全站爬取链家网
一,获取链家独特的命名链接(全拼+缩写)
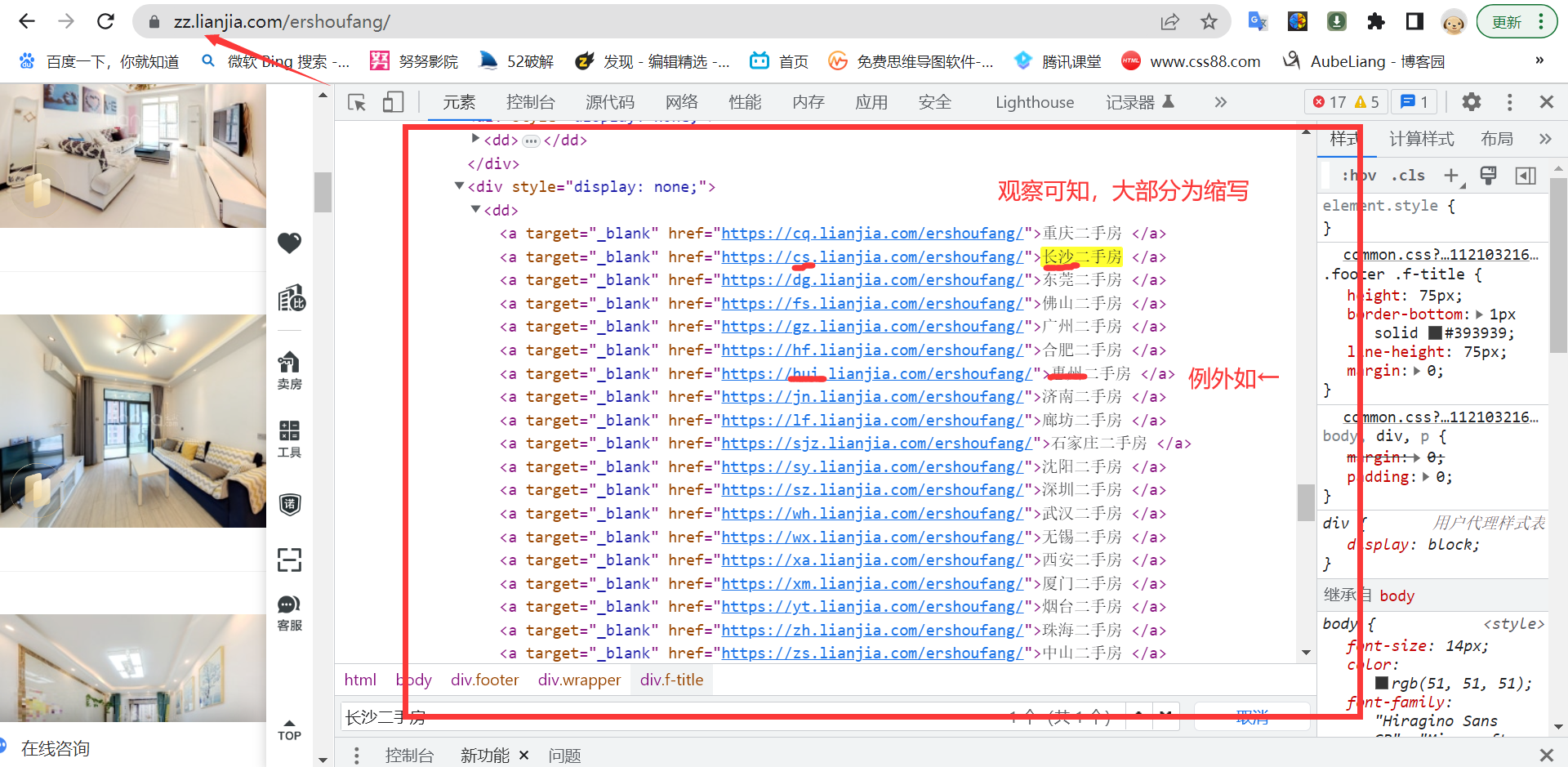
1、由上可知,链家的网页链接是采取城市名称缩写加普通链接的形式。
及 城市缩写+lianjia.com
但是存在一些问题,有部分城市的命名可能与其他城市重复,所以在这里,我需要重新获取链家的所有城市缩写命名
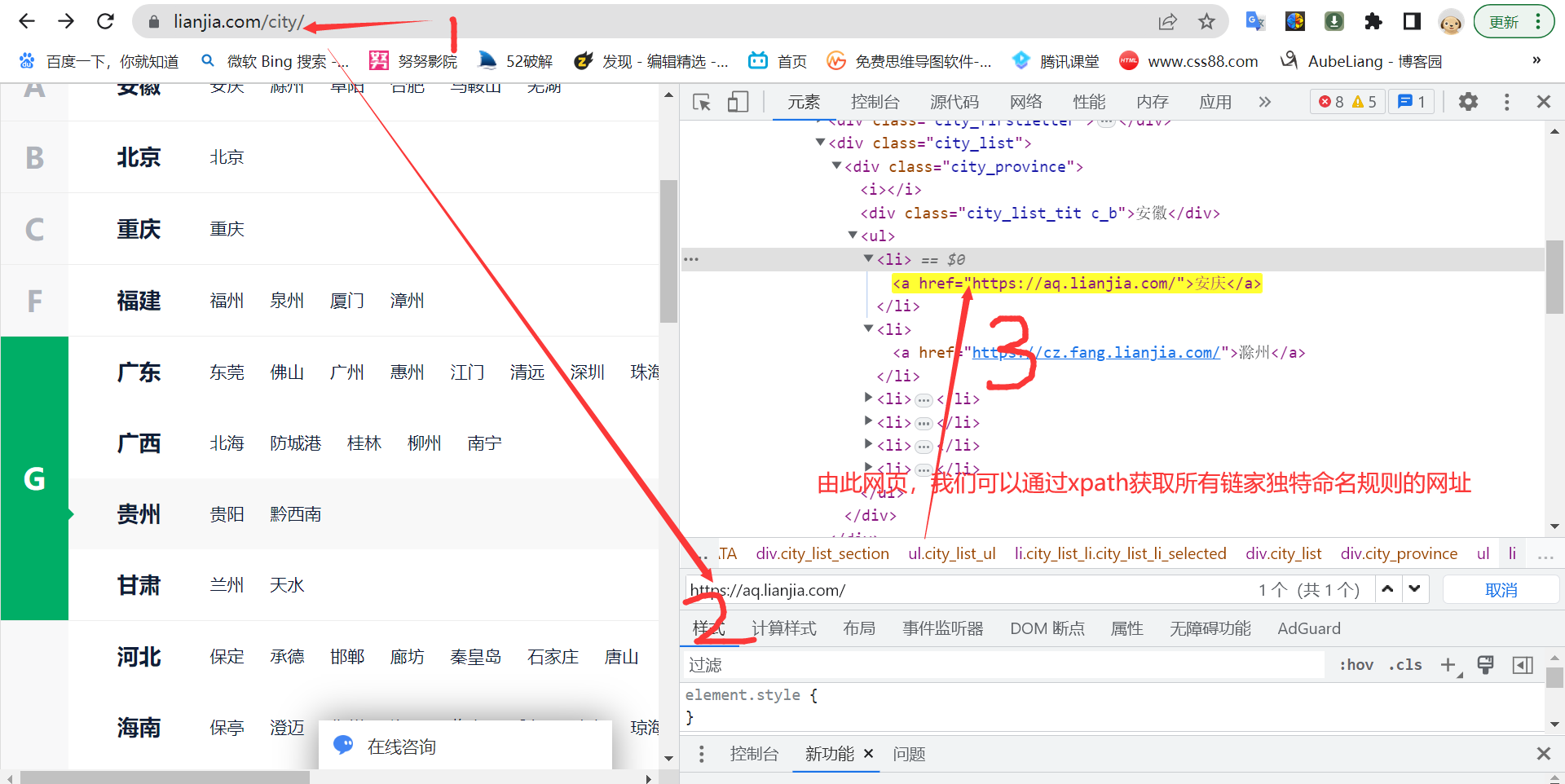
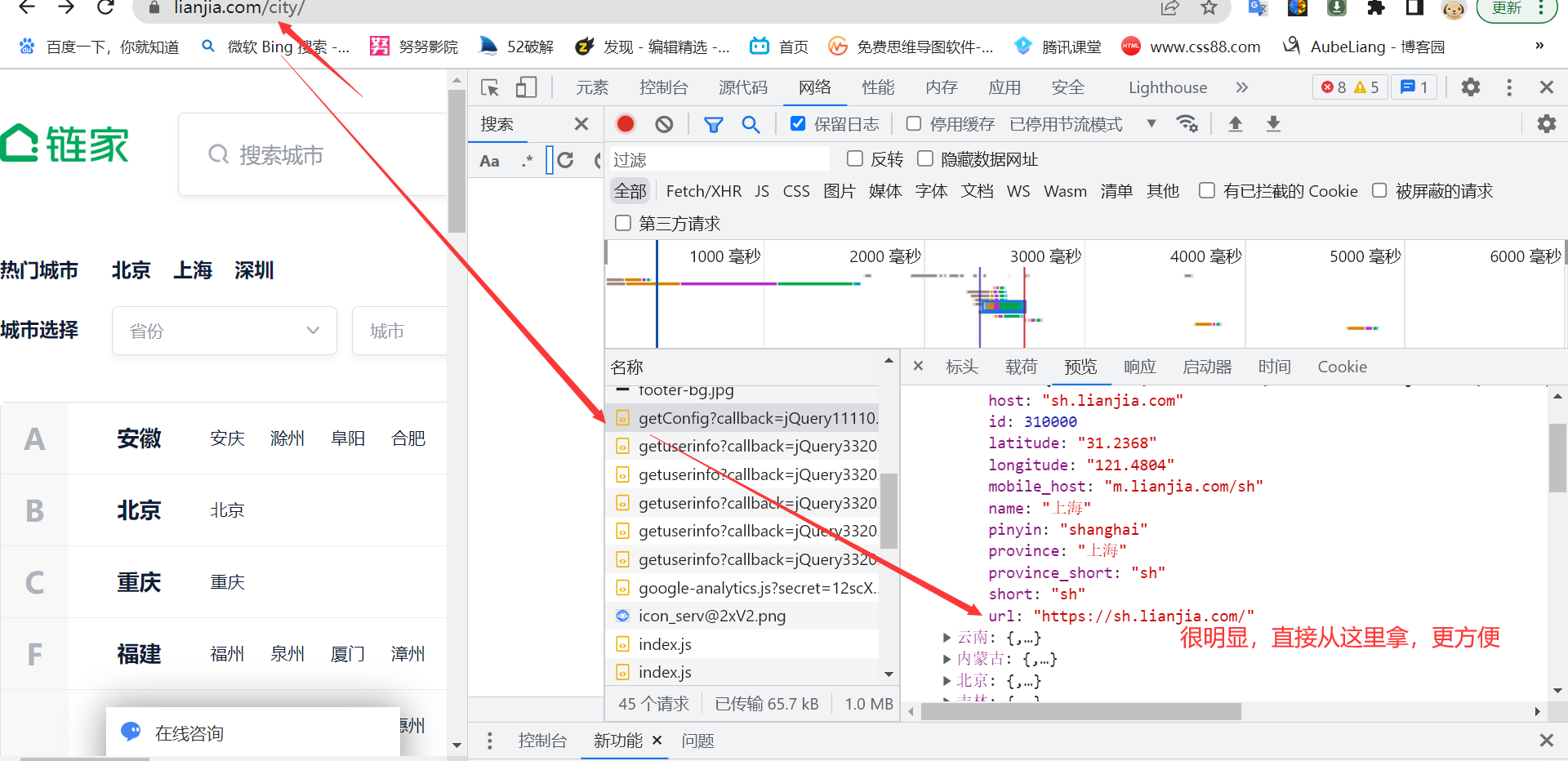
2、具体代码如下,这里我直接通过第二种方法拿到链接:
import requests
import json
import pprint
#获取城市名与对应链接
def get_url():
get_city_url='https://ajax.api.lianjia.com/config/cityConfig/getConfig?type=province&category=1'
json_data=json.loads(requests.get(url=get_city_url).text)['data']
url_list=[]
for key in json_data:
for id in json_data[key]:
ls={}
ls[json_data[key][id]['name']]=json_data[key][id]['url']
url_list.append(ls)
return url_list
get_url()
[{'济南': 'https://jn.lianjia.com/'},
{'泰安': 'https://ta.lianjia.com/'},
{'临沂': 'https://linyi.lianjia.com/'},
...
...
{'天津': 'https://tj.lianjia.com/'}]
for i in get_url():
s=i.values()
#获取链接
print('step1:')
print(s)
#将dict_values(['https://tj.lianjia.com/'])中的dict_values去掉
print('step2:')
print(list(s))
#获取字符类型链接
print('step3:')
print(list(s)[0])
step1:
dict_values(['https://tj.lianjia.com/'])
step2:
['https://tj.lianjia.com/']
step3:
https://tj.lianjia.com/
#只获取链接列表列表推导式
url_list=[list(i.values())[0]+'ershoufang/' for i in get_url()]
len(url_list)
url_list
['https://weihai.lianjia.com/ershoufang/',
'https://zjk.lianjia.com/ershoufang/',
'https://yibin.lianjia.com/ershoufang/',
...
...
'https://hrb.lianjia.com/ershoufang/',
'https://tj.lianjia.com/ershoufang/']
二,获取每个城市二手房房源信息最大页数
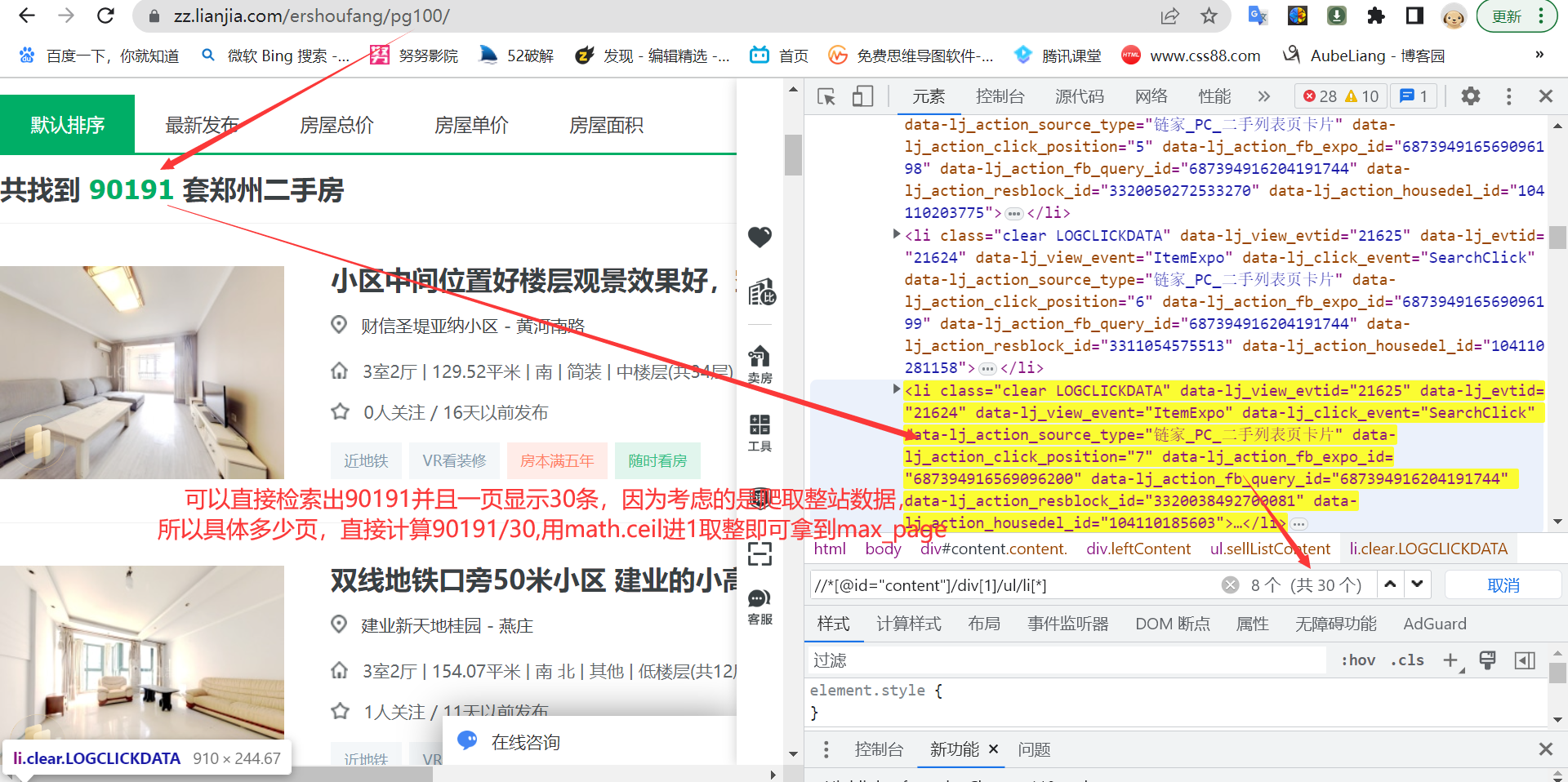
这里分为两种情况,一种是顶部显示最大套数,底部动态加载的页码(直接提取不到页码),如上图。另一种就是不显示最大套数,但底部数据可以直接获得,如下图。前者是大多数城市的页码获取方式,后者不多,但在整站爬取过程中让人如鲠在喉。
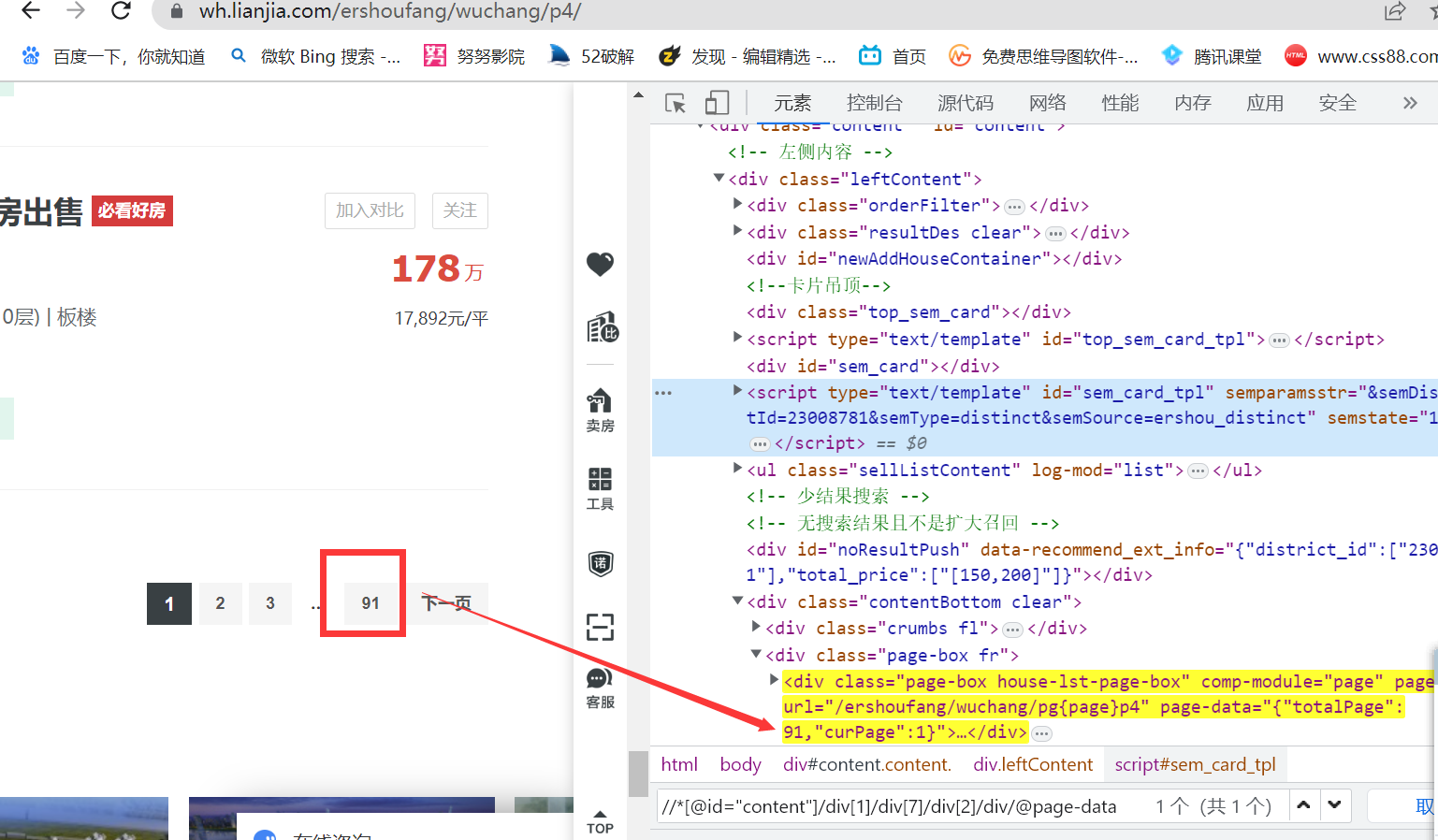
