

异数OS 织梦师-水桶(三)-- RAM共享存储方案
.
异数OS 织梦师-水桶(三)– RAM共享存储方案
本文来自异数OS社区
github: https://github.com/yds086/HereticOS
异数OS社区QQ群: 652455784
异数OS-织梦师(消息中间件 RPC技术)群: 476260389
织梦师-水桶 RAM共享存储简介
织梦师-水桶 是使用异数OS IPC技术设计实现的一种共享介质层存储方案,得益于IPC的简单易用,因此水桶的设计过程是非常轻松容易的,也因此也更加方便用户定制扩展,由于异数OS IPC性能的突破,他也因此提供了其他系统无法提供的一些激动特性与能力。
与众不同的特性
- 简单的框架,简单的实现,使用IPC技术,不需要重量级的定义功能和通讯协议,整个实现加测试仅500行代码。
- 网络共享存储特性 传统的介质存储方案,只能访问者独占使用,不能分布式扩充性能与容量,因此在使用中受到了极大的能力限制,原因有两点,一是存储介质被硬件结构控制一般不能直接支持网络访问,二是介质存储只提供读写访问能力,对于多个读写者而言,不能彼此同步cache,造成多访问者环境出现不可预知的数据故障,因此一般介质存储之上需要复杂的文件系统(分布式)来对介质做独占访问,比如iscsi技术虽然解决了介质的网络访问问题,但却无法解决多访问者系统的cache同步,一致性等问题,因此iscsi并不能独立提供存储方案,还需要宿主操作系统的文件系统做支持,才能为应用提供共享的存储能力,织梦师-水桶则通过IPC技术解决了上述传统介质存储中问题,水桶可以使用TCP网络RPC来实现扩展远程访问的能力,同时,通过RPC技术,水桶提供了介质写入消息实时推送广播,这使得多访问者之间的cache实时同步成为可能,使用这一技术扩展各类分布式cache产品后,则可以使得各个分布式cache实例的数据更新在微秒级别完成实时跟新同步,而不需要cache产品耗费更多同步开销,从而为秒杀类推送类应用提供更好更实时的服务(12306),由于共享存储介质方案的实现,文件系统以及介质存储的边界变的模糊,介质存储因此可以不用依赖文件系统直接为应用以及cache提供存储服务,而文件系统则可以通过共享介质存储来获得更加简化高效的存储方案。
- 方便定制 由于是软件介质存储方案,因此并不需要符合一些硬件规范的通讯协议,比如scsi,nvme等,用户可以根据自己需求改变功能设计,增加写入日志,定制访问事件,甚至将介质存储改变为对象存储,也是很容易完成的。
- 方便的定制扩充nosql能力,提高nosql的一些实际业务效率,降低需求对newsql技术的依赖,长久以来nosql在提高和扩充系统容量性能,降低系统设计复杂性方面成效卓著,但nosql由于缺乏事务能力,数据结构能力固定,导致一些上层业务逻辑设计无法直接在nosql之上落地,织梦师-水桶由于使用rpc技术实现,在介质层有望提供事务定制,业务服务定制能力,将事务以及业务下沉到介质存储层有利于真正解决一些数据业务的效率问题,比如将sql的select操作下沉到存储层后,将大大降低对nosql的网络io需求,提升系统tps能力,因此从根本上使得nosql技术可以快速定制落地满足复杂项目业务需求,从而降低对newsql的需求依赖(newsql并不能高效的适应加速所有业务场景,本身对网络IO的性能以及延迟依赖较大)。
- 更灵活高效的介质访问方案 传统的介质访问技术由于考虑到linux windows等传统操作系统的实际能力限制,所以使用了更大的块存储单位,主流的硬盘 SSD都使用4096字节的块读写单位,以便于在linux windows约束下,更有利的发挥硬件带宽,但这却没有解决实际需求问题,反而带来更多性能障碍,织梦师-水桶则提供小到16字节的块访问单位,在同样带宽和内存开销下,相比4096字节的块,16字节在随机读写性能上,理论上则可达到4096字节的256倍,同时上层cache(redis)在缓存小数据时(16字节)同样的内存开销则可缓存256倍的数据项,或者在缓存同样数据项的网络带宽需求降低64倍,由于可变读写长度的优势,因此在做对象存储时对带宽以及内存的利用则变的毫无冗余。
- 10倍以上随机读写性能 在SSD成为主流存储方案后,一些基于linux windows操作系统开发的网络分布式cache方案甚至因此磁盘io性能的不适应而被淘汰,原因是SSD在存储容量以及随机读写性能以及数据安全可用性上都优于网络cache产品,但现在情况不同了,异数OS由于网络IO瓶颈解除,使用异数OS开发的cache在随机读写性能上达到SSD 10倍以上,并且由于共享存储特性,则可以很容易做到分布式容量和性能的扩充。
织梦师-水桶 方案说明

1.WriteNotifyClient 启动后在DiskIPCServer注册关注的块写入事件IPC,DiskIPCServer收到注册请求后启动一个对应的WriteNotifyPushThread,WriteNotifyPushThread等待一个写入事件event.
