

使用Scrapy爬取豆瓣图书并存储在数据库
一、目标
通过对Scrapy爬取项目的设计与实现,掌握Scrapy框架的用法和Mysql的基本操作,学会使用Scrapy框架爬取网页数据并保存至数据库
二、分析网页结构
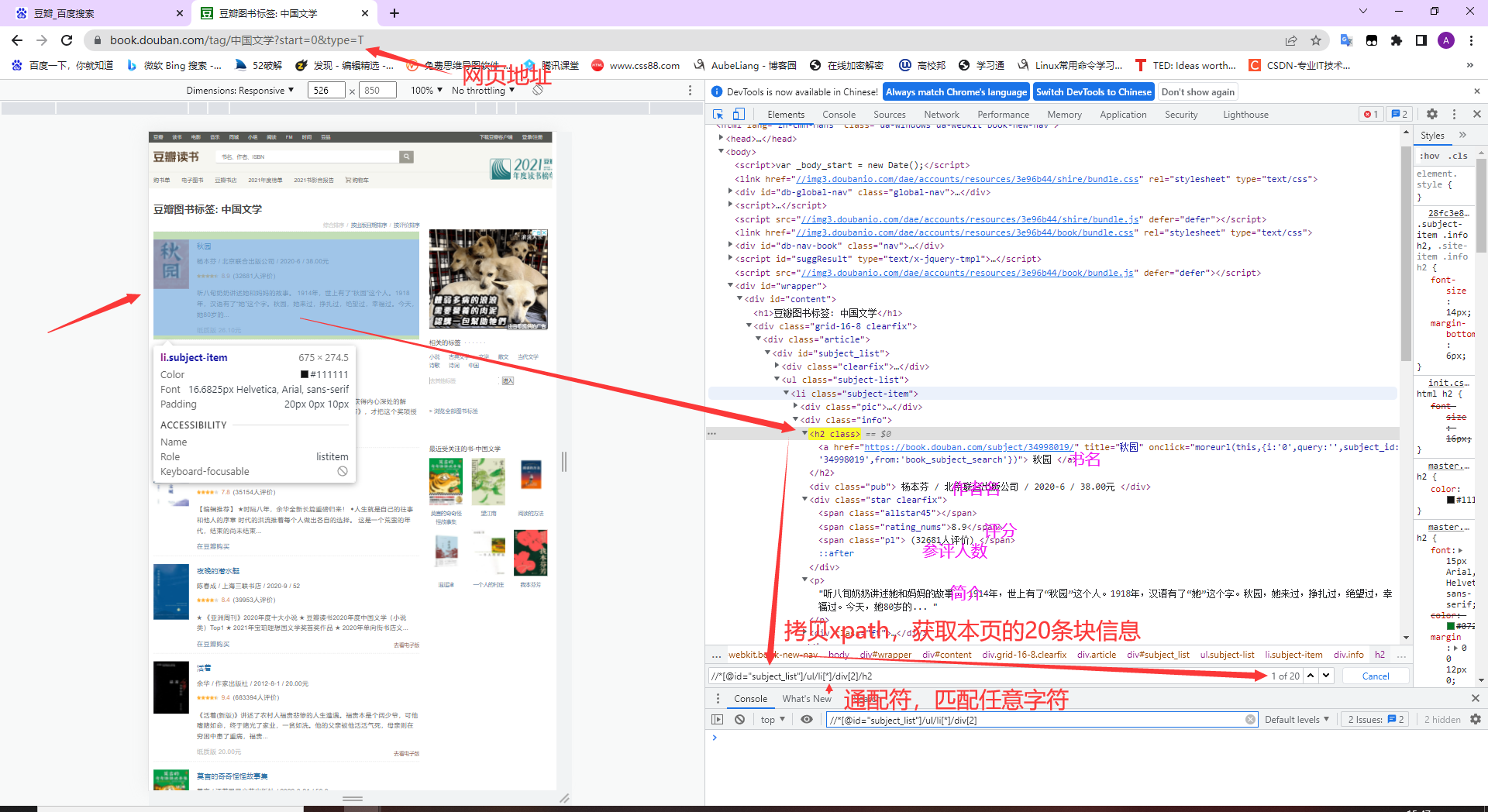
三、创建Scrapy项目并命名为douban
1 | scrapy startproject douban |
四、编写或修改代码
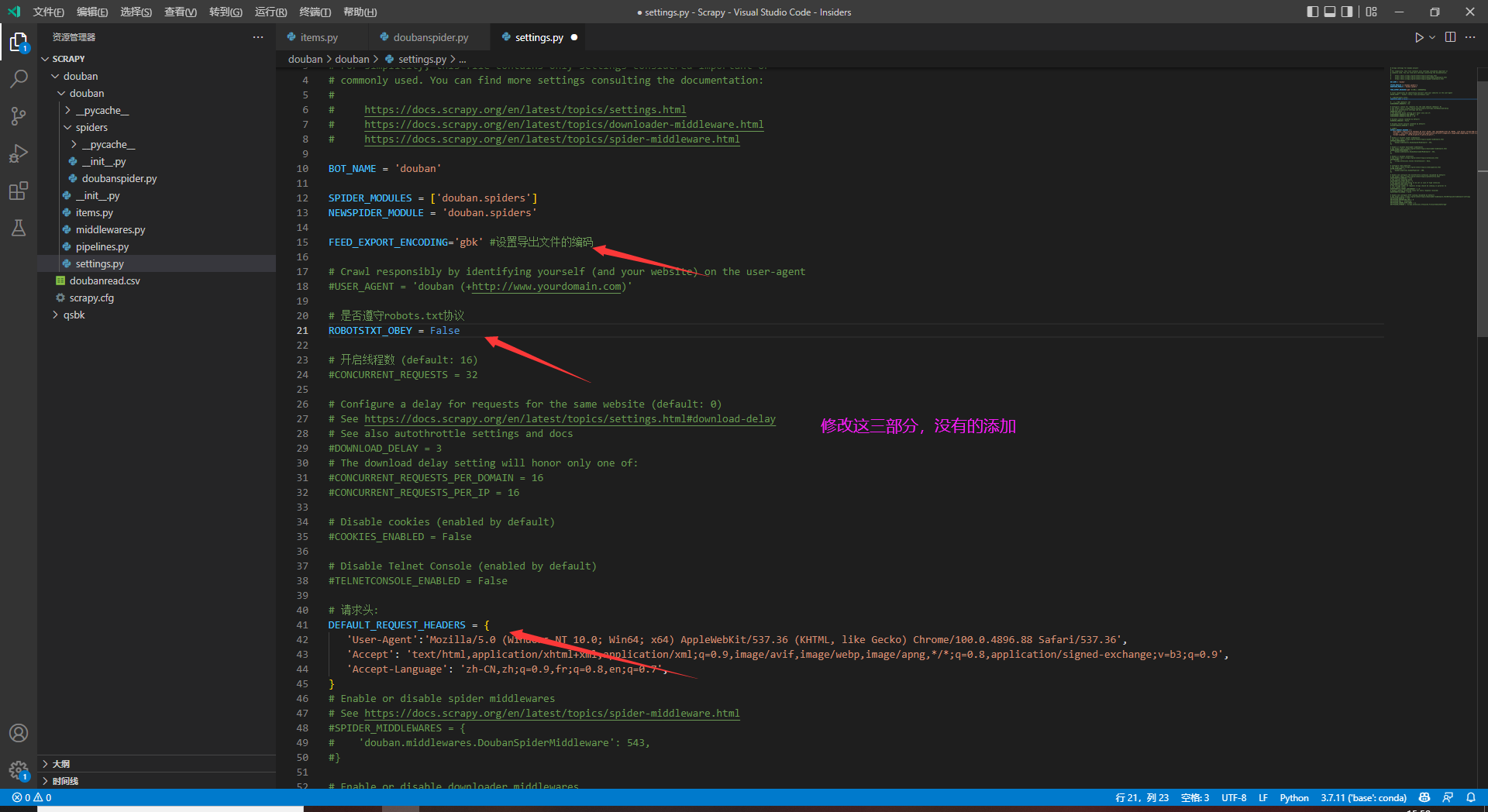
1.修改settings.py
2、设置items.py
1 2 3 4 5 6 7 8 9 10 11 | import scrapyclass DoubanItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() book_name = scrapy.Field() author = scrapy.Field() grade = scrapy.Field() count = scrapy.Field() introduction = scrapy.Field() |
3、在spiders目录下新建一个doubanspider.py,编写如下代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | import scrapyfrom douban.items import DoubanItemimport timeclass DoubanspiderSpider(scrapy.Spider): name = 'doubanspider' #过滤爬取的域名 allowed_domains = ['douban.com'] def start_requests(self): #起始url url = 'https://book.douban.com/tag/%E4%B8%AD%E5%9B%BD%E6%96%87%E5%AD%A6' yield scrapy.Request(url,callback = self.parse,dont_filter = True) def parse(self, response): item = DoubanItem() info_list = response.xpath('//div[@class="info"]') for info in info_list: #休眠1秒 time.sleep(1) if info!