#第一种,适用于大部分城市
import requests
from lxml import etree
import math
def get_max_page(ershou_url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
}
ershou_url=ershou_url
ershou_req=requests.get(url=ershou_url,headers=headers)
web_html = etree.HTML(ershou_req.text)
number_of_houses=web_html.xpath('//*[@id="content"]/div[1]/div[2]/h2/span/text()')[0]
max_page=math.ceil(int(number_of_houses)/30)
return 100 if max_page>100 else max_page
get_max_page('https://zz.lianjia.com/ershoufang/')
#第二种,适用于极个别城市
def get_max_page2(ershou_url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
}
ershou_url=ershou_url
ershou_req=requests.get(url=ershou_url,headers=headers)
web_html = etree.HTML(ershou_req.text)
max_page=int(json.loads(web_html.xpath('//*[@id="content"]/div[1]/div[7]/div[2]/div/@page-data')[0])['totalPage'])
return max_page
get_max_page2('https://zz.lianjia.com/ershoufang/')
100
具体的网站结构没有细究,但链家的网站布局都不是一成不变的。。。
上面为什么要设置不能大于100呢?
每个城市链家二手房数据都只展示100页数据,一页30条,也就是3000条,但是我们可以通过分区+加分价格索引的方式,最大程度上的获取房源信息。
在后面的代码我会获取地区及价格的动态信息,通过索引方式最大程度拿到数据。
三,获取具体房源信息的链接
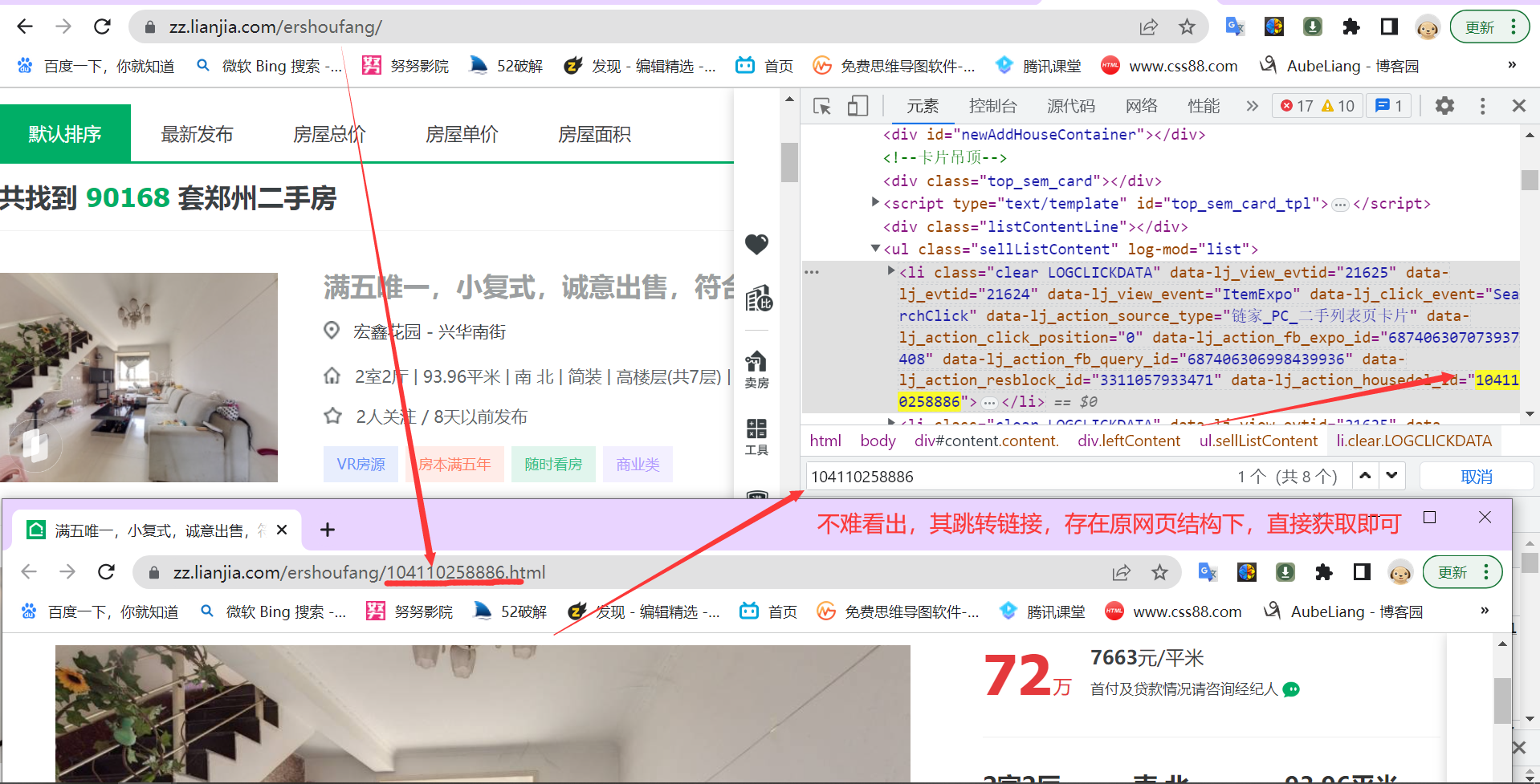
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
}
#获取一页的房源链接
def get_houses_url(url):
url=url
houses_res=requests.get(url=url,headers=headers)
if houses_res.status_code==200:
web_html = etree.HTML(houses_res.text)
houses_url_list=web_html.xpath('//*[@id="content"]/div[1]/ul/li[*]/a/@href')
return houses_url_list
else:
input('3、开始真人验证,输入任意字符继续。。')
get_houses_url(url)
#根据索引,最大页数,遍历获取所有房源链接,暂存本地
def get_all_url(url_l):
url_list=list(url_l.values())[0]
city_name=list(url_l.keys())[0]
regions,prices=get_regions_prices(url_list)
