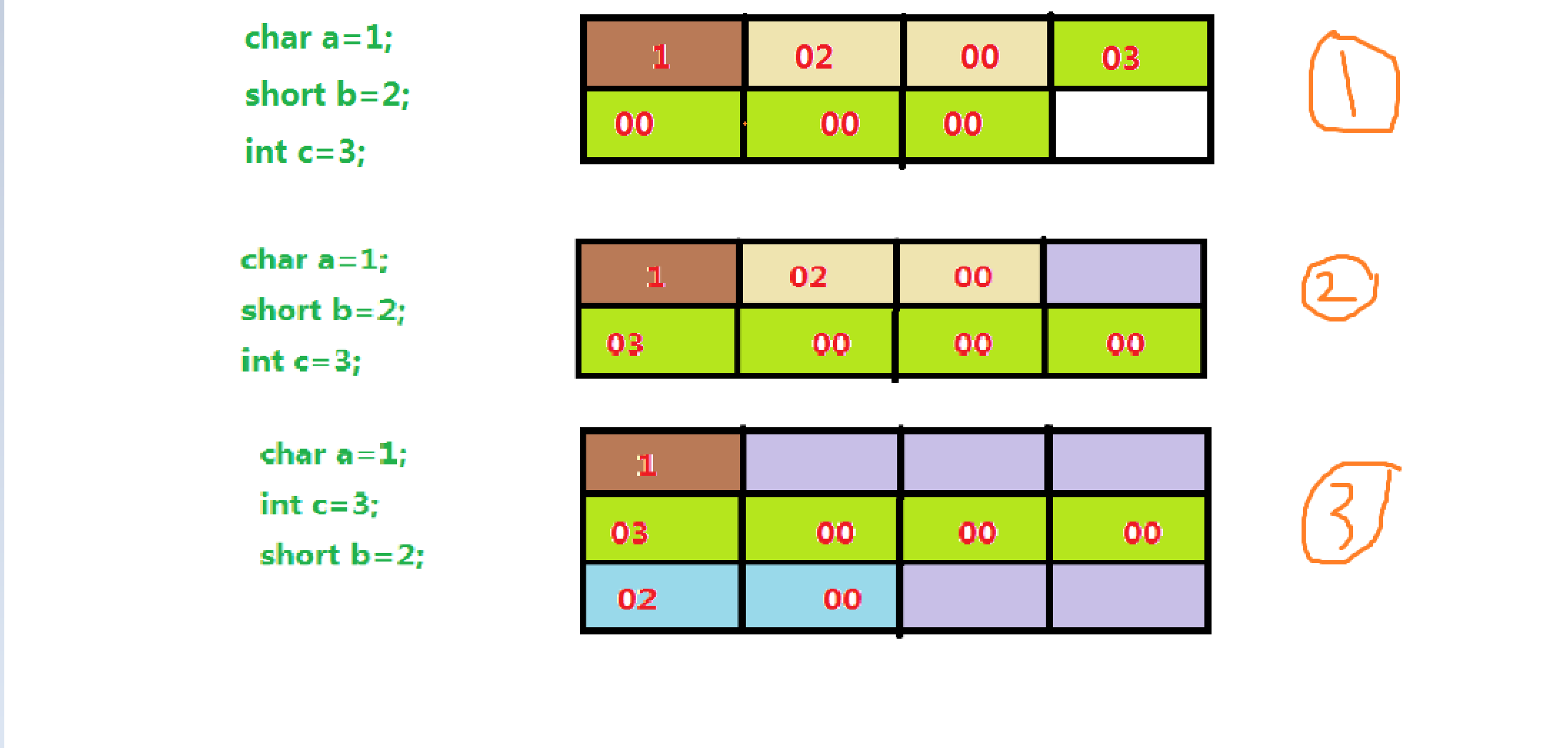 如图所示,紫色部分为浪费了的空间
如图所示,紫色部分为浪费了的空间
1.为什么不可以c直接接在后面进行存储呢?
这涉及到内存寻址,当数据被切开后,那么就要求寻址两次,才能获取完整的数据,由于寻址是要耗费CPU的,为了寻找一部分的数据,要多寻找一次,操作系统设计者觉得效率低下,相对于内存来说,cpu是很昂贵的,而且降低了整体效率,所以他们决定以空间换效率,也就是说,像第一种方式,它最后数据c只会进行一次寻址,从而提高了效率。
2.那么有人会说,既然这些数据存放不了,为什么不可以把其他数据再填充进来呢?
我想,如果还要把那些小碎片还得利用的话,那么是不是还需要一个表用以记录维护那些小碎片,这无疑降低了效率。为了效率,设计者们还是决定浪费部分空间,来提高整体的效率
由此,我们可以知道,今后在程序设计时,可以将数据从小到大进行定义,从而优化内存结构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号