=None and info!='': if (info.xpath('./h2/a/text()').extract_first()!=None) and (info.xpath('./div[@class="pub"]/text()').extract_first()!=None) and (info.xpath('./div[2]/span[3]/text()').extract_first()!=None) and (info.xpath('./p/text()').extract_first()!=None): item['book_name'] = info.xpath('./h2/a/text()').extract_first().strip()#去除空格 str.strip() item['author'] = info.xpath('./div[@class="pub"]/text()').extract_first().strip().split('/')[0] item['grade'] = info.xpath('./div[2]/span[2]/text()').extract_first() item['count'] = info.xpath('./div[2]/span[3]/text()').extract_first().strip().replace('\n','') # item['introduction'] = info.xpath('./p/text()').extract_first().replace('\n','').replace("'", "").replace('"', '') item['introduction'] = info.xpath('./p/text()').extract_first().replace('\n','') else: continue else: pass yield item #获取下一页的url next_temp_url = response.xpath("//div[@id='subject_list']/div[@class='paginator']/span[@class='next']/a/@href").extract_first() if next_temp_url: next_url = response.urljoin(next_temp_url) yield scrapy.Request(next_url) |
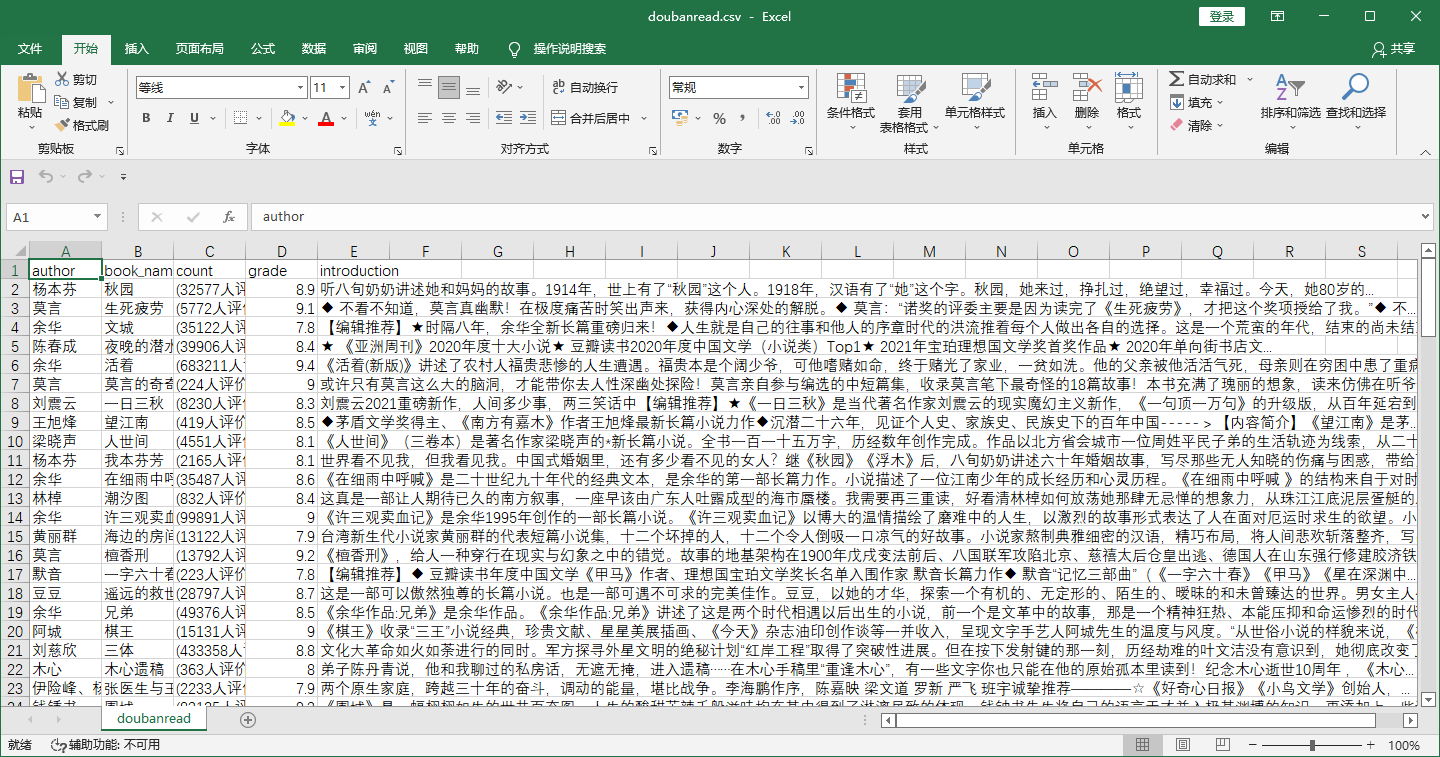
4、尝试保存本地.csv文件
在与scrapy.cfg同目录下,cmd运行如下命令:
1 | scrapy crawl doubanspider -o doubanread.csv |
5、创建MySQL数据库douban和数据表doubanread

drop database if exists douban;
create database if not exists douban charset=gbk;
use douban;
create table doubanread(
id int(11) primary key not null auto_increment,
book_name varchar(255) default null,
author varchar(255) default null,
grade varchar(255) default null,
count varchar(255) default null,
introduction varchar(255) default null
) engine=innoDB auto_increment=1409 default charset=utf8;
6、设置pipelines.py(这里踩了个坑,千万别用MySQLdb!!!!!)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | # Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interfa数据库存在则删除mysqlce#from itemadapter import ItemAdapter# import MySQLdbimport pymysql# # 