with open('./data/省会/{}.txt'.format(city_name), 'a') as f:
for re in regions:
for pr in prices:
page = 1
max_page=get_max_page2(url_list + re + '/' + pr + '/')
while True:
url = url_list + re + '/pg' + str(page) + pr + '/'
houses_url_list=get_houses_url(url)
for houses_url in houses_url_list:
f.write(houses_url+',')
page = page + 1
if page > max_page:
print('{} 网页下载完成'.format(url))
break
print('{} 全部获取成功!!!'.format(url_list))
city_list=[{'济南': 'https://jn.lianjia.com/'},
{'泰安': 'https://ta.lianjia.com/'},
{'临沂': 'https://linyi.lianjia.com/'},
{'菏泽': 'https://heze.lianjia.com/'},
{'济宁': 'https://jining.lianjia.com/'},
{'淄博': 'https://zb.lianjia.com/'},
{'潍坊': 'https://wf.lianjia.com/'},
{'青岛': 'https://qd.lianjia.com/'},
{'烟台': 'https://yt.lianjia.com/'},
{'威海': 'https://weihai.lianjia.com/'},
{'廊坊': 'https://lf.lianjia.com/'},
{'唐山': 'https://ts.lianjia.com/'},
{'保定': 'https://bd.lianjia.com/'},
{'石家庄': 'https://sjz.lianjia.com/'},
{'邯郸': 'https://hd.lianjia.com/'},
{'承德': 'https://chengde.lianjia.com/'},
{'秦皇岛': 'https://qhd.fang.lianjia.com/'},
{'张家口': 'https://zjk.lianjia.com/'},
{'南充': 'https://nanchong.lianjia.com/'},
{'德阳': 'https://dy.lianjia.com/'},
{'雅安': 'https://yaan.lianjia.com/'},
{'遂宁': 'https://sn.lianjia.com/'},
{'资阳': 'https://ziyang.lianjia.com/'},
{'成都': 'https://cd.lianjia.com/'},
{'达州': 'https://dazhou.lianjia.com/'},
{'乐山': 'https://leshan.fang.lianjia.com/'},
{'凉山': 'https://liangshan.lianjia.com/'},
{'攀枝花': 'https://pzh.lianjia.com/'},
{'广元': 'https://guangyuan.lianjia.com/'},
{'眉山': 'https://ms.fang.lianjia.com/'},
{'绵阳': 'https://mianyang.lianjia.com/'},
{'宜宾': 'https://yibin.lianjia.com/'},
{'东莞': 'https://dg.lianjia.com/'},