2.ReadWriteClient通过DiskIPCServer提供的DiskIPC服务读写RAM盘,DiskIPCServer在Write IPC中检查write操作,如果有关注的块写入事件,则触发相关event, 相关联的WriteNotifyPushThread因此活跃并通过IPC推送event到WriteNotifyClient。
demo实现以及测试代码在git目录的test目录下,有兴趣的可以观摩下。
织梦师-水桶测试成绩
测试项目中组件通讯分为LPC RPC两种,读测试主要是64线程64字节序列读和随机读,写测试以及WriteNotify的成绩暂时不提供,原因是WriteNotify回和持久化策略以及上层文件系统事件响应能力有关系,LPC是单核环境下,本地服务线程间通讯,RPC是异数OS TCP协议栈实现的跨网络通讯,环境是dpdk 82599 10G网卡环境,所有测试成绩均是指每核性能。
LPC本地64字节序列读

LPC本地64字节随机读
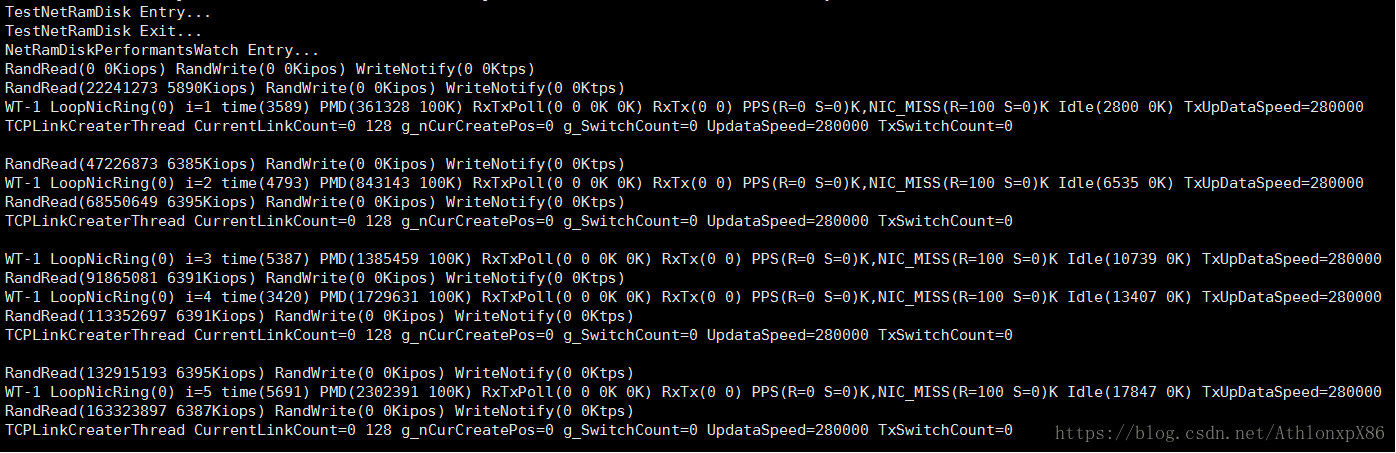
RPC TCP远程64字节序列读
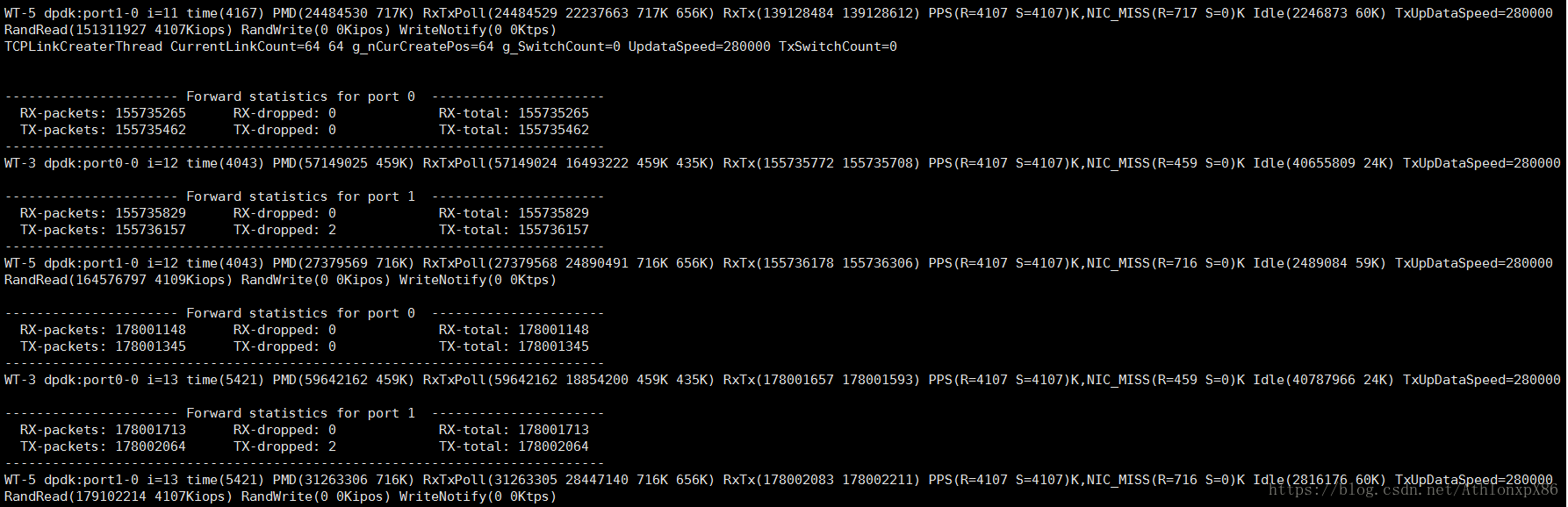
RPC TCP远程64字节随机读
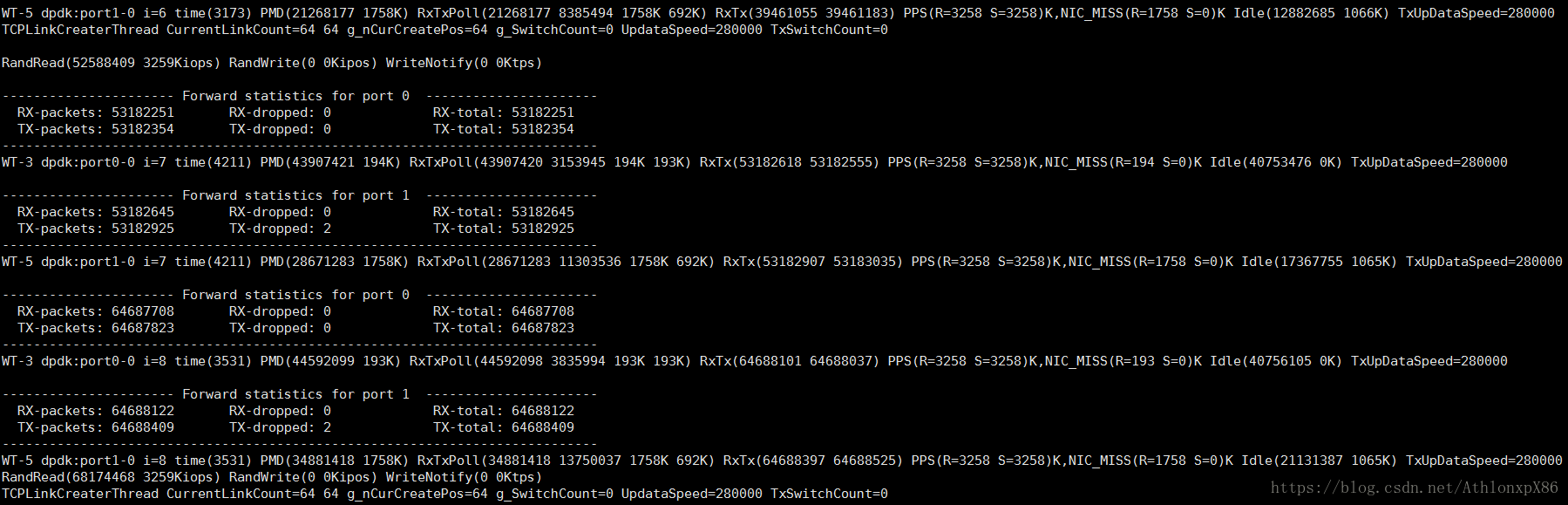
相关存储产品性能对比
数据来自网络,环境目标不同,选取目标产品最大性能值,成绩仅供参考。
引用的其他产品测试成绩
Intel 900P
https://www.chiphell.com/thread-1788441-1-1.html
https://baijiahao.baidu.com/s?id=1588310894168427063&wfr=spider&for=pc
redis
https://blog.csdn.net/zlfprogram/article/details/74338685
| 测试特性 | LPC 64字节1线程序列读 | LPC 64字节1线程随机读 | RPC 64字节64线程序列读 | RPC 64字节64线程随机读 | Intel 900P SSD 4K DQ1随机读 | Redis 非批量读 | Redis 批量读 | 阿里 PolarDB RDMA |
|---|---|---|---|---|---|---|---|---|
| IOPS | 13M | 6.4M | 4.1M | 3.5M | 55W(实际被操作系统约束在10W) | 8W | 50W | 20W |
| 平均延迟 | 调用性能/链接数量 | 调用性能/链接数量 | 调用性能/链接数量 | 调用性能/链接数量 | 10ms+调用性能/链接数量 | 10ms+调用性能/链接数量 | 10ms+调用性能/链接数量 | 10ms+调用性能/链接数量 |
| 最小延迟 | <1us | <1us | 10us | 10us | 1-10ms | 1-10ms | 1-10ms | 1-10ms |

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步