加载settings文件# from scrapy.utils.project import get_project_settingsclass DoubanPipeline(object): # def process_item(self, item, spider): # return item # def __init__(self): # self.db = MySQLdb.connect('localhost','root','yourpwd','douban',charset='gbk') # self.cursor = self.db.cursor() # def process_item(self, item, spider): # book_name = item.get('book_name','N/A') # author = item.get('author','N/A') # grade = item.get('grade','N/A') # count = item.get('count','N/A') # introduction = item.get('introduction','N/A') # sql = "insert into doubanread(book_name,author,grade,count,introduction) values ('%s','%s','%s','%s','%s')" # self.cursor.execute(sql,(book_name,author,grade,count,MySQLdb.escape_string(introduction).decode('gbk'))) # # self.cursor.execute(sql,(book_name,author,grade,count,introduction)) # print("========================================插入成功==========================================") # self.db.commit() # def close_spider(self,spider): # self.cursor.close() # self.db.close() def __init__(self): self.host = 'localhost' self.port = 3306 self.user = 'root' self.password = 'yourppd' self.db = 'douban' self.charset = 'utf8' self.connet() def connet(self): self.conn = pymysql.connect( host=self.host,port=self.port,user=self.user,password=self.password,db=self.db,charset=self.charset) #创建游标 self.cursor = self.conn.cursor() def process_item(self, item, spider): sql = "insert into doubanread(book_name,author,grade,count,introduction) values ('{}','{}','{}','{}','{}')".format(item['book_name'],item['author'],item['grade'],item['count'],item['introduction']) # 执行sql语句 self.cursor.execute(sql) # 提交事务 self.conn.commit() print("=================================提交完成=======================================") return item def __del__(self): self.cursor.close() self.conn.close() |
这里有个细节,settings.py下 记得开启通道
1 2 3 | ITEM_PIPELINES = { 'douban.pipelines.DoubanPipeline': 300,} |
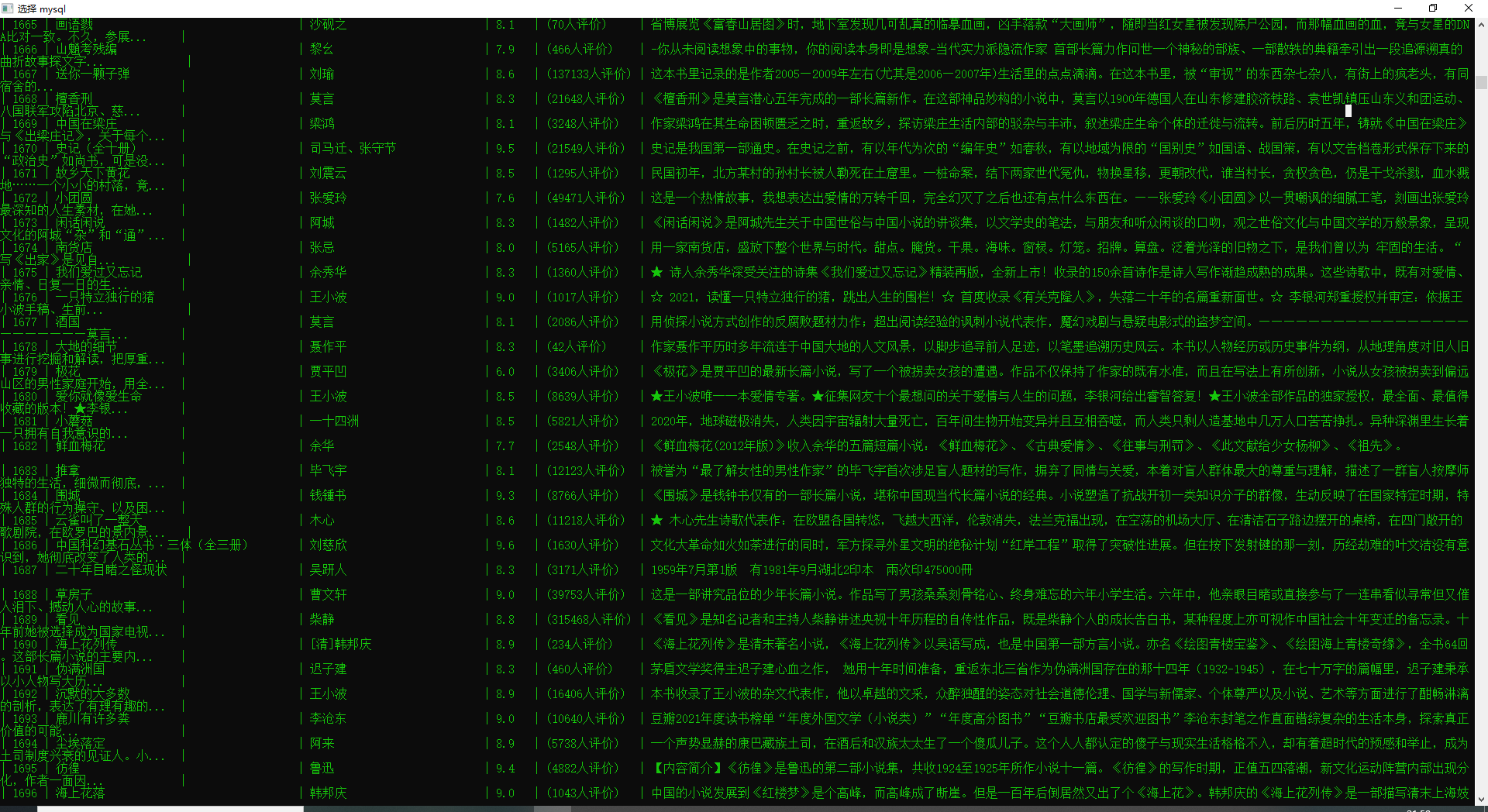
7、数据如下:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!