{'湛江': 'https://zhanjiang.lianjia.com/'},
{'珠海': 'https://zh.lianjia.com/'},
{'清远': 'https://qy.lianjia.com/'},
{'江门': 'https://jiangmen.lianjia.com/'},
{'深圳': 'https://sz.lianjia.com/'},
{'惠州': 'https://hui.lianjia.com/'},
{'中山': 'https://zs.lianjia.com/'},
{'佛山': 'https://fs.lianjia.com/'},
{'广州': 'https://gz.lianjia.com/'},
{'昆明': 'https://km.lianjia.com/'},
{'西双版纳': 'https://xsbn.fang.lianjia.com/'},
{'大理': 'https://dali.lianjia.com/'},
{'绍兴': 'https://sx.lianjia.com/'},
{'宁波': 'https://nb.lianjia.com/'},
{'金华': 'https://jh.lianjia.com/'},
{'义乌': 'https://yw.lianjia.com/'},
{'温州': 'https://wz.lianjia.com/'},
{'台州': 'https://taizhou.lianjia.com/'},
{'衢州': 'https://quzhou.lianjia.com/'},
{'嘉兴': 'https://jx.lianjia.com/'},
{'湖州': 'https://huzhou.lianjia.com/'},
{'杭州': 'https://hz.lianjia.com/'},
{'万宁': 'https://wn.fang.lianjia.com/'},
{'文昌': 'https://wc.fang.lianjia.com/'},
{'琼海': 'https://qh.fang.lianjia.com/'},
{'五指山': 'https://wzs.fang.lianjia.com/'},
{'儋州': 'https://dz.fang.lianjia.com/'},
{'海口': 'https://hk.lianjia.com/'},
{'三亚': 'https://san.lianjia.com/'},
{'陵水': 'https://ls.fang.lianjia.com/'},
{'乐东': 'https://ld.fang.lianjia.com/'},
{'临高': 'https://lg.fang.lianjia.com/'},
{'澄迈': 'https://cm.lianjia.com/'},
{'保亭': 'https://bt.fang.lianjia.com/'},
{'西安': 'https://xa.lianjia.com/'},
{'汉中': 'https://hanzhong.lianjia.com/'},
{'宝鸡': 'https://baoji.lianjia.com/'},
{'咸阳': 'https://xianyang.lianjia.com/'},
{'安庆': 'https://aq.lianjia.com/'},
{'阜阳': 'https://fy.lianjia.com/'},
{'合肥': 'https://hf.lianjia.com/'},
{'马鞍山': 'https://mas.lianjia.com/'},
{'芜湖': 'https://wuhu.lianjia.com/'},
{'滁州': 'https://cz.fang.lianjia.com/'},
{'上饶': 'https://sr.lianjia.com/'},
{'赣州': 'https://ganzhou.lianjia.com/'},
{'南昌': 'https://nc.lianjia.com/'},
{'九江': 'https://jiujiang.lianjia.com/'},
{'吉安': 'https://jian.lianjia.com/'},
{'株洲': 'https://zhuzhou.lianjia.com/'},
{'岳阳': 'https://yy.lianjia.com/'},
{'长沙': 'https://cs.lianjia.com/'},
{'湘西': 'https://xx.lianjia.com/'},
{'衡阳': 'https://hy.lianjia.com/'},
{'常德': 'https://changde.lianjia.com/'},
{'镇江': 'https://zj.lianjia.com/'},
{'句容': 'https://jr.lianjia.com/'},
{'丹阳': 'https://danyang.lianjia.com/'},
{'淮安': 'https://ha.lianjia.com/'},
{'常州': 'https://changzhou.lianjia.com/'},
{'昆山': 'https://ks.lianjia.com/'},
{'常熟': 'https://changshu.lianjia.com/'},
{'盐城': 'https://yc.lianjia.com/'},
{'苏州': 'https://su.lianjia.com/'},
{'南京': 'https://nj.lianjia.com/'},
{'太仓': 'https://taicang.lianjia.com/'},
{'江阴': 'https://jy.lianjia.com/'},
{'南通': 'https://nt.lianjia.com/'},
{'无锡': 'https://wx.lianjia.com/'},
{'海门': 'https://haimen.lianjia.com/'},
{'徐州': 'https://xz.lianjia.com/'},
{'驻马店': 'https://zmd.lianjia.com/'},
{'郑州': 'https://zz.lianjia.com/'},
{'濮阳': 'https://py.lianjia.com/'},
{'三门峡': 'https://smx.fang.lianjia.com/'},
{'周口': 'https://zk.lianjia.com/'},
{'平顶山': 'https://pds.lianjia.com/'},
{'新乡': 'https://xinxiang.lianjia.com/'},
{'洛阳': 'https://luoyang.lianjia.com/'},
{'许昌': 'https://xc.lianjia.com/'},
{'济源': 'https://jiyuan.fang.lianjia.com/'},
{'开封': 'https://kf.lianjia.com/'},
{'乌鲁木齐': 'https://wlmq.lianjia.com/'},
{'长春': 'https://cc.lianjia.com/'},
{'吉林': 'https://jl.lianjia.com/'},
{'福州': 'https://fz.lianjia.com/'},
{'泉州': 'https://quanzhou.lianjia.com/'},
{'漳州': 'https://zhangzhou.lianjia.com/'},
{'厦门': 'https://xm.lianjia.com/'},
{'重庆': 'https://cq.lianjia.com/'},
{'包头': 'https://baotou.lianjia.com/'},
{'通辽': 'https://tongliao.lianjia.com/'},
{'呼和浩特': 'https://hhht.lianjia.com/'},
{'巴彦淖尔': 'https://byne.fang.lianjia.com/'},
{'赤峰': 'https://cf.lianjia.com/'},
{'防城港': 'https://fcg.lianjia.com/'},
{'柳州': 'https://liuzhou.lianjia.com/'},
{'北海': 'https://bh.lianjia.com/'},
{'南宁': 'https://nn.lianjia.com/'},
{'桂林': 'https://gl.lianjia.com/'},
{'运城': 'https://yuncheng.lianjia.com/'},
{'晋中': 'https://jz.lianjia.com/'},
{'太原': 'https://ty.lianjia.com/'},
{'北京': 'https://bj.lianjia.com/'},
{'鄂州': 'https://ez.lianjia.com/'},
{'黄石': 'https://huangshi.lianjia.com/'},
{'襄阳': 'https://xy.lianjia.com/'},
{'武汉': 'https://wh.lianjia.com/'},
{'宜昌': 'https://yichang.lianjia.com/'},
{'黔西南': 'https://qxn.fang.lianjia.com/'},
{'贵阳': 'https://gy.lianjia.com/'},
{'大连': 'https://dl.lianjia.com/'},
{'丹东': 'https://dd.lianjia.com/'},
{'沈阳': 'https://sy.lianjia.com/'},
{'抚顺': 'https://fushun.lianjia.com/'},
{'银川': 'https://yinchuan.lianjia.com/'},
{'天水': 'https://tianshui.lianjia.com/'},
{'兰州': 'https://lz.lianjia.com/'},
{'上海': 'https://sh.lianjia.com/'},
{'哈尔滨': 'https://hrb.lianjia.com/'},
{'天津': 'https://tj.lianjia.com/'}]
#遍历获取所有房源链接
for url_list in city_list:
print(url_list)
get_all_url(url_list)
#多线程 不推荐,大型网站对于爬虫很忌讳,多线程我尝试用代理池,随机请求头都会出现人机识别,跳不过去。。当然,这么大的网站,有一点反爬也很正常。
#非要用的话,在代码里添加try机制,当出现异常,手动跳过人机验证即可。速度倒是很可观。
from multiprocessing.dummy import Pool
pool = Pool(8)
pool.map(get_all_url, city_list)
四,获取房源具体信息
建库
create database lianjia DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
创表
create table tianjin(
total varchar(16),
unitPrice varchar(16),
communityName varchar(32),
areaName varchar(32),
base_list longtext,
transaction_list longtext,
tags_clear varchar(50),
baseattribute_clear varchar(100),
url varchar(255)
) default charset=utf8;
#汇总
def geturl(city):
city=city
with open('./data/{}.txt'.format(city), 'r') as f:
content = f.read()
url_lists=content.split(',')[:-1]
url_list=set(url_lists)
print(f'去重前{len(url_lists)}个链接-------去重后{len(url_list)}个链接')
return list(url_list)
import requests
from lxml import etree
from fake_useragent import UserAgent
count=0
def get_detailed_house(url):
global count
count+=1
print(f'第{count}个房源')
headers= {'User-Agent':str(UserAgent().random)}
url=url
print(f'{url} 开始')
r = requests.get(url, headers=headers)
if r.status_code==200:
web_html = etree.HTML(r.text)
try:
#总价
total=web_html.xpath('/html/body/div[5]/div[2]/div[3]/div/span[1]/text()')[0]
#单价
unitPrice=web_html.xpath('/html/body/div[5]/div[2]/div[3]/div/div[1]/div[1]/span/text()')[0]
except:
#总价
total=web_html.xpath('/html/body/div[5]/div[2]/div[4]/p/span/text()')[0]
#单价
unitPrice=web_html.xpath('/html/body/div[5]/div[2]/div[4]/p/span/text()')[1]
#小区名
communityName=web_html.xpath('/html/body/div[5]/div[2]/div/div[1]/a[1]/text()')[0]
#位置
areaName=''
for i in web_html.xpath('/html/body/div[5]/div[2]/div/div[2]/span[2]/a/text()'):
areaName+=i
################################ 基本信息 #################################
base_list=web_html.xpath('//*[@id="introduction"]/div/div/div[1]/div[2]/ul/li/text()')
#房屋户型
#所在楼层
#建筑面积
#户型结构
#套内面积
#建筑类型
#房屋朝向
#建筑结构
#装修情况
#梯户比例
#配备电梯
################################ 交易属性 #################################
transaction_list=[t.strip() for t in web_html.xpath('//*[@id="introduction"]/div/div/div[2]/div[2]/ul/li/span[2]/text()') ]
