大模型梳理
| Time | Org | Model | Language | Model Scale | Data Scale | Training Time | Training GPU | Inference GPU | Sequence Length |
|---|---|---|---|---|---|---|---|---|---|
| 2022.07 | 清华大学 | zn,en | GLM-130B | 1300 亿 | 4000 亿个tokens(中英各一半) | A100(40G * 8) 或 V100(32G * 8) | |||
| 2023.03 | 清华大学 | zn,en | ChatGLM-6B | 62 亿 | 1T tokens (中英各一半) | 13 GB(FP16 半精度)、10 GB(INT8)、6 GB(INT4) | 2048 | ||
| 清华大学 | zn,en | ChatGLM-10B | 1024 | ||||||
| Meta | zn,en | OPT-2.7B/13B/30B/66B | |||||||
| 2023.03 | Meta | zn,en | LLaMA-13B | 130 亿 | 单块V100 | ||||
| 2023.03 | Meta | zn,en | LLaMA-7B | ||||||
| 2023.03 | Meta | zn,en | LLaMA-65B | ||||||
| 2023.03 | Standford | en | Alpaca-7B | 52K 条指令 | 3小时 | 8A10080GB | |||
| Standford | en | Alpaca-Lora | 5小时 | 一块RTX 4090 | |||||
| zn,en | BELLE | 由chatGPT生成的 100万条中文数据 | |||||||
| zn,en | LLaMA(Large Language Model Meta AI) |
来源:
GLM-130B
https://keg.cs.tsinghua.edu.cn/glm-130b/zh/posts/glm-130b/
chatglm
https://chatglm.cn/blog
BELLE(Bloom-Enhanced Large Language Model Engine)
https://github.com/LianjiaTech/BELLE
https://www.jiqizhixin.com/articles/2023-03-22-7
LLaMA:据说可以媲美GPT-3,但是没有经过指令微调。
Stanford Alpaca:让 OpenAI 的 text-davinci-003 模型以 self-instruct 方式生成 52K 指令遵循(instruction-following)样本,以此作为 Alpaca 的训练数据。性能媲美GPT-3.5。
Alpaca-Lora:Stanford Alpaca 是在 LLaMA 整个模型上微调,而 Alpaca-Lora 则是利用 Lora 技术,在冻结原模型 LLaMA 参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅微调的成本显著下降,还能获得和全模型微调类似的效果。
技术:
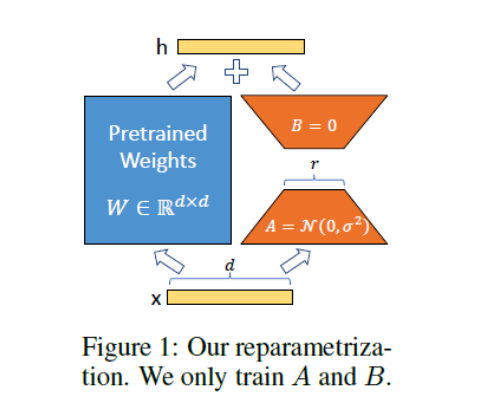
lora:low-rank adaptation 冻结原来的参数层,新增额外的参数层,只训练这些新增的参数层
LoRA 的思想是在原始 PLM 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank。训练的时候固定 PLM 的参数,只训练降维矩阵 A 与升维矩阵 B。而模型的输入输出维度不变,输出时将 BA 与 PLM 的参数叠加。用随机高斯分布初始化 A,用 0 矩阵初始化 B,保证训练的开始此旁路矩阵依然是 0 矩阵(引自:https://finisky.github.io/lora/)。
prompt-tuning:
- 冻结了预训练模型的权重,减少了训练的内存和时间
- 只用0.1%左右的任务特定参数(prompt)训练
p-tuning-v2:冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号