#挂牌时间
#交易权属
#上次交易
#房屋用途
#房屋年限
#产权所属
#抵押信息
#房本备件
################################ 房源特色 #################################
try:
#房源标签
tags_clear=[t.strip() for t in web_html.xpath('/html/body/div[7]/div/div[2]/div/div[1]/div[2]/a/text()')]
#h核心卖点
baseattribute_clear=web_html.xpath('/html/body/div[7]/div/div[2]/div/div[2]/div[2]/text()')[0].strip()
except:
tags_clear='暂无数据'
baseattribute_clear='暂无数据'
#房屋链接
#print(total,unitPrice,communityName,areaName,base_list,transaction_list,tags_clear,baseattribute_clear,url)
sql='insert into tianjin(total,unitPrice,communityName,areaName,base_list,transaction_list,tags_clear,baseattribute_clear,url) values (%s,%s,%s,%s,%s,%s,%s,%s,%s)'
cursor.execute(sql, [total,unitPrice,communityName,areaName,str(base_list),str(transaction_list),str(tags_clear),baseattribute_clear,url,])
conn.commit()
print(f'++++++++++++第{count}个房源 {url} 下载完成!+++++++++++++')
elif r.status_code==404:
pass
else:
input('人机验证,任意字符继续...:')
#main
import pymysql
from multiprocessing.dummy import Pool
# 1.连接MySQL
conn = pymysql.connect(host="127.0.0.1", port=3306, user='root', passwd="******", charset='utf8', db='lianjia')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
#测试
# url='https://zz.lianjia.com/ershoufang/104107897508.html'
# get_detailed_house(url)
#单线程
# url_list=geturl('郑州')
# for url in url_list:
# try:
# get_detailed_house(url)
# except:
# pass
#多线程
url_list=geturl('天津')
pool = Pool(10)
pool.map(get_detailed_house,url_list)
# url='https://zz.lianjia.com/ershoufang/104107897508.html'
# get_detailed_house(url)
cursor.close()